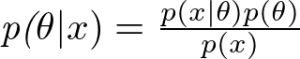2019.04.09
Kaggleコンペティション体験記:ELO MERCHANT CATEGORY RECOMMENDATION
次世代システム研究室第一グループでデータサイエンティストをしております Y.T と申します。
前回に引き続き、私のKaggle体験記を皆様と共有させていただきたいと思います。
Kaggleについて
すでにご存知の方も多いと思いますがKaggleは、データサイエンティスト・機械学習エンジニア向けのコンペティションサイトです。
企業がコンペティションのスポンサーとなり、コンペティションのお題と使うデータセットを提供し、参加者はお題に沿ってモデルを構築し、予測した結果を提出します。
世界中の専門家が頭をひねって選りすぐったモデルを投稿するので、スポンサー企業にとってKaggleは、抱えている分析課題のブレイクスルーをリーズナブルなコストで手に入れることができる大変便利なプラットフォームと映るかもしれません。
Kaggleのコンペティション
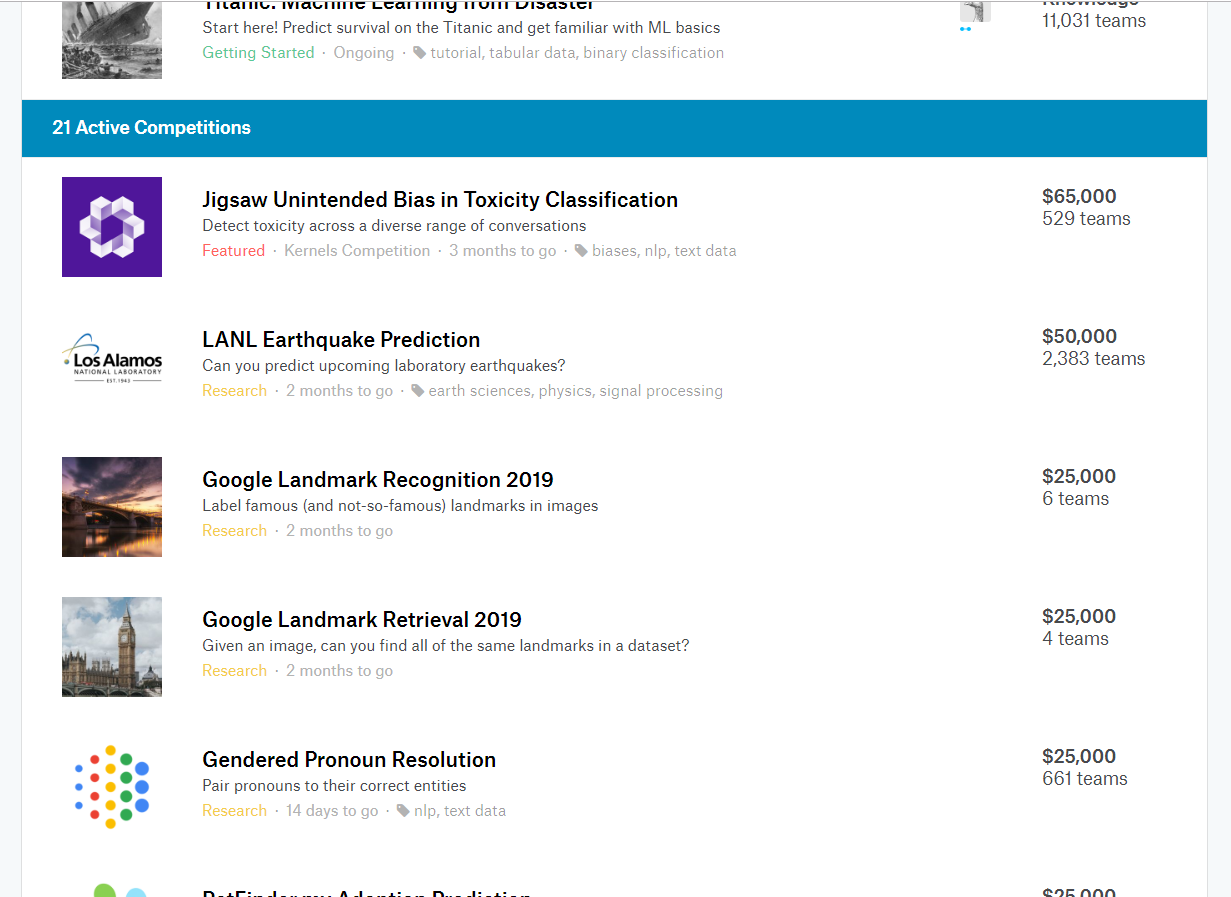
以下は、Kaggleのコンペティション一覧画面です。
様々なタスク(解析対象が音声、画像、テーブルデータ、信号など色々)のコンペティションが並んでいるのが分かります。
また、賞金があるコンペティションがあることも確認できます。
以下のスクリーンショット内では、6万5000ドルや5万ドル、2万5000ドルの賞金が付いているコンペティションがあります。
世界中の専門家に参加を呼びかける上で、賞金は有効なアプローチの一つです。報酬的モチベーションと、実績の視覚化(ランキング)という二つの点で、参加するデータサイエンティストや機械学習エンジニアの参加意欲をかき立てます。
今回参加したコンペティション
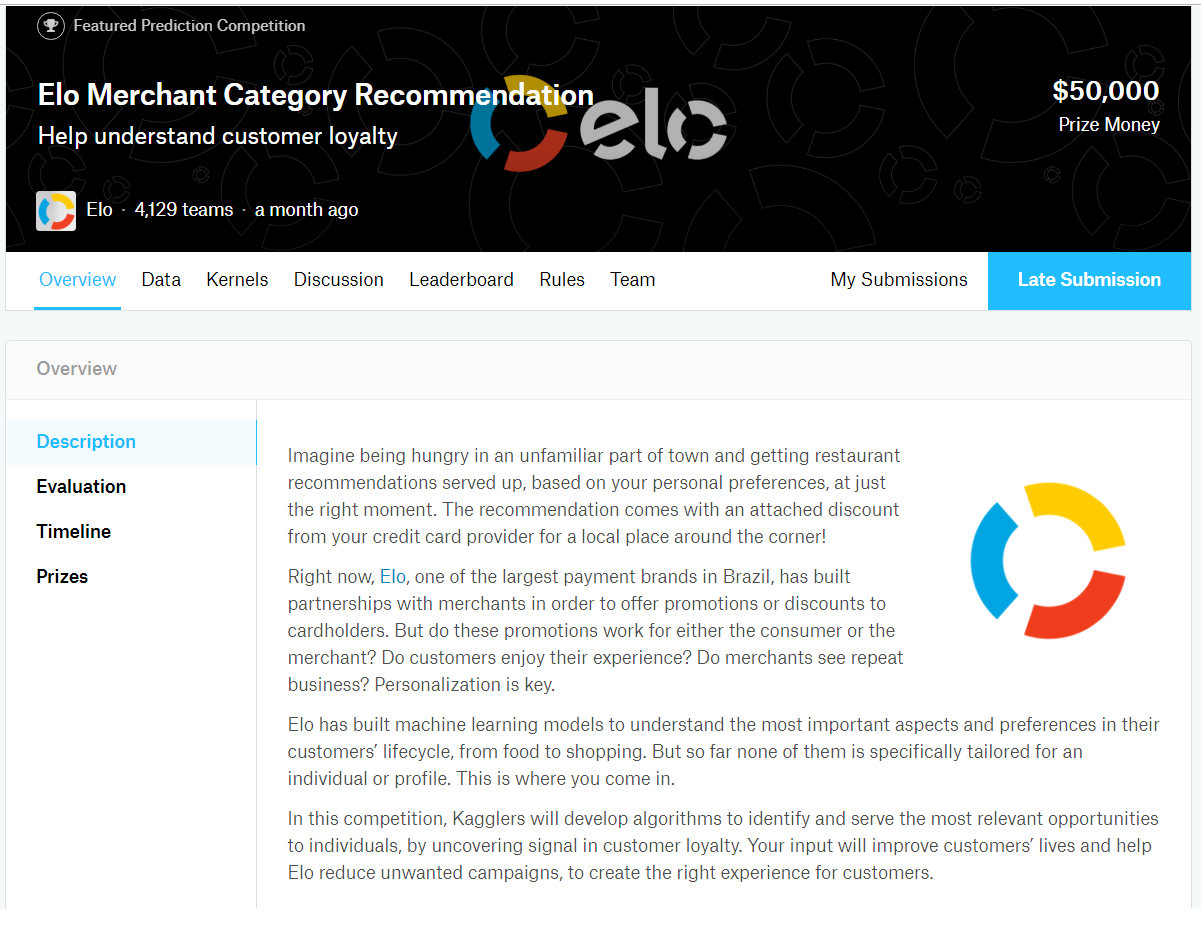
今回参加したコンペティションは、ELO MERCHANT CATEGORY RECOMMENDATIONです。
ELO MERCHANT CATEGORY RECOMMENDATION の概要
コンペティション:ELO MERCHANT CATEGORY RECOMMENDATION(以下、本コンペティションと略)の概要は以下の通りです。(英文)
Imagine being hungry in an unfamiliar part of town and getting restaurant recommendations served up, based on your personal preferences, at just the right moment. The recommendation comes with an attached discount from your credit card provider for a local place around the corner!
Right now, Elo, one of the largest payment brands in Brazil, has built partnerships with merchants in order to offer promotions or discounts to cardholders. But do these promotions work for either the consumer or the merchant? Do customers enjoy their experience? Do merchants see repeat business? Personalization is key.
Elo has built machine learning models to understand the most important aspects and preferences in their customers’ lifecycle, from food to shopping. But so far none of them is specifically tailored for an individual or profile. This is where you come in.
In this competition, Kagglers will develop algorithms to identify and serve the most relevant opportunities to individuals, by uncovering signal in customer loyalty. Your input will improve customers’ lives and help Elo reduce unwanted campaigns, to create the right experience for customers.
上記の内容を私なりに解釈して、簡潔にまとめたものはこちらです。
- ELOは、ブラジルで最も大きな決済企業の一つである。
- クレジットカード保有者(=顧客)に対して、個々の嗜好を踏まえたプロモーションや割引サービスの案内を送りたい。
- ELOは機械学習を用いて、食べ物から買い物に至るまでの顧客のライフサイクルにおける好みや振る舞いの側面を理解しようと取り組んでいる。
- しかしこれまでの取り組みは、個々の顧客に焦点を当てた、パーソナライズされたモデルではなかった。そこで参加者の出番である。
- 今回は、顧客ロイヤリティスコアというシグナルを解明することで、パーソナライズされたサービスを顧客に提供できるアルゴリズムの探求に取り組む。
どうやら「顧客ロイヤリティスコア」なるスコアを、機械学習モデルを使って予測するのがこのコンペティションのタスクであるようです。
予測したスコアは、どのように評価されるのか「Evaluation」の項目を見てみましょう。
評価基準について
評価基準ページはこちらです。そのページのスクリーンショットを以下に用意しました。
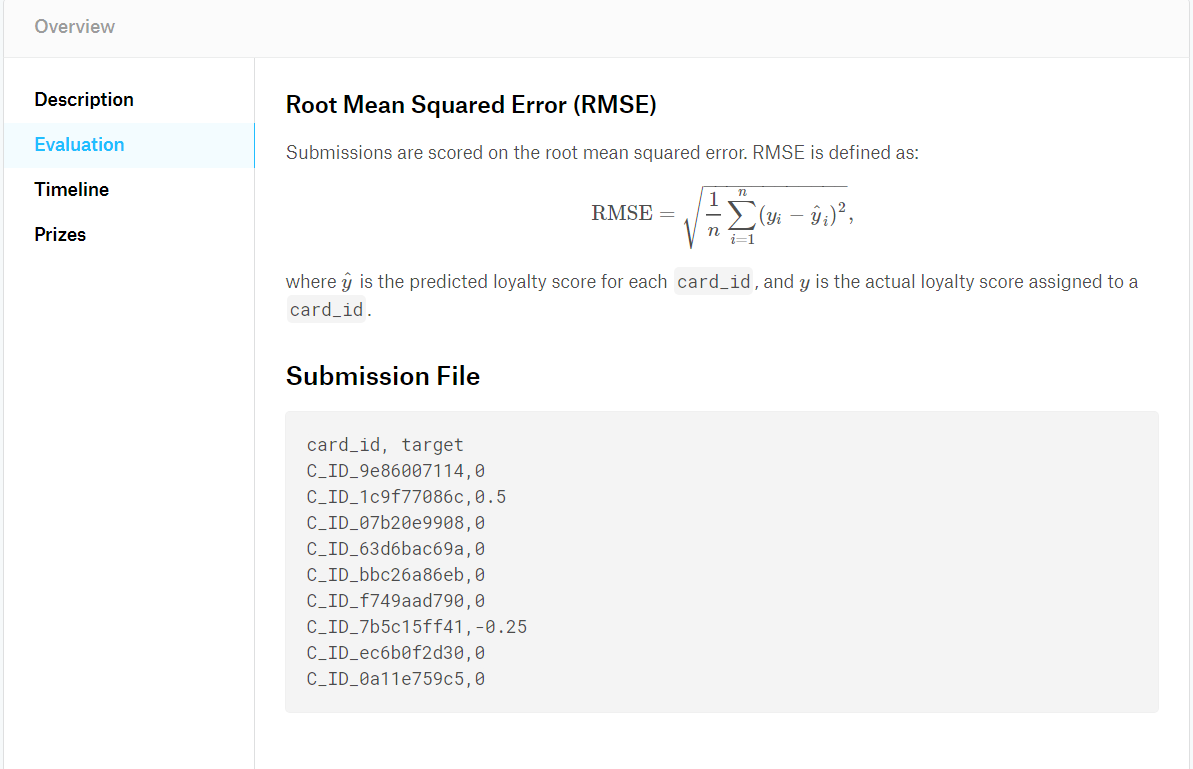
評価基準は、予測スコアと正解スコア間の平均平方二乗誤差(RMSE)です。
RMSEの説明ですが、以下のエントリが分かりやすい説明を提供していますので、ご参照ください。
いろいろな予測誤差の意味(RMSE、MAEなど) – 具体例で学ぶ数学
評価基準ページの下を見ると、提出ファイル(CSV形式)のサンプルがあるのが分かります。
各クレジットカードIDごとに先ほど述べた「顧客ロイヤリティスコア」を書き出せば良さそうですね。
続いて、本コンペティションで扱うデータファイルについて見ていきましょう。
データファイルについて
本コンペティションで扱うことになるデータファイルの説明はこちらです。
データファイルについての説明
重要なところを抜粋したものはこちらです。
File descriptions:
train.csv – the training set
test.csv – the test set
sample_submission.csv – a sample submission file in the correct format – contains all card_ids you are expected to predict for.
historical_transactions.csv – up to 3 months’ worth of historical transactions for each card_id
merchants.csv – additional information about all merchants / merchant_ids in the dataset.
new_merchant_transactions.csv – two months’ worth of data for each card_id containing ALL purchases that card_id made at merchant_ids that were not visited in the historical data.Data fields:
Data field descriptions are provided in Data Dictionary.xlsx.
トレーニングデータセットはtrain.csv です。名前からしても分かりやすいですね。
予測すべき対象はtest.csv に収録されています。こちらもよくある名前で理解しやすいですね。
提出ファイル(submission file)のお手本もあります。sample_submission.csv というファイルです。
取引履歴ファイルが二つありますね。
一つは、historical_transactions.csvで、3ヶ月間の各カードIDごとの取引履歴を記録しています。
もう一つは、new_merchant_transactions.csvで、historical_transactions.csvに出現しない新しい商業者ID(merchand_ids)について、2ヶ月分の各カードIDの取引履歴を記録しています。
商業者の情報は、merchants.csvです。
トレーニングデータセット以外にもデータファイルがあるのが、本コンペティションの特徴の一つです。
どうやら、トレーニングデータセット以外のデータファイルを駆使して、有益な特徴量を探索する必要がありそうな予感がします(=特徴量エンジニアリングが手ごわいかも)
そして、各データファイルの仕様は、Dictionary.xlsxというエクセルファイルにまとめられているようです。
各カラムの意味を考慮し、テーブル間でデータの結合や集約といった処理をする際のヒントが隠されていそうです。
それでは、カーネル(Kaggleの仮想マシン)を開いて、探索的解析に着手してみましょう。
探索的解析
それでは、本コンペティション参加にあたり私が組んだ解析の中からいくつか抜粋してご紹介したいと思います。
データファイルの場所を確認する
モデル構築の手がかりを得るため、データファイルの中身をのぞいて見ましょう。
まずトレーニングデータですが、仕様を確認したところカラム数が少ないようです。
[table id=4 /]
実際の値はどうなっているでしょうか。
カーネルを開き、“../input”にあるデータファイルの一覧を確認します。
!ls ../input -l total 3027892 -rw-r--r-- 1 root root 17600 Nov 26 21:36 Data_Dictionary.xlsx -rw-r--r-- 1 root root 2845920484 Nov 26 21:37 historical_transactions.csv -rw-r--r-- 1 root root 50040976 Nov 26 21:36 merchants.csv -rw-r--r-- 1 root root 190246145 Nov 26 21:36 new_merchant_transactions.csv -rw-r--r-- 1 root root 2225229 Nov 26 21:36 sample_submission.csv -rw-r--r-- 1 root root 3708740 Nov 26 21:36 test.csv -rw-r--r-- 1 root root 8383651 Nov 26 21:36 train.csv
取引履歴ファイルがかなり大きいことが分かります。
ようやら、train.csvだけを読み込めば済む、というタスクではなさそうですね。
トレーニングデータ、テストデータ、取引履歴2ファイルをデータフレームに読み込み、探索を始めるとしましょう。
おなじみの pandas を使って、データを操作していきます。
import numpy as np
import pandas as pd
import datetime
import gc
import matplotlib.pyplot as plt
import seaborn as sns
import lightgbm as lgb
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import mean_squared_error
df_train = pd.read_csv('../input/train.csv')
df_test = pd.read_csv('../input/test.csv')
df_hist_trans = pd.read_csv('../input/historical_transactions.csv')
df_new_merchant_trans = pd.read_csv('../input/new_merchant_transactions.csv')
実際にカーネル上で上記コードを実行するとお分かりになると思いますが、かなりメモリを消費します。
取引履歴データファイルが特に大きな割合を占めます。
Kaggleのカーネルでは16~17GBのメモリが使えるのですが、半分以上がデータファイルを読み込んだだけで消費されてしまいます。
メモリ効率を意識したPythonコード実装が求められます。
カードIDの分布を調べる
カードIDは連続値ではなく、固有文字列なので、分布と言っても統計的分布という意味ではなく、トレーニングデータとテストデータで重複がないか調べるという意味です。
以下のように、python の集合演算を使い、カードIDの重複がないか調べます。
card_id = {"train":df_train['card_id'].unique(),
"test":df_test['card_id'].unique()}
card_id["common"] = set(card_id['train']) & set(card_id['test'])
print(card_id['common'])
# 出力結果
set()
トレーニングデータとテストデータで、カードIDが重複するケースは無いことが分かりました。
もし重複があったら、リークになってしまいますので、IDの分離はきちんとされているのは大前提となります。
取引履歴に含まれるカードID
取引履歴にはテストデータのカードIDがちゃんと包含されているか調べます。
card_id['total'] = df_hist_trans['card_id'].unique() len(set(card_id['test']) & set(card_id['total'])) # 出力結果 # 123623 len(card_id['test']) # 出力結果 # 123623
テストデータに登場するカードID 123,623件のうち、すべてが取引履歴の中で見つかることが分かりました。
len(set(card_id['train']) & set(card_id['total'])) # 出力結果 # 201917 len(card_id['train']) # 出力結果 # 201917
トレーニングデータに登場するカードID 201,917件すべてが取引履歴の中で見つかることも分かりました。
これならば取引履歴を使って、カードIDごとの統計量を計算するなどして、特徴量を作り出すことができそうです。
顧客ロイヤリティスコアの分布
本コンペティションにおいて、モデルの目的変数となる顧客ロイヤリティスコアの分布を調査します。
分布形状を視覚的に確かめることで、定性面から作戦やアイディアが得られることが期待できます。
顧客ロイヤリティスコアは、目的変数 target としてデータファイルの中に記述されています。
それでは値のサンプルを見てみましょう。
print(df_train.head()) first_active_month card_id ... feature_3 target 0 2017-06 C_ID_92a2005557 ... 1 -0.820283 1 2017-01 C_ID_3d0044924f ... 0 0.392913 2 2016-08 C_ID_d639edf6cd ... 0 0.688056 3 2017-09 C_ID_186d6a6901 ... 0 0.142495 4 2017-11 C_ID_cdbd2c0db2 ... 0 -0.159749 [5 rows x 6 columns]
顧客ロイヤリティスコアは、カテゴリ的、階段的な数値ではなく、連続する実数値であることが分かります。
では、ヒストグラムを生成して、分布形状を視覚的に確認しましょう。
ここでは seaborn ライブラリを使います。
plt.figure(figsize=(16,8)) sns.distplot(df_train['target'], bins='auto', kde=False)
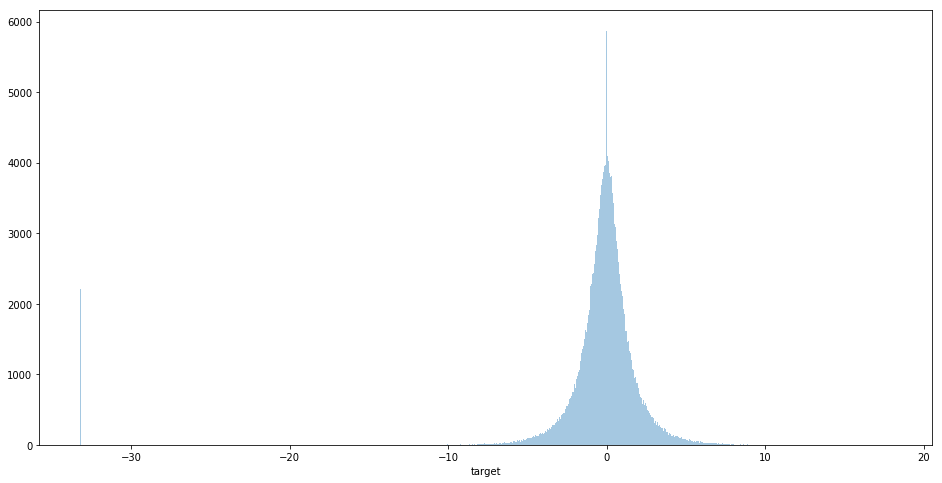
平均値 0 を中心とする正規分布的な形状が見えます。
一方、-30 付近にサンプルが固まって存在することも確認できます。分布形状を考慮すると、-30付近のサンプル集団は、異常値の集まりと見て扱ったほうが良さそうです。(平均値 0 を中心とする正規分布的な分布から、明らかに外れた場所にある!)
-30を閾値として、異常値(outliers)の数を数えてみました。
df_train['outliers'] = 0 df_train.loc[df_train['target'] < -30, 'outliers'] = 1 df_train['outliers'].value_counts() # 実行結果 0 199710 1 2207 Name: outliers, dtype: int64
全体の約1%が異常値に属することが分かりました。
数は少ないですが、1個当たりに生じる誤差のインパクトはかなり大きいものになりそうです。
と、このように、様々な側面、観点について調査をして知見を積み上げるプロセスを続けていき、モデル構築のコンセプトを固めてゆきます。
本コンペティションで使ったモデル
本コンペティションでは、前回のエントリでも紹介した lighGBM を使い、回帰モデルを構築して予測に挑戦しました。
lightGBMは、マイクロソフトが開発し、GitHubで公開しているブースティング型の機械学習モデルです。
本コンペティションでは、連続値を予測するため、回帰モデルを構築する必要があります。
そこで以下のパラメータを適用して、lighGBMで学習を行いました。
# lighGBM のオプションに指定するパラメータ定義
param = {'num_leaves': 33,
'min_data_in_leaf': 30,
'objective':'regression',
'max_depth': -1,
'learning_rate': 0.01,
"min_child_samples": 20,
"boosting": "gbdt",
"feature_fraction": 0.9,
"bagging_freq": 1,
"bagging_fraction": 0.9 ,
"bagging_seed": 11,
"metric": 'rmse',
"lambda_l1": 0.1,
"verbosity": -1,
"nthread": 4,
"random_state": 20190202}
最も重要なのは、'objective':'regression' です。この設定で、回帰モデルを構築するという指定をしています。
モデル構築と予測
lightGBMを使ったモデル構築と予測は、どういった手順で行い、どのような出力が得られるのでしょうか?
実際に使ったカーネルからコードと結果を抜粋してご紹介したいと思います。
本コンペティションでは、基本的に以下のような構造のコードで学習と予測を行いました。
StratifiedKFoldモジュールを使い、目的変数の内訳に大きな偏りが出ないようにサンプリングを行い、交差検証を実施しています。
各交差検証と平行して、構築したモデルを使った予測値をバッファに蓄積し、平均値アンサンブル(=予測値の平均値を最終的な予測値とする)を行います。
num_round = 10000
for fold_, (trn_idx, val_idx) in enumerate(folds.split(df_train,df_train['outliers'].values)):
print("fold {}".format(fold_))
trn_data = lgb.Dataset(df_train.iloc[trn_idx][df_train_columns], label=target.iloc[trn_idx])
val_data = lgb.Dataset(df_train.iloc[val_idx][df_train_columns], label=target.iloc[val_idx])
clf = lgb.train(param, trn_data, num_round, valid_sets = [trn_data, val_data], verbose_eval=100, early_stopping_rounds = 100)
oof[val_idx] = clf.predict(df_train.iloc[val_idx][df_train_columns], num_iteration=clf.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = df_train_columns
fold_importance_df["importance"] = clf.feature_importance()
fold_importance_df["fold"] = fold_ + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
predictions += clf.predict(df_test[df_train_columns], num_iteration=clf.best_iteration) / folds.n_splits
np.sqrt(mean_squared_error(oof, target))
実行結果の抜粋は以下のようになります。
fold 0 Training until validation scores don't improve for 100 rounds. [100] training's rmse: 3.66692 valid_1's rmse: 3.7231 [200] training's rmse: 3.59039 valid_1's rmse: 3.6895 [300] training's rmse: 3.54433 valid_1's rmse: 3.67587 [400] training's rmse: 3.50831 valid_1's rmse: 3.66769 [500] training's rmse: 3.47944 valid_1's rmse: 3.66322 [600] training's rmse: 3.45378 valid_1's rmse: 3.65988 [700] training's rmse: 3.43108 valid_1's rmse: 3.65742 [800] training's rmse: 3.41017 valid_1's rmse: 3.65622 [900] training's rmse: 3.39083 valid_1's rmse: 3.65555 [1000] training's rmse: 3.37277 valid_1's rmse: 3.65481 [1100] training's rmse: 3.35654 valid_1's rmse: 3.65421 [1200] training's rmse: 3.3411 valid_1's rmse: 3.654 [1300] training's rmse: 3.32568 valid_1's rmse: 3.65408 Early stopping, best iteration is: [1210] training's rmse: 3.33983 valid_1's rmse: 3.65392 fold 1 Training until validation scores don't improve for 100 rounds. [100] training's rmse: 3.6692 valid_1's rmse: 3.71347 [200] training's rmse: 3.5934 valid_1's rmse: 3.68216 [300] training's rmse: 3.5451 valid_1's rmse: 3.67104 [400] training's rmse: 3.50828 valid_1's rmse: 3.66472 [500] training's rmse: 3.4791 valid_1's rmse: 3.66145 [600] training's rmse: 3.45285 valid_1's rmse: 3.65897 [700] training's rmse: 3.43011 valid_1's rmse: 3.65769 [800] training's rmse: 3.40841 valid_1's rmse: 3.65652 [900] training's rmse: 3.38968 valid_1's rmse: 3.65628 [1000] training's rmse: 3.37182 valid_1's rmse: 3.65578 [1100] training's rmse: 3.35562 valid_1's rmse: 3.65512 [1200] training's rmse: 3.3398 valid_1's rmse: 3.65527 [1300] training's rmse: 3.32436 valid_1's rmse: 3.65487 [1400] training's rmse: 3.30938 valid_1's rmse: 3.65497 Early stopping, best iteration is: [1338] training's rmse: 3.31893 valid_1's rmse: 3.65455 fold 2 (・・・中略・・・)
最終的には、バッファに蓄積された予測値の平均値(=predictions)を submission.csv に出力して、これを提出します。
sub_df = pd.DataFrame({"card_id":df_test["card_id"].values})
sub_df["target"] = predictions
sub_df.to_csv("submission.csv", index=False)
果たしてランキングの結果は・・・?
上記で説明したようなプロセスを繰り返し、試行錯誤を積み重ねたわけですが、最終的には銅メダル(ブロンズメダル)を獲得することができました。
![]()
まとめ
Kaggleでは、多種多様な分野のデータセットとタスクが公開されており、挑戦することができます。
世界中のデータサイエンティスト・機械学習エンジニアと文字通り切磋琢磨する環境に身を投じることができます。
実戦的な感覚を磨き、知見や手法を体得する上で大変良い環境です。
今後も様々なコンペティションに参加して、実戦さながらのデータと課題に取り組んでデータサイエンティストとしての力を鍛えて行きたいと思います。
最後に
次世代システム研究室では、機械学習や統計処理に関心を持つ開発者、アーキテクト、データサイエンティストを求めています。
次世代システム研究室にご興味を持たれたらすぐに 募集職種一覧 からご応募してください。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD