2019.10.07
強化学習(Advantage Actor-Critic)はFX取引できるか(基礎)
こんにちは。次世代システム研究室のY.R.です。外国人です。
本ブログでは、強化学習を用いて、FX取引を試してみたので、その結果を共有いたします。
1. 定義
強化学習の定義は次のとおりです。「強化学習(きょうかがくしゅう、英: Reinforcement learning)とは、ある環境内におけるエージェントが、現在の状態を観測し、取るべき行動を決定する問題を扱う機械学習の一種。エージェントは行動を選択することで環境から報酬を得る。強化学習は一連の行動を通じて報酬が最も多く得られるような方策(policy)を学習する。」(wikipediaより引用)
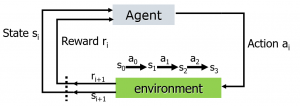
強化学習のモデルを上図に示します。エージェントと環境の間のインターフェース(Agent)には、アクション(Action)、タイムリーな報酬(Reward)、およびステータス(State)が含まれます。各ステップで、エージェントはポリシー(Policy)に基づいてアクションの実行を選択し、次の状態を認識してタイムリーに戻り、経験を通じて独自の戦略を変更します。エージェントの目標は、タイムリーな報酬(Reward)ではなく、長期的なリターン(Return)を最大化することです。
2.強化学習の進展
近年、強化学習の発展は著しく、特にゲーム領域において、コンピュータが人間に勝る成果を残しています。
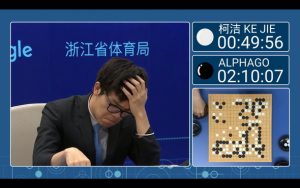
AlphaGo https://ja.wikipedia.org/wiki/AlphaGo
強化学習のブレイクスルーといける成果として、AlphaGoが挙げられます。AlphaGoはGoogle DeepMindによって開発されたコンピュータ囲碁プログラムです。 2017年5月には、七回の世界チャンピオンの柯潔との三番勝負で3局全勝を挙げ、中国囲棋協会にプロの名誉九段を授与されました。コンピュータが人間に打ち勝つことが最も難しいと考えられてきた分野である囲碁において、人工知能が勝利を収めたことは世界に衝撃をもたらしました。AlphaGoの登場は単なる一競技の勝敗を越え、人工知能の有用性を広く知らしめました。
https://aitube.io/video/poker-ai-libratus/
また、ポーカーにおいても、強化学習はその威力を発揮しています。2017年1月にペンシルベニア州ピッツバーグのリバーズカジノで開催されたテキサスホールデムマンマシンバトルにおいて、カーネギーメロン大学(CMU)が開発したAIプログラムであるLibratusは、人間のトッププロ選手を破り、賞金20万ドルを獲得しました。囲碁や将棋と違い、カードゲームの「ポーカー」では相手の手札が公開されていない不完全な応報の中での戦いを強いられる「不完全情報ゲーム」であるため、ポーカーは一般的に最良の手を探し出すアルゴリズムの開発が難しいゲームとして知られています。そのため、AIの進化の尺度を示すものとしてポーカーは機能してきたという側面があり、人間のプロプレイヤーを破るという快挙をカーネギー・メロン大学で開発されたAI「Libratus」が成し遂げたことは、AI開発の歴史的偉業だとたたえられています。

https://deepmind.com/blog/article/alphastar-mastering-real-time-strategy-game-starcraft-ii
また、コンピュータゲームにおいても、強化学習の驚異的な進展みられました。人工知能(AI)企業のDeepMindが開発しているAI「AlphaStar」が、Blizzard Entertainmentのリアルタイムストラテジー(RTS)「スタークラフト2」でプロのトッププレイヤーであるTLO氏とMaNa氏と対戦し、10連勝を達成しました。このようなゲームは、ゲームがリアルタイム進行、不完全情報、極めて広大な行動空間を持つ、という特徴があり、人間のプロに打ち勝つことができたのは、AI分野においてかなりのブレイクスルーとなりました。
今挙げたように、強化学習はこれまでの常識からは考えられないほどの成果を達成してきました。それでは、強化学習は金融取引分野においても、人間より優れた性能を達成できるのでしょうか?
3.方法によってのクラスタリング
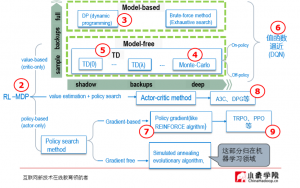
強化学習は包括的な領域であり、アイデアに従ってさらに分類することができます。
Value based: これの目的は、最適な報酬の合計を見つけ、すべてのアクションの価値を出力し、最高の価値に基づいてアクションを選択することです。このタイプの方法は、直感にわかりやすいです。しかし、行動空間が連続量の状況では使用が難しくなるという問題があります。代表的なモデルは:Q-learning(Deep Q-learning), SARSAです。
Value based 強化学習に興味があれば、「Deep Q-LearningでFXしてみた」に参考してお願いします。
Policy based: これの目的は、置かれている環境を分析し、与えられる状態をインプットとして次のステップで実行すべきアクションの確率を直接求め、アクションを実行することにより、最適な戦略を見つけることです。代表的な方法はPolicy Gradientsです。
更に、両方の方法の利点を組み合わせたActor-Criticと呼ばれるアルゴリズムもあります。
4.Actor-Critic
これからActor-Criticという強化学習方法を紹介します。
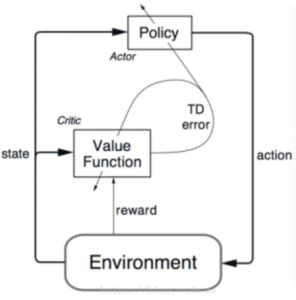
最初は最適行動がわからないので、ランダムにアクションを試していきます。批評家(Critic)はあなたの行動を観察し、フィードバックを提供します。実践者(Actor)はこのフィードバックから学習して、ポリシーを更新し、そのゲームをより上手にプレイします。一方、評論家もフィードバックを提供する独自の方法を更新して、次回のフィードバックを改善できるようにします。外側のリングのポリシー部分を個別に見ると、これは一般的なポリシーベースの方法であり、内部の更新のみを調べ、値ベースの方法である。したがって、ACメソッドは、ポリシーベースと値ベースを組み合わせたメソッドです。
Q関数を利用して擬似コード は以下の通りです。
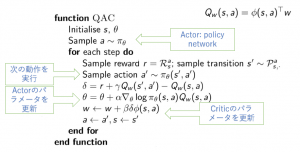
Actor-Criticの特徴はActor とCritic両方がステップで更新されるということが分かります。
Actor-Criticで良く知られているアルゴリズムはAsynchronous Actor-Critic Agents (A3C)です。A3Cの構築は次のグラフ(左)で示しています。A3Cで複数のAgentはそれぞれの環境(Env)を探索してニューラルネットワークを学習していきます。学習完了後、それぞれのパラメータの勾配情報をマスター各のネットワーク関数に非同期に更新します。これにより、複数のAgentの施行結果に基づき、パラメータの更新がなされるので、学習効率が良くなります。さらに、A3Cの非同期更新を同期更新、つまり全てのAgentの施行が完了してから更新を行う、Actor-Critic Agents (A2C)という方法(グラフ(右))が提出されました。この同期更新により、GPUのutilityが向上し、より学習効率が向上します。
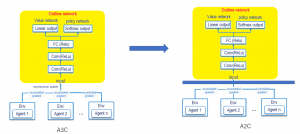
今回は、FX取引に対して、A2Cの応用を検証しました。
5.取引で検証
データソース
USDJPY 1分間のレベルの相場データ
https://www.histdata.com/download-free-forex-historical-data/?/ascii/tick-data-quotes/USDJPY
トレーニング:2019/05/01-2019/07/31
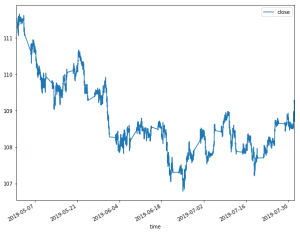
テスト: 2019/08/01-08/12
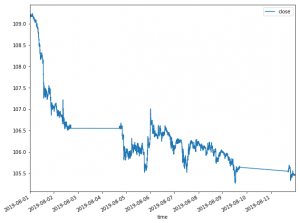
フレームワーク
PPO2-currency-trader
https://github.com/pipatth/PPO2-currency-trader
このプロジェクトでstable-baselines, RLTraderが利用されています。名前にPPO2とありますが、A2Cに替えて検証しています。
特に強化学習に関しての説明は以下の通り
Action: long, short (10%->100%) and hold
State: 最近(n=50)のOHLC (Open-High-Low-Close)
Reward: net value
結果
デモのスクリーンショップ
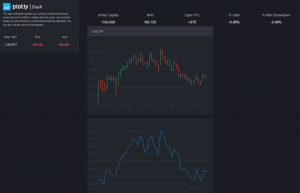
仮に私たちの投資金額は100,000円です。このグラフで一つの瞬間の収益を示している。
評価として取引の売買価格、残された資金、収益金額、収益率と最大ドローダウンを含めている。具体的にグラフの瞬間で私たちは損失(-875円)が出ています。
全体の収益
テスト期間で全体収益の状況は以下の通り
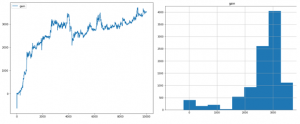
最後A2Cにより収益率(左)は3.53%に達して、MDDは-1.3%になっている。
始まりマイナス収益が出ていたが、ステップにつき収益は改善して来た。詳しい分散状況は右側のグラフによって、大体2,000から3,000ぐらいに置いてある。
8月の上旬で大きい落ちることが起こっていたのに良い結果と思います。
6.これからの計画
金融相場は変わりつつある相場ですから、広い範囲のデータで特に各状況の上でA2Cをトレーディングして検証する必要があります。通用性は重要な評価指標です。
更に、伝統的な取引方法(例えば、2重指数移動平均)と比較して評価する必要があります。長い時間をかけて取引者はいろいろな方法を提出しました。これらの方法と比べてAIによる取引はどうなるか?どんな条件でいい結果を取ることができるか? これらの疑問について今後ブログで答えていく予定である。
つつく
参考
Asynchronous Methods for Deep Reinforcement Learning
https://arxiv.org/pdf/1602.01783.pdf
OpenAI Baselines: ACKTR & A2C
https://openai.com/blog/baselines-acktr-a2c/
最後に
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD