2023.07.03
ChatGPTでレシピちゃんを作ってみた
こんにちは。AI研究開発室のK.S.(女性、外国人)です。
今回はChatGPTとRaspberry Pi Robotでレシピちゃんを作ってみました!
本題に入る前に、早速、作ってみた可愛らしいレシピちゃんをご覧ください。
いかがでしょうか?
少しでも気に入っていただければ幸いです。
それでは、どうやって作ったかを共有したいと思います。今回は楽しい、可愛らしいをコンセプトに、真面目な理論を書いているわけではありません。子供のときの気持ちで、楽しく遊んでみましたので、今回のブログも軽い感じで書いてみました。
やったことは下記の流れです。
1. Raspberry Pi Robotの組み立て
Raspberry Pi は小さいハードウェアです。安価なコンピュータで、教育用として開発されましたが、最近は手軽にIoT開発でも利用されています。また、Raspberry Piは電子回路の制御を学べるように設計されて、手軽に回路を作ることができます。
今回使ったのはRaspberry Pi 4 Model B (8GB)です。Raspberry Piの中で良いスペックですが、節約したい時にスペックを少し落としても問題ないかと思います。また、Raspberry Piだけでもロボットを作れますが、可愛くないとテンションが上がらないので、今回はPiSlothという可愛らしいロボットと一緒に組み立てました。
準備
まず、必要なものを用意していきましょう。組み立てるため、主に、Raspberry Pi、PiSloth、バッテリーが必要です。それから、様々な設定のため、パソコンを用意しました。パソコンがない場合でも、モニターとキーボードとマウスがあれば設定できます。

組み立て
ここでは、手順通りにパーツを一つずつ組み立て行けば大丈夫です。ちなみに、適当に自分で手順を見逃してしまって、最初の完成版の足が逆になってしました。

それはそれで個人的に面白いと思いました。足が逆になっても、GPIO(集積回路、general-purpose input/output)が機能し、歩くコマンドをbackwardとforwardにすれば、どうにかなる気がしました。しかし、レシピちゃんがかわいそうなので、直しました。
組み立てが完成しましたので、PiSlothのEzblockソフトでテストしてみました。
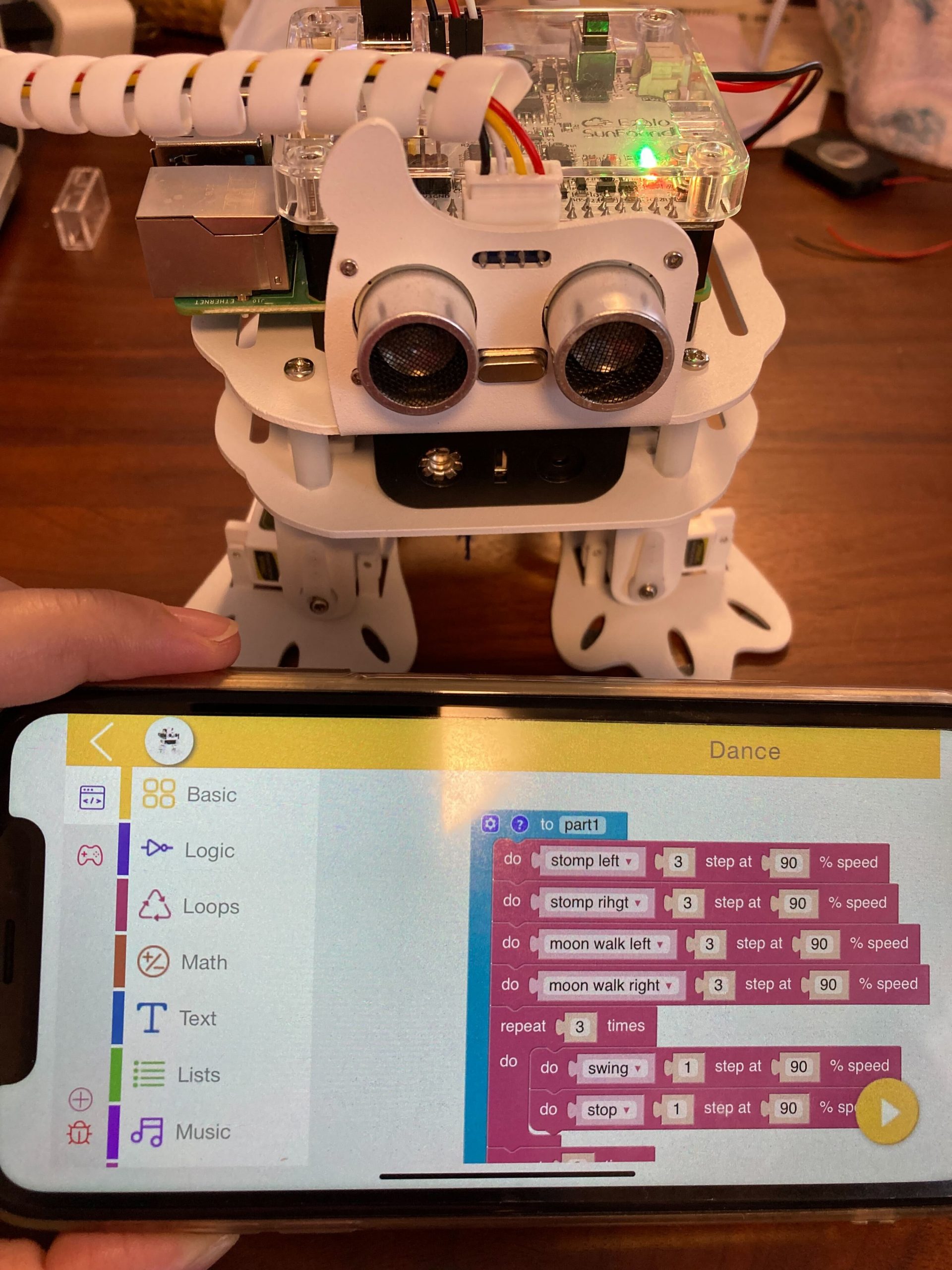
さて、レシピちゃんとダンスはこんな感じです。いけていますでしょうか。
ここまで来ると、PiSlothの設定は完了です。通常に遊べるようになりました。また、PiSlothでは、Text-To-Speed(TTS)の機能があり、話すようにプログラミングが可能ですが、残念ながら、Defaultは日本語に対応していないようです。そこで、今回は別途追加で実装しました。加えて、PiSlothはMicrophoneがないので、別途で用意しました。
2. ChatGPT APIの組み込み
ChatGPT(Chat Generative Pre-trained Transformer)は2022年11月に公開され、今年ずっと話題になっているので、聞いたことがない人はほとんどいないのではないでしょうか。ChatGPTは様々な質問や要望に対して文章で回答するAIチャットポットです。WEBサイトでタイプしてやりとりできますが、音声は今のところ出力していません。
また、ChatGPTにはAPI(Application Programming Interface)が用意されていて、多くのアプリケーションからAPI経由で利用できます。開発者は簡単にChatGPTを利用し、タスクを実行することができます。
Raspberry Pi Robotと接続するために、APIを使います。API実装の例は下記の通りです。promptを記入すれば、答えを返してくれます。
コード: OpenAI Chat
import openai
import requests
# Set OpenAI Chat Completion API Endpoint
ENDPOINT = 'https://api.openai.com/v1/chat/completions'
def get_chat_response(prompt):
# Set up API request headers
headers = {
'Content-Type': 'application/json; charset=utf-8',
'Authorization': 'Bearer ' + constants.openai_api_key
}
# Set API request data
data = {
'model': 'gpt-3.5-turbo',
'messages': [{'role': 'user', 'content': prompt }]
}
# Send API request
response = requests.post(ENDPOINT, headers=headers, json=data, timeout=60)
# Analyze API response
response_json = response.json()
message = response_json['choices'][0]['message']['content'].strip()
return message
3. レシピちゃんの実装
いよいよ、レシピちゃんの実装です。
実装環境の設定から、全体コードまで載せておきますので、興味がある方は参考になれば幸いです。
実装環境
Raspberry Pi OS (Unix-like operating system)でPythonベースで実装しました。Macのノートパソコンから、VScodeのRemote SSHで作業しました。
全体フロー
全体フローは下記です。Raspberry Pi Robot(PiSloth)にChatGPT APIと音声合成(TTS, Text-to-Speech)と音声認識(STT, Speech-to-Text)の技術を組み合わせます。BCMや障害回避の機能も繋ぐようにします。
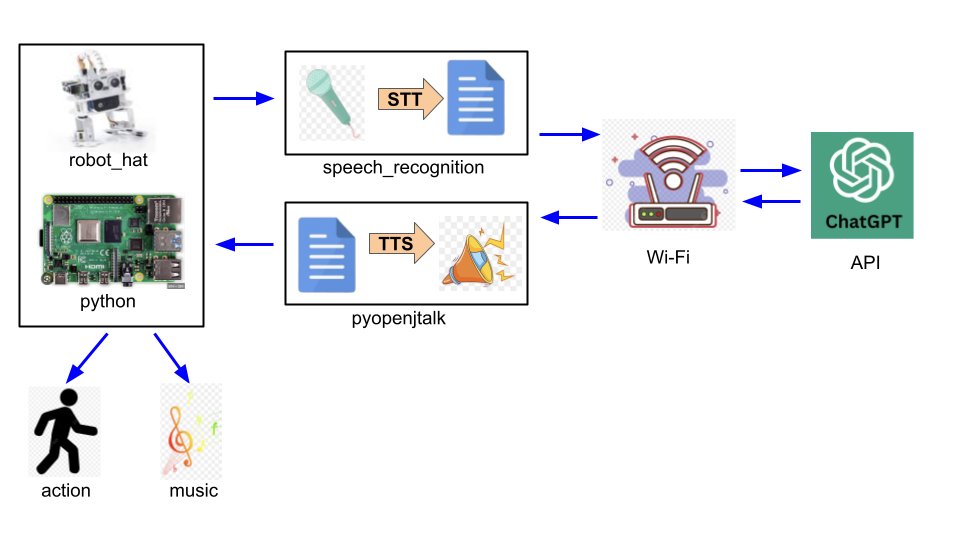
諸々のインストール
上記のように、Pislothの専用ソフトのEzblockがinstallされ、PiSlothの動きが確認できました。ここでは、Pythonをインストールし、OpenAIなどの関連ライブラリもインストールします。
コマンド: Install related libraries
# #### install necessary libraries # update and upgrade recent packages apt-get update apt-get upgrade # install robothat cd /home/pi/ git clone https://github.com/sunfounder/robot-hat.git cd robot-hat sudo python3 setup.py install # install pisloth cd /home/pi/ git clone -b v2.0 https://github.com/sunfounder/pisloth.git cd pisloth sudo python3 setup.py install # install i2samp cd /home/pi/pisloth sudo bash i2samp.sh # install related python libraries pip3 install openai pip3 install pyopenjtalk pip3 install scipy pip3 install SpeechRecognition sudo apt-get install flac
Microphone設定
ここまでで、Speakerは使えますが、Microphoneは認識できないため、MicrophoneとSpeakerが同時に使えるように、設定を変更します。
コマンド: MicrophoneとSpeakerの設定変更
Ref: http://keizan3105diy.xrea.jp/rdiy200503.htm
USBが接続できるかを確認し、USBとRobotHatの順番を確認します。
$ lsusb
$ cat /proc/asound/modules
0 snd_soc_rpi_simple_soundcard
1 snd_usb_audio
ここで、soundcard(speaker)が0で、usb micが1ですので、合わせて設定します。
$ sudo nano /home/.asoundrc
pcm.!default {
type asym
capture.pcm "mic"
playback.pcm "speaker"
}
pcm.mic {
type plug
slave {
pcm "hw:0,0"
}
}
pcm.speaker {
type plug
slave {
pcm "hw:1,0"
}
}
終わったら、再起動します。
$ sudo reboot
音声合成 (TTS, Text-to-Speech)
ここでは、ChatGPTが答えてくれたテキストを音声に変換します。
音声合成(TTS)は、テキストを自然な音声に変換する技術です。コンピューターやデバイスが文字列を読み上げ、人間のような声で発話します。ナビゲーションや音声アシスタントなどさまざまな場面で活用され、機械学習の進歩によって、より自然な音声が実現されています。バリアフリーや個人化にも貢献し、日常生活でますます重要な存在です。【因みに、このパラグラフはChatGPTが作成】
今回は、日本語の音声に合成するため、pyopenjtalk libraryを利用しました。pyopenjtalkは、日本語の音声合成エンジンであるOpen JTalkをPythonから利用するためのlibraryです。Open JTalkは、日本語のテキストを音声に変換するためのオープンソースのソフトウェアです。使い方は下記のようになります。
コード: TTS
def process_text_to_speech(text, wavfilename = "output/test.wav", stop_sound_flag=False):
x, sr = pyopenjtalk.tts(text)
wavfile.write(wavfilename, sr, x.astype(np.int16))
if stop_sound_flag==True:
mixer.music.stop()
audio = pygame.mixer.Sound(wavfilename)
audio.play()
return
音声認識 (STT, Speech-to-Text)
ここでは、ChatGPTに質問するため、音声を認識し、テキストに変更します。
音声認識(STT)は、音声をテキストに変換する技術です。音声入力を受け取り、それをテキストとして解析します。音声アシスタントや会議録音、音声入力メッセージなどに利用され、ディープラーニングの進歩により高い精度が実現されました。音声の特徴や言語モデルを利用し、音声をテキストに変換します。【因みに、このパラグラフはChatGPTが作成】
今回は、日本語の音声に変換するため、speech recognition libraryを利用しました。speech recognitionは、様々な音声ソースから音声データを受け取り、音声認識エンジンを活用してテキストに変換します。多くの場合、クラウドベースの音声認識APIやオフラインの音声認識エンジンとの連携をサポートしています。
日本語サポートを無料で使いたいので、Googleの音声認識APIを選びました。ちなみに、OpenAIが提供するWhisper APIも選べますが、有料なので選びませんでした。
コード: STT
def process_speech_to_text(speech_time, wavfilename = "output/test.wav"):
# record voice
cmd = "arecord -D plughw:1,0 -d {} -f cd {}".format(speech_time, wavfilename)
print(cmd)
os.system(cmd)
# convert speech to text
r = sr.Recognizer()
audio_file = os.path.join(os.path.dirname(os.path.realpath(__file__)), wavfilename)
print(audio_file)
with sr.AudioFile(audio_file) as source:
audio = r.record(source)
try:
text = r.recognize_google(audio, language='ja-JP')
print(text)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
return text
Background Music(BGM)の機能
ここでは、BGMを流せるような機能を作ります。
pygame libraryを利用します。下記は使い方の例ですが、実際は使いたいタイミングに合わせてコード書く順番を調整します。全体コードを参考にしてください。
コード: BGM
import pygame
from pygame.locals import *
from pygame import mixer
from robot_hat import Music
# set up initial
pygame.init()
mixer.init()
music = Music()
# set up volume
music.music_set_volume(20)
# load music file
mixer.music.load('output/christmas.mp3')
# start playing music
mixer.music.play()
# stop playing music
mixer.music.stop()</span>
動きや障害物回避の機能
ここでは、GPIOを通して、動きや障害物回避の機能を追加します。
PiSloth libraryでGPIOを実行します。Raspberry Piで直接に超音波距離センサーに繋いで、RPi.GPIO libraryなどで、GPIOを実行することも可能ですが、他の機能に合わせて、PiSlothのrobot_hatを使うのが便利ですので、 robot_hatのUltrasonicを実装しました。
コード: GPIO
from pisloth import Sloth
from robot_hat import Ultrasonic, Pin
def dont_touch_me(wavfilename):
sloth = Sloth([1,2,3,4])
sloth.set_offset([0,0,0,0])
sonar = Ultrasonic(Pin("D2") ,Pin("D3"))
alert_distance = 50
distance = sonar.read()
if distance <= alert_distance:
process_text_to_speech("あー、僕が邪魔ですか。移動しますね", wavfilename)
sloth.do_action('turn right', 4, 90)
sloth.do_action('forward', 2, 90)
else:
sloth.do_action('stand', 1, 90)
time.sleep(1)
全体のコード
ファイルが二つになります。一つはconstants.pyで、OpenAIのAPI keyを管理するためのものです。もう一つはmain.pyで、下記の全体コードになります。
コード: 全体のコード
import os
import os
import re
import time
from scipy.io import wavfile
import numpy as np
import requests
import pyaudio
import pygame
from pygame.locals import *
from pygame import mixer
import pyopenjtalk
import speech_recognition as sr
from pisloth import Sloth
from robot_hat import TTS, Music
from robot_hat import Ultrasonic, Pin
import openai
import constants
# Set OpenAI Chat Completion API Endpoint
ENDPOINT = 'https://api.openai.com/v1/chat/completions'
def get_chat_response(prompt):
# Set up API request headers
headers = {
'Content-Type': 'application/json; charset=utf-8',
'Authorization': 'Bearer ' + constants.openai_api_key
}
# Set API request data
data = {
'model': 'gpt-3.5-turbo',
'messages': [{'role': 'user', 'content': prompt }]
}
# Send API request
response = requests.post(ENDPOINT, headers=headers, json=data, timeout=60)
# Analyze API response
response_json = response.json()
message = response_json['choices'][0]['message']['content'].strip()
return message
def move_forward():
sloth = Sloth([1,2,3,4])
sloth.set_offset([0,0,0,0])
sloth.do_action('forward', 2, 90)
return
def process_speech_to_text(speech_time, wavfilename = "output/test.wav"):
cmd = "arecord -D plughw:1,0 -d {} -f cd {}".format(speech_time, wavfilename)
print(cmd)
os.system(cmd)
r = sr.Recognizer()
audio_file = os.path.join(os.path.dirname(os.path.realpath(__file__)), wavfilename)
print(audio_file)
with sr.AudioFile(audio_file) as source:
audio = r.record(source)
try:
text = r.recognize_google(audio, language='ja-JP')
print(text)
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
return text
def process_text_to_speech(text, wavfilename = "output/test.wav", stop_sound_flag=False):
x, sr = pyopenjtalk.tts(text)
wavfile.write(wavfilename, sr, x.astype(np.int16))
if stop_sound_flag==True:
mixer.music.stop()
audio = pygame.mixer.Sound(wavfilename)
audio.play()
return
def simple_dance():
sloth = Sloth([1,2,3,4])
sloth.set_offset([0,0,0,0])
sloth.do_action('swing',2,bpm=129)
sloth.do_action('moon walk left',2,bpm=129)
sloth.do_action('moon walk right',2,bpm=129)
def dont_touch_me(wavfilename):
sloth = Sloth([1,2,3,4])
sloth.set_offset([0,0,0,0])
sonar = Ultrasonic(Pin("D2") ,Pin("D3"))
alert_distance = 50
distance = sonar.read()
if distance <= alert_distance:
process_text_to_speech("あー、僕が邪魔ですか。移動しますね", wavfilename)
# sloth.do_action('backward', 2, 90)
sloth.do_action('turn right', 4, 90)
sloth.do_action('forward', 2, 90)
else: sloth.do_action('stand', 1, 90)
time.sleep(1)
def main():
pygame.init()
mixer.init()
music = Music()
music.music_set_volume(20)
# set up prompt filename
wavfilename = "output/test.wav"
# Greeting prompt0 = "こんにちは 御用はなんですか?"
process_text_to_speech(prompt0, wavfilename)
move_forward()
# Get order process_text_to_speech("10秒で指示をください〜", wavfilename)
prompt = process_speech_to_text(10, wavfilename)
mixer.music.load('output/christmas.mp3')
mixer.music.play()
process_text_to_speech("承知しました。調べますので、音楽を聴きながら、少々お待ちくださいね〜", wavfilename)
# Get Chatbot response and process TTS
chat_response = get_chat_response(prompt)
# print('Chatbot: ' + chat_response)
process_text_to_speech("お待たせしました。答えは ", wavfilename)
process_text_to_speech(chat_response, stop_sound_flag=True)
simple_dance()
timeout = time.time() + 60*5 # 5 minutes from now
while True:
if time.time() > timeout:
break
dont_touch_me(wavfilename)
if __name__ == "__main__":
main()
ここまでで、なんとか動きました。実際に欲しい機能が動くかを確認できましたが、コードのロジックまだ課題が残っています。
4. ハマったら
PiSlothが動かない場合
PiSlothのPython環境はなぜか動かないので、Ezblockベースにして、Pythonを追加するのが無難です。
エラーが出た場合
NotADirectoryError: [Errno 20] Not a directory: '/home/pi/.config/robot-hat' このようなエラーが出たら、ファイルを削除すれば解決できます。
sudo: unable to resolve host PiCar-X: Name or service not known このようなエラーが出たら、下記のようにhostを追加してみてください。 sudo sh -c 'echo 127.0.1.1 $(hostname) >> /etc/hosts'
5. まとめと考察
今回はレシピちゃんを作ってみました。ChatGPTの自然言語モデルに自然な音声合成(Text-To-Speech)と自動音声認識(Speech-To-Text)の技術を一体化しました。また、レシピの目には超音波距離センサーがあり、障害物回避のための距離検出に利用でき、避けるように実装してみました。
しかし、ChatGPTには待ち時間があり、即答会話ができませんでした。静かすぎると、寂しいので、代わりに、Background Music (BGM)を流せる機能を実装しておきました。
楽しかったです! みなさんも少しでも楽しんで頂ければ幸いです。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室に興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD