2024.01.15
100 fps超え!?超高速画像生成AI StreamDiffusion
TL;DR
- 2023/12/19にStreamDiffusionという画像生成モデルがリリースされました。拡散モデルによる画像生成のパイプラインを最適化し、Latent Consistency Model(LCM)やAdversarial Diffusion Distillation(ADD)という高速画像生成技術を利用することで、100 fpsを超える高速な画像生成が可能です(注: GeForce RTX 4090を利用した場合)
- 生成過程を近似する技術を利用しているため画像の品質にはやや懸念がありますが、リアルタイムの画像変換や動画生成などへの利用が期待されます
はじめに
こんにちは、グループ研究開発本部・AI研究室のT.I.です。昨今の生成AIの発展は著しいものがあり、そのスピードに追いつくのがなかなか大変です。先日(2023/12/19)にStreamDiffusion(https://arxiv.org/abs/2312.12491)というモデルがリリースされました。StreamDiffusionは論文のタイトル「StreamDiffusion: A Pipeline-Level Solution for Real-Time Interactive Generation」とある様に複数の高速化技術を組み合わせるフレームワークです。その結果、100 fpsを超える驚異的な速度で画像の生成が可能です。技術的に興味深かったので今回のBlogでは、どのようにこれほどの高速画像生成を実現しているのか、その仕組みについて解説します(早く記事にまとめないと陳腐化してしまう…)。
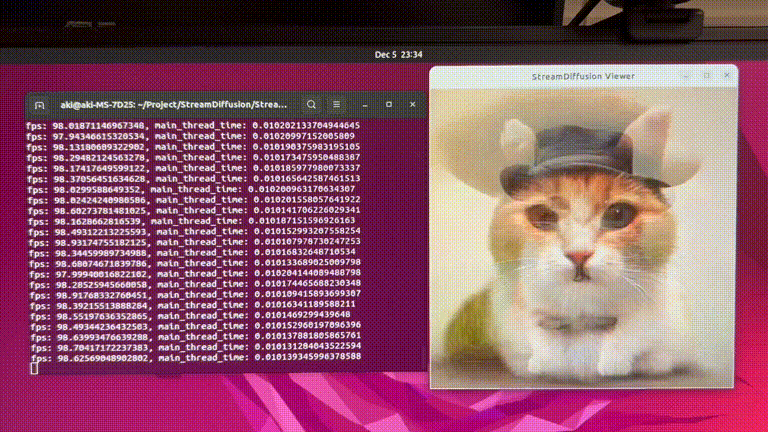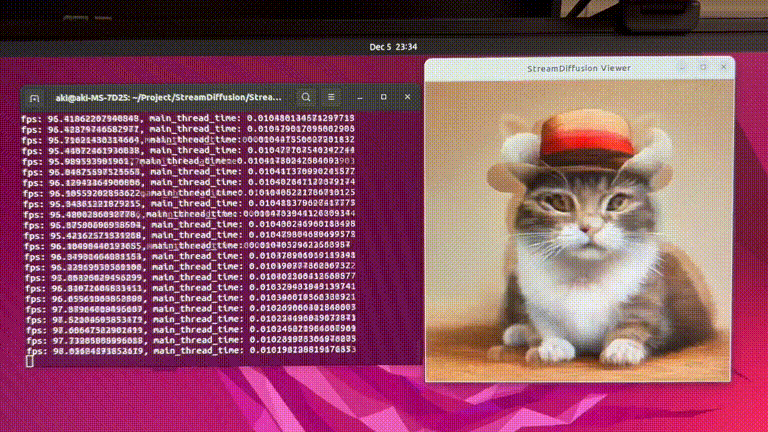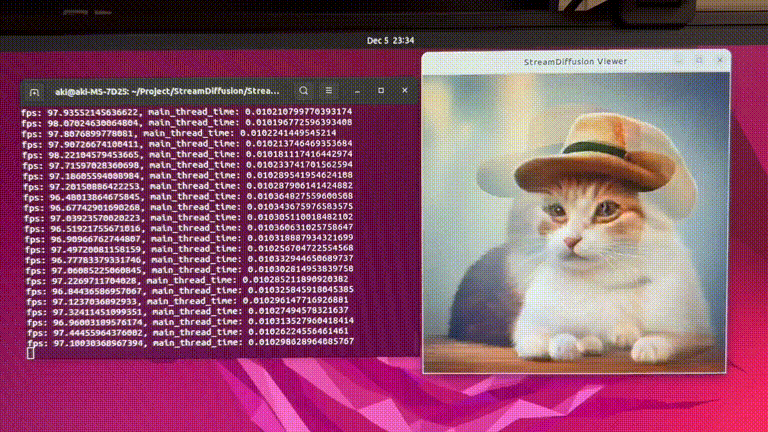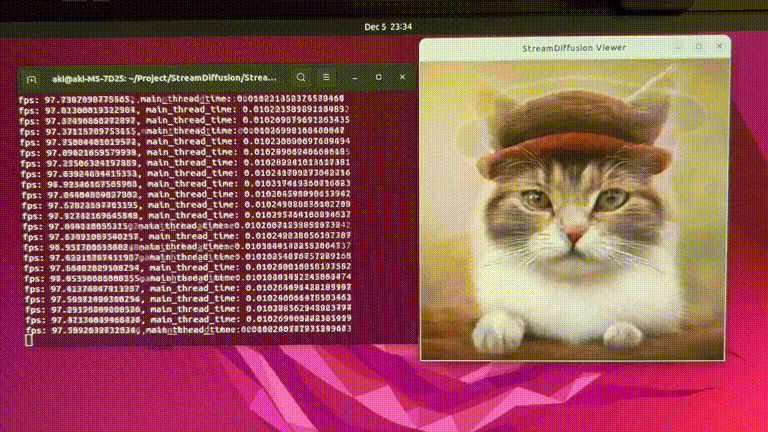
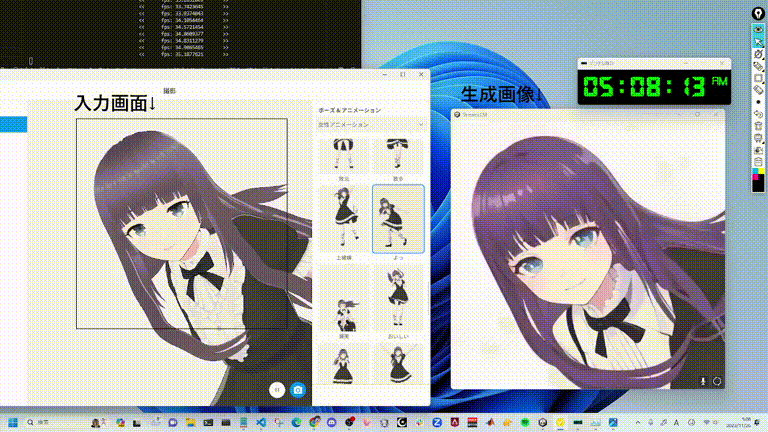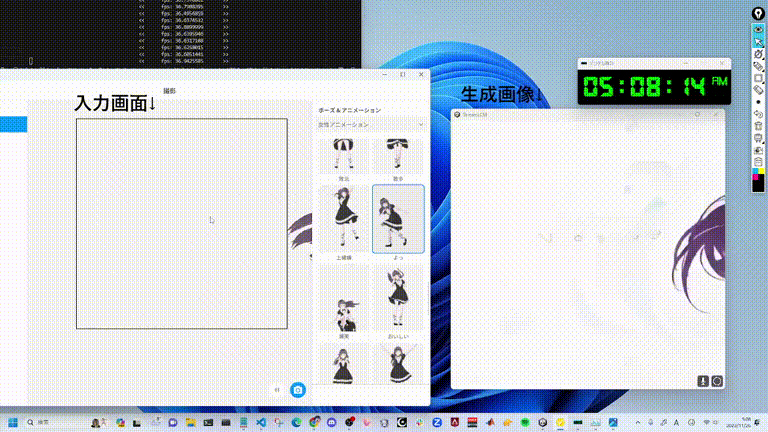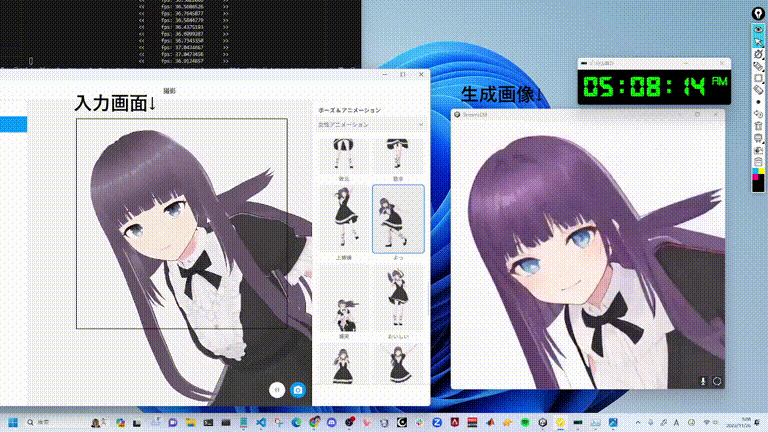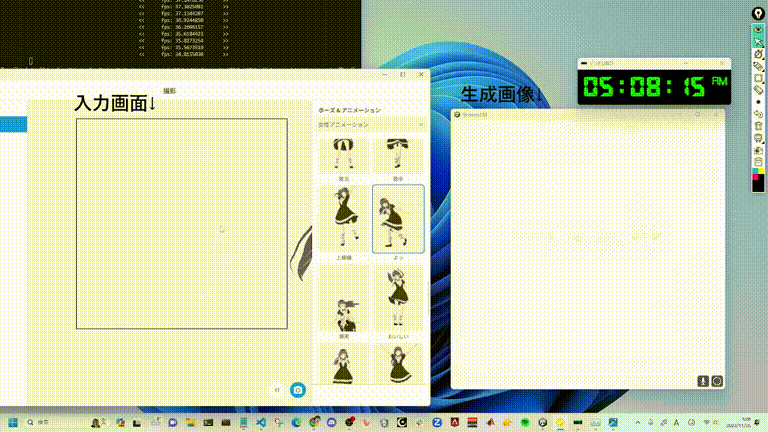
GitHub(https://github.com/cumulo-autumn/StreamDiffusion)で公開されているStreamDiffusionのデモ動画。もはや生成スピードが早すぎて何が起きているのかわからないですね。
生成速度は以下の通りになります。ここでSD-turboはADDを利用した場合、LCM-LoRA + KohakuV2は、KohakuV2というベースモデルに対してLCM-LoRAを利用した場合です。詳細は後程解説しますが、比較にする際には前者は1ステップ、後者は4ステップのDenoising Processで画像を生成している点に注意してください。(なお、KohakuV2自体はStable Diffusion 1.5を特定の画像スタイルにファインチューニングしたモデル(checkpoint)で高速化とは無関係です。)
StreamDiffusionの速度のまとめ(GitHubの表の数値より作成)
(注) 論文では、image-to-imageで、91.07 fpsを達成したと記載されていますが、GitHubの記載では93.897 fpsとなっています。text-to-imageでは、100 fpsすら超えています。
Stable Diffusionの画像生成の仕組み
StreamDiffusionの解説の前に、そもそもStable Diffusion(Latent Diffusion Models)がどうやって画像を生成しているのか簡単に説明します。まず、重要な要素は以下の3つです。(注:学習時のプロセスについては、今回は割愛します。)
- Denoising Process (U-Net)
- Text Encoder (CLIP)
- VAE (Variational Autoencoder)
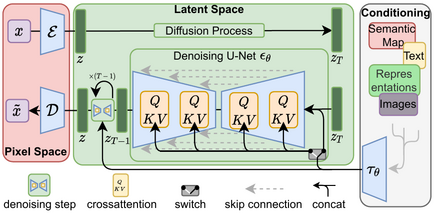
Stable Diffusionの構造(図はStable Diffusionの論文 https://arxiv.org/abs/2112.10752 より引用)
Denoising Process (逆拡散過程)
同じ生成AIという区分ですが、画像生成AIとGPTのような文章生成AIの仕組みは大きく異なります。ほんのひと昔前まで、画像生成というと、GAN(Generative Adversarial Network)という仕組みが中心でした。しかし、Denoising Diffusion Probabilistic Model (DDPM)という手法が考案され状況は大きく変わりました。DDPMは、データにノイズを加える過程を学習し、逆にノイズからデータを復元していく過程を実行するアルゴリズムです。Stable Diffusionでは、これまで画像認識タスクに利用されていたU-Netという深層学習モデルの構造を利用し、このプロセスを実行しています。拡散モデルの理論面について詳しく興味がありましたら「拡散モデルデータ生成技術の数理」 (https://www.iwanami.co.jp/book/b619864.html)がおすすめです。
以下の図はDenoising stepsを徐々に増やした場合の画像の例です。見てわかる様に最初はぼんやりとサイケデリックな感じですが、徐々に輪郭がハッキリとしてきます。ステップ数が一定以上になるほど、解像度が上がっています。ただし、途中で髪の色や背景が変わるなど、ステップ数を増やすほど安定するというわけでもありません。(Sampling methodとしてDPM++2M SDE Karrasを利用)

Denoising stepsによる画像生成の例
Text Encoder (CLIP)
さて、ノイズから画像が生成できるのは良いのですが、そもそもどうやって生成する画像を制御すればよいかという問題があります。そこで利用されるモデルがCLIP(Contrastive Language-Image Pre-Training)というモデルで、これは画像と文章を同時に学習するモデルです。これを利用することで、文章と画像を結びつけることができ、その結果、プロンプトの指示で画像が生成ができます。

画像生成時に、U-NetによるDenoising Processの中でText Encoderで埋め込まれた表現がCross attention によって追加されます。これにより、生成される画像の方向性を決定します。
VAE (Variational Autoencoder)
そして、VAEの役割について補足します。まず、U-Netの処理では、通常の画像をそのまま扱うのではなく、EncoderでLatent Space(潜在空間)という、より低次元に圧縮された形式に変換して処理しています。VAEは入力をLatent Spaceに圧縮し、Decoderで元の画像に戻す機構です。このLatent Spaceでの処理を通じてより高速・高精度の画像生成が可能となります。以下は、Wikipediaより引用したVAEの概念図です。Latent Spaceの変数(潜在変数)は、一般的にガウシアンの分布に従うと仮定します。

By EugenioTL – Own work, CC BY-SA 4.0, Link
逆拡散過程の高速化技術
先ほど紹介したように逆拡散過程によるノイズ除去が画像生成に不可欠な要素です。しかしながら、この過程は、多くの計算ステップが必要で、画像生成の速度を遅くするボトルネックとなります。その高速化のために昨年末に「Latent Consistency Model (LCM)」や「SDXL Turbo」というモデルが相次いで発表されました。これらは、少ないステップ数で画像を生成する技術です。 StreamDiffusionもこれらの高速化技術を利用しています。まず、これらのモデルについて解説します。
Latent Consistency Model
Latent Consistency Model (LCM) (https://latent-consistency-models.github.io/) は、2023/10/06に発表された技術で、Stable Diffusionの生成スピードを大幅に改善することに成功しました。元々は、2023年の3月に発表された、Consistency Modelsを改良したものです。これは、通常は20ステップほど必要なDenoising Processを、わずか数ステップに短縮可能です。
まず、Consistency function \(f\)を導入します。
\[
f: (x_t, t) \rightarrow x_\varepsilon
\]
ここで、\((x_t, t)\)は\(t\)でのデータ、\(\varepsilon\)は小さな数値です。これは、任意の時刻から\(\varepsilon\)の時刻のデータに一気に変換する関数です。以下の図は、この関数のイメージです。通常、徐々にステップを重ねてノイズからデータを生成するわけですが、このような関数があれば、一気にデータを生成することが可能になります。

Consistency functionのイメージ(図はConsistency Modelsの論文より引用)
さて、そのような都合の良いConsistency functionなんてあるのか?と思われるかもしれません。それを以下のように近似して、ベースとなるモデルから学習するのがConsistency Modelsです。
\[
f_\theta(x,t) = \begin{cases}
x & t = \varepsilon \\
F_\theta(x,t) & t \in (\varepsilon, T]
\end{cases}
\]
ここで、\(F_\theta\)は、Deep Learningのモデルで、\(\theta\)はそのパラメータです。このパラメータを既存のモデルを近似するように学習(蒸留)し、少ないステップ数での生成が可能となります。Consistency ModelsをLatent spaceに拡張したものがLatent Consistency Models(LCM)です。
LCMはモデル毎に学習(Consistency Distillation)する必要があります。その後、LoRA(Low-Rank Adaptation of Large Language Models)を使うことで、様々なベースモデルに対してLCMを適用できるようになりました。このLCM-LoRA(https://arxiv.org/abs/2311.05556)を利用してStreamDiffusionは数ステップでの画像生成を実現しています。
Adversarial Diffusion Distillation (ADD)
SDXL Turboは、Stability.aiが2023/11/28に発表したモデルです。これはConsistency Modelではなく、Adversarial Diffusion Distillation (ADD)というアルゴリズムを利用して元となるモデルの生成過程を近似します。その性能はわずか1ステップでも十分な画像を生成することが可能です。以下の図は、ADDの概念図となります。
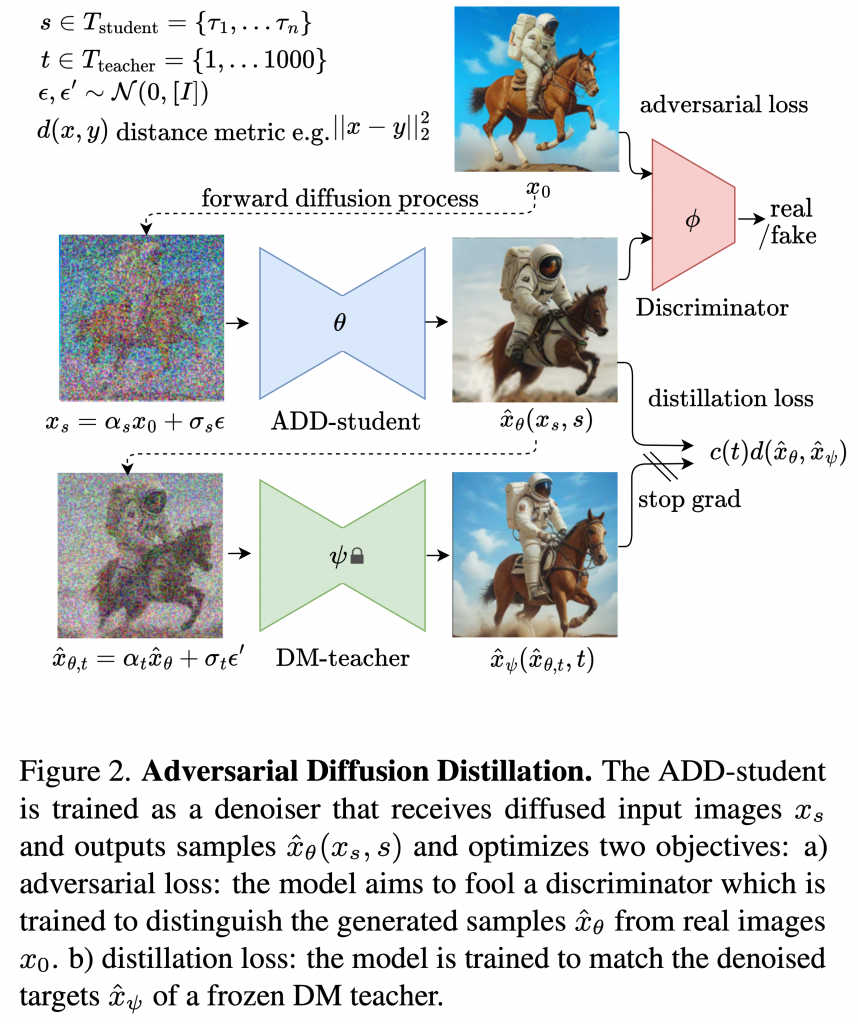
Adversarial Diffusion Distillationのイメージ(図はSDXL Turboの論文より引用)
ADDは以下の3つの構成要素からなります。
- ADD-student: ノイズの入った画像(\(x_s\))からノイズを除去して画像を生成\(\hat{x}_\theta(x_s,s)\)
- Discriminator: ADD-studentが生成した画像が本物か偽物か判定
- DM(Diffusion Model)-teacher: ADD-studentの生成画像にノイズを加えたもの(\(\hat{x}_{\theta,t}\))を入力に、ノイズを除去し画像を生成(\(\hat{x}_\psi(\hat{x}_{\theta,t},t)\))
DM-teacherは模倣すべき元のモデルでパラメータ \(\psi\) は固定しておきます。学習ではADD-student(パラメータ \(\theta\))とDiscriminator(パラメータ \(\phi\) 論文ではVision Transformerを利用)を最適化します。その際に2種類の損失関数を利用します。1つ目が、adversarial lossです。これは、DiscriminatorがADD-studentの生成画像を本物か否か判定する精度です。2つ目が、distillation lossです、これはADD-studentの生成結果がDMM-teacherと似ているかの指標となります。Distillation lossに関して重み(\(\lambda\))を加えて全体の損失関数は下記の通りです。
\[
\mathcal{L} = \mathcal{L}_\mathrm{adv}^\mathrm{G}(\hat{x}_\theta(x_s, s), \phi) + \lambda \mathcal{L}_\mathrm{distill}(\hat{x}_\theta(x_s, s), \psi)
\]
このようにしてSDXL 1.0を元に学習し蒸留されたモデルがSDXL Turboとなります。Stable Diffusion 2.1を同様に蒸留したSD Turboというモデルもありますが、画像の品質についてはSDXL Turboの方が優れているようです(https://huggingface.co/stabilityai/sd-turbo)。
StreamDiffusionは、このADDで上流されたモデルを利用することも可能です。その場合、LCM-LoRAよりもさらに高速に画像生成できます。
StreamDiffusionのメカニズム
さて、いよいよStreamDiffusionについて解説します。先ほど紹介したLCMやADDで生成に必要なステップを減らした上に、StreamDiffusionでは、以下の様な処理のパイプラインを構築して全体の画像生成速度を高速化しています。
- Stream Batch
- Residual Classifier-Free Guidance (RCFG)
- Stochastic Similarity Filter
- IO queueの最適化
- Pre-computationの最適化
- Modelの高速化する技術の利用
StreamDiffusionの高速化技術の1つがStream Batchです。動画のような連続した画像を入力する場合、通常は1枚の画像の処理の完了を待ってから次の画像を入力します。この処理を並列化して、入力した画像のDenoising Stepが完全に終わる前に、1ステップ毎に次の画像を順次入力して処理することで、その処理を待つステップを高速化できます。
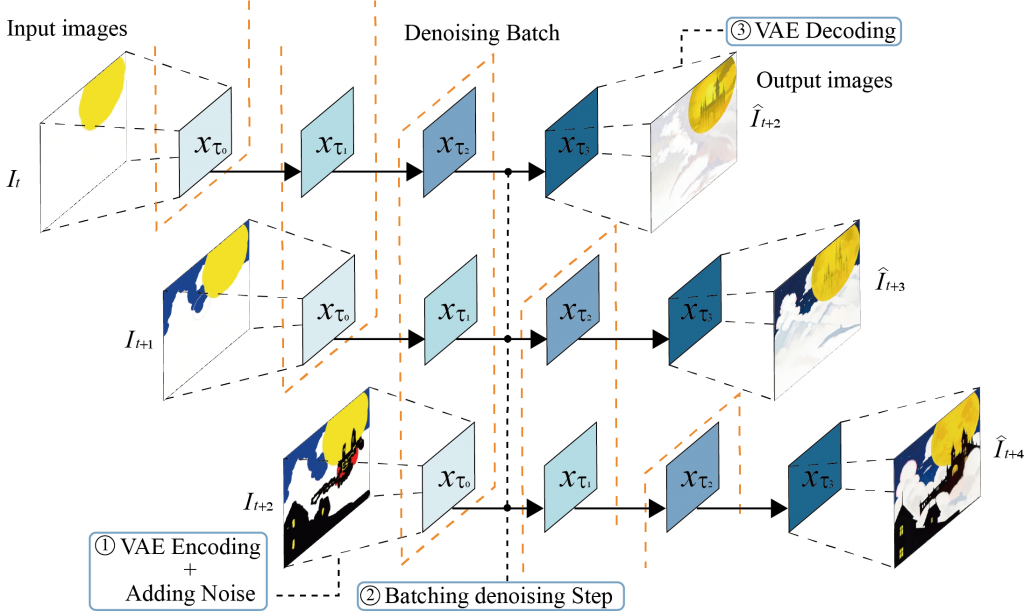
Stream Batchの概念図(図はStreamDiffusionの論文より引用)
次に、Residual Classifier-Free Guidance(RCFG)です。これはStreamDiffusionが採用している画像がよりプロンプトに忠実になるようにする技術です。RCFGは、一般的に利用されているClassifier-free guidance(CFG)というアルゴリズムを改良し、より高速に画像生成を行うことができます。逆拡散プロセスでは、機械学習モデルが除去すべきノイズを予測します。CFGでは、その際にプロンプトに従うようにCFGでは以下の量を計算します。
\[
\epsilon_{\tau_i, \mathrm{cfg}} = \epsilon_{\tau_i, \bar{c}} + \gamma (\epsilon_{\tau_i, c} – \epsilon_{\tau_i, \bar{c}})
\]
ここで、\(\epsilon_{\tau_i, c}\)と\(\epsilon_{\tau_i, \bar{c}}\)は、それぞれ、condition \(c\)とnegative condition \(\bar{c}\)を入力して予測されたノイズです。\(\gamma\)はguidance scaleというパラメータで、これが強いほど入力されたプロンプトの情報が反映されます。これらの計算では、\(c\)と\(\bar{c}\)に対して、それぞれU-Netでの計算が必要になります。StreamDiffusionのRCFGでは、virtual negative condition embedding \(\bar{c}^\prime\)という概念を導入し、\(\bar{c}\)に関する計算を近似・省略しています。結果的に、元々は\(2n\)回のステップが必要だったU-Netの処理をSelf-Negative RCFGでは\(n\)回のステップで済ませることができます。また、Onetime-Negative RCFGの場合では、\(n+1\)回のステップとなります。
CFGやRCFGを使ってimg2imgで画像を処理した結果の例が以下の通りです。CFGを利用しない場合、あまり入力したプロンプトの内容を反映できていません。CFG、RCFGと比較すると、徐々にプロンプトの内容が色濃く反映されていることがわかります。

CFGとRCFGの比較(図はStreamDiffusionの論文より引用)
次に、Stochastic Similarity Filterです。これは入力される画像が変化しない場合に、不要な処理をスキップする技術です。そのために、画像の類似度(cosine similarity)を計算して、閾値を超えた場合には、処理をスキップします。
\[
S_C(I_t, I_\mathrm{ref}) = \frac{I_t \cdot I_{\mathrm{ref}}}{||I_t|| ||I_{\mathrm{ref}}||}
\]
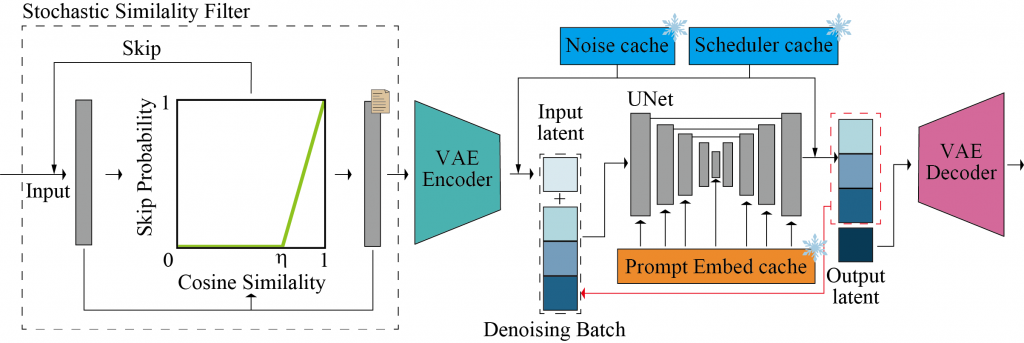
Stochastic Similarity Filterの概念図(図はStreamDiffusionの論文より引用)
また、詳細は割愛しますが、これらの技術に加えて、IO queueの最適化やPre-computationの最適化、NVIDIA TensorRT (https://developer.nvidia.com/tensorrt) も活用して、高速化を図っています。先に紹介したLCM-LoRAやADD(SD-Turbo)と、これらの技術を合わせてパイプライン処理することで、StreamDiffusionは高速な画像生成を可能としています。ImgAutoPipeline Image2Image (huggingface diffuser)の処理と比較するとStreamDiffusionは、平均の推論時間が634.40 msから10.65 msと最大で59.6倍もの高速化(Denoising 1 step)を達成しました。
グラフは論文注の表より作成
また、SSFによる計算効率の改善によりエネルギー消費も大きく削減されます。RTX4090で、2ステップのimg2imgのタスクで20-frameの動画の処理する場合、平均238.68Wから119.77Wと約半分程度になります。
グラフは論文注の表より作成

様々なモデルを使ってtxt2imgを行った結果(図はStreamDiffusionの論文より引用)左上の6つの画像は、それぞれのベースモデル(checkpoint)にLCM-LoRAを適用し4ステップで生成した結果、右下の2つは、SD-Turboを使って1ステップで生成した結果
上の図は、Base model + LCM-LoRA とSD-Turboを利用したStreamDiffusionのイラスト生成例です。SD-Turboは1ステップで生成できる利点があります。一方、LCM-LoRAを使用すると、多様なスタイルに対応するモデル(checkpoint)により、さまざまなイラストを生成できます。なお、この記事(【StreamDiffusion】世界最速!?のスピードで画像を出力する超高速画像生成AIの使い方から実践まで)では、StreamDiffusionとStable Diffusionの生成結果を比較し、StreamDiffusionはアニメなどの画像を追加学習したのかとコメントがあります。しかし、StreamDiffusionは高速化技術であり、特定のデータセット学習したモデルではありませんね。本記事の冒頭で述べた様にイラストのスタイルは単純にkohaku-v2.1というモデルの特性かと思いますが…?
StreamDiffusionを使って画像を生成してみる
さて、StreamDiffusionを実際に使ってみます。GitHubで公開されて以降、Google ColabやLocal GPUで実行したという情報が見られますが、ここではあえてMacで実行してみます。GitHub (https://github.com/cumulo-autumn/StreamDiffusion)で様々なデモコードが公開されていますので、それを使ってみるのもおすすめです。
$ conda create -n streamdiffusion python=3.10 $ conda activate streamdiffusion $ conda install pytorch torchvision -c pytorch $ pip install streamdiffusion
TensorRTやCUDAをMacでは利用できませんが、MPS(Metal Performance Shaders)を使うことで、PyTorchの高速化ができます。使用したMacのスペックは、MacBook ProのApple M1 Maxでメモリーは64GBです。下記で作ったアプリの場合、4枚の画像生成にLCM-LoRAでは約4秒、SD- Turboでは約1.7秒かかりました。また、GitHubで公開されているパフォーマンス測定のコードの場合では、5fps弱でした。参考として、Stable Diffusionで20ステップで生成すると4枚の生成に約33秒ほどです。NVIDIA GeForce RTX 4090の100fpsには遠く及びませんが、StreamDiffusionを使用することで大幅に高速化できました。
なお、実行の際に、CUDAがないとエラーが出たので、ここら辺の時間測定系の処理をコメントアウトしています。(生成時間を集計している箇所みたいですし、問題ないでしょう多分)
start = torch.cuda.Event(enable_timing=True) end = torch.cuda.Event(enable_timing=True)
前回のBlogではStreamlitを使っていましたが、今回はGradio (https://www.gradio.app/)で、アプリを作ってみます。GradioならJupyter Notebookでも起動できたり、処理のフローが分かりやすい利点があります(参考:【Streamlitよりいいかも?】機械学習系のデモアプリ作成に最適!Gradio解説)。Graidioを以下でインストールしておきます。
$ conda install gradio -c conda-forge
以下の動画がGradioで作成したアプリのデモです。下記のpython scriptを実行しするとGradioのアプリが起動します。ブラウザでアクセスしても良いですが、Jupyter Notebook上でも表示・アプリの操作は可能です。PromptとNegative Promptを入力してGenerateボタンを押すと、画像が生成されます。一度に生成する枚数も指定できます。なお、初回の実行時にはGB単位でモデルのダウンロードが必要なので時間がかかります。また、プロンプトを修正した場合、初期化が必要になるので、そこでも若干の時間がかかります。
python scriptは以下です。StreamDiffusionによる画像生成処理の箇所は、GitHubで公開されているサンプルコードを参考にしております。
import gradio as gr
import torch
from diffusers import AutoencoderTiny, StableDiffusionPipeline
from streamdiffusion import StreamDiffusion
from streamdiffusion.image_utils import postprocess_image
def initialize_stream(width=512, height=512, t_index_list=[0, 16, 32, 45], device="mps"):
model_id_or_path = "stablediffusionapi/counterfeit-v30-fp16"
pipe = StableDiffusionPipeline.from_pretrained(model_id_or_path).to(
device=torch.device(device),
dtype=torch.float16,
)
stream = StreamDiffusion(
pipe,
t_index_list=t_index_list,
torch_dtype=torch.float16,
width=width,
height=height,
cfg_type="none",
)
# If the loaded model is not LCM, merge LCM
stream.load_lcm_lora()
stream.fuse_lora()
# Use Tiny VAE for further acceleration
stream.vae = AutoencoderTiny.from_pretrained("madebyollin/taesd").to(device=pipe.device, dtype=pipe.dtype)
# Enable acceleration
# pipe.enable_xformers_memory_efficient_attention()
return stream
def generate_image(prompt, negative_prompt, batch_count, state):
if state["stream"] is None:
stream = initialize_stream()
state["stream"] = stream
else:
stream = state["stream"]
if (state["prompt"] != prompt) or (state["negative_prompt"] != negative_prompt):
stream.prepare(prompt=prompt, negative_prompt=negative_prompt)
for _ in range(4): # warm up
_ = stream()
state["prompt"] = prompt
state["negative_prompt"] = negative_prompt
else:
pass
images = []
for i in range(batch_count):
x_output = stream.txt2img()
images.append(postprocess_image(x_output, output_type="pil")[0])
return images, state
with gr.Blocks() as app:
with gr.Row():
with gr.Column():
prompt = gr.Textbox("girl with panda ears wearing a hood", label="Prompt")
negative_prompt = gr.Textbox("bad image, bad quality, low resolution", label="NegativePrompt")
batch_count = gr.Slider(minimum=1, maximum=256, step=1, value=1, label="Batch Count")
btn = gr.Button("Generate")
with gr.Column():
gallery = gr.Gallery()
state = gr.State({
"stream": None,
"prompt": None,
"negative_prompt": None,
})
btn.click(generate_image, inputs=[prompt, negative_prompt, batch_count, state], outputs=
[gallery, state]
) app.launch()
SD-Turboを使用したい場合は、modelとして"stabilityai/sd-turbo”を指定して、t_index_list=[0]に変更しLoRAの箇所を削除すれば大丈夫です。以下はSD-Turboを利用した画像生成のデモです。1ステップだけで済むので、LCM-LoRAのものよりもかなり高速ですね。
なお、GitHubにあるexamples/optimal-performance/single.pyを実行すると、以下のような結果が得られます。なお、そのままでは、CUDAがないと怒られますので、deviceとしてcudaを指定する箇所をmpsに無理やり書き換えて実行しています。ぎりぎり5 fpsに届かない程度ですが、MacのM1 Maxだけでこれだけの速度が出せるのは驚きです。
まとめ
今回のBlogでは、先月発表されたStreamDiffusionという超高速な画像生成モデルを紹介しました。十分な性能のあるGPUを使えば、100 fpsという速度で画像が生成可能です。リアルタイムの動画の変換など応用が期待されます。振り返ると2022年8月にStability AIがStable Diffusionを発表してから、まだ1年半しか経っていないのに、ここまでの発展を遂げたのは驚きです。
SD-Turboは1ステップでの高速生成が特徴で、その速さは驚異的であります。ただし、より高品質な生成物を求める場合、ステップ数を増やすことが必要なようです。論文では、生成された画像の品質を人間が評価した結果が示されています。SD-TurboよりもSDXL-Turboの方が画像生成の性能は良いのですが、そのSDXL-Turboの場合であっても、1ステップの生成よりも4ステップの方が画質が向上し、与えられたプロンプトに対する忠実度も高まります。しかし、SDXL-Turboと比較するとSDXL 1.0 Baseモデルの方が画質とプロンプトへの忠実性の両方で優れています。

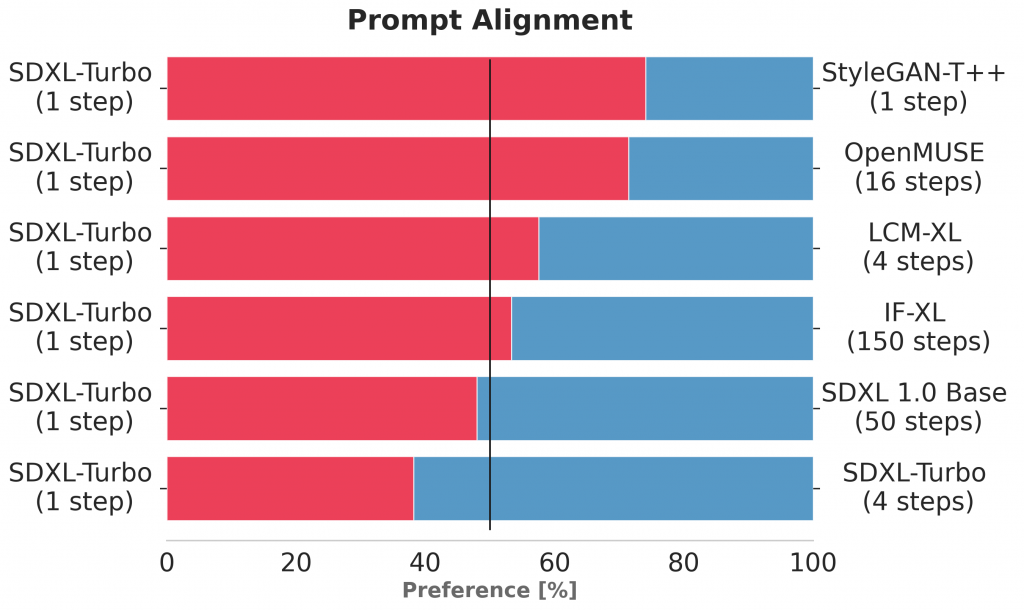
SDXL Turboの生成結果と他のモデルの出力との人による評価の比較(図はSDXL Turboの論文より引用)
先ほどの猫の高速画像生成も、詳しく確認すると以下の様に奇妙な画像が含まれています。確率分布からサンプリングするという画像生成アルゴリズムとして、この種の画像が生成されるのは仕方ないのかもしれません。やはり高速に生成するトレードオフとして画像の品質が落ちるということもあるようです。先ほどの猫の画像も手足の位置や数がおかしいものが一定数含まれています。

高速で生成されるのでつい見落としてしまいますが、よくよく確認するとこの様な名状しがたい猫のようなものが生成されています。
また、SD-Turboではなく、LCM-LoRAで画像生成のステップを削減した場合でも同様の問題が見られます。これは利用するベースモデルとの相性もあるかと思いますが、オリジナルのモデルで多くのステップを重ねた生成と比べると色彩が控えめで、細部の書き込みが荒い傾向が見られます。参考にした論文中の「counterfeitV30+LCM-LoRA 4 step」も上段のような画像が生成されていますので、今回の実験のセットアップの問題ではないようです。SDXL TurboもLCM-LoRAも本来のモデルを近似的に計算するので仕方ない面もあるかもしれませんが、高品質な生成するならばじっくりと時間を掛ける方が良いかもしれませんね。

同一のチェックポイントとプロンプトを用いて、StreamDiffusion + LCM-LoRAで4ステップ(上段)と通常通り20ステップ(下段)で生成した結果。生成までのプロセスや乱数などの条件が異なるため、単純な比較は難しいですが、複数のイラストを生成して比較してみると、20ステップの方が色彩が鮮やかで、細部までより詳細に生成できる傾向があります。
画像生成AIは、簡単に挿絵や資料に使うイラストを生成できるのは便利ですが、やはり人の書いたイラストと比べると何か物足りなさがありますね。前回のBlogで紹介した生成AIによる文章生成も、やはり専門家の文章と比べると何かぼやけた印象が否めません。非専門家に向けた大まかな説明としては十分ですが、論文や専門書のような解像度の高い文章としては、まだ改良が必要です。このギャップを乗り越えて巷で言われている様なAGIのようなものが実現するのでしょうか?今後のAI技術の発展を冷静にキャッチアップしていきたいと思います。
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
参考資料
- 拡散モデルについての理論的な解説書「拡散モデル データ生成技術の数理」 https://www.iwanami.co.jp/book/b619864.html
- High-Resolution Image Synthesis with Latent Diffusion Models https://arxiv.org/abs/2112.10752
- 世界に衝撃を与えた画像生成AI「Stable Diffusion」を徹底解説! https://qiita.com/omiita/items/ecf8d60466c50ae8295b
- StreamDiffusion
- Consistency Models https://arxiv.org/abs/2303.01469
- Latent Consistency Models https://latent-consistency-models.github.io/
- Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference https://arxiv.org/abs/2310.04378
- LCM-LoRA https://arxiv.org/abs/2311.05556
- Latent Consistency Modelsに関した日本語解説記事
- Consistency Models: 1~4stepsで画像が生成できる、新しいスコアベース生成モデル https://zenn.dev/discus0434/articles/484be111f7862d
- Latent Consistency Modelsについて https://note.com/te_ftef/n/n397aa3a43db4
- Hugging Face: SDXL Turbo https://huggingface.co/stabilityai/sdxl-turbo
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD