2021.01.12
深層強化学習によるサッカーの局面解析 ~ XRL 強化学習の説明可能性 ~
こんにちは。次世代システム研究室のY. O.です。
私事で恐縮ですが筆者の特技は、仕事面ではデータ分析、趣味面ではサッカーです。
今回は、筆者の2つの特技を掛け合わせ、サッカーの局面分析を題材に、強化学習の説明可能性(XRL:eXplainable Reinforcement Learning)ついて記事にしていきます。
以下の画像は、今回の記事で作成した動画の切り抜きです。前半ではXRL全般について述べながら、最終的には作成したデモの解説をして締め括ります。

0. TL;DR
- 強化学習の発展に伴い、強化学習の説明可能性が求められるようになる!
- 強化学習の説明可能性手法には、教師あり学習モデルの説明可能性手法とは異なるものがある!
- サッカーゲームを深層強化学習で解析し、局面ごとにどの部分に着目するべきかを可視化した!
1. 強化学習の説明可能性(XRL)に関する背景
1-1. 強化学習
まずは強化学習の位置付けです。強化学習は、機械学習(≒ AI)の3大カテゴリ(教師あり学習・教師なし学習・強化学習)のうちの1つであり「Agentが環境で行動を繰り返し報酬が最大になる行動を学習する」というスキームでモデルのパラメータ等を獲得していきます(図1)。
今回詳細は省略しますが、次世代システム研究室では数年前から強化学習の動向を研究していますので、そちらをご参照ください(https://recruit.gmo.jp/engineer/jisedai/tag/強化学習/)。
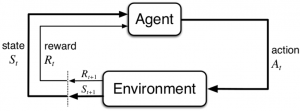
図1 強化学習の学習スキーム(Reinforcement Learning: An Introduction (Sutton, R., Barto A.))
1-2. 説明可能性
AIの説明可能性・説明可能なAI(XAI)というワードは、機械学習界隈では一般的ですし、最近では新聞でピックアップされることもあります(世界・日本問わず、AIが不公平・非倫理的な予測をしたことでサービスが停止に追い込まれるニュースを1度は耳にしたことがあるのではないでしょうか)。
このようなニュースにもあるように、機械学習モデルの判断根拠に説明性を持たせたいというモチベーションが機械学習分野にはあります。
1-3. 強化学習の説明可能性(XRL)
上記のXAIですが、ほとんどの議論は機械学習における教師あり学習・教師なし学習が対象となっています。すでに実社会において大きな成果を出しており、精度が高いだけではなく、どのような仕組みでその精度が達成されたのか・不平等な仕組みにはなっていないのか、のように判断根拠も知りたいと社会全体から要請されているのがその背景です。
では、機械学習の3大カテゴリのうち、強化学習(RL:Reinforcement Learning)はどうかというと、実社会から判断根拠を要請される場面はまだ少なく、研究自体も教師あり・教師なし程には多くありません。
例えば、強化学習の説明可能性(XRL:eXplainable Reinforcement Learning)手法についての初めてのSurvey論文は2020/5に発表されています(https://arxiv.org/abs/2005.06247)。
XRLの注目度が低いからといって、強化学習自体の注目が低いわけではありません。ゲーム・ロボットなどを中心に応用例も出てきていますし、今後の強化学習の発展に伴いXRLは現在のXAIのようにますます注目されていくと予想されますし、強化学習の実社会利用となれば必然的にXRLが注目されると考えられます(図2)。
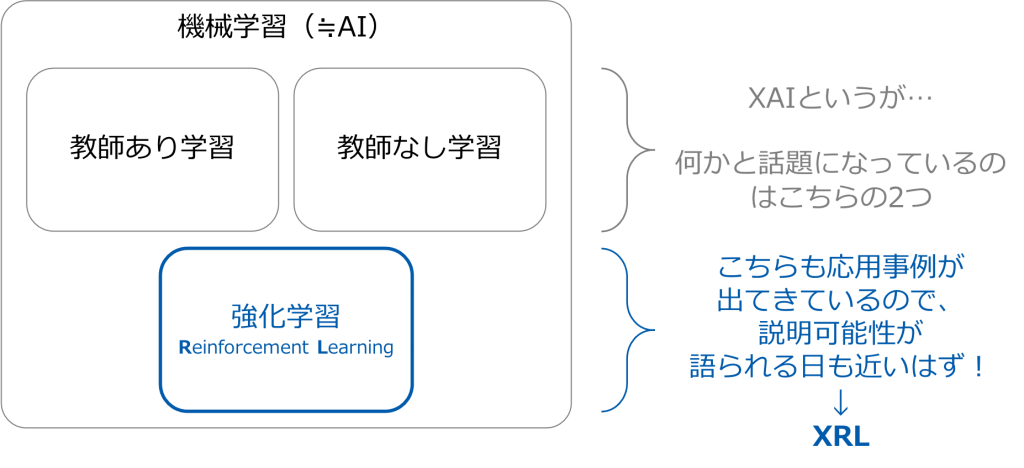
図2 機械学習の3大カテゴリとXRLの展望
2. 強化学習の説明可能性(XRL)の手法概観
それでは、XRLのSurvey論文(https://arxiv.org/abs/2005.06247・https://arxiv.org/abs/2008.06693)を参考に、提案されているXRL手法の概要を把握していきます。
その際、XAIの基礎資料としてよく引用される「Interpretable Machine Learning: A Guide for Making Black Box Models Explainable」(https://christophm.github.io/interpretable-ml-book/)などで提案されている以下の2つの軸を用いて、手法を2×2マトリクスに整理していきます(図3)。
- 「モデル全体が対象の手法か (Global)」vs「サンプル1つ1つが対象の手法か (Local)」
- 「モデルに組み込まれた手法か(Model-specific)」vs「モデルに依存しない手法か (Model-agnostic)」

図3 XRL手法名称の2×2マトリクスへのマッピング
機械学習分野の方でも図3の各種XRL手法を見て、ピンと来るものは少ないのではないでしょうか。一方、教師あり学習のXAI手法であれば聞き馴染みがあったり、概念を知っていたりする方が多いと思います。
そこで、教師あり学習のXAI手法との対比をしながら、図3のXRL手法の概要説明を作成しました(図4)。

図4 XRL手法の概要説明
教師あり学習のXAI手法と強化学習のXRL手法を比較すると、対象とするタスクが異なるため手法名称や実装方法は全く異なるのですが、4象限のうち3象限では両者が似た考え方を元に組成されている手法が多かったです。一方、右上の1象限では、教師あり学習のXAI手法とは異なる考え方を元に提案されたXRL手法が多いという結果になりました。
3. サッカーゲームをPFRLで解析
3-1. モチベーション・やったこと
モチベーション
- イニエスタはフィールドのどこを見て次のアクションを決めているのか?
- もし強化学習エージェントがイニエスタ並みの状況判断ができるようになれば、その思考を解析できるのではないか?
- もし強化学習エージェントがイニエスタを超える戦術眼を手に入れたら、Alpha Goのようにサッカーにおいても数億手先を読んだ最善アクションがわかるのではないか?
サッカー大好きデータサイエンティストの、純粋なワクワクを満たしたい!以上。
やったこと
Google Research Footballというサッカーの強化学習環境を利用し、ゴールすることを報酬にしてAgentを学習させました。サッカーというと11人 vs 11人のフルゲームなのですが、タスクの難易度が高すぎたため、今回は簡単に以下の2つの場面を対象とします。

図5 分析対象とした場面
また、Q値の推定にはRainbow(https://arxiv.org/abs/1710.02298)としてお馴染みのDeep Q-Network構成とし、EfficientNet-B0で特徴抽出した最終層をGrad-CAM(https://arxiv.org/abs/1610.02391)で可視化しています(図6)。
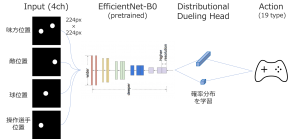
図6 構成したDeep Q-Network
3-2. Google Research Football
2019/7にGoogle Brainから公開された、サッカーの強化学習環境です(https://github.com/google-research/football)。論文では、サッカーのルールを全て実装した3Dビジュアルも作成できる新しい強化学習環境についての詳細と、強化学習エージェントに学習させた時のベースラインになる得点結果について報告されています(https://arxiv.org/abs/1907.11180)。
Google Research Footballについての概要と、筆者の使用感は以下の通りです。
- OpenAI Gymクラスを継承したPython用の強化学習環境
- 19のアクション(一般的なゲーム操作と同じ)
- 試合だけでなく、練習用のシナリオを複数用意している
- ルールを全て実装している
- ルールベースAIや、開発者が適度にトレーニングしたRLモデルをCOMとして対戦できる
- レポジトリは活発だが、ドキュメントが整備されていない部分も多く、環境構築など大変(1日溶かした…)
3-3. PFRL
今回は、2020/7にChainer RLの後継として発表されたPFRLを利用しました。その理由としては、PFRLがPyTorchベースのライブラリであること(筆者はPyTorchを普段使いしている)と、新しいライブラリなので使用してみたかった、の2点です。
筆者の使用感は以下の通りです。
- トレーニングラッパーなどが充実しており利用しやすい
- IMPALAなどの分散強化学習アルゴリズムや、R2D2などの最新DQNアーキテクチャは未実装
- 可視化は自分で実装する必要あり(他のフレームワークも然り)
3-4. 解析結果
キーパーなしPK
学習済みエージェントの行動と、Deep Q-Networkが注目している箇所を可視化し、動画にしました。
以上のような結果になりました。特にゴール直前においては注目箇所が顕著になっていますね(図7)。
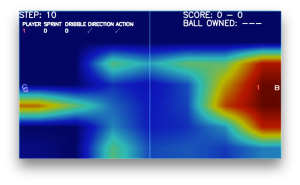
図7 ゴール直前の可視化画像
キーパーなしKickoff
上と同じく、学習済みエージェントの行動と、Deep Q-Networkが注目している箇所を可視化し、動画にしました。
さて、動画だとわかりづらいのですが、場面を切り出すと図8のようになりました。
時間が経過し、プレイヤー・ボールの動きとともに注目部分がゴールに近づいている、ように見えますね…。
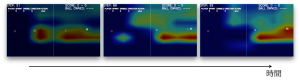
図8 時間経過と注目箇所
4. 最後に
デモを作成しましたが、Tesla P100を20時間回してやっとこのレベルです。筆者のエージェントがイニエスタに近づくには何年かかるのでしょうか…。
ただ、カスタマー行動などといったタスクより、ゲームやスポーツのようにルールが決まっていて(制約が多い環境下で)理想状態が定義しやすいタスクの方が強化学習には向いているし、XRL技術を用いることでその解釈を人間の意思決定にも活かすことができます(Alpha Goが多用する特殊な”手”は、プロ棋士の間でも定石となった。XRLはその”手”に解釈を与える)。
本記事では技術詳細を説明しませんでしたが、特に強化学習特有の説明手法については引き続き注目していきたいです。
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD