2022.04.07
株マーケットの知識グラフの構築実践
こんにちは、次世代システム研究室のC.Zです。今回は知識グラフの紹介から株マーケットの知識グラフの構築実践まで共有したいと思います。
最初は日本の株をやりたいでしたが、必要なデータが取得しにくいため、中国の株マーケットを対象しました。なお、本文は初歩的な探索なので、定量的なデータを利用せず、定性情報を使って知識グラフの構築を行いました。
知識グラフは何か?
私は金融に関わる業務を担当していますので、金融領域の例を挙げたいと思います。
一般的な機械学習モデル、例えばARMA・GARCH・RNN・LSTMは金融領域でうまくいけないときが多いです。なぜかといいますと、上記モデルらが基本は時系列の分析になり、イベントやマーケットのturning pointが把握できないというわけです。

このような場合、やはり金融に関する「知識」がないと、妥当な予測がつけられないです。
ここでは、「知識グラフ」の出番になります。
まず知識グラフのイメージをつけましょう
Things, not strings. (文字列ではなく、ものだ)
これはGoogleが2012年「Knowledge Graph」を提出した際の宣伝語です。(Introducing the Knowledge Graph: things, not strings (blog.google))
発表記事に記載したように、Googleの知識グラフ最初の適用先は検索エンジンになり、なお3つの目的(強み)が挙げられました。
- 正しい結果を見つける(find the right thing)
- 最適なサマリー(get the best summary)
- もっと深く、広く(go deeper and broader)
まず簡単な例を挙げます。
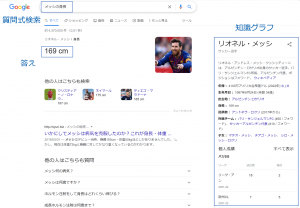
右のボックスがまさに一番直観的な知識グラフです。
但し、知識グラフの本質はそれだけではなく、Google記事のように3つの強みをこの例で説明します。
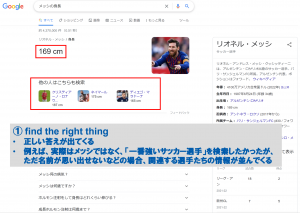
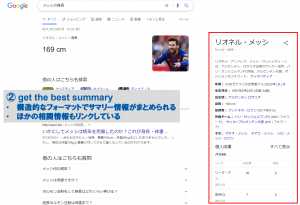
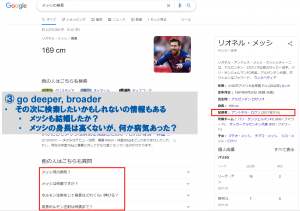
知識グラフの歴史と発展
1950~1980年代に、意味ネットワーク(Semantic Network)の研究をはじめ、「知識」ベースの研究が開始しました。その後、1998年のSemantic Webから2006年のLinked Data、現代意味の「知識グラフ」に段々近づけました。
「Knowledge Graph」という名前付けの製品は確かに2012年にGoogleより提出されましたが、各大手会社が実際はその前でも関連技術の研究を進めていました。

各コミュニティでも「知識グラフ」に関するプロジェクトが発展しています。例えば
- Wikidata
- WordNet | A Lexical Database for English (princeton.edu)
- The Linked Open Data Cloud (lod-cloud.net)
- ConceptNet
- CN-DBpedia (fudan.edu.cn)
「知識」の必要性
冒頭で一つ有名なDIKWモデルを紹介します。それぞれ分解すると、Data・Information・Knowledge・Wisdomになります。
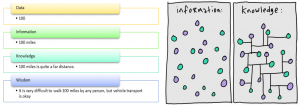
今までのモデルはほとんどInformation(Answer)まで止まります。
なぜKnowledgeが得られないですか?まずデータの特徴から解釈してみます。
インターネット上は膨大なデータが存在します。但し、各データソースやデータセットが異なる形で様々なところに配置しています。それをうまく統一する手段がないし、ある程度集計しても構造的なわかりやすい結果も得られないです。そのため、「知識」を獲得することが不可能です。
知識グラフはこれらの問題を解決するため提出された技術です。どうやって問題解決するかを理解するため、今までのコンピューター時代を整理してみましょう。
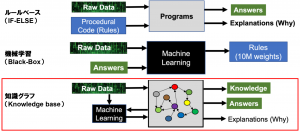
ルールベースの時代では、ルールが人間より設定されたため、答えと解釈ができますが、複雑な計算は対応できないという広い限界があるし、精度も期待あまりできないです。
機械学習時代はモデル精度が高いが、どうやって結果に導かれるかはBlack-Boxになり、解釈が難しいし、上記挙げた経済イベント発生する際への対応もほぼできないです。
一方、知識グラフの利用より、Rawデータだけではなく、機械学習の結果も知識グラフに導入することで、答えと解釈以外、知識も得ることができると期待しています。
知識グラフの紹介
知識グラフモデル
標準的な定義(gold standard definition)はまだないですが、実体(entity)と実体間の関係(relation)を表現するものと定義できます。つまり

具体な例を挙げると
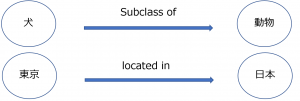
この基本のコンセプトをベースに、知識グラフの2つ主流モデルを紹介します。
RDF(Resource Description Framework)
RDFはWorld Wide Wed(W3C)により標準定義され、インターネットの情報を表現するため設計されたものです。モデルは三要素の形で表現できます。

それぞれの要素はURI、LiteralやBlankのタイプを利用することが可能です。詳細は略しますが、簡単の例を挙げます。

RDFの代表クエリ言語はSparkqlです。使用例として、Wikidataから公式の検索エンジンとサンプルページあります。(Wikidata:SPARQL query service/queries/examples – Wikidata)
PG(Property Graph) model
RDFと違い、インターネット情報向けのモデリングではなく、もっと汎用的、一般的なグラフデータを扱うことができ、定義済みのschemaへの依存度も低いです。なお、PGとRDFとの変換は簡単に行うことができます。
Property Graphは沢山有名なグラフデータベースに利用されています。例えば、今回の実践で利用されていたNeo4jもそうです。(DB-Engines Ranking – popularity ranking of graph DBMS)
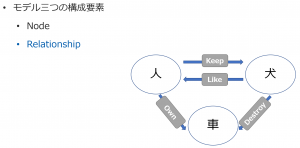
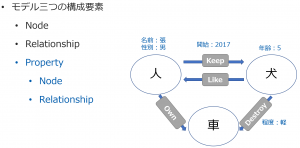
RDFと似ていますが、PGは別の形の三要素で構成されています。つまり
- Node
- Relationship
- Property
1つの例で説明します。

知識グラフ構築のフレームワーク
定義は幾らでもできますが、以下のように簡単に整理します。
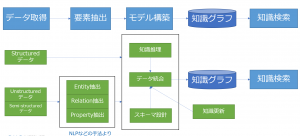
ほかのプロセスは略しますが、構造的なデータと非構造的なデータの扱い・「要素抽出」は何かについて、1つ例で説明します。

ここでは、構造的なデータは実際グラフデータにイコールではないですが、理解しやすいためグラフデータの形にしました。
株マーケットの知識グラフ構築
ここから本番の知識グラフ構築に入ります。
株マーケットの仕組み
細かく分解することは可能ですが、株マーケットの基本仕組みは以下のように表現できます。

需要と供給の基本原理から分かるように、株の発行数が限られているので、ある上場企業の株を購入したい投資家が多いほど、この株の株価が高くなるということです。
つまり、株の株価を解かるため、上場企業の情報だけではなく、投資家(特に大口)の情報も重要です。それで、投資家側の分解ももう少ししましょう。
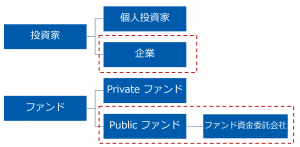
上記のように、プライベート側の情報が基本取得できないし、シェアも比較的に小さいため、赤いカッコの公的な情報は今回のデータ抽出対象になります。
知識グラフの構築
データの説明
- データソース:Tushare(中国株マーケットのデータ取得API:Tushare大数据社区)

- 利用データ
- 企業(上場企業、ファンド管理会社、ファンド資金委託会社)
- ファンド
- 管理層(上場企業、ファンド管理会社)
- 所在地(中国の省)
- 業界
- コンセプト(下記説明参考)
- コンセプト
- 投資可能の複数株から組み合わせできたportfolio
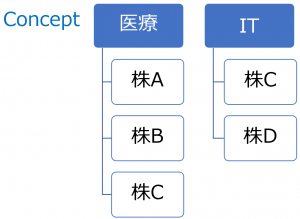
知識グラフのスキーマ設計
今回はPGモデル(Neo4j)を利用しますので、前述のようにPGの三要素のスキーマを設計する必要ががります。詳細は略しますが、データは以下のように作成しました。
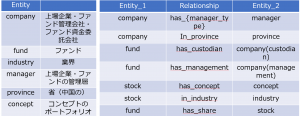
知識グラフの応用目的に応じ、三要素の配慮は重要です。例えば、Neo4jでは、RelationshipのPropertyを検索することができないので、companyとmanagerの種類はentityのところに複数labelをつけました。(詳細は略)
多少見にくいと思いますが、このスキーマはNeo4jの内蔵関数(schema.visulization)より表現できます。
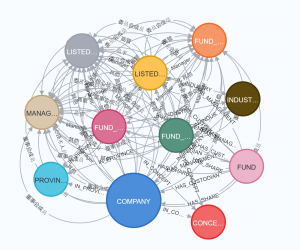
知識グラフの応用
Cypherの簡単紹介
PGの代表的なクエリ言語はCypherになります。イラストで簡単に紹介します。

以上のように、Cypherはグラフ構造なデータが処理対象なので、SQLのような紐づく(join作業など)が必要なく、スピーディーで処理可能ですし、自然言葉のようにクエリロジックが書けるので、直観的で分かりやすいのが特徴(強み)です。
応用例①可視化:中国広東の国有企業の業界・コンセプト状況を見てみたい
- クエリ
MATCH ci = (lc:LISTED_COMPANY)-[:IN_INDUSTRY]-(:INDUSTRY)
WHERE lc.code in ["000529","000060","000636","600259","600866","000973","002400","600183","600004"]
MATCH cc = (lc)-[:IN_CONCEPT]-(:CONCEPT)
MATCH cp = (lc)-[:IN_PROVINCE]-(:PROVINCE)
return ci, cc, cp
- 可視化
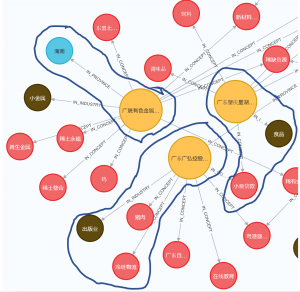
簡単な可視化ですが、新しい発見が簡単にできました。例えば、
-
- 出版業がメインな会社、実際は物流や食品運輸のビジネスもやっている
- 広東な会社だが、Headquarterは海南にある
- 食品業がメインな会社、実際は少額融資のビジネスをやっている
応用例②グラフ検索:もっとも投資されたBeijingの上場企業
- クエリ
MATCH (f:FUND)-[s:HAS_SHARE]->(lc:LISTED_COMPANY)-[:IN_PROVINCE]->(:PROVINCE {province:"北京"})
RETURN lc.company as company,count(DISTINCT f.fund_code) as fund_num,sum(s.mkv) as fund_market_value
ORDER BY fund_market_value DESC
limit 10
- 結果
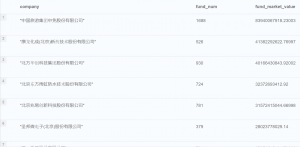
上記から分かるように、簡単なクエリで情報を抽出できますし、興味ある企業に続いて簡単にグラフより情報を確認できます。
応用例③投資推奨戦略:人気ファンドと類似する(共通な投資Conceptが多い)ファンドを推奨する
- クエリ(生Cypher)
MATCH p = (f1:FUND)-[:HAS_SHARE]->(:COMPANY)-[:IN_CONCEPT]-(c1:CONCEPT)
WHERE f1.fund_code="008270"
WITH COLLECT(DISTINCT c1.concept) as concept_base
MATCH (f2:FUND)-[:HAS_SHARE]->(:COMPANY)-[:IN_CONCEPT]-(c2:CONCEPT)
WITH f2.fund_code as fund_code,f2.name as name, concept_base ,collect(DISTINCT c2.concept) as concept_target
RETURN fund_code,name,
case when size([i in concept_target where i in concept_base]) > size([i in concept_base where i in concept_target])
then size([i in concept_base where i in concept_target]) else size([i in concept_target where i in concept_base])
end as same_invest_num
ORDER BY same_invest_num DESC
LIMIT 10
- クエリ(標準PluginであるApoc利用)
MATCH p = (f1:FUND)-[:HAS_SHARE]->(:COMPANY)-[:IN_CONCEPT]-(c1:CONCEPT)
WHERE f1.fund_code="008270"
WITH COLLECT(DISTINCT c1.concept) as concept_base
MATCH (f2:FUND)-[:HAS_SHARE]->(:COMPANY)-[:IN_CONCEPT]-(c2:CONCEPT)
WITH f2.fund_code as fund_code,f2.name as name, concept_base ,collect(DISTINCT c2.concept) as concept_target
RETURN fund_code,name,
apoc.coll.min([size([i in concept_target where i in concept_base]), size([i in concept_base where i in concept_target])])
as same_invest_num
ORDER BY same_invest_num DESC
LIMIT 10
- 結果

今回はシンプルなルールで投資推奨しましたが、もう少し戦略を考慮し、複数な条件を組み合わせることによって、もっといい推奨戦略ができるかもしれないですね。
最後
中国株マーケットの知識グラフを作りました。
しかし、Structuredデータを使っても、知識グラフのスキーマに合わせるため、データの前処理が大変でしたので、各機械学習手法を使って、Mappingの自動化が非常に重要な課題と認識していました。なお、人間ベースの知識推定(例えば投資推奨)が多少できましたが、機械学習手法との組み合わせがないと、限界を感じます。
一方、今までと違う視点でデータを見ることができまして、将来様々なデータ(ニュース情報、定量情報など)の追加より、本当の「知識」を作り出すことが期待できると考えます。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD