2021.10.08
日本語ALBERTのWord Embeddingsを考える
こんにちは。次世代システム研究室のT.Y.です。よろしくお願いします。
この記事では、近年、自然言語処理の分野で主流になっているBERTの派生モデルの一つであるALBERTについて紹介します。
記事の最後には実際にALBERTを動かしてみた結果を載せています。今回紹介するようなモデルは、それらを簡単に試すことができるライブラリが公開されており、また、ALBERTは比較的計算コストに優れるモデルでなので皆さんも是非試してみてください。(私は会社のMac book Proで試しています。)
自然言語処理とは
そもそも自然言語処理とは?、という方のために簡単に説明します。自然言語処理とは、我々が日常会話で使っているような言語(自然言語)を数学的なモデルで表現し、単語の羅列である自然言語を、機械の処理に適した形、つまり数字の羅列に変換する処理です。一般的な手法では、単語は、その単語の特徴を表す一定の次元数の実数ベクトルで表され、このベクトルのことを分散表現、埋め込み表現(Embedding)と呼びます。
まだふわっとした説明なので単純化した例をあげて説明します。兄、弟、妹、の3つの単語の意味を数学的に表現する例を考えてみましょう。
まず、兄という単語の意味を「男かどうか」と「年上か年下か」の2つの要素と考え、それらの要素に各次元が対応する2次元のベクトルで表します。
すると兄という単語の意味は[1,1]というベクトルで表されます。弟という単語も同様にベクトルで表すと、[1,0]となり、妹という単語の意味は[0,0]となります。こうして得られたベクトル間の距離は、単語の意味がどのくらい違っているかを表すものになっっています。つまり、単語の意味の違いというそのままでは機械で扱えない概念を、機械で処理できるベクトルの距離に置き換えることができたわけです。

実際のモデルはもっと複雑で、分散表現の次元数は数十から数百次元であり、各次元も言葉で表現できるような意味を表すものではありませんが、単語の分散表現と言われたらこういうものをイメージしてもらえば大丈夫です。
(余談ですが実際のモデルでは、各単語に同じ次元数の要素の値がランダムなベクトルを割り当て、意味の近い単語のベクトルの距離が近くなるように値の更新を繰り返す、というようなことをしています。単語の意味の近さはどう決めるの?という話ですが、これは「同じ単語とよく一緒に使われる単語は意味が近いはずだ」というような仮定に従っています。このような仮定はある程度正しいみたいですが、本当に正しいのかは誰にもわかっていません。単語の意味の近さ、とは一体…?)
BERT
BERTとは、2018年にGoogleから発表された最先端の自然言語処理のモデルです。非常に強力で様々な目的に応用できるモデルで、発表当時の最先端モデルに、ほとんどの自然言語処理タスク(次の文章の予測やQandAなど)の精度で上回りました。
ここでは細かい数式等には触れませんが、BERTのポイントだけを説明します。
まず、BERTは深層学習を使った自然言語処理モデルです。深層学習を使ったモデルでは、Attentionという機構を取り入れることが様々な分野で有効と言われており、このBERTがベースにしているTransformerというモデルもこのAttentionを取り入れ精度を向上させているモデルです。Attentionは、一言で言うとネットワークの学習されたパラメータへの重み付けです。これによりどのパラメータを重視するかを表現しています。(有効性についてはGoogleも「Attention Is All You Need」 と言っています。)
もう一つのポイントは、BERTの学習は、Transformerのencoder部分を用いた教師なしの事前学習の部分と、事前学習によって得られたパラメータを初期値としてFine-Tuningを行う部分に分かれていることです。
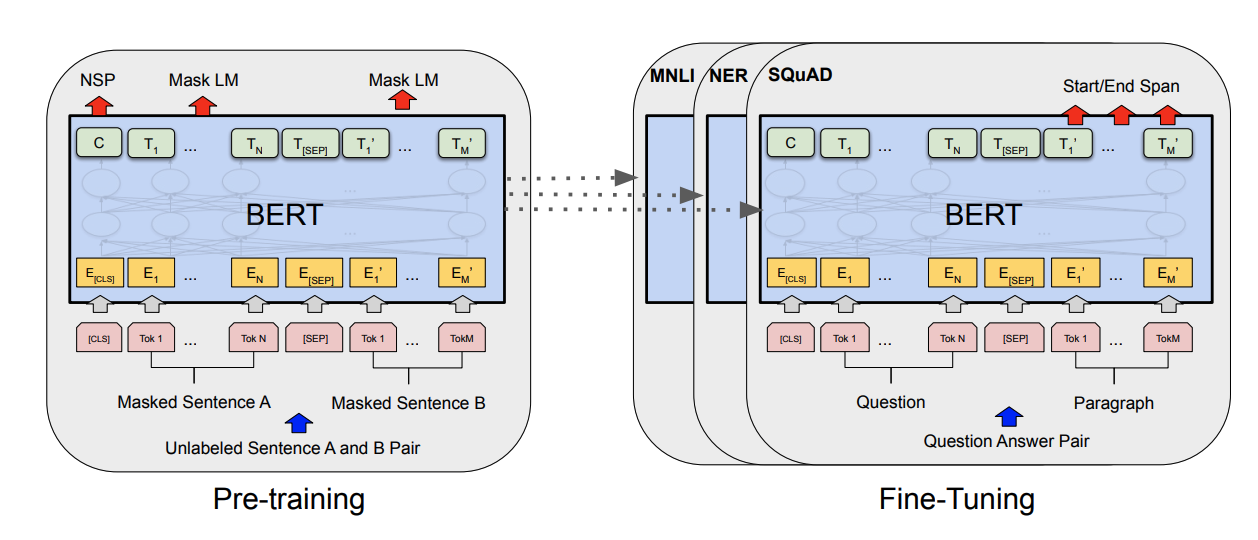
事前学習のステップではBERTは、Masked Langage Modeling(穴埋め問題)とNext Sentence Prediction(文章の連続性の判定)という二つの問題を解くことで単語の意味的な特徴を表すパラメータを学習します。Masked Langage Modelingは、文章の一部の単語を特殊なトークンに置き換えることで欠損させてモデルに入力し、得られる出力が元の単語を入力したときに得られる出力に近くなるように学習します。
Fine-Tuningのステップでは実際に解きたい問題に合わせた文章を入力してパラメータを更新します。例えば、質問文に対する回答文を自動生成する問題を解くならば、質問文と回答文のペアを正解データとして入力して学習させます。
自然言語処理では一般に学習に非常に大規模なデータが必要です。しかし、そのようなデータを用いた学習は非常にコストが大きく、そもそもそんなに大規模なデータは簡単に用意できるものではありません。しかし、BERTでは事前学習を一度大規模なデータで行なっておけば、Fine-Tuningに大きなデータは必要なく、タスクに合わせてモデルを更新することは容易です。また、モデルを用いる環境(BERTを適用したい自分のサービスなど)にデータが少ない場合でも、Wikipediaの語彙で学習したモデルのような汎用的な事前学習のモデルをFine-Tuningすることで、環境に合わせたモデルを得られ、データ不足の問題を解決できます。
ALBERT
BERTの良いところを語ってきましたが、当然改善すべきポイントはあります。その一つが学習コストです。事前学習のコストは、TPUで全力でやって数日かかると言った具合なので一個人が行うには非現実的なレベルでしょう。Fine-Tuningがあるとはいえ、別のデータセットで事前学習からやり直したいケースもあると思いますが、それも大変です。
AlBERTのモデルの構造は概ねBERTと同じですが、パラメータを削減するためのいくつかの工夫がなされており、精度を落とさず学習コストを軽減することに成功しています。
一つ目の工夫がWord Embeddingsの次元数の削減です。BERTでは、モデルの構造上、モデルの隠れ層の次元数とWord Embeddingのサイズを合わせる必要がありました。Word Embeddingsは非常に巨大なものになっていました。具体的にEnglish wikipediaの語彙、2500M Wordsを用いた隠れ層の次元数768のBert-baseのモデルが持つWord Embeddingは、768 X 2500Mの超巨大な行列です。ALBERTでは、Word Embeddingsの次元数 X モデルの隠れ層の次元数の変換行列を用います。これにより、Word Embedingsの次元数をモデルの隠れ層の次元数より小さくしてパラメータを削減することができ、学習コストを下げることができます。
二つ目の工夫は隠れ層のパラメータの共有です。BERTでは隠れ層はTransformerを重ねた構造になっており、各層が異なるパラメータを持っていました。ALBERTはそれらのパラメータを共有しています。
三つ目の工夫は、事前学習のタスクの改善です。BERTのNSPはMLMに対して簡単すぎるため学習への貢献が小さいという指摘がありました。ALBERTではNSPではなく、二つの分の順序を判定するSentence Order Predictionで事前学習を行います。
実際に動かしてみようのコーナー
BERTやALBERTなどの事前学習されたモデルや、それらを簡単に使うためのライブラリはHuggingface Transformersで(href=”https://huggingface.co/transformers/)公開されており、誰でも試すことができます。今回は計算資源と時間に限りがあるので小規模な日本語のALBERTモデル、albert-japanese-v2(https://github.com/alinear-corp/albert-japanese)を試します。このモデルはLivedoorニュースコーパスで事前学習されたモデルです。
まずはインストール。pipで一発です。
pip3 install torch torchvision pip install transformers
実際の使い方はこんな感じです。torknizerで文章を単語に分割し、単語に対応するIDのシーケンスに変換します。そしてモデルに入力すると出力が返ってきます。
from transformers import AlbertTokenizer, AlbertForPreTraining
import torch
tokenizer = AlbertTokenizer.from_pretrained('ALINEAR/albert-japanese-v2')
model = AlbertForPreTraining.from_pretrained('ALINEAR/albert-japanese-v2')
input_ids = torch.tensor(tokenizer.encode("吾輩は神である。", add_special_tokens=True)).unsqueeze(0) # Batch size 1
outputs = model(input_ids)
prediction_logits = outputs.prediction_logits
出力がどんなものかはまずモデル定義を見るとわかりやすいです。
print(model)
--------------------------------------------
AlbertForPreTraining(
(albert): AlbertModel(
(embeddings): AlbertEmbeddings(
(word_embeddings): Embedding(32000, 128)
(position_embeddings): Embedding(512, 128)
(token_type_embeddings): Embedding(2, 128)
(LayerNorm): LayerNorm((128,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): AlbertTransformer(
(embedding_hidden_mapping_in): Linear(in_features=128, out_features=768, bias=True)
(albert_layer_groups): ModuleList(
(0): AlbertLayerGroup(
(albert_layers): ModuleList(
(0): AlbertLayer(
(full_layer_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(attention): AlbertAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(attention_dropout): Dropout(p=0.1, inplace=False)
(output_dropout): Dropout(p=0.1, inplace=False)
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
(ffn): Linear(in_features=768, out_features=3072, bias=True)
(ffn_output): Linear(in_features=3072, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
)
(pooler): Linear(in_features=768, out_features=768, bias=True)
(pooler_activation): Tanh()
)
(predictions): AlbertMLMHead(
(LayerNorm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(dense): Linear(in_features=768, out_features=128, bias=True)
(decoder): Linear(in_features=128, out_features=32000, bias=True)
)
(sop_classifier): AlbertSOPHead(
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=2, bias=True)
)
)
見覚えのあるパラメータが見えるので、先程のALBERTの説明の復習ついでに見ていきましょう。まず何度も説明に出てきたword embeddingsがいますね。語彙数が32000で次元数が128です。これをembedding_hidden_mapping_inと名前のついたLinear Layerを通して線形変換し隠れ層と同じ次元数のベクトルを得ます。position_embeddingsとかattentionのあたりは本記事で詳しく説明しなかったtransformerのencorderなのですが、ここのweightが層に跨って共有されているのがALBERTのパラメータを削減する工夫の一つでした。poolerは文章の先頭に挿入される文章の始まりを表す特殊なtokenの入力に対する出力です。BERTの事前学習のNSPやFine-Tuningで使われるものです。Tanh()のアクティベーション関数を通すと元のtokenが出てくるはずです。
predictionはAlbertTransformerのffn_outputとattentionのoutputなどから計算される最後の層の出力を受け取って出力したものがprediction logitです。これは入力した語彙が各語彙であるかどうかのスコアのようなものです。このスコアが高い語彙は、入力した語彙と同じ文脈で文章中に現れやすい、意味的に近い語彙といえるでしょう。
prediction_logitsの中身はこんな感じです。
print(prediction_logits.size())
>>> torch.Size([1, 9, 32000])
print(prediction_logits)
>>> tensor([[[ -5.4226, 5.0025, -7.1903, ..., -7.3084, -5.4212, -6.0753],
[ -5.4136, 5.5594, -8.5267, ..., -4.3746, -8.4527, -4.0389],
[ -4.9033, 3.4257, -9.0574, ..., -2.3863, -4.5260, -4.8764],
...,
[ -5.4280, 4.5423, -11.8602, ..., -4.5775, -6.4396, -2.3579],
[ -5.9569, 6.1530, -5.3676, ..., -7.9072, -5.8880, -5.6555],
[ -4.0028, 5.2620, -5.6757, ..., -7.0424, -5.6761, -5.9782]]],
grad_fn=<AddBackward0>)
一通りモデルの全体が見えたところで、単語の特徴を表すベクトルはどこの出力なのかを考えてみます。これはやはりAlbertTransformerの最終層のhidden_stateかと思います。ここの出力が類似している語彙同士は、predictionの出力も類似するので、ここの出力を取り出して語彙の分散表現として比較してやると良さそうです。(word_embeddings)をそのまま使うのはFine-Tuningなどをしたときに色々と変わってきそうだなと思います。
まあ一番の理由はTransformerではhidden_stateが一行で取れるからですけどね。最終層から何層かの出力を使う考えもあるとか。
print(outputs.hidden_states)
>>>(tensor([[[-0.2944, 0.1718, 0.1627, ..., 0.2514, -0.1138, -0.2410],
[-0.1478, 0.4971, -0.1262, ..., -0.1164, -0.2513, 0.0600],
[ 0.1372, 0.1896, -0.0370, ..., 0.3006, -0.3163, 0.1843],
...,
[-0.0779, 0.1540, -0.2121, ..., -0.0200, -0.3697, 0.0453],
[ 0.3144, 0.0823, 0.3410, ..., 0.0789, -0.5377, 0.0576],
[ 0.1835, 0.1853, 0.0307, ..., 0.1268, -0.1111, -0.1929]]],
grad_fn=<AddBackward0>),
tensor([[[-0.5455, 1.3107, 0.7287, ..., 0.8775, -0.6803, -0.7955],
[-0.1097, 2.6213, -0.1650, ..., -0.8167, -2.0849, 0.7774],
[ 1.4688, 1.2690, 0.1107, ..., 1.8470, -1.6622, 1.8551],
...,
[-0.0493, 0.8248, -1.1655, ..., -0.0385, -1.8924, 0.3705],
[ 2.0977, 0.2322, 1.8544, ..., 0.2146, -3.1315, 0.4868],
[ 1.2955, 0.8047, 0.1736, ..., 1.0116, -1.0047, -0.3840]]],
grad_fn=<NativeLayerNormBackward>),
tensor([[[ 0.5774, 1.5612, 0.2735, ..., 0.3198, -0.6192, -0.6820],
[ 0.5754, 2.2735, 0.3145, ..., -1.2400,
(略)
文章のベクトルの類似度を計算してみました。
input_ids_A = torch.tensor(tokenizer.encode("吾輩は神である。", add_special_tokens=True)).unsqueeze(0)
embeddings_A = torch.mean(model(input_ids_A,output_hidden_states=True).hidden_states[12],1)
input_ids_B = torch.tensor(tokenizer.encode("吾輩は猫である。", add_special_tokens=True)).unsqueeze(0)
embeddings_B = torch.mean(model(input_ids_B,output_hidden_states=True).hidden_states[12],1)
input_ids_C = torch.tensor(tokenizer.encode("運も実力のうち・そんなことを言っている間は実力が足りない。", add_special_tokens=True)).unsqueeze(0)
embeddings_C = torch.mean(model(input_ids_C,output_hidden_states=True).hidden_states[12],1)
print(torch.cosine_similarity(embeddings_A,embeddings_B,dim=1))
print(torch.cosine_similarity(embeddings_A,embeddings_C,dim=1))
print(torch.cosine_similarity(embeddings_B,embeddings_C,dim=1))
>>>tensor([0.8960], grad_fn=<DivBackward0>)
tensor([0.6784], grad_fn=<DivBackward0>)
tensor([0.6946], grad_fn=<DivBackward0>)
期待通りの結果ですね。小説などを入力してみると面白そうです。
参考
ALBERT: A Lite BERT for Self-supervised Learning of Language Representationshttps://arxiv.org/abs/1909.11942
BERT: Pre-training of Deep Bidirectional Transformers for Language Understandinghttps://arxiv.org/abs/1810.04805
albert-japanesehttps://github.com/alinear-corp/albert-japanese
Attention Is All You Need
https://arxiv.org/abs/1706.03762
最後に
Huggingface Transformersで公開されているモデルにはオンラインデモが用意されているものもあります(Rinnaのオンラインデモ)。コードを動かすまではいかないけど興味はあるという方はこちらを試してみても良いと思います。また本記事では試していませんが、公開されているモデルをFine-Tuningすることも可能です。つまり、あなたの用意したデータでRinnaをFine-Tuningできます。それでは、よい自然言語処理ライフを。
次世代システム研究室では、 Web アプリケーション開発を行うアーキテクトを募集しています。募集職種一覧からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD