2022.04.07
自然言語処理(NER, RE)を使ってニュースデータから知識グラフを構築してみました
はじめに
こんにちは、次世代システム研究室のC.Wです。
知識グラフは近年流行始めた概念で、お恥ずかしいのですが今年に入ってから知識グラフの概念を知りました。その思想を分かればわかるほど高い興味が湧いていきて、これこそがデータの最終的な形式ではないのかと思い始めています。
ただ構築しやすくないのが知識グラフの問題であって、自然言語処理を使って一発の自動作成ができるとすごく嬉しいと思ったので今回のテーマを研究しました。それでは始めましょう。
TL;DR
- ニュースデータからグラフDBに落とすまでを一通り試して、結果は微妙だった
- 自然言語処理の結果がグラフの意義性を左右している
(言ってみれば当たり前のことです!)
知識グラフの概要
知識グラフとは、グラフ構造のデータモデルまたはトポロジを使用してデータを統合する知識データベースです。すなわち「知識」と言う抽象的なものをグラフ構造に保存する様なデータベースと理解しています。グラフ構造ではnodeとedgeの組み合わせなので、AとBとその関係性の知識をデータ化すれば知識グラフになれると思います。ただ知識は脳に保存しているもので、どこかに構造化しているデータではありません。なのでA, Bと関係性のデータを取得するためには、人間が理解できる様なロジックで書かれている文章から読み取れば幅広い関係の再現ができるかと思っています。そのために今回はニュースデータからA, Bと関係性の抽出を試してみました。
関わる自然言語処理のタスク
上記AとBとその関係性を取り出すには、まずAとBの認識、と関係性の抽出の2タスクとなっています。自然言語処理の中ではこの様なタスクは下記の2種類に分類されています
Name Entity Recognition (NER):AとBの認識
固有表現抽出(こゆうひょうげんちゅうしゅつ、英: named entity recognition)とは、計算機を用いた自然言語処理技術の一つであり、情報抽出の一分野である。文中から固有表現 (Named Entity) を抽出し、それを固有名詞(人名、組織名、地名など)や日付、時間表現、数量、金額、パーセンテージなどのあらかじめ定義された固有表現分類へと分類する。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
Relational Extraction (RE):関係性の抽出
関係抽出タスクは、テキストまたはXMLドキュメントの中の意味関係を検出して分類するタスクです。このタスクは情報抽出(IE)のタスクと非常に似ていますが、IEはさらに、繰り返される関係の削除を必要とし、一般に多くの異なる関係の抽出を指します。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
PFN
NERとREのタスクのために、今回試したモデルはPartition Filter Network、略してPFNです。(日本の機械学習界で有名なあのPFNではないです)
2021年11月で公開されたモデルで、ブログを書いている現在でもWebNLGデータセットの最高精度を達しているモデルであります(Paperwithcodeランキング)。 その特徴としては、NERとREを別々のタスクと考えていなく、同じタスクと考えているので、一部の特徴量を共通で利用していて同時に学習をしています。
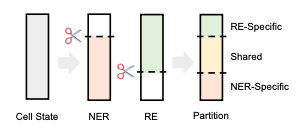
Partition Filter Encoder
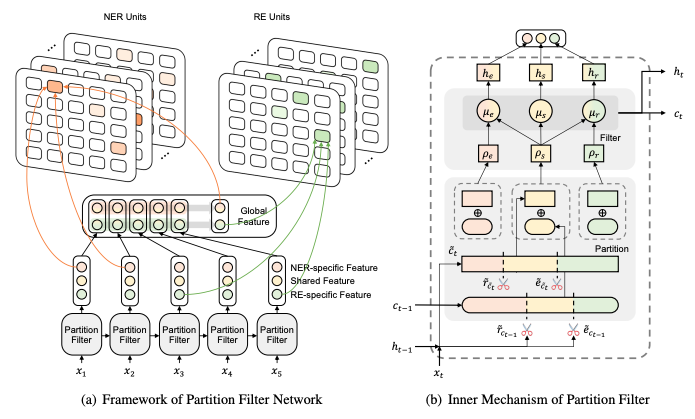
PFNではLSTMと似た様な流れで回帰的学習をしていますが、LSTM unitではなくをPartition Filter Encoderと言う単位で学習をしています。そのステップは
- Partition: ニューロンをtask specific partition(NER-specific, RE-specific)とshared partitionに分ける
- Filter: LSTMに似たctとhtを出力するときはtask specific partitionをフィルターする
で実装をしています。
実装
データソース
ニュースデータは News API (https://newsapi.org/) から取得しています。ロイター(Reuters)、ブルームバーグ(Bloomberg)、アルジャジーラ(Al Jazeera)等世界でのメインはニュース発信源は勿論、ビジネスワイヤ(Business Wire)からSeeking Alphaの記事など特定領域に偏っているサイトのコンテンツもAPIのデータ取得対象となっているので幅広いニュースデータを収集することができます。
対応している言語は英語がメインで日本語がないのが一番残念な点です。しかしNERやREのタスクでは英語を対象としているモデルの方が進展しているので、garbage in garbage outを避ける視点でも今回は英語のデータを使いました。
もう一つ大きい利点は開発中やテストプロジェクトであれば個人と企業の両方とも無料枠で使えるのが利点です(フリーミアム最高!)。無料枠にはリクエストの制限や歴史データの期間制限があるので、あくまでもスモールテスト用って感じですね。ちなみに公式サイトで書かれてない無料枠の制限は1requestの取得上限が100までなので、dateで切ると100記事以上あった場合は前の100記事しか取得できない状況です。
今回は最近のウクライナ情勢で石油価格に激しい値動きがあるのを見かけて、石油関連の企業がどのように対応をしているかがすごく気になったので、世界でトップの石油関連企業に関わるニュースを使ってを知識グラフを構築できるかどうかを試してみました。
使ったキーワード(ザ・石油企業)は以下の通りです:
- Exxon Mobil
- Saudi Aramco
- Chevron
- Shell
- Petrochina
- Total Energies
requestsでデータの取得をして
import requests
from collections import defaultdict
api_key = ****
api_template = 'https://newsapi.org/v2/everything?q={query}&from={from_param}&to={to_param}&apiKey={api_key}&language={language}&sortBy={sortby}&pageSize={pg_size}&page={pg}'
sortby = 'relevancy'
language = 'en'
pg_size = 100
pg = 1
querys = ['exxon mobil','saudi aramco', 'chevron', 'shell', 'petrochina', 'total energies']
date_range = pd.date_range(start=START_DATE, end=END_DATE, freq='D').strftime('%Y-%m-%d').tolist()
dic_res = defaultdict(dict)
for query in querys:
for date_ in date_range:
from_param = date_
to_param = date_
url = api_template.format(query=query, from_param=from_param, to_param=to_param, api_key=api_key, language=language, sortby=sortby, pg_size=pg_size, pg=pg)
try:
res = requests.get(url).json()
except ConnectionError:
print('ConnectionError')
time.sleep(5)
continue
dic_res[query][date_] = res
取得したデータをさらに整形すると
df_res = pd.DataFrame()
for query in querys:
for date_ in date_range:
res = dic_res[query][date_]
df_res = pd.concat((
df_res,
pd.DataFrame.from_dict(res['articles'])\
.assign(query=query, date=date_, totalResults=res['totalResults'])\
.assign(source_=lambda x: x['source'].apply(lambda x: x['name']))\
.drop(columns=['source'],inplace=False)\
.rename({'content':'trim_content', 'source_':'source'}, axis=1)
), axis=0)\
.reset_index(drop=True)
今回取得したデータは2022-02-20から2022-03-12の3週間分で、 丁度ウクライナ侵攻が始まって石油価格の乱れが始まったところです。それを使ってなにか企業に関わる面白いことがあるかを試してみました。
EDA(探索的データ分析)
データソース
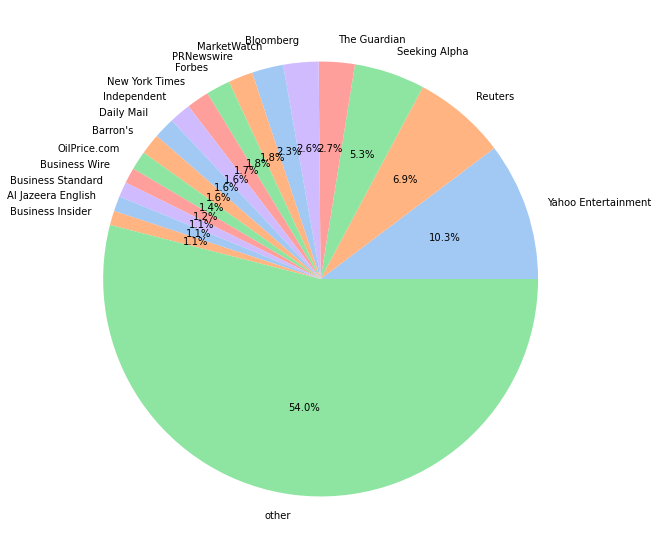
まずはデータソースの偏りによって結果のバイアスに至る可能性があるので、軽く記事の数をデータソースごとの分布で見てみました。表記されている%は取得した記事の全体の%で、othersは記事の割合が全体の1%以下のデータソースです。結論から言うと偏りが低いきれいな分布をしています。気になっているのはSeeking Alphaの記事の量が多かったのと、詳しく見るとジャーナリストが書いたニュース的なものではなく、個人投資家のアナリティックの記事だらけだったです。
ワードクラウド
次に試したのは自然言語処理タスク定番のワードクラウドです。pythonのwordcloudパッケージで一発で出せたので試してみました。意外にも企業をキーワードとして検索したとしても、出現頻度が一番多いのはinvasion Ukraine(ウクライナ侵攻)やRussia(ロシア)などの単語です。

PFN
PFNは公式のgithubを移植して使っています。学習の部分は特にコード変えてやっているわけではないので、紹介の割愛をします。詳細はGithubにて確認いただければと思います。実際にモデル推論しているところは下記の様にクラス化して実行をしています。
class Inferencer:
def __init__(self, model_file, embed_mode=None, hidden_size=300, dropconnect=0, dropout=0.):
”””
事前学習しているモデルの準備
”””
def inf(self, sent):
target_sent = findall(r"\w+|[^\w\s]", sent)
sent_bert_ids = self.tokenizer(target_sent, return_tensors="pt", is_split_into_words=True)["input_ids"].tolist()
sent_bert_ids = sent_bert_ids[0]
sent_bert_str = []
for i in sent_bert_ids:
sent_bert_str.append(self.tokenizer.convert_ids_to_tokens(i))
bert_len = len(sent_bert_str)
mask = torch.ones(bert_len, 1).to('cpu')
ner_score, re_score = self.model(target_sent, mask)
ner_score = torch.where(ner_score>=0.5, torch.ones_like(ner_score), torch.zeros_like(ner_score))
re_score = torch.where(re_score>=0.5, torch.ones_like(re_score), torch.zeros_like(re_score))
entity = (ner_score == 1).nonzero(as_tuple=False).tolist()
relation = (re_score == 1).nonzero(as_tuple=False).tolist()
word_to_bep = map_origin_word_to_bert(target_sent, self.tokenizer)
bep_to_word = {word_to_bep[i][0]:i for i in word_to_bep.keys()}
entity_ = []
triplet_ = []
entity_names = {}
for en in entity:
type = self.idx2ner[en[3]]
start = None
end = None
if en[0] in bep_to_word.keys():
start = bep_to_word[en[0]]
if en[1] in bep_to_word.keys():
end = bep_to_word[en[1]]
if start == None or end == None:
continue
entity_str = " ".join(target_sent[start:end+1])
entity_names[entity_str] = start
entity_.append((entity_str, type))
for re in relation:
type = self.idx2rel[re[3]]
e1 = None
e2 = None
if re[0] in bep_to_word.keys():
e1 = bep_to_word[re[0]]
if re[1] in bep_to_word.keys():
e2 = bep_to_word[re[1]]
if e1 == None or e2 == None:
continue
subj = None
obj = None
for en, start_index in entity_names.items():
if en.startswith(target_sent[e1]) and start_index == e1:
subj = en
if en.startswith(target_sent[e2]) and start_index == e2:
obj = en
if subj == None or obj == None:
continue
#print("triple: {}, {}, {}".format(subj, type, obj))
triplet_.append((subj, type, obj))
return entity_, triplet_
for sentence in tqdm(sentences):
entity, triplet = inferer.inf(sentence)
all_entity.append(entity)
all_triplet.append(triplet)
更に今回の目的としては、グラフ構造に落として知識グラフでentityの関係性を見ることなので、関係性の存在しないentityを取り除きます。
triplets_name = [y for (a,b,c) in all_triplets for y in [a,c]] triplets_name = list(dict.fromkeys(triplets_name)) triplets_entity = [y for x in all_entity for y in x if y[0] in triplets_name] triplets_entity = list(dict.fromkeys(triplets_entity))
neo4j
neo4jはグラフ構造に特化したデータベースです。グラフデータを扱うDBの中でもコミュニティの大きさではトップレベルなので、分からなかった所があってもすぐに解決できるためこちらを使いました。ドキュメントも充実して無料枠もあるのですぐに試せます。下記のコードでPFNから出力したentityとrelationで知識グラフを作りました。
from neo4j import GraphDatabase
from tqdm import tqdm
driver = GraphDatabase.driver(uri, auth=(user, password))
def add_entity(tx, name_, type_):
return tx.run('CREATE (p:{type_} {{name: "{name_}"}}) RETURN p'.format(name_=name_, type_=type_))
def add_realation(tx, name1, rel, name2):
return tx.run("""
MATCH (p {{name: "{name1}"}}), (q {{name: "{name2}"}})
CREATE (p)-[:"{rel}"]->(q)
""".format(name1=name1, name2=name2, rel=rel))
with driver.session() as session:
for name,type in tqdm(triplets_entity):
session.write_transaction(add_entity, name, type)
for name1,rel,name2 in tqdm(cap_triplets):
rel = rel.replace('-', '_')
session.write_transaction(add_realation, name1, rel, name2)
結果がこちらです。
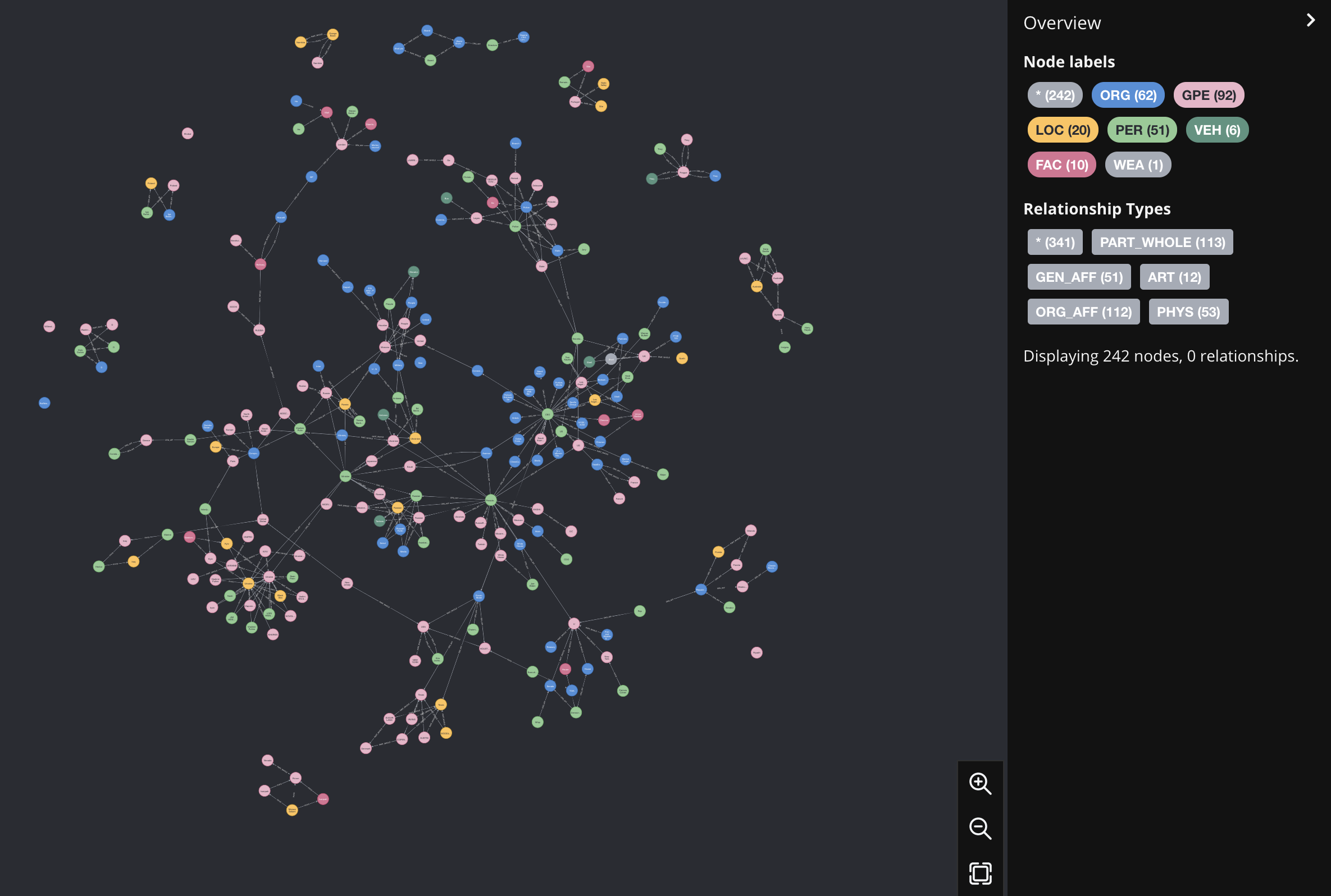
なんとなくグラフっぽい出力となって群がっている様に見えますね。ちゃんと石油価格との関連性が出てきたかをチェックしようと思った時に発見したのですが、実はNER/REの段階ですでに石油周りとの関係性の認識をしてなかったのです。実際の石油企業のキーワードで以下のクエリで何が出てくるかを見てみました。
match (n)--(a)--(b)--(c)--(d) where n.name in ['Exxon Mobil','Aramco', 'Chevron', 'Shell', 'petrochina', 'TotalEnergies'] and a.name<>'CEO' and b.name<>'CEO' and c.name<>'CEO' and d.name<>'CEO' and a.name<>'President' and b.name<>'President' and c.name<>'President' and d.name<>'President' return (n)--(a)--(b)--(c)
なんとなく欲しい知識グラフ的なものに似てきてはいますが、NER/REの精度で捉えているentityは地名と微妙なものばかりになってますね。とりあえず初歩的ニュースから知識グラフ作成のフローとしてはまあまあの結果だと思います。
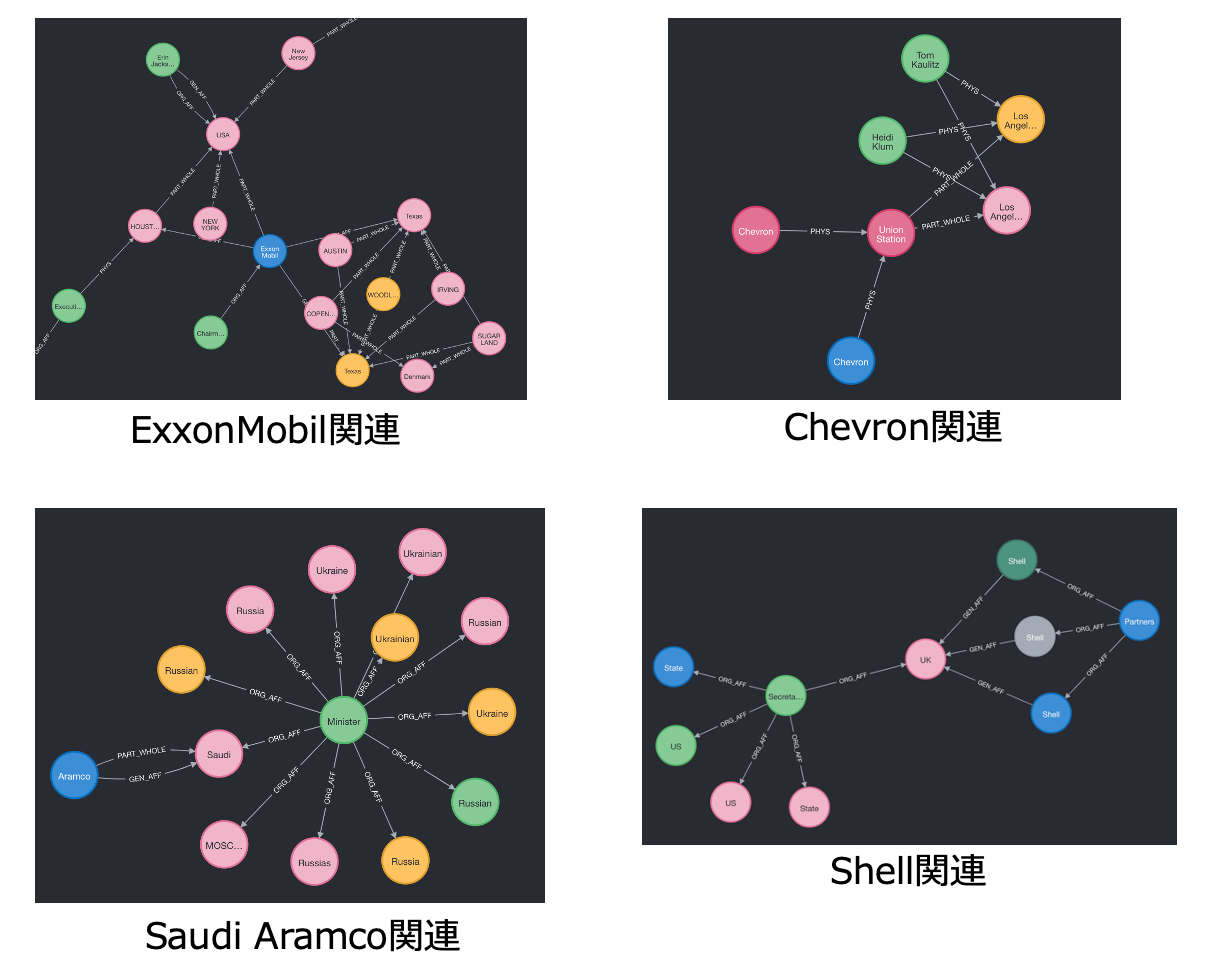
まとめ
今回は知識グラフ構築をニュースデータから試してみました。自然言語処理モデルの精度に大きく影響されてはいますが、それでも少し知識っぽいものが見えてきました。更にneo4jの扱いも一通り試してみました。次からは自然言語処理モデルの出力の有意義性にフォーカスして知識グラフ構築を深めていきたいと思っています!
最後に
次世代システム研究室では、ビッグデータ解析プラットフォームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方にはぜひ 募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD