2019.12.16
強化学習(Advantage Actor-Critic)はFX取引できるか(深入り1)
こんにちは。次世代システム研究室のY.R.です。外国人です。よろしくお願いします。
1.はじまり
GMOインターネット次世代システム研究室で強化学習を利用しFX取引の研究[1,2,3]を行って続けています。 本ブログでは、前回[1]A2Cという強化学習アルゴリズムを用いてFX取引を試してみたことを深入ります。前回のブログで概述を紹介しましたが、ご興味をお持ちいただけましたら前の記事をご覧ください。
2.Actor-Criticの詳細
重要な強化学習種類として、Actor-Criticからたくさんアルゴリズム(A3C[4]、A2C[5],ACKTR[6]など)が派生しました。Actor-Criticの原理を理解して,私たちの分析結果とより複雑な計算法の両方に助けがあります。
これから、簡単なデモ[7]を通してActor-Criticの原理を説明します。
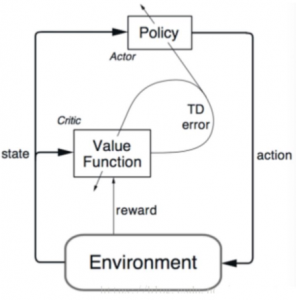
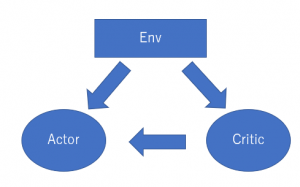
(1) (2)
図(1)はよく利用されますが、簡単にすれば図(2)になっています。Actor-Criticは自体の名前通り、ActorとCritic二つの本体で構成されました。
Criticという本体の役目は環境(Env)から状態(S)と報酬を取って評価標準を更新します。一方、Actorという本体は環境からの状態とCriticの評価に従って最適化の動作(Action)を実行します。こんなことは繰り返してActorとCritic両方も自体を更新します。
よく理解のために、両方の実装(TensorFlow 1.14.0とGym0.14.0で検証しました)に入ります。
2.1 Criticの実装
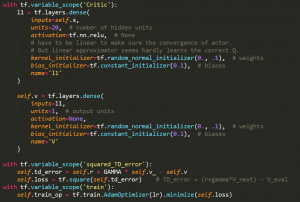
評価標準(V)は簡単なニューラルネットワークで表示されています。図(1)に紹介されたTD-Errorは評価標準の更新です。TD-Errorの最小化で評価標準を更新します。最終、Criticは最適の評価標準を取ります。気に入るところはこの更新はステップごとに進行できます。
2.2 Actorの実装
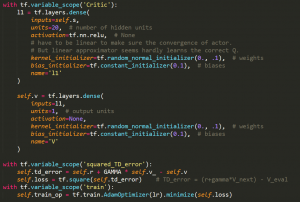
Criticと同じく簡単なニューラルネットワークを使用されました。今度のニューラルネットワークの出力は動作の確率です。ActorはCriticからのTD-Errorを参考して動作ニューラルネットワークのパラメータを調整します。
より複雑なActor-Criticアルゴリズムも以上の模式の上で展開します。
3. A2Cで取引の進展
前回と同じくA2Cを利用してFX取引できるか探索します。
3.1データ
Forex(USD/JPY)の1分足データ(OHLC)を使用
https://www.histdata.com/download-free-forex-historical-data/?/ascii/tick-data-quotes/USDJPY
トレーニング期間
2019/01/01-2019/07/31
実際にモデルのトレーニング2019/01/03でフラッシュクラッシュが起こっていましたから、始まりの1週間を抜きにしていました。そうしなければ、モデルトレーニング途中でロスカットという現象も常に起こっていました。
テスト期間
2019/08/01-2019/08/30
取引条件
初期費用:10万円
レバレッジ:25倍
ロスカット:証拠金維持率が50%以下
スプレッド: 0.003円
3.2 結果
今度良い結果をもたらすだけでなく, 不満足な結果も展示します。全面的に理解して頂けると思います。
良いトレーニングボット
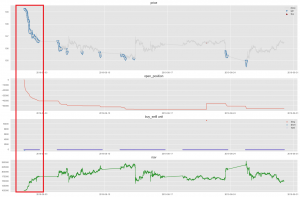
実際に、今年8月曜日でUSDJPYは大体下がりました。特に、8月分の始まりで速く落ち込んでいました。
A2Cのモデルは多く売る操作を実行していい収益(最終NAV:15万円)を取りました。
ロスカットのトレーニングボット
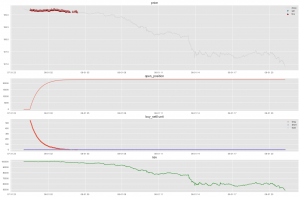
8月1日さえでロスカットのことが起こっていました。8月初期、USDJPYは速く下がっていましたが、A2Cモデルは買う動作を連続的にやりました。似ていること取引の人々でも時々発生していました。
保守的なトレーニングボット
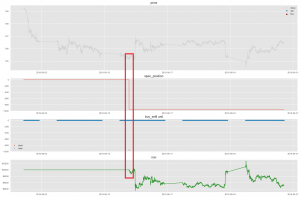
今度のモデルは速く価格下がり後で、一つのみの売る取引を実行しましたが、他の時間帯でホールドしていました。結局、損失がやはり起こっていました。取引の世界で発生したことと似ていますが、本当の原因はA2Cモデルの不安定にあると思います。
安定性を改善ために、いくつの方法を試しています。
- PPO(Proximal Policy Optimization)という強化学習アルゴリズムを応用します。具体的な探索は[2]に参考していただければいいと思います。
- 採用されたニューラルネットワークを改善します。Optuna[8]というツールを使用してパフォーマンストレーニングします。ボラティリティを減らすことは重要あります。
- トレーニングデータをよく利用します。強化学習に対してトレーニングサンプルは多ければいいと言えないと思います。トレーニングデータを十分利用することはモデルに大きい影響があると思います。
4.これから
一番重要なことはモデルの安定性を取ることです。A2Cで複雑なニューラルネットワークを採用されていますから、最適化はチャレンジになっております。更に、既存のニューラルネットワークではなく、自分の考えでPolicyニューラルネットワークを実装に向けて頑張っています。
最後に
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
参考資料
[1]https://recruit.gmo.jp/engineer/jisedai/blog/advantage-actor-critic-fx/
[2]https://recruit.gmo.jp/engineer/jisedai/blog/rl_fx_ppo2/
[3]https://recruit.gmo.jp/engineer/jisedai/blog/deep-q-learning/
[4]https://arxiv.org/pdf/1602.01783.pdf
[5]https://stable-baselines.readthedocs.io/en/master/modules/a2c.html
[6]https://stable-baselines.readthedocs.io/en/master/modules/acktr.html
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD





