2019.10.16
クリック予測のモデルにおいて、Neural NetworkのEmbeddingはどんなものか
こんにちは。次世代システム研究室のA.Z.です。
みんなさん毎日インターネット利用し、様々な自分が好きなことや興味がある情報を見ていると思います。
何か自分が好きなことや興味を持つことが見つかったら、あるリンクや画像などをクリックし、詳細情報や商品ページなどに遷移します。そこで、ものを買ったりや記事を読んだりをすることです。そのようにインターネットのビジネスが生み出しました。
ユーザーがどんな興味を持つか、どんな関心を持つかをできるだけ想定し、それに合う情報や商品などを見せることが重要です。ユーザの興味と合う情報を提供すると、ユーザがクリックする確率が高くなります。一方、ユーザの興味が合わない情報を提供すると、クリック確率が低くなり、更にユーザにとっては`うざい`という印象になりました。
特にインターネット広告の業界の中に、どれだけクリック予測精度が良いのかはかなり重要になっています。ctr精度がよければ、もっと効率的に広告配信でき、結果的に利益も改善されます。
今回は現在担当しているインターネット広告関連プロジェクト改善に伴い、取り込んだ内容(Embedding手法)について、簡単に紹介したいと思います。
クリック予測の最近の話
クリック予測するにはほとんど機械学習の手法を利用しています。様々な特徴量を作成し、その特徴量を機械学習モデルに流し、クリックする確率の値が出てきます。Neural networkのboom以前、基本的に linearモデル(Gradient Boosting, Random Forestなど)が使われていたがNeural networkの流行った後はclick予測で使われているモデルはほとんどNeural network系になっています。
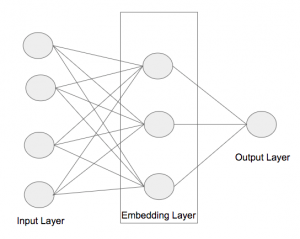
今まで、様々なNeural network baseのモデルがありますが、基本的に、MLP(Multi Layer Perceptron)+Embeddingアプローチが一番よく使われています。Embedding部分はdiscreteとsparseなカテゴリ系の特徴量を低次元の空間に変換する為に使われています。その後、Pooling layerを利用し、固定次元のベクトルに変換する。Pooling layerの結果は次のMLPの部分にinputになります。こちらのMLPの役割はMLPのFull connectedの特徴で、feature間のインタラクションを学習する為です。具体的にイメージは以下の図になります。
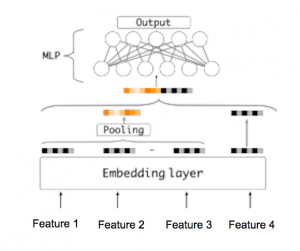
MLPの部分や、それ以外の構造は様々要素に影響されいます。例えば、利用できる特徴量(user系、商品系、記事系など)や、利用目的(製品のクリック予測とか、広告のクリック予測)によって変わります。Embeddingの部分は基本的に、汎用的である、どんなケースでも使いかたや構造はほとんど変わりません。なので、今回はEmbeddingについて、もっと詳しく紹介します。
Embedding について
Embeddingとはある特徴量を別の次元にmappingする手法です。Neural networkでのEmbeddingは基本的に、one hot encodingでcategorical featureをN次元(基本的に、Nはカテゴリの数より少ない)空間に変換を行います。目的はいくつかにあります。
-
多次元のsparse空間の特徴量をもっとdense空間に変換するためです。つまり、featureの次元を減らすため。
-
discrete空間(one hot encoding)で、表現できない特徴量の関係をN次元の連続空間に変換することで、関連性や関係性を表現できるようにする為
Neural NetworkでEmbeddingを使う
基本的に、一般的に使われているdeep learning framework(tensorflow,pytorchなど)では、embedding layerというembedding仕組みを用意されています。
今回はちょっと簡単なケースで作成して見ます。例えば、以下のようなデータがあります。`cat_feat_a`はある
一つのカテゴリ特徴量になっています。labelのほは正解データをになっています。例えば
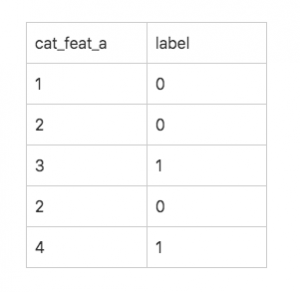
上記の例だと、カテゴリ3とカテゴリ4の値近くなるように、同じlabelを設定いたしました。
つまり、カテゴリ3とカテゴリ4はpositiveになりようようになります。
次は、上記のデータから、実際に、neural networkに入れる為のデータ形式を変換します。
例えば、全体のカテゴリの数は4のカテゴリがあります。そうすると、`cat_feat_a`のone hot encodingの結果は以下になります。
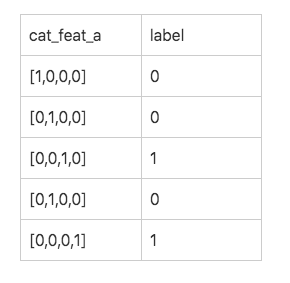
データが形式ができたら、次は、neural networkの構造そ作成します。今回使っている構造はかなり簡単で、
-
input layer : 4 node
-
embedding layer: 3 node
-
4次元のinputデータを3次元に変換します。
-
-
output layer : 1 node
-
0 or 1
-
今回は一番最新版tensorflow 2.0.0を使っています。実際にtensorflowのコードで、大体こんな感じになります。
import numpy as np
import pandas as pd
import os
import sys
import tensorflow as tf
import datetime
data=np.array([
np.array([1,0,0,0]),
np.array([0,1,0,0]),
np.array([0,0,1,0]),
np.array([0,1,0,0]),
np.array([0,0,0,1]),
])
target=np.array([0,0,1,0,1])
# do embedding
def get_compiled_model():
model = tf.keras.Sequential([
tf.keras.layers.Embedding(4,3,input_length=4), #embedding layer
tf.keras.layers.Flatten(), #flatten layer
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
return model
model = get_compiled_model()
model.fit(tf_dataset, epochs=10)
実際に各カテゴリの関連性や関係を確認して見ましょう。
cos_sim=np.zeros((4,4))
emb_weights=model.layers[0].get_weights()[0]
for i in range(4):
for j in range(4):
cos_sim[i,j]=spatial.distance.cosine(emb_weights[i],emb_weights[j])
結果
array([[0. , 1.86820132, 1.33754292, 1.33195299],
[1.86820132, 0. , 0.87285927, 0.62867606],
[1.33754292, 0.87285927, 0. , 0.33248162],
[1.33195299, 0.62867606, 0.33248162, 0. ]])
上記の結果からみると、cat_3とcat4は近い関連性が見られました。つまり、最初の想定した通りの結果になります。
Embedding手法を使って、neural networkでのカテゴリの特徴量はもっとうまく表現できることがわかりました。
特に特徴量のカテゴリ数が多い時とか全体のfeatureの数が多くなる時とか先にembeddingをlayerをかまして、全体的なneural networkの精度が上がるではないかと思います。
まとめ
-
今回はNeural Networkに置けるEmbedding方法について紹介しました。
-
Embeddingを利用し、カテゴリ間の関連性の表現が困難なものは表現できるようになりました。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD