wikipediaのentity linkのグラフから関連のある企業を見つける
はじめに
こんにちは、グループ研究開発本部 AI研究開発室のS.Sです。
前回はwikipediaのS&P 500の企業ページからNERで企業名を抽出し、企業同士の関係を表現する知識グラフを構築した上で、企業のembeddingをトレーニングして株価と同様の相関関係を持つかどうかを調査しました。
調査により知識グラフから得られる企業の相関関係と株価から得られる相関関係はそれほど強くないものの一定の相関はあることがわかりました。
今回は組織名のつながりではなくwikipedia上でentityのlinkから知識グラフを構築し、より幅広い企業に対して知識グラフから企業の相関関係を算出するアプローチを適用してみたいと思います。
このアプローチによってAmazon <-> Cloud Computing <-> Google <-> Cloud Computing <-> IBMのような提供しているサービスの類似性での関係やApple <-> Information Technology <-> IBMのようなsectorを通した関係を捉えることが期待できます。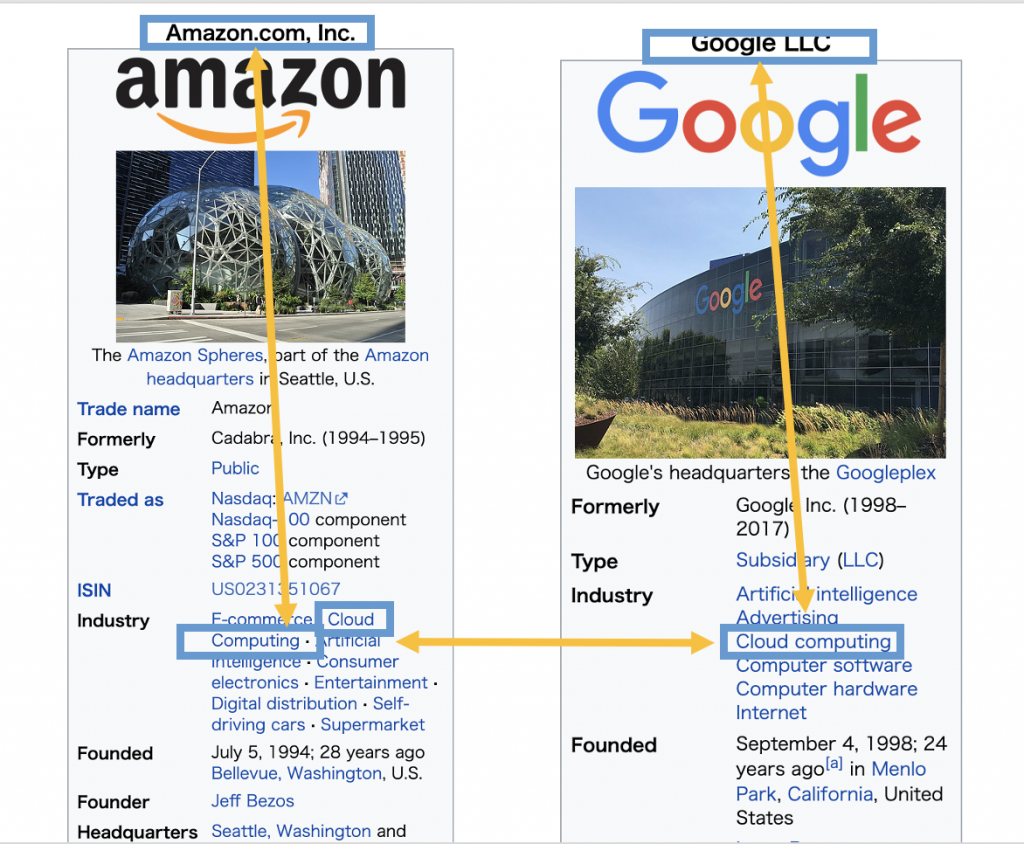
entity linkを使った知識グラフの構築
前回と同様にS&P500の企業一覧に含まれる企業ページを対象とした上で、今回は各ページから(page title, entity link)のペアを抽出します。
pywikibotを利用すると各ページのentity linkが次のようなコードで簡単に抽出できます。
import pandas as pd
import pywikibot
from pywikibot import textlib
from tqdm import tqdm
def save_page(title):
site = pywikibot.Site('en', "wikipedia")
page = pywikibot.Page(site, title)
dsts = [x.title() for x in page.linkedPages()]
df_links = pd.DataFrame({"src": page.title(), "dst": dsts})
all_templates = page.templatesWithParams()
df_infobox = pd.DataFrame()
for tmpl, params in all_templates:
if tmpl.title(with_ns=False) == "Infobox company":
df_infobox = pd.DataFrame({"title": page.title(), "infobox": params})
t = time.time()
df_links.to_csv("sp500_20220924/link_{}.csv".format(t), index=False)
df_infobox.to_csv("sp500_20220924/infobox_{}.csv".format(t), index=False)
with open("sp500_20220924/pagetext_{}.json".format(t), "w") as f:
f.write(json.dumps({"title": page.title(), "text": page.text}))
site = pywikibot.Site('en', "wikipedia")
page = pywikibot.Page(site, "List of S&P 500 companies")
sect = textlib.extract_sections(page.text, site) # divide content into sections
links = sorted(link.group('title') for link in pywikibot.link_regex.finditer(str(sect.sections[1])))
for x in tqdm(links):
save_page(x)
time.sleep(10)
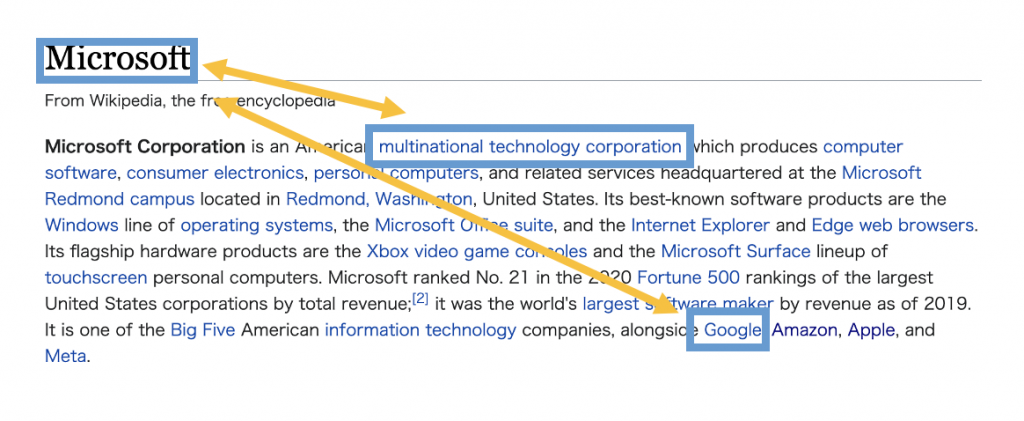
さきほどの例でいうと[(Amazon, Cloud Computing), (Google, Cloud Computing), (Apple, Information Technology), (Apple, Steve Jobs) …]のようにservice名やsectorだけでなく各ページに含まれるentity linkが全て抽出されてpage titleとひもづけられます。
知識グラフからの相関関係の導出
抽出したペアをedgeとみなして知識グラフの隣接行列Aを計算します。
構築したグラフはノード数 15940 エッジ数 105391ほどのグラフとなりました。
S&P 500の企業を中心として直接関連しているentityを全て抽出した形です。
さらにspectral clusteringと同様の方法にそって、ノードの次数で割って正規化した隣接行列Mを固有値分解し、TOP kの固有ベクトル(U[:, :k])を並べてspectral embeddingを作ります。
正規化した隣接行列の2番目に大きい固有値に対応する固有ベクトルは画像のセグメンテーションに使われる特徴量ともなっています。
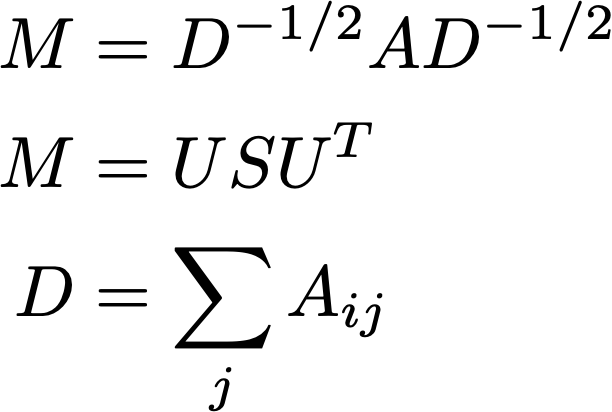
import scipy
import scipy.sparse
import scipy.sparse.linalg
# S&P 500ページよりSymbolとSecurityのmappingを取得
df_sp = pd.read_csv("sp500.csv")
df_map = df_sp.assign(Symbol=lambda x: x["Symbol"].str.lower()).groupby(["Symbol"])["Security"].first()
df_inv_map = df_map.reset_index().groupby(["Security"])["Symbol"].first()
N = df_node_num.pipe(len)
A = scipy.sparse.coo_matrix((np.ones(len(df_bidir_edge)), (df_bidir_edge["src"], df_bidir_edge["dst"])))
D = scipy.sparse.spdiags(1/np.sqrt(np.array(np.clip(A.sum(axis=1), 1, np.inf)).flatten()), 0, N, N)
M = D @ A @ D
s, U = scipy.sparse.linalg.eigsh(M, 64)
df_emb = pd.DataFrame(U, index=df_node_num.index).loc[lambda x: ~x.index.duplicated()]
df_emb.index = df_emb.index.to_series().str.replace(" \(company\)", "")
df_emb = df_emb.loc[lambda x: ~x.index.duplicated()]
df_emb_ind = df_emb.reindex(df_sp["Security"]).dropna()
df_emb_ind = df_emb_ind.apply(lambda x: x/np.linalg.norm(x), axis=1)
corr = df_emb_ind.dot(df_emb_ind.T)
今回のデータではdeepwalkとspectral embeddingの両方を試してみましたが、相関上位の企業を比べるとspectral embeddingのほうが解釈が容易な結果となっていましたのでspectral embeddingのほうをご紹介しました。
知識グラフから相関関係の評価
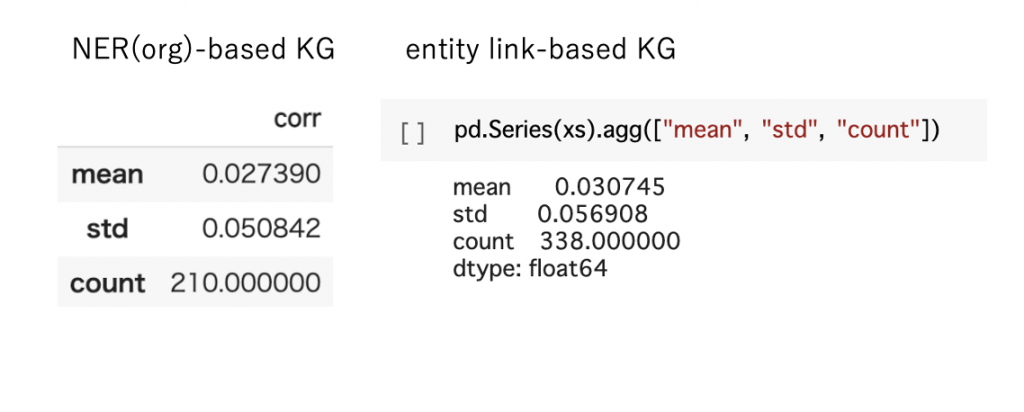
wikipediaからうまく抽出できたS&P500のうち338件の企業の相関関係を評価してみます。
厳密な比較にはなりませんが、前回と同様に知識グラフの相関と株価の相関の整合性をkendall相関係数にて評価したところ、より整合性は強くなるという結果になっています。
xs = []
lst = df_map.loc[lambda x: x.isin(corr.index)]
for x in lst:
try:
xs.append(pd.concat((
pd.Series(corr_orig[df_inv_map[x]].reindex(corr[x].index.to_series().map(df_inv_map)).values,
index=corr[x].index),
corr[x]
), axis=1).corr(method="kendall").iloc[0, 1])
except:
pass
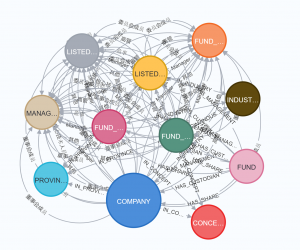
各企業に対して知識グラフ上で相関がもっとも高い10の企業に対して辺をはって、グラフを可視化してみます。
可視化にはNeo4j Desktopを使いました。
本来であればKGはentity同士の関係も含めた(entity, relation, entity)のtripletでの表現を使うことが一般的ですが、wikipediaのentity linkがどのような関係を示しているのか簡単に抽出する方法がなかったので、relationは全てrelatedで埋めています。
異なるsectorからPfizer(pfe), ExxonMobil(xom), Nvidia(nvda)の3つをみてみます。
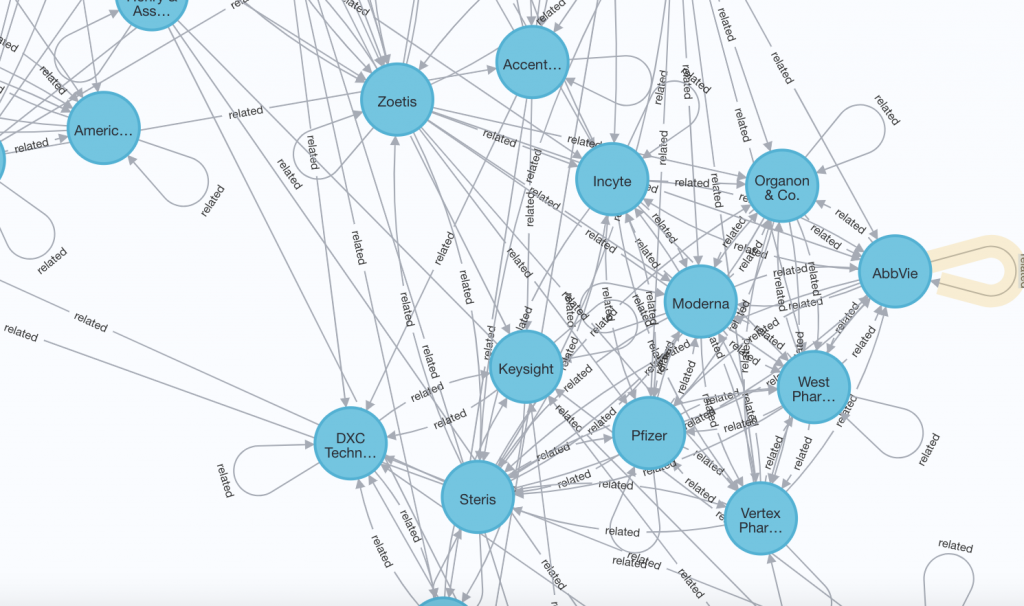 例えばPfizerの例だと製薬会社や医療系の企業が周囲に固まっているというような傾向がみえます。
例えばPfizerの例だと製薬会社や医療系の企業が周囲に固まっているというような傾向がみえます。
新型コロナウイルスのワクチンを開発したPfizerとModernaの2社は知識グラフ上でもかなり近くに配置されています。
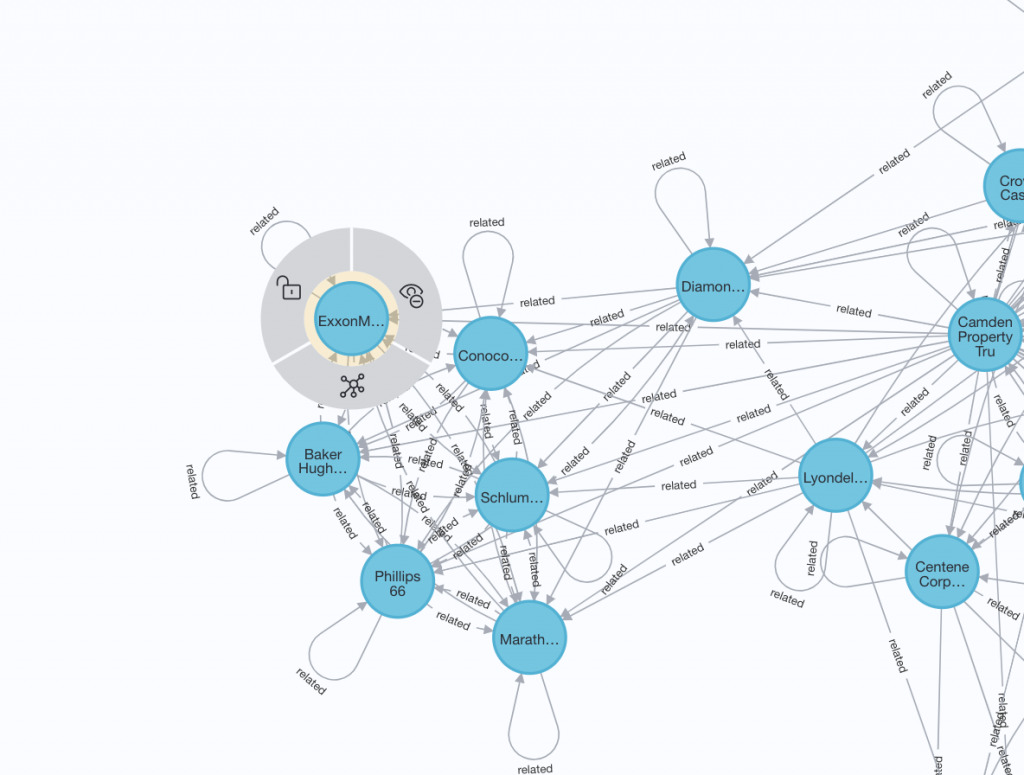
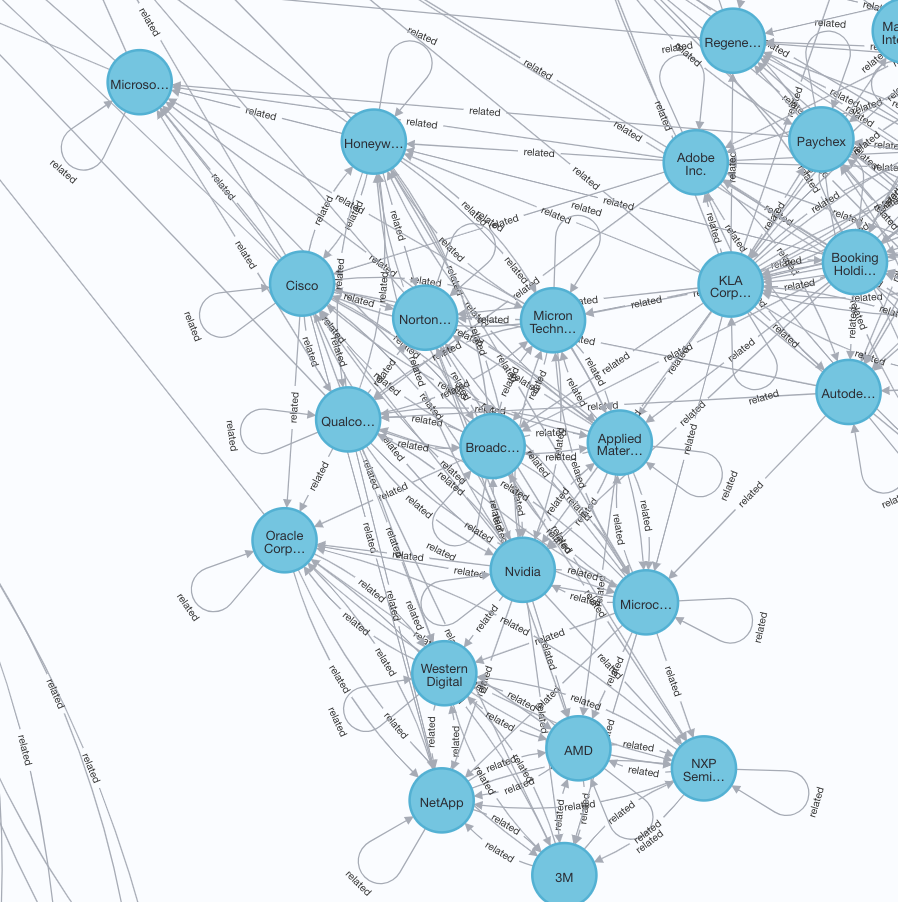
Nvidiaの周辺にはITと半導体のsectorが混じっています。ただし3Mは他と比べるとやや関連性は低そうにみえます。
補足
上記のグラフの可視化には次のようなCypherのクエリを使いました。あらかじめ対象企業に対して相関の高い10企業をsrc, dst, relationとしてcsvに出力しておき、次のように読み込みます。
LOAD CSV FROM "file:///graph_20221003.csv" AS line
MERGE (src:Company {name:line[0]})
MERGE (dst:Company {name:line[1]})
WITH src, dst, line
CALL apoc.merge.relationship(src,line[2],{},{},dst) YIELD rel
RETURN *;
Cypherクエリを使うとグラフの一部を切り取って可視化することもでき、特定の企業(例えばExxonMobil)の2ステップの近傍ノードを出力するには以下のようなクエリが使えます。LOAD CSV FROM "file:///graph_20221003.csv" AS line
MERGE (src:Company {name:line[0]})
MERGE (dst:Company {name:line[1]})
WITH src, dst, line
CALL apoc.merge.relationship(src,line[2],{},{},dst) YIELD rel
MATCH (n:Company{name: "ExxonMobil"})-[*1..2]->(m)
RETURN collect(m);
まとめ
前回の知識グラフから似ている企業のグループを見つけるというテーマの続きで、今度は適用対象を広げるためにentity linkベースの手法を試してみました。
手法を変えて対象企業の数を増やしましたが、株価の相関関係との整合性はさらに少し強くなるという傾向がみえています。
さらにNeo4jを使っていくつかのsectorの代表的な企業の近傍ノードを可視化したところ、wikipediaでの記述が整理されている企業に関してはある程度感覚とあっていそうな印象でした。
entity linkをベースにすることで表現の抽出エラーや表記ゆれの問題に対処する必要がなくなるので、お手軽にwikipediaのデータから特定ドメインのentityのグラフを構築できてよいかと思います。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。