2022.04.05
ユーザーの暗黙的フィードバック(Implicit Feedback)からオススメアイテムを推奨したい
導入
こんにちは、次世代システム研究室の T.I. です。
前回の Blog では、ユーザーの明示的(explicit)な評価をもとにアイテムを推薦する explicit feedback の手法の1つ matrix factorization について紹介しました。その際に、ユーザー評価は元々の嗜好などのバイアスが含まれる点とその対策について解説しました。
しかし、世の中、評価してくださるユーザーは希で実際のユーザー全体を反映していません。(そのため、一部の極端な方々が目立つわけですね)明確な評価データを持たないユーザーに対して、その嗜好を予想し推奨するためには、暗黙的(implicit)な反応をもとに推薦する必要があります。
今回の Blog では、Implicit Feedback に基づいた推薦システムに特徴と実装について紹介します。
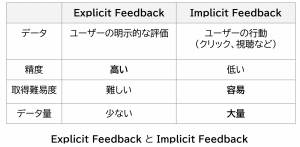
Explicit Feedback と Implicit Feedback
Explicit Feedback とは、ユーザーのアイテムに対する明示的な嗜好データです。前回、紹介した MovieLens Dataset では、ユーザーごとの映画に対する5段階の評価のデータでした。個人の嗜好を正確に把握できますが、データとしては入手が難しいです。
一方で Implicit Feedback とは、ユーザーの行動(クリックや試聴、購入など)から嗜好を推定して利用します。真の嗜好ではなく、あくまで推察である点に注意が必要です。例えば、広告を間違えてしてクリックしてしまった経験がある方も多いと思いますが、だからと言って、その商品の興味があるとは限りません。そのため Implicit Feedback の精度は Explicit Feedback ほど正確ではありません。しかし、ユーザーの行動ログから大量に入手できる利点があります。多くの方は特にアイテムの評価をしなくても、Netflix や Amazon などのサービスで勝手に自分の興味のあるアイテムが推薦された経験があると思います。これは私たちの行動ログから嗜好を推測して、それに沿って推薦が行われているからです。
まずは、Explicit & Implicit Feedback の問題を整理してみます。
アイテム \( i \in I \) とユーザー \(u \in U \) に対するフィードバックを
\( r_{ui} \in \mathbf{R} \)と定義します。フィードバックはExplicit Feedback の場合は嗜好に関するスコア、Implicit Feedback の場合では、クリック数や視聴時間などのユーザー反応に関する数値となります。
そもそもの前提として、可能性のあるユーザーとアイテムの組み合わせ \( |U| \times |I| \) と比較して、実際に観測されるデータ \( (u, i) \in S \) は極めて少なく \( |S| \ll |U| \times |I| \)、Feedback Matrix はほとんどの要素が空の非常に疎な行列となります。
目的は未知のユーザー・アイテムの組みに対する feedback \( \hat{r}_{ui} \) を予測し、未知のアイテムに対して高い評価の期待できるものを推奨します。
その代表的な手法が Matrix Factorization といい \( R \approx P^T Q \) のようにユーザー行列(P)とアイテム行列(Q)の積で元の Feedback Matrix を近似し、未知の行列の要素を推定します。同様の手法としてSVD(Singular Value Decomposition)、FM(Factorization Machine)という手法もあります。
Alternative Least Square
Explicit Feedback では、低い評価によりユーザーの好まない度合いのデータも含まれています。(ただし、前回の Blog で紹介したように、そもそも興味のないアイテムについてはユーザーは評価すらしないので、そのバイアスが含まれている点には注意が必要です。)一方で、Implicit Feedback では、ユーザー行動を追跡し、その興味・関心を推定するために、ここで好まないもの(負例)のデータが欠損しています。
単純にこの負例を無視して Matrix Factorization などで推薦すると、一見すると精度が良くても問題のある推薦をしてしまうことが Xin らの論文で示されています。彼らの論文では、特定の嗜好グループのクラスターがいくつか存在する半人工データを用いて、負例を無視した解析をした結果、ファミリームービーを好んでいた子供にホラームービーを勧めてしまうあまりよろしくないアイテムが推薦されることを示しました。
また、Implicit Feedback では、対象は全ユーザー・全アイテムのために、Explicit Feedback 以上に膨大なデータを扱う必要があり計算コスト・時間がはねあがります。そのために Implicit Feedback で用いられる代表的なアルゴリズムであるAlternative Least Square をここでは解説します。
基本的は前回紹介した Matrix Factorization (MF) と同じです。MFでは、ユーザーから得られた rating 情報 \( r_{ui} \in \mathbf{R} \)をユーザー行列とアイテム行列 \( y_I \in \mathbf{R}^f \)の積で近似します。この \( f \) は特徴量を埋め込む行列の次元の数となります。モデルの学習では、以下の量を観測されたデータに対して最小化します。
$$
\min_{x,y} \sum_{r_{ui} \in \Omega} \left(r_{ui}- x_u^T y_i \right)^2 + \lambda \left( ||x_u||^2 + ||y_i||^2 \right)
$$
ここで、 \( \lambda \) は正規化パラメータで過学習を防ぐために導入します。
Implicit Feedback にこの手法を応用するために rating ( \( r_{ui} \in \mathbf{R} \) )の代わりに confidence \( c_{ui} \) を導入します。
まず、ユーザーの feedback の有無に対応して 0 or 1 となる指標 preference \( p_{ui} \) を定義します。
- \( p_{ui} = 1\) for \( r_{ui} > 0 \)
- \( p_{ui} = 0\) for \( r_{ui} = 0 \)
preference = 1 ならば、ユーザーの関心があったことを意味しますが、preference = 0 の場合、ユーザーは本当に関心がないのでしょうか?
そもそも、そのアイテムを見る機会がなかっただけかもしれません。そのためこのようなアイテムを完全に無視することは推薦システムとして不十分であります。そこで、confidence \( c_{ui} \) を以下のように定義します。
$$
c_{ui} = 1 + \alpha r_{ui}
$$
\(\alpha \) はパラメータです。つまり、フィードバックのないアイテムに対しても最小限の confidence (=1) を与え、反応のあったものに対しては \( \alpha \) の重みをつけます。そして、最小化する目的関数は以下で与えられます。
$$
\min_{x,y} \sum_{u,i} c_{ui} (p_{u,i} – x_u^T y_i)^2 + \lambda \left( \sum_u ||x_u||^2 + \sum_i ||y_i||^2 \right)
$$
さて、この目的関数ですが、実用上の問題があります。Explicit Feedback の場合、観測された評価について和をとりますが、この式では全てのユーザー数(n) x 全てのアイテム数(m)の計算コストが必要です。これは典型的なデータセットでも数十億超えてしまうため Explicit Feedback で用いたStochastic Gradient Decent (SGD) で取り扱うことは効率が非常に悪く時間もかかります。
そのために提唱された技術が Alternating Least Squares (ALS) です。ユーザー行列(X)・アイテム行列(Y)を交互に更新し目的関数を最小化します。
- ユーザー行列の更新
- \( x_u = (Y^T C^u Y + \lambda I)^{-1} Y^T C^u p(u) \)
- アイテム行列の更新
- \( y_i = (X^C C^i X + \lambda I)^{-1} X^T C^i p(i) \)
それぞれの式は、目的関数の微分から導出できます。ここで、\( C^u = C_{ii}^u = c_{ui} \) となる \( n \times n \) 行の対角行列、\( C^i = C_{uu}^i = c_{ui} \) となる \( m \times m \) の対角行列です。また、\( p(u)(p(i)) \) は、それぞれ個別のユーザー(アイテム)の preference のベクトルです。この計算で最もコストが掛かるのは \( Y^T C^u Y \) で、\( \mathcal{O}(f^2 n) \)となり、これをユーザー数 \( m \) だけ繰り返す必要があります。
さて、ここで
$$
Y^T C^u Y = Y^ Y + Y^T(C^u – I) Y
$$
と式を変形します。一見、無駄な操作に見えますが、実は第1項はユーザーに依存しないので計算は1度だけで済みます。
また、第2項のも対角行列かつ殆どがゼロでfeedbackのあった一部の要素のみ非ゼロとなるので計算はその部分のみを扱えばよいです。\( C^u p(u) \) についても、feedback のあったものを評価すればよく、結果的に計算が非常に効率化されます。アイテム行列の更新も同様です。些細な工夫ですがよく考えられていて感心させられます。
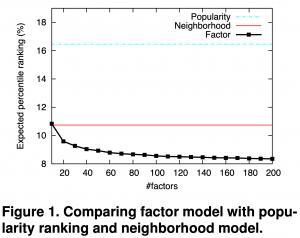
以下の図は、Hu et al より引用したユーザー・アイテム行列の factor f を増やした場合の精度をベースラインと比較した結果です。f を増やすほどに精度が改善されることが分かります。
また、これらの行列を用いて推奨の説明ができます。アイテムの推薦が透明性があるほど、その結果を信頼し推薦結果を好んだという研究結果が示されています。確かに唐突にアイテムを推奨されるよりも、以前にあるアイテムに関心を示したので、それではこちらもどうですか?と勧められるほうが実感として納得しやすいですね。
ALS で予測される preference は、
$$
\hat{p}_{ui} = y_i^T x_u
$$
となり、これは以下のように変形できます。
$$
\hat{p}_{ui} = \sum_{j;r_{ui} > 0} s_{ij}^u c_{uj}
$$
ここで、 \( s_{ij} = y_i^T (Y^T C^u Y + \lambda I)^{-1} y_j \)で、これは、既存のユーザーの Feedback (confidence) が推奨に寄与する重みとなります。
Implicit
最後に Implicit Feedback の python library を使って推薦システムを作ってみます。ALS の algorithm はシンプルで実装は簡単ではありますが、実際に動かすには library を利用した方が手軽でかつ高速です。今回は、その名も implicit (そのままですね)という library(https://github.com/benfred/implicit)を利用しました。これは、Cython と OpenMP を利用することで動作を高速化しており、さらにGPUの利用も可能です。
Implicit では、推奨モデルでよく使われる MovieLens のデータセットに加えて LastFMなどの複数のデータセットを手軽に利用できます。default で利用可能なデータセットは以下の5つとなります。
import implicit print(implicit.__version__) # -> 0.5.2 from implicit.datasets.lastfm import get_lastfm from implicit.datasets.million_song_dataset import get_msd_taste_profile from implicit.datasets.movielens import get_movielens from implicit.datasets.reddit import get_reddit from implicit.datasets.sketchfab import get_sketchfab
データの詳細については、Docstring と対応するドキュメントに説明がありますので助かります。
In [1]: from implicit.datasets.lastfm import get_lastfm In [2]: get_lastfm? Signature: get_lastfm() Docstring: Returns the lastfm360k dataset, downloading locally if necessary. Returns a tuple of (artistids, userids, plays) where plays is a CSR matrix File: ~/miniforge3/envs/py38_implicit/lib/python3.8/site-packages/implicit/datasets/lastfm.py Type: function
Sketchfab Dataset
今回は、その中で Sketchfab データセットを利用します。Sketchfab(https://sketchfab.com/) とは、3D model の取引ができるサイトです。
アイテムを選択するとこのように 3D model を操作したり、類似したアイテムが自動的に推薦されたりします。
他にもBlog に埋め込むことも可能です。
この Sketchfab のユーザーがアイテムに付けた like のデータセットになります。
詳細については、こちらのBlog(https://www.ethanrosenthal.com/2016/10/09/likes-out-guerilla-dataset/)にまとめられています。
In [1]: from implicit.datasets.sketchfab import get_sketchfab In [2]: get_sketchfab? Signature: get_sketchfab() Docstring: Returns the sketchfab dataset, downloading locally if necessary. This dataset contains about 632K likes from 62K users on 28k items collected from the sketchfab website, as described here: http://blog.ethanrosenthal.com/2016/10/09/likes-out-guerilla-dataset/ Returns a tuple of (items, users, likes) where likes is a CSR matrix File: ~/miniforge3/envs/py38_implicit/lib/python3.8/site-packages/implicit/datasets/sketchfab.py Type: function
データセットの読み込みは以下の通りです。
from implicit.datasets.sketchfab import get_sketchfab items, users, likes = get_sketchfab()
この詳細は以下の通りです。
- number of items 28,806
- number of users 62,583
- number of feedbacks 632,677
- sparsity 99.965%
アイテム x ユーザー数が、約18億に対して得られている feedback は約63万と極めて疎な行列となっています。どのようなデータ分布となっているか簡単にEDAしてみます。
import pandas as pd df = pd.Series.sparse.from_coo(likes.tocoo()).to_frame().reset_index() df.columns = ['item', 'user', 'like'] df.head() # item user like # 0 0 7445 1.0 # 1 0 9075 1.0 # 2 0 13847 1.0 # 3 0 14010 1.0 # 4 0 16585 1.0
ここで注意ですが、データセットは非常に疎な行列ですので、CSR(Compressed Sparse Row)形式で保存されています。これを元の密な行列に直してデータフレームに格納するとメモリが膨大となり大変なことになります。そのため、pandas でも sparse な形式のまま扱う必要があります。
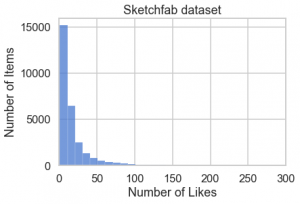
fig, ax = plt.subplots()
sns.histplot(df.item.value_counts(), binwidth=10, ax=ax)
ax.set(xlim=(0, 300), xlabel='Number of Likes', ylabel='Number of Items',
title='Sketchfab dataset')
fig.savefig('figs/numberof_items_vs_likes.png', bbox_inches='tight')
fig, ax = plt.subplots()
sns.histplot(df.user.value_counts(), binwidth=5, ax=ax)
ax.set(xlim=(0, 100), xlabel='Number of Likes', ylabel='Number of Users',
title='Sketchfab dataset')
fig.savefig('figs/numberof_users_vs_likes.png', bbox_inches='tight')
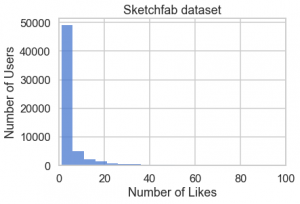
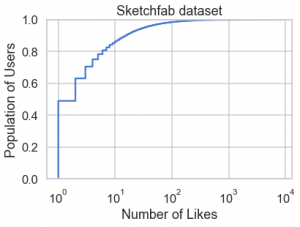
上記のグラフから分かるように、殆どのユーザー・アイテムの feedback の件数はそれほど多くないことが分かります。ただし、この種の歪みが大きい分布の場合はヒストグラムではなくて、累積分布(ECDF)による可視化のほうがより正確なデータの特徴が把握できます。極端に多い like を持つアイテム・ユーザーの数は上位数%に限っており、約9割のアイテム、約5割のユーザーは高々 10 件程度であると分かります。
fig, ax = plt.subplots() sns.ecdfplot(df.item.value_counts(), log_scale=True, ax=ax) ax.set(title='Sketchfab dataset', xlabel='Number of Likes', ylabel='Population of Items')
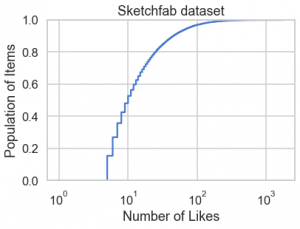
fig, ax = plt.subplots()
sns.ecdfplot(df.user.value_counts(), log_scale=True, ax=ax)
ax.set(title='Sketchfab dataset', xlabel='Number of Likes', ylabel='Population of Users')
fig.savefig('figs/number_of_likes_vs_users_ecdf.png', bbox_inches='tight')
Implicit によるアイテム推奨
さて、実際にALSで学習してみます。get_sketchfab で得られた implicit feedback はアイテム x ユーザーの形になっていたので、ユーザー x アイテムの形に変換して利用します。factor は特徴量を埋め込むベクトルの次元数で、regularization とは、正則化のパラメータとなります。なお、confidence のパラメーターのαは直接に掛け合わせて設定します。
from implicit.als import AlternatingLeastSquares user_likes = likes.T.tocsr() factors = 40 _lambda = 0.1 _alpha = 50 model = AlternatingLeastSquares(factors=factors, regularization=_lambda, calculate_training_loss=True, random_state=42) model.fit(_alpha * user_likes)
これで学習ができました。
では、実際に推奨してみます。
def recommend_items(userid, N=10, filter_already_liked_items=False):
ids, scores = model.recommend(userid, user_likes[userid], N=N,
filter_already_liked_items=filter_already_liked_items)
df_recommend = pd.DataFrame({"items": items[ids], "item_index": ids, "scores": scores,
"already_liked" : np.in1d(ids, user_likes[userid].indices)})
df_recommend['items'] = df_recommend['items'].apply(lambda x: x.decode()) # decode bytes to strong
return df_recommend
df_recommend = recommend_items(userid=258)
df_recommend
# items item_index scores already_liked
# 0 522e811044bc4e09bf84431e6c1cc109 9079 0.781962 True
# 1 641feb1a485b492c8de31e84ff89ad64 11113 0.508428 True
# 2 694f033755bd42709f56d7cb81b78a6e 11692 0.495486 True
# 3 hliAt7xc6YU2XjXh5G4lzmQwFmR 28325 0.474780 False
# 4 f3769a474a714ebbbaca0d97f9b0a5a0 26840 0.447096 False
# 5 470a1dc7ffde4177bc4bf23605ba82a6 7899 0.421501 True
# 6 1d5285f2e0fd4211a27c8042496d5959 3267 0.398827 False
# 7 eb88f06b4bc342d6bfa99e7608f1d7be 26022 0.348721 False
# 8 ac0a9c6676e34d1ebb184d8e93443c77 19131 0.346815 False
# 9 ea69a7088e1e481fb14723dcc31088d5 25913 0.339477 False
ここで、item ID は byte 形式のため変換が必要です。これらの item ID がずらずらと出ましたが、これでは一体何が何だか分からないですよね。具体的にItem IDに対応する 3D model の情報は以下の URL にアクセスすれば見ることができます。
https://sketchfab.com/models/522e811044bc4e09bf84431e6c1cc109
これはり首長竜(≠恐竜)リオプレウロドンの 3D model ですね(しかも、動く)。
こんなことを逐次手作業でチェックしてられませんので、Scraping します。
import request url = 'https://sketchfab.com/i/models/522e811044bc4e09bf84431e6c1cc109' response = requests.get(url).json()
アイテムの名前やthumbnailの情報は以下のように取得できます。
name = response.get('name')
thumbnails = response.get('thumbnails').get('images')
この thumbnails は、アイテムによりますが、複数の解像度の jpeg file へのリンクと、解像度の情報などが含まれています。これらを組み合わせて推奨アイテムをまとめて可視化してみます。
ちなみに、先ほどEDAでみた大量の評価を集めている 3D model ってどんな感じでしょうか?
from IPython.display import HTML
N = 5
df_top_N = df.item.value_counts().to_frame(name='likes')[:N]
_html = ''
for ith, (ind, row) in enumerate(df_top_N.iterrows(), start=1):
itemid = ind
item_likes = row['likes']
url = 'https://sketchfab.com/i/models/{}'.format(items[itemid].decode())
try:
response = requests.get(url).json()
_name = response.get('name')
_df = pd.DataFrame(response.get('thumbnails').get('images'))
image_src = _df.sort_values('width', ascending=False).iloc[0]['url']
_html += f'{_name} : {item_likes} likes<br>\n'
_html += f'<img src="{image_src}" width="300"/><br>\n'
except:
print(f'failed to get {url}')
HTML(_html)
では、話を戻して先ほどのユーザーに推奨したアイテムを見てみます。
def create_recommendation_thumbnails_html(df_recommend):
_html = ''
for ith, row in df_recommend.iterrows():
item_id = row['items']
_score = row['scores']
url = 'https://sketchfab.com/i/models/{}'.format(item_id)
try:
response = requests.get(url).json()
_name = response.get('name')
print(_name)
_df = pd.DataFrame(response.get('thumbnails').get('images'))
image_src = _df.sort_values('width', ascending=False).iloc[0]['url']
_html += f'ranking = {ith+1}, title = {_name}, score = {_score:.3f}<br>\n'
_html += f'<img src="{image_src}" width="300"/><br>\n'
except:
print(f'failed to get {url})
return _html
df_recommend = recommend_items(userid=258)
_html = create_recommendation_thumbnails_html(df_recommend=df_recommend)
HTML(_html)

なるほど、恐竜や動物、廃墟?などのそれっぽいアイテムが推奨されていますね。
ALS の解説で述べたように推薦されたアイテムに対して、どのような要因で推薦したかの説明が可能です。
def create_explanation_thumbnails_html(recommended_item, top_contributions):
_html = ''
url = 'https://sketchfab.com/i/models/{}'.format(items[recommended_item].decode())
try:
response = requests.get(url).json()
_name = response.get('name')
_df = pd.DataFrame(response.get('thumbnails').get('images'))
image_src = _df.sort_values('width', ascending=False).iloc[0]['url']
_html += f'RECOMMENDED ITEM {_name}<br>\n'
_html += f'<img src="{image_src}" width="300"/></br>\n'
except:
print(f'failed to get {url}')
_html += '<hr>'
for ith, row in enumerate(top_contributions, start=1):
itemid = row[0]
weight = row[1]
url = 'https://sketchfab.com/i/models/{}'.format(items[itemid].decode())
try:
response = requests.get(url).json()
_name = response.get('name')
_df = pd.DataFrame(response.get('thumbnails').get('images'))
image_src = _df.sort_values('width', ascending=False).iloc[0]['url']
_html += f'{ith}. {_name} : weight = {weight:.6f}<br>\n'
_html += f'<img src="{image_src}" width="300"/></br>\n'
except:
print(f'failed to get {url}')
return _html
userid = 258
itemid = 25913
total_score, top_contributions, _ = model.explain(userid=userid, user_items=user_likes, itemid=itemid)
_html = create_explanation_thumbnails_html(itemid, top_contributions)
HTML(_html)

このユーザー(userid = 258)には Tyrannosaurus Rex が推薦されていました。これは、Liopleurodon Ferox や Brachiosaurus などのアイテムを評価していたことが理由であると判りました。
さいごに
さて、今回は前回の Blog で紹介したユーザーの明示的なアイテム評価(Explicit Feedback)に基づく推奨の展開として、暗黙的な反応(Implicit Feedback)によるアイテム推奨のアルゴリズムの解説と Sketchfab のデータを scraping しながら 3D model 推奨を実践しました。このように具体的なアイテムを使ってみると理解しやすいです。Alternative Least Square で解説したように推薦システムの数理モデルは中々に奥が深い世界で、さらに深ぼってみたいです。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
参考資料
- Yifan Hu, Yehuda Koren, Chris Volinsky, “Collaborative Filtering for Implicit Feedback Datasets“
- Doris Xin, Nicolas Mayoraz, Hubert Pham, Karthik Lakshmanan, and John R. Anderson, “Folding: Why Good Models Sometimes Make Spurious Recommendations”, RecSys ’17.
- Implicit Feedback のレビュー Steffen Rendle, “Item Recommendation from Implicit Feedback”, arXiv:2101.08769 (https://arxiv.org/abs/2101.08769).
- Implicit (https://github.com/benfred/implicit
- 神嶌敏弘、[推奨システムのアルゴリズム](https://github.com/tkamishima/recsysdoc)
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD