2024.03.11
Stable Diffusion 3: Stability AIの最新生成AIの技術解説
Multimodal Diffusion Transformer & Rectified Flow
TL;DR
- Stability AIが2024/02/22に、新たなStable Diffusion 3のリリースを発表しましたが、early preview版で一般では利用できず、技術詳細も概要のみで詳細は不明でした。2024/03/05にStability AIは、ついにStable Diffusion 3のResearch Paperを公開しました。なお、Stable Diffusion 3のモデル自体は未公開のためまだ利用できません。
- Stable Diffusion 3は、Multimodal Diffusion Transformer (MMDiT)とRectified Flowという生成技術を核としたモデルです。
- MMDiTでは、テキストと画像の2つのモダリティを扱うため2つのTransformerがAttentionを共有しつつ並列するモデル構造を持っています。更に、プロンプトも2つのCLIPモデルと1つのT5モデルの計3つのエンコーダーを使って処理されます。これらの工夫によりStable Diffusion 3は、画像の生成においてテキスト表現が大幅に改善されています。
- Rectified Flowは、従来のDiffusion modelでのノイズからデータを生成する手法ではなく、フロー・マッチングというフロー・ベース生成AI技術を応用した手法です。既存の手法よりも効率的な画像生成が期待されており、実際にStable Diffusion 3の実験ではモデルサイズ・訓練などを大規模化するほど性能改善(Scaling law)が見られています。
- これらの新技術の導入によりStable Diffusion 3は、DALLE-3などの他の画像生成モデルと比較して、テキスト表現において大きくリードした結果となっています。
(注)rectify: 整流する、調整するの意

なお、時系列としてはこのようになっております。(なんと慌ただしいことでしょう)
- 2024/02/12(Tue) Stable Cascade の公開「Introducing Stable Cascade」
- 2024/02/22(Thu) Stable Diffusion 3 の発表「Stable Diffusion 3」
- 2024/03/05(Tue) Stable Diffusion 3のResearch Paperの公開「Stable Diffusion 3: Research Paper」
はじめに
こんにちは、グループ研究開発本部・AI研究室のT.I.です。また、お前かと思われるかもしれませんが、以下略。
さて、先日の2/22(Thu)に発表されたStability AIの最新の画像生成AI「Stable Diffusion 3」ですが、技術要素について Diffusion Transformerを使っていることは公表されていましたが、詳細は不明なままでした。それが、ついに3/5(Tue)にResearch Paperが公開され、詳細が明らかになりました。今回のBlogでは、Stable Diffusion 3の技術的な要素について解説します。
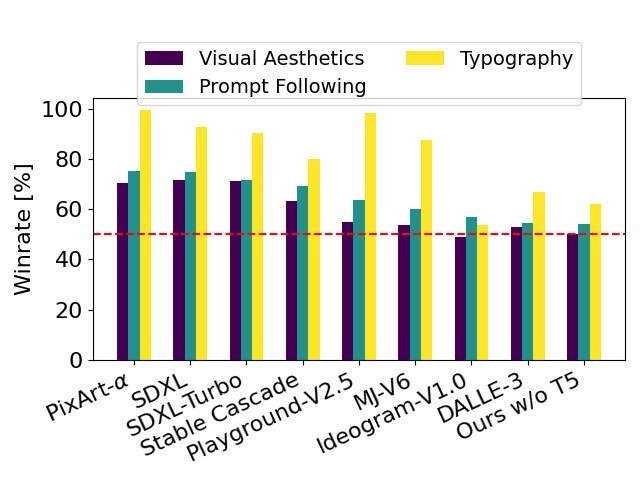
まず、Stable Diffusion 3と他のモデルとの性能の比較を紹介します。以下は、生成されたイラストの品質(visual aesthetics)、プロンプトに対する忠実度(prompt following)、そしてテキスト表現(typography)をStable Diffusion 3のイラストと比較した勝率です。特にTypographyの部分でStable Diffusion 3は他のモデルを圧倒しています。DALLE-3(右から2つ目)に対しては、イラストの品質やプロンプトへの忠実度についてはほぼ同じですが、テキスト表現では10 point程度の差で勝ります。
後ほど解説しますが、Research paperで公開されていたStable Diffusion 3のイラストとプロンプトを参考に前回のBlogで紹介したStable Cascadeでイラストを生成して比較した結果が以下となります。シンプルな単語に関してはStable Cascadeでも表現可能ですが、複雑なテキストでは正確に生成することが難しく、Stable Diffusion 3の表現の高さがわかります。

なお、Stable Diffusion 3は800Mから8B parameterまでの複数のモデルがありますが、最大のモデルの場合では、24GB VRAMをもつRTX 4090で1024×1024の画像の生成が34秒で実行可能だそうです。
Stable Diffusion 3の概要
Multimodal Diffusion Transformer (MMDiT)
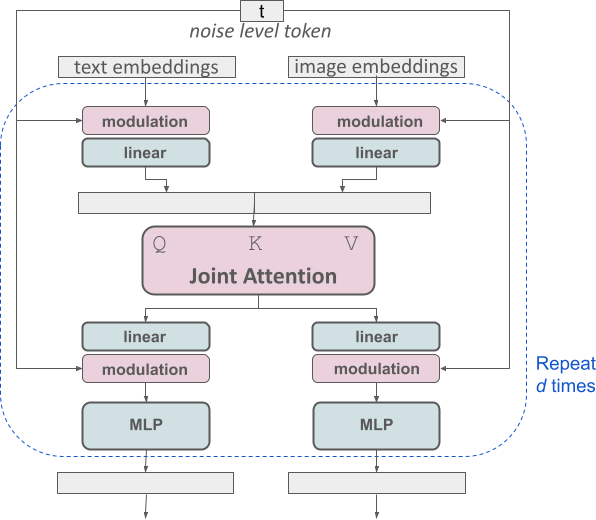
Stable Diffusion 3の最大の特徴が Multimodal Diffusion Transformer (MMDiT) です。従来は画像生成において、U-Net(CNN)を使っていましたが、OpenAI Soraと同様にTransformer-based modelへ移行しています。更にただのTransformerではなく、MMDiTというテキストと画像という2つのモダリティを扱うためのモデルを採用しています。これは、画像用とテキスト用の2つのTransformerが並列し、Attentionの部分で共通の情報を共有するという構造になっています。
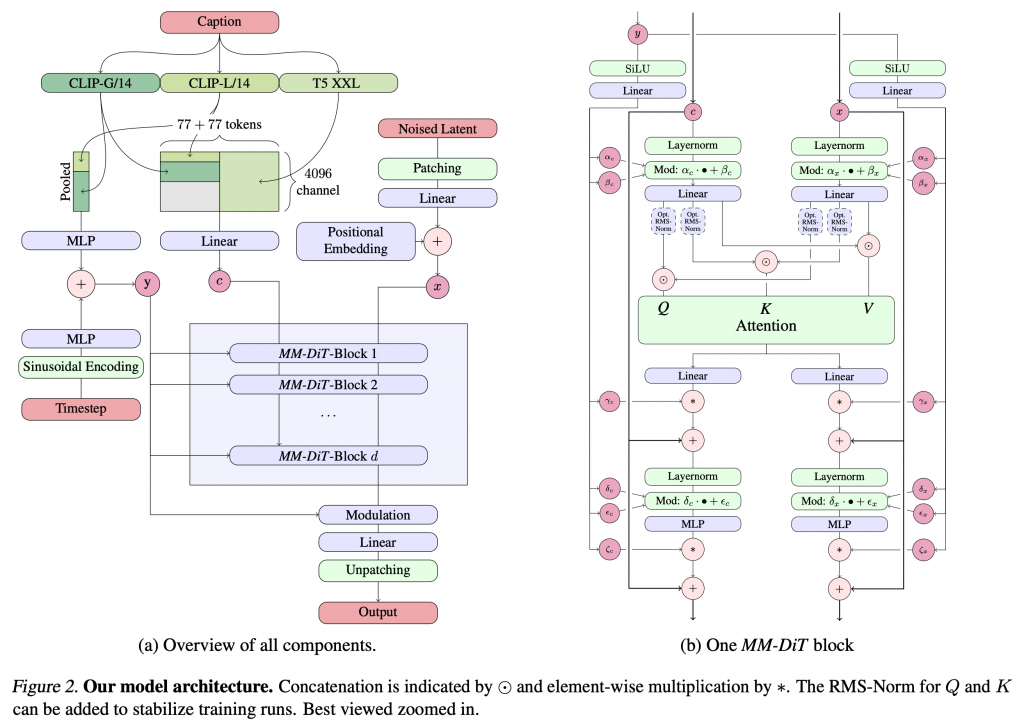
Stable Diffusion 3の全体像の詳細は以下のようになっています。左側は全体のデータの流れを示しており、右側がMMDiT blockの詳細です。まず、入力されたプロンプト(Caption)の処理も工夫されております。通常はプロンプトを1つのモデルでエンコードして画像生成の指示に利用していますが、Stable Diffusion 3では、CLIP-G/14とCLIP-L/14、そしてT5 XXLという3つのモデルを使ってエンコードした結果を結合して画像生成の指示に利用しています。
Rectified Flow: Flow-based generative model
さて、モデル構造も大きく変わりましたが、画像生成のプロセスもこれまで拡散モデルではなく、フロー・マッチングに基づいたRectified Flowというフロー・ベース生成モデルを使っています。拡散モデルとは、以前のBlog(StreamDiffusionの紹介 https://recruit.gmo.jp/engineer/jisedai/blog/streamdiffusion/)で解説したように画像にノイズを加える過程(拡散過程)を逆方向に進めることでノイズから画像を生成する技術です。巷で生成AI、生成AIとバズワード化していますが、生成AIと言っても、そのアルゴリズムは様々です。あまり耳慣れないかもしれませんが、フロー・ベース生成モデルという別の生成手法も研究されています (参考書:岡野原大輔著「ディープラーニングを支える技術2」 Amazon link)。
フロー・ベース生成モデルとは、データを生成する分布\(p(x)\)を変換していき、目的のデータ分布を得ることで生成する手法です。まず、その基礎となるのは、正規化フロー(Normalizing flow)で下記のような単純な分布\(p_0(z_0)\)を順々に変換し複雑な分布\(p_K(z_K)\)を得る手法です。
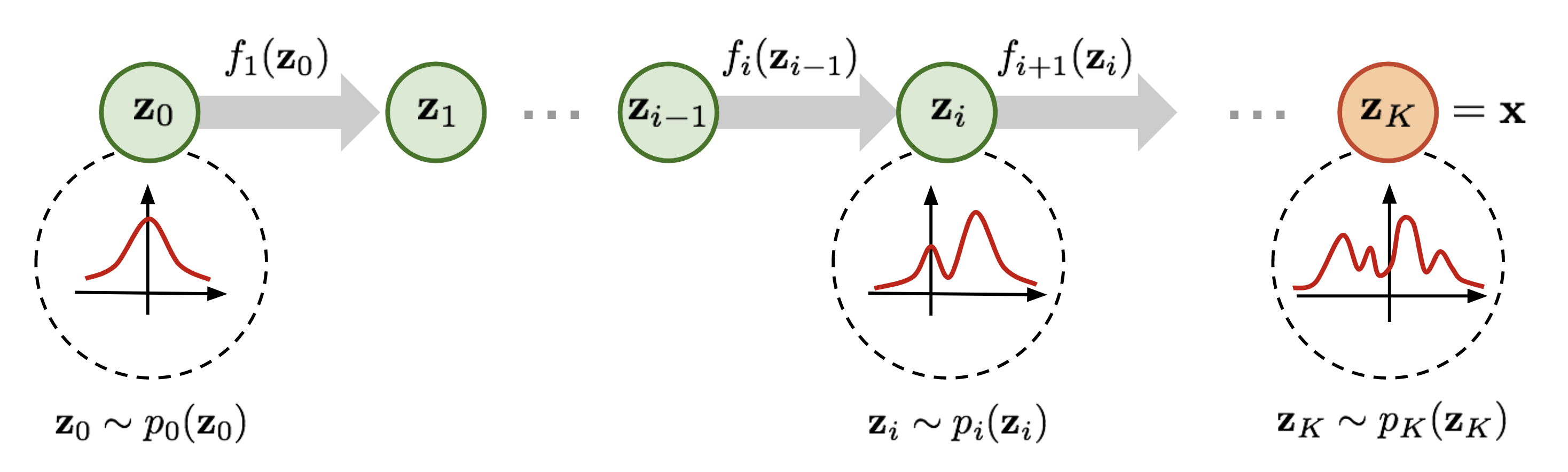
この正規化フローを連続的な時刻(\(t\))での変換に拡張したものがContinuous Normalizing Flow (CNF)で、時刻 \(t\) におけるデータ \(x\) のベクトル \(v_t(t)\) に関する以下の常微分方程式で表現されます。しかし、この手法では計算コストが高いという問題がありました。
$$
\frac{d}{dt}\phi_t(x) = v_t(\phi_t(x))
$$
$$
\phi_0(x) = x
$$
CNFを改良した手法が、フロー・マッチング(FM)です。これはフローの各時刻での条件付きフローを学習するもので、目標分布を生み出しているベクトル場 \(u_t(x)\) に合わせるようにします。
$$
\mathcal{L}_\mathrm{FM}(\theta) = \mathbb{E}_{t, p_t(x)}||v_t(x) – u_t(x)||^2
$$
しかし、この手法にも計算上の問題があるため、それを工夫したconditional flow matching (CFM)が提案されています。
$$
\mathcal{L}_\mathrm{CFM}(\theta) = \mathbb{E}_{t, q(x_1), p_t(x|x_1)}||v_t(x) – u_t(x|x_1)||^2
$$
2つの分布を結びつけるフローには様々なタイプを考えることができます。Stable Diffusion 3では、いくつかの候補を試した結果「Rectified Flow」を採用しています。 Rectified Flowとは、データの分布と正規分布を線形に結びつけるフロー(\(z_t = (1-t)x_0 + t\varepsilon\))というシンプルなものです。Stable Diffusion 3では、これにsamplingの際の途中のステップの重み付けを補正して利用しています。

Stable Diffusion 3のモデルサイズと学習ステップによる性能評価が以下の図です。上段は画像・ビデオのデータについてモデルサイズ、訓練ステップ数ごとのValidation lossの比較であり、モデルサイズ(depth)が大きく、訓練ステップ数を増やすほど誤差が減少することがわかります。特にTraining FLOPsで比較すると、飽和することなく精度が改善しており、LLMで報告されているいわゆるscaling lawが見られます。また、下段は、Validation lossと各種性能比較指標の比較です。Validation lossを下げることで性能が向上していることがわかります。
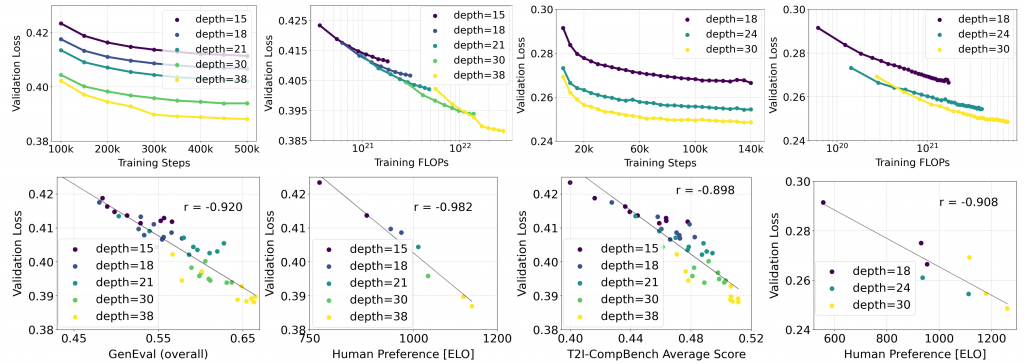
この図は、モデルのサイズを大きくしてトレーニングするほどに各種性能指標が改善することを示しております。その性能改善には、限界が見えておらず将来的に更に大規模化することで、更なる性能向上が期待されます。Research Paperのタイトルも「Scaling Rectified Flow Transformers for High-Resolution Image Synthesis」となっており、その観点からの期待感も伺うことができます。
Stable Diffusion 3とStable Cascadeのテキスト表現性能の比較
さて、最後に実際にStable Diffusion 3の性能がどの程度のものなのかを実験してみます。しかし、Stable Diffusion 3自体は、まだ公開されていません。そこでResearch Paperなどで公開されているイラストとプロンプトを参考に、Stable Diffusion XLよりも高性能のStable Cascadeを使った生成イラストと比較してみます。Stable Cascadeについては、前回のBlog同様に公開されている最大のモデル(Stage C Large & Stage B Large)を使用し1920×1080のサイズで出力、プロンプトのみでネガティブ・プロンプトはなし、それぞれ100枚ずつ生成して適当に良さそうなものを4枚選択しています。

A surreal and humorous scene in a classroom with a words “GPUs go brrrrrr” written in white chalk on a blackboard. In front of the blackboard, a group of students are celebrating. These students are uniquely depicted as avocados, complete with little arms and legs, and faces showing expressions of joy and excitement. The scene captures a playful and imaginative atmosphere, blending the concept of a traditional classroom with the whimsical portrayal of avocado students.
(DeepLによる訳)黒板に白いチョークで「GPUs go brrrrrr」と書かれた教室でのシュールでユーモラスなシーン。黒板の前では、生徒たちが祝っている。生徒たちはアボカドに見立てられ、小さな手足と喜びと興奮の表情を浮かべている。このシーンは、伝統的な教室のコンセプトとアボカドの生徒たちの気まぐれな描写を融合させ、遊び心と想像力にあふれた雰囲気をとらえている。
さて、これと同じプロンプトをStable Cascadeで生成してみました。結果は以下の通りです。

なかなか、”GPUs go brrrrrr”というテキストの表現が難しいです。GPUsではなく、GUSになったり、brrrrrもbrrnとかbrrinになったりと、ほとんどの場合、不正確なテキストで表現されてしまっています。100枚ほど生成して実験してみましたが、よくできたイラストであってもこのような感じです。また、生徒をアボガド化するキャラクターの表現も難しく良くできて黒板に書かれたキャラクターで殆どの場合は普通の生徒が描写されてしまっています。あと、この画像では、縮小しているためあまり目立ちませんが、実際に生成した画像は変に波打ったようなエフェクトがかかっており、生徒やこれらのキャラクターがかなり気持ち悪いものになってしまっています。
では、次の実験です。

Frog sitting in a 1950s diner wearing a leather jacket and a top hat. on the table is a giant burger and a small sign that says “froggy fridays”
(DeepLによる訳)1950年代のダイナーで、レザージャケットにトップハットをかぶって座っているカエル。テーブルの上には巨大なハンバーガーと、”Froggy fridays “と書かれた小さな看板。
これと同じプロンプトをStable Cascadeで生成してみました。結果は以下の通りです。

先ほどのアボガドのイラストとは違って、テキストの表現はStable Cascadeでもそれなりに表現できています。これは、”GPus go brrrrr”という文字列が特殊なものに比べて、看板としてFroggyやFridaysという一般的な文字列なことと、プロンプトもシンプルで複雑ではないこともStable Diffusion 3との差があまりないことの要因と思われます。
では、最後に次のイラストです。

Beautiful pixel art of a Wizard with hovering text “Achievement unlocked: Diffusion models can spell now”
(DeepLによる訳)魔法使いの美しいピクセルアートとホバリングテキスト「Achievement unlocked: 拡散モデルが呪文を唱えられるようになった。」
Stable Cascadeで同じプロンプトで生成すると以下のようになりました。

ドット絵のイラストに関しては、まあまあの出来なのですが、単語が長くて複雑だからなのか、”Achievement”の時点でかなり怪しい文字列ばかりです。これでもある程度意味のがとれた文字列が出たイラストをチョイスしていますが、Stable Diffusion 3との差は歴然です。
まとめ
さて、Stability AIの最新の画像生成AIであるStable Diffusion 3について解説しました。Stable Cascadeが公開された直後の発表でしたが、その性能はStable Cascadeを上回るものとなっています。モデルは従来のノイズ除許の拡散モデルではなく、フロー・マッチングを使ったRectified Flowという生成技術を使っています。また、その根幹もMultimodal Diffusion Transformer (MMDiT)という画像とテキストの2つのモダリティを扱うモデルとなっています。その結果として、従来の画像生成AIの苦手とするテキストの表現が大幅に改良されております。実験として、Stable Cascadeと比較してみましたが、やはりテキストの表現には苦戦されることが多くStable Diffusion 3の正確な表現はすごいですね(ただし、何事も100%という訳ではなく、Research paperの例を見ると”COFFE”になっていたりする失敗例もありますので、実際に動かしてみてどの程度の正解率か試してみたいです)。
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
- Stability AI “Stable Diffusion 3” https://stability.ai/news/stable-diffusion-3
- Stability AI “Stable Diffusion 3: Research Paper” https://stability.ai/news/stable-diffusion-3-research-paper
- Scaling Rectified Flow Transformers for High-Resolution Images Synthesis https://arxiv.org/abs/2403.03206
- Flow-based modelに関する参考資料
- Flow-based Deep Generative Models https://lilianweng.github.io/posts/2018-10-13-flow-models/
- Flow Matching for Generative Modeling https://arxiv.org/abs/2210.02747
- Rectified Flow https://github.com/gnobitab/RectifiedFlow
- Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow https://arxiv.org/abs/2209.03003
- Flowベース生成モデルの調査 https://zenn.dev/d2c_mtech_blog/articles/6bd54c0db73a8e
- フローマッチング:非拡散モデルによる生成 https://xtech.nikkei.com/atcl/nxt/mag/rob/18/00007/00060/
- Optimal Transport Conditional Flow Matching – 拡散モデルに取って代わる次世代の生産技術? https://zenn.dev/fusic/articles/ml-flow-matching
- 岡野原大輔著「ディープラーニングを支える技術2」 Amazon link
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD