GPT-4 Turbo with Vision と Streamlit で画像解説アプリ(&文章要約 with 音声)を作ってみた(2) 実装開発編
もくじ
はじめに
こんにちは、グループ研究開発本部・AI研究室のT.I.です。さて、前編では、GPT-4 Turbo with VisionのAPIとStreamlitを使って、(喋る)画像解説(+文章要約)アプリを動かしてみました。 順番が前後しますが、この後編で具体的な開発の手順を紹介します。欲しい機能(再掲)
さて、前回の実験で分かったように、GPT-4 Turbo with Visionは画像を分析して文章を生成することができます。しかし、その性能はまだまだ不十分で正確な数値の読み取りなどは難しいです、また生成AI特有の勝手に尤もらしい内容(Hallucination)を出力するので、注意が必要です。したがって出力した文章を修正することを前提に設計します。また、プロンプトの入力も可能にしますが、定型作業するためのテンプレートも選べるようにします。入力画像については、前回に紹介したようにURLからとファイルをアップロードする両方の形式をサポートします。また、OpenAI APIを使うと音声の合成もできます。いちいちレポートを読みげるのも面倒ですよね、音声を合成して代わりに読み上げてもらいましょう。以上の仕様を整理すると、以下のようになります。
- プロンプトはテンプレートから選択
- プロンプトは更に修正可能
- 画像の入力はURLとファイルアップロードの両方をサポート
- GPTの出力結果を追加修正が可能
- ついでに音声合成
…(以下略)できました。
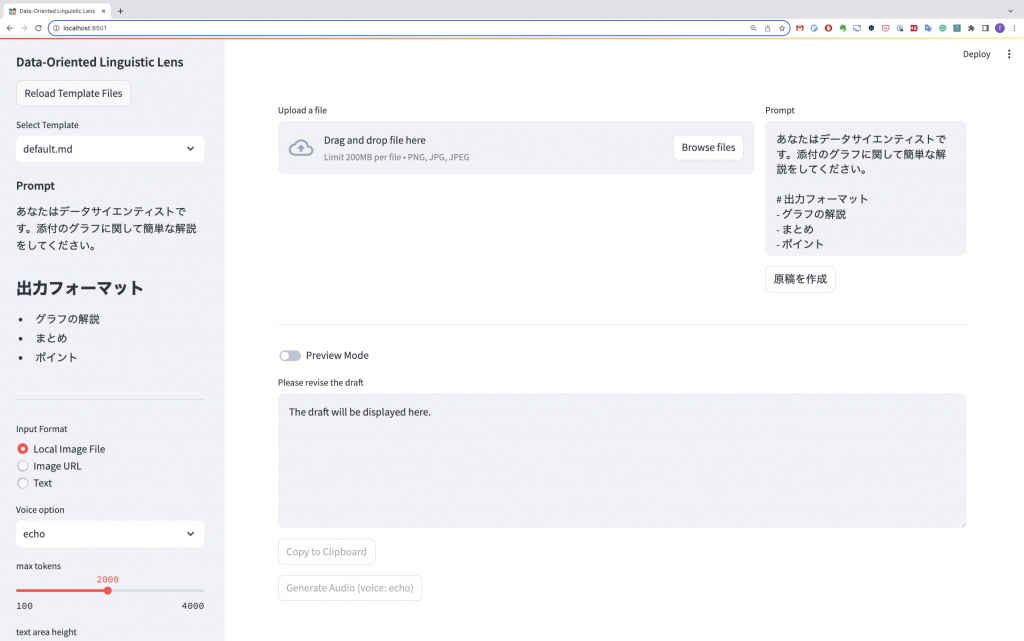
名付けて Data-Oriented Linguistic Lens 略してDOLLです。

時々、間違ったり変なことを言ったりもしますが、温かい目で見守りましょう。
さて、今回はこのアプリの実装について解説します。
(喋る)画像解説(+文章要約)アプリを作ってみた
openaiは前提として、streamlitをインストールします。(なお、streamlitのv1.29.0を使用しました)$ pip install streamlitこれで、
$ streamlit helloと実行すれば、localhostにサーバーが立ち上がって、ブラウザでアクセスできるようになります。(デフォルトではhttp://localhost:8501) 制作したアプリ(app.py)を実行するには、以下のようにします。
$ streamlit run app.py
サイドバー : プロンプト、入力フォーマットの選択と各種オプションの指定
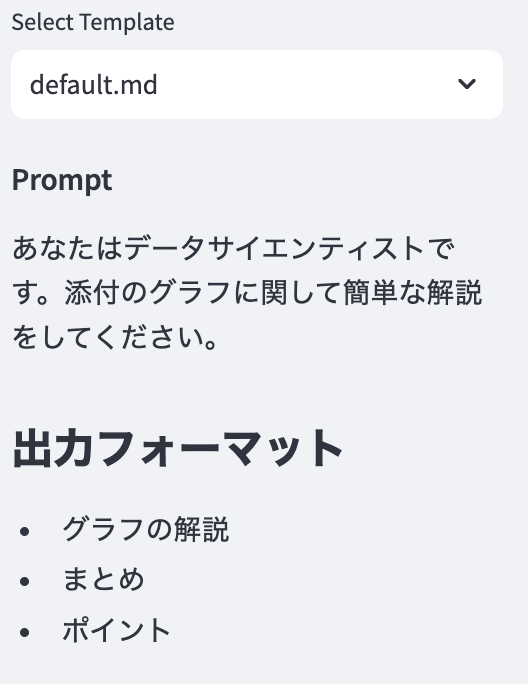
プロンプトのテンプレートとして、簡単のためtemplatesというディレクトリを作り、そこに個別のファイルで保存します。これらのテンプレートを読み取るために、sidebarにselectboxを設置します。 ファイルを追加した場合に、リストを更新するためのボタンもつけておきます。読み込んだテンプレートの内容はwriteで書き出します。これでよしなに出力してくれるのでとても便利ですね。import streamlit as st
import os
if 'template_file_list' not in st.session_state:
st.session_state.template_file_list = os.listdir('templates')
if st.sidebar.button('Reload Template Files'):
st.session_state.template_file_list = os.listdir('templates')
prompt_template_file = st.sidebar.selectbox(
'Select Template',
st.session_state.template_file_list
)
with open(f'templates/{prompt_template_file}', 'r') as f:
prompt_template_text = f.read()
st.sidebar.subheader('Prompt')
st.sidebar.write(
prompt_template_text,
)
このような感じになります。$ cat templates/default.md
あなたはデータサイエンティストです。添付のグラフに関して簡単な解説をしてください。
# 出力フォーマット
– グラフの解説
– まとめ
– ポイント
これで、こんな風なサイドバーができます。このように選択したファイルの内容が反映されて表示されます。
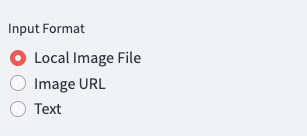
また、入力フォーマットを選択するために、Radio buttonをサイドバーにを設置します。このボタンでの選択結果は、input_formatに入力され、後の入力フォームでの条件分岐に使います。
INPUT_IMAGE_URL = 'Image URL'
INPUT_LOCAL_IMAGE_FILE = 'Local Image File'
INPUT_TEXT = 'Text'
input_format = st.sidebar.radio(
"Input Format",
[INPUT_LOCAL_IMAGE_FILE, INPUT_IMAGE_URL, INPUT_TEXT]
)
ついでに残りのサイドバーにある設定変更の機能も作成してしまいます。
voice_option = st.sidebar.selectbox(
'Voice option',
['echo', 'alloy', 'fable', 'onyx', 'nova', 'shimmer']
)
st.session_state.max_tokens = st.sidebar.slider(
'max tokens', min_value=100, max_value=4000, value=2000, step=100)
st.session_state.text_area_height = st.sidebar.slider(
'text area height', min_value=100, max_value=1000, value=400, step=100)
あたらしく出てきたsliderは、数値をスライダーで入力できるようにするものです。文章生成時のmax tokenの数や、テキストエリアの高さを調整できるようにしました。max tokenがあまり少なすぎると生成される文章が途中で切れる可能性があるので注意が必要です。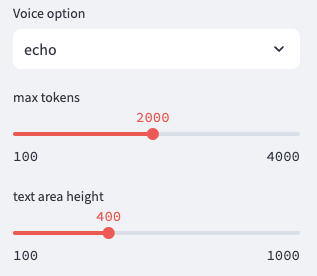
入力フォーム : 画像の入力とプロンプトの修正
次に、テンプレートを元にユーザーがプロンプトを修正、そして画像を入力するためのフォームを作ります。st.columnsで分割して、左側に画像入力、右側にプロンプトの修正を設置します。input_column, prompt_column = st.columns([0.7, 0.3])
input_data_is_valid = False
if input_format == INPUT_LOCAL_IMAGE_FILE:
uploaded_file = input_column.file_uploader(
"Upload a file", type=['png', 'jpg'])
if uploaded_file is not None:
image_data = uploaded_file.getvalue()
base64_image = base64.b64encode(image_data).decode('utf-8')
image_url = f"data:image/jpeg;base64,{base64_image}"
input_column.image(image_data)
input_data_is_valid = True
elif input_format == INPUT_IMAGE_URL:
image_url = input_column.text_input("Image URL")
if image_url:
try:
input_column.image(image_url)
input_data_is_valid = True
except Exception as e:
input_column.write(f"An error occurred: {e}")
input_column.write("Please input a valid image URL")
elif input_format == INPUT_TEXT:
additional_message = input_column.text_area("Text", height=st.session_state.text_area_height)
input_data_is_valid = True
prompt = prompt_column.text_area('Prompt', prompt_template_text, height=st.session_state.text_area_height)
generate_draft = prompt_column.button("原稿を作成")
エラーのチェックなどはもう少しちゃんとした方が良い気もしますが簡単のため省略しています。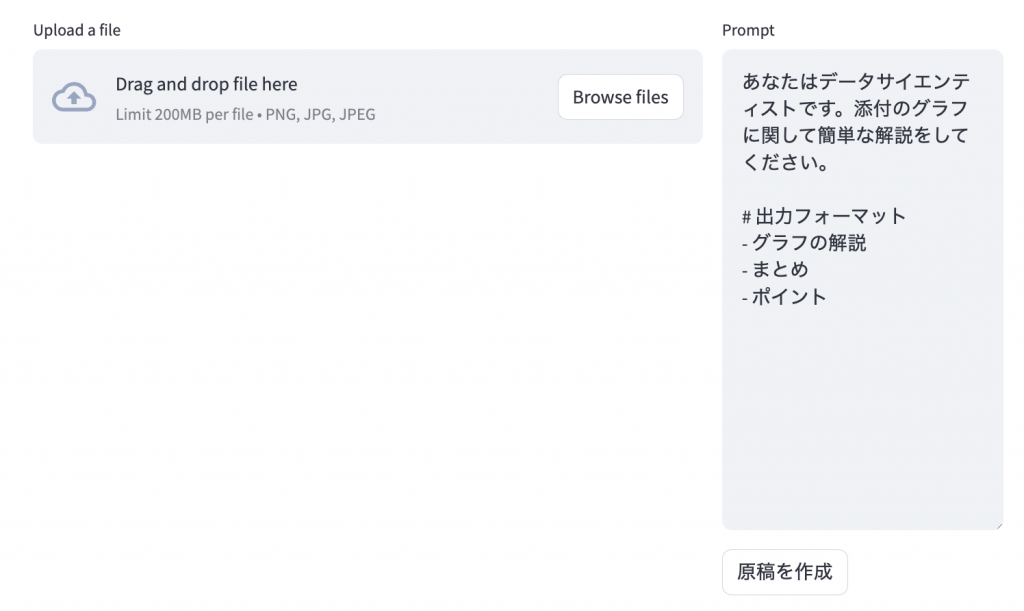
file_uploaderは、ファイルのアップロードができるフォームになります。また、imageを使うとURLや画像データであっても画像を表示できます。サイドバーで入力形式を変更すると、入力フォームが変わります。あとは前回のBlogのデモのように画像をDrag&Dropしたり、URLを入力すると画像が表示されます。text_areaは、文字を入力編集できるコンポーネントです。デフォルトでは、先ほどサイドバーで選択したテンプレートを表示します。最後のbuttonを押すと原稿生成のプロセスに進みます。文章生成機能の実装
ここで、次にOpenAIのAPIを使って、文章を生成する関数を作ります。前回のBlogで紹介したように、URLを直接指定するか、ファイルをアップロードするかで、微妙に処理が異なります。URLを指定する場合は、openaiのAPIをそのまま利用してできるのですが、ファイルをアップロードする場合は、requestsを使う必要があります。2種類の関数を作るのは面倒なので、後者に合わせて作成します。あまり洗練されたコードではありませんが、こんな感じで作ってみました。def generate_text_from_image(user_message: str, image_url: str) -> tuple[str, dict]:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": f"{user_message}"
},
{
"type": "image_url",
"image_url": {
"url": f"{image_url}"
}
}
]
}
],
"max_tokens": st.session_state.max_tokens
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload, timeout=REQUESTS_TIMEOUT)
content = response.json()['choices'][0]['message']['content']
usage = response.json()['usage']
return content, usage
また、文章要約用の関数も作成します。def generate_text_from_text(prompt: str, additional_message: str) -> tuple[str, dict]:
system_message = {
'role': 'system',
'content': [
{'type': 'text', 'text': prompt},
],
}
user_message = {
'role': 'user',
'content': [
{'type': 'text', 'text': additional_message},
],
}
response = client.chat.completions.create(
model='gpt-4-1106-preview',
messages=[system_message, user_message], max_tokens=st.session_state.max_tokens,
)
content = response.choices[0].message.content
usage = response.model_dump()['usage']
return content, usage
ついでに後で利用する声合成用の関数も作成します。def generate_voice(input_text: str, voice_option: str):
response = client.audio.speech.create(
model='tts-1',
voice=voice_option,
input=input_text
)
content = response.content
return content
そして、これらの関数を呼び出して、原稿を生成します。 少し時間のかかる処理なので、statusを使って、処理中であることをユーザーに伝えます。if 'draft_message' not in st.session_state:
st.session_state.draft_message = "The draft will be displayed here."
if generate_draft and not input_data_is_valid:
st.error("Please input valid data")
if generate_draft and input_data_is_valid:
with st.status("原稿を作成中です...少々お待ちください", expanded=True) as status:
st.subheader("Prompt")
st.text(prompt)
start_time = time.time()
if input_format in [INPUT_IMAGE_URL, INPUT_LOCAL_IMAGE_FILE]:
draft_by_gpt, usage = generate_text_from_image(
user_message=prompt, image_url=image_url)
elif input_format == INPUT_TEXT:
draft_by_gpt, usage = generate_text_from_text(
prompt=prompt, additional_message=additional_message)
end_time = time.time()
status.update(
label=f"原稿の作成が完了しました 🍻 (経過時間 {(end_time - start_time):.1f} sec., "
+ f"Prompt {usage.get('prompt_tokens'):,d} tokens, Completion {usage.get('completion_tokens'):,d} tokens, "
+ f"Total {usage.get('total_tokens'):,d} tokens)",
state="complete", expanded=False
)
st.session_state.draft_message = draft_by_gpt
画像を入力して、原稿を作成を押すと、原稿を生成中のメッセージと入力されたプロンプトが表示されます。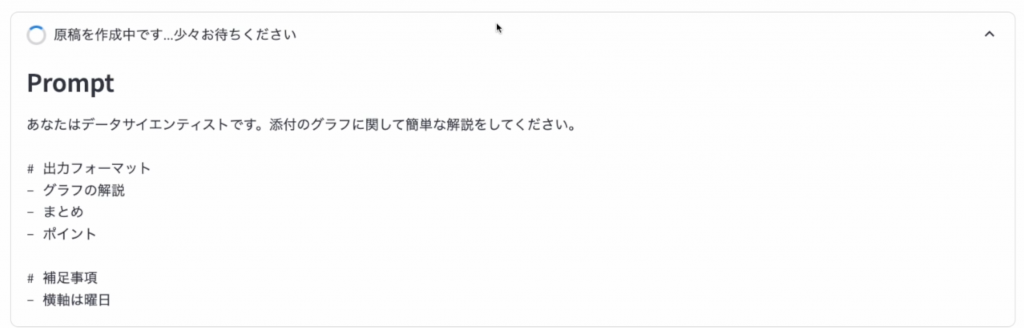
完了すると
statusは折りたたまれて、時間と使用したトークン数が表示されます。また、以下で作成するフォームに原稿が表示されます。
出力フォーム : 原稿の表示と修正
次に、原稿を表示してユーザーで修正するフォームを作成します。クリップボードへのコピーと音声合成のボタンも作ります。なお、コピーや音声合成はユーザーがチェックしてプレビュー状態でないと不可能にしておきます。プレビューへの切り替えはトグルボタン(toggle)を使用します。(disable=not on_previewとしているのが、なんともあれですが)。コピーはclipboard libraryを使っていますので、別途インストールしておきます。また、音声合成も処理に時間がかかるので、spinnerを使って、処理中であることをユーザーに伝えます。import clipboard
on_preview = st.toggle("Preview Mode", value=False)
if on_preview:
st.write(st.session_state.draft_message)
else:
st.session_state.draft_message = st.text_area(
"Please revise the draft", st.session_state.draft_message, height=st.session_state.text_area_height
)
if st.button("Copy to Clipboard", disabled=not on_preview):
clipboard.copy(st.session_state.draft_message)
st.success("Copied to clipboard!", icon='✅')
if st.button(f"Generate Audio (voice: {voice_option})", disabled=not on_preview):
with st.spinner("解説音声を生成中です...少々お待ちください"):
start_time = time.time()
content = generate_voice(input_text=st.session_state.draft_message, voice_option=voice_option)
end_time = time.time()
st.toast("音声の生成が完了しました", icon='🍻')
st.write(f"音声生成時間: {(end_time - start_time):.1f} sec.")
st.audio(content)

コードのまとめ
以上のコードをまとめると、以下のようになります。 (適当なコードですみません。そのうちに直します🙇)なお、最初の方にあるset_page_configで、タイトルやファビコン、レイアウトなどを設定しています。import os
import base64
import time
import requests
import clipboard
import streamlit as st
from openai import OpenAI
INPUT_IMAGE_URL = 'Image URL'
INPUT_LOCAL_IMAGE_FILE = 'Local Image File'
INPUT_TEXT = 'Text'
REQUESTS_TIMEOUT = 60
api_key = os.environ["OPENAI_API_KEY"]
client = OpenAI(
api_key=api_key,
)
st.set_page_config(
page_title="Data-Oriented Linguistic Lens",
page_icon=":dolls:",
layout="wide",
initial_sidebar_state="collapsed",
)
def main():
st.sidebar.header('Data-Oriented Linguistic Lens')
if 'template_file_list' not in st.session_state:
st.session_state.template_file_list = os.listdir('templates')
if st.sidebar.button('Reload Template Files'):
st.session_state.template_file_list = os.listdir('templates')
prompt_template_file = st.sidebar.selectbox(
'Select Template',
st.session_state.template_file_list
)
with open(f'templates/{prompt_template_file}', 'r') as f:
prompt_template_text = f.read()
st.sidebar.subheader('Prompt')
st.sidebar.write(
prompt_template_text,
)
st.sidebar.divider()
input_format = st.sidebar.radio(
"Input Format",
[INPUT_LOCAL_IMAGE_FILE, INPUT_IMAGE_URL, INPUT_TEXT]
)
voice_option = st.sidebar.selectbox(
'Voice option',
['echo', 'alloy', 'fable', 'onyx', 'nova', 'shimmer']
)
st.session_state.max_tokens = st.sidebar.slider(
'max tokens', min_value=100, max_value=4000, value=2000, step=100)
st.session_state.text_area_height = st.sidebar.slider(
'text area height', min_value=100, max_value=1000, value=400, step=100)
input_column, prompt_column = st.columns([0.7, 0.3])
input_data_is_valid = False
if input_format == INPUT_LOCAL_IMAGE_FILE:
uploaded_file = input_column.file_uploader(
"Upload a file", type=['png', 'jpg'])
if uploaded_file is not None:
image_data = uploaded_file.getvalue()
base64_image = base64.b64encode(image_data).decode('utf-8')
image_url = f"data:image/jpeg;base64,{base64_image}"
input_column.image(image_data)
input_data_is_valid = True
elif input_format == INPUT_IMAGE_URL:
image_url = input_column.text_input("Image URL")
if image_url:
try:
input_column.image(image_url)
input_data_is_valid = True
except Exception as e:
input_column.write(f"An error occurred: {e}")
input_column.write("Please input a valid image URL")
elif input_format == INPUT_TEXT:
additional_message = input_column.text_area("Text", height=st.session_state.text_area_height)
input_data_is_valid = True
prompt = prompt_column.text_area('Prompt', prompt_template_text, height=st.session_state.text_area_height)
generate_draft = prompt_column.button("原稿を作成")
st.divider()
if 'draft_message' not in st.session_state:
st.session_state.draft_message = "The draft will be displayed here."
if generate_draft and not input_data_is_valid:
st.error("Please input valid data")
if generate_draft and input_data_is_valid:
with st.status("原稿を作成中です...少々お待ちください", expanded=True) as status:
st.subheader("Prompt")
st.text(prompt)
start_time = time.time()
if input_format in [INPUT_IMAGE_URL, INPUT_LOCAL_IMAGE_FILE]:
draft_by_gpt, usage = generate_text_from_image(
user_message=prompt, image_url=image_url)
elif input_format == INPUT_TEXT:
draft_by_gpt, usage = generate_text_from_text(
prompt=prompt, additional_message=additional_message)
end_time = time.time()
status.update(
label=f"原稿の作成が完了しました 🍻 (経過時間 {(end_time - start_time):.1f} sec., "
+ f"Prompt {usage.get('prompt_tokens'):,d} tokens, Completion {usage.get('completion_tokens'):,d} tokens, "
+ f"Total {usage.get('total_tokens'):,d} tokens)",
state="complete", expanded=False
)
st.session_state.draft_message = draft_by_gpt
on_preview = st.toggle("Preview Mode", value=False)
if on_preview:
st.write(st.session_state.draft_message)
else:
st.session_state.draft_message = st.text_area(
"Please revise the draft", st.session_state.draft_message, height=st.session_state.text_area_height
)
if st.button("Copy to Clipboard", disabled=not on_preview):
clipboard.copy(st.session_state.draft_message)
st.success("Copied to clipboard!", icon='✅')
if st.button(f"Generate Audio (voice: {voice_option})", disabled=not on_preview):
with st.spinner("解説音声を生成中です...少々お待ちください"):
start_time = time.time()
content = generate_voice(input_text=st.session_state.draft_message, voice_option=voice_option)
end_time = time.time()
st.toast("音声の生成が完了しました", icon='🍻')
st.write(f"音声生成時間: {(end_time - start_time):.1f} sec.")
st.audio(content)
def generate_text_from_image(user_message: str, image_url: str) -> tuple[str, dict]:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": f"{user_message}"
},
{
"type": "image_url",
"image_url": {
"url": f"{image_url}"
}
}
]
}
],
"max_tokens": st.session_state.max_tokens
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload, timeout=REQUESTS_TIMEOUT)
content = response.json()['choices'][0]['message']['content']
usage = response.json()['usage']
return content, usage
def generate_text_from_text(prompt: str, additional_message: str) -> tuple[str, dict]:
system_message = {
'role': 'system',
'content': [
{'type': 'text', 'text': prompt},
],
}
user_message = {
'role': 'user',
'content': [
{'type': 'text', 'text': additional_message},
],
}
response = client.chat.completions.create(
model='gpt-4-1106-preview',
messages=[system_message, user_message], max_tokens=st.session_state.max_tokens,
)
content = response.choices[0].message.content
usage = response.model_dump()['usage']
return content, usage
def generate_voice(input_text: str, voice_option: str):
response = client.audio.speech.create(
model='tts-1',
voice=voice_option,
input=input_text
)
content = response.content
return content
if __name__ == "__main__":
main()
これを以下のように実行すれば、アプリが動きます。$ streamlit run doll.pyこれで実行したアプリの具体的な利用例が前編のBlogになります。せっかくですので使い方の動画を再掲します。
まとめ(再掲)
以上で、GPT-4 Turbo with Visionを使ったアプリを作って利用してみました。Blogの前編として実際の利用例、そして後編では、Streamlitで具体的な実装を紹介しました。Streamlitは、簡単にWebアプリを作ることができるので、とても便利でした。 GPTsで同じようなことはもちろん可能ですが、ノーコードの場合、アプリの管理やバージョンコントロールなどの面で、非常に不便です。このようにコードで管理していれば簡単に複製や修正が可能です。また、APIを使うことにより入力データを学習に使われないので、安心して使うことができますね。つい先日知ったのですが、ChatGPTのSettings-Data controls-Chat history & trainingをオフにすると問答無用でMy GPTsも利用が不可能になります。更に、ChatGPT Plusは、月額$20必要ですが、今回のようにAPIを利用した場合、gpt-4-1106-vision-preview(gpt-4-1106-preview)は、inputでは、$0.01/1K tokens, outputでは$0.03/1K tokensです(2023/12/17時点)。画像に関しても別途必要みたいですが、1080×1080 pixels で、$0.00765なので、outputのコストと比較すると少ないです。今回の実験では、1回あたり両方とも1K tokens程度だったので、$0.05ぐらいのコストでしょうか(そのチェックのためもあって使用したtokenを出力するようにしました)、ざっくりですが400回ぐらい使えば、ChatGPT Plusの月額分になります。で、それほど頻繁に使うかと言われると、週1回の報告に高々数枚のグラフの解説する程度なので、失敗した場合も考えて週10回、1ヶ月で40回ぐらい使うとして、$2ぐらいのコストになります。文章要約だけでしたら、GPT-3.5 Turbo(gpt-3.5-turbo-1106で、input $0.0010/1K tokens, output $0.0020/1K tokens)を利用するなら更に安く済ませることも可能です。Chatではなく、簡単なルールに従った出力をさせるだけのMy GPTsを作るぐらいなら、このアプリで済ませるほうがお手軽でプロンプトの切り替えも簡単ですね。
今回のアプリは、MVPとして必要最低限の機能のみに限定していましたが、もう少し使いやすく色々と改良を加えていきたいですね。そもそも利用しているAPIやmodelもpreview版な感じなので、今後のOpenAIのアップデートに対応しないといけません。
正直、グラフの解説内容に関しては、見れば直ちに分かる内容が出てくるだけで特に目新しいものではありません。ただ、それらの情報を言語化して、毎度それを解説することは、なかなか面倒です
追記:今回のデモ動画は一発撮りで作りましたが、生成AIの性質上、同じ画像・プロンプトであっても毎回、結果が異なります。それ自体は新しい視点からの意見として面白いのですが、それをチェックして修正する作業となると何が出てくるか予想できないだけあってかなり大変でした(何回も撮り直したものもあります)。ですが、後で動画を編集するなら最初から切り貼りして作ればよかったと終わってから気がつきました。次回からはそうします。
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
- Blog「GPT-4 Turbo with visionを使って画像を分析してみた」https://recruit.gmo.jp/engineer/jisedai/blog/gpt-4-turbo-with-vision/
- Streamlit https://docs.streamlit.io/
- OpenAI developer platform https://platform.openai.com/
- OpenAI Pricing https://openai.com/pricing