AWSアカウント不要!Sagemaker Studio Labで無料でGPU機械学習お試し環境を手に入れちゃおう!と思ったけど、GPUインスタンスはなかなか起動しないし、諦めてお金を払った方が良い。
まとめ
表題の通りです。Sagemaker Studio Labはアカウントを作れば、GPUインスタンス作成ボタンを押すだけでjupyterが使えるようになっているGPUインスタンスが建つ、はずなんですが、時間帯を変えながら何回ボタンを押してもこの通り。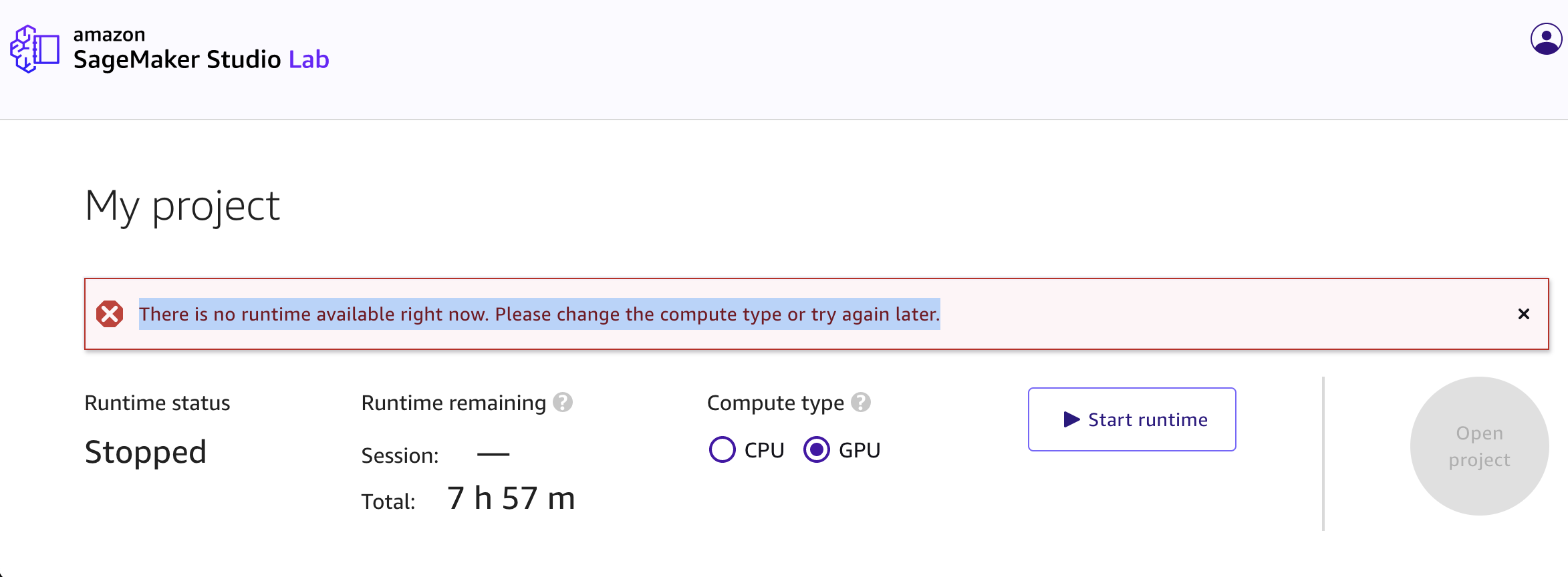
終
制作・著作
━━━━━
G M O
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。・・・
以下おまけ
みなさん、こんにちは。グループ研究開発本部、AI研究開発室のY.Tです。もう言いたいこと全部書いたので終わりでいいんですけど、もう少しSagemaker Studio Labについて色々書いていこうと思います。お暇な方はお付き合いください。
今回の目的は、「Sparkによる分散処理環境+jupyter環境の小規模なテスト環境」を「無料あるいはほぼ無料でクラウド上で使えるようにする」ことです。
まず、いくつかドキュメントに目を通し、用途にあいそうなクラウドサービスを探しました。
そこで見つけた候補は以下の通りです。
- AWS(Amazon Sagemaker Studio)
sparkを試す程度であれば無料枠+α 程度のコストでなんとかなりそう。
公式ブログにそのままのハンズオンもあり学習もしやすい。
https://aws.amazon.com/jp/blogs/news/load-and-transform-data-from-delta-lake-using-amazon-sagemaker-studio-and-apache-spark/ - GCP
こちらも無料枠の範囲でなんとかやっていけそう。
Dataproc、BigQuery、Apache Spark ML の環境はこちらの公式チュートリアルが参考になる。
https://cloud.google.com/dataproc/docs/tutorials/bigquery-sparkml?hl=ja#spark-ml-tutorial_subset-python - Azure
クラウドの無料枠は一部のサービスと30日間の200USD分のクレジットが利用可能
Azure Synapse Analyticsが奥的にマッチしているサービスのようだ。
https://learn.microsoft.com/ja-jp/azure/synapse-analytics/spark/apache-spark-data-visualization-tutorial - databrics
Sparkといえばここ。14日間の無料トライアル及び、Sparkの学習を目的とした1ノードの制限があるcommunity版が使えます。
https://www.databricks.com/jp/product/pricing
さすがというべきかsparkのチュートリアルなどは豊富です。
ごく個人的な感想ですが、課金単位のdatabrics unit(DBU)が少しわかりづらい… - IBM
無料利用期間の制限がないらしい。
IBM Cloud無料利用枠
https://www.ibm.com/jp-ja/cloud/free
もう少し調べていけば、Sagemaker Studioの無料お試し版とでもいうべき「Sagemaker Studio Lab」というサービスがある様子。まずはこちらから使ってみるのが良さそう、と目をつけました。
Sagemaker Studio Labとは
Amazon SageMaker Studio Lab は、無料の機械学習 (ML) 開発環境であり、コンピューティング、ストレージ (最大 15 GB)、セキュリティをすべて無料で提供し、誰でも ML を学んで実験できます。
https://aws.amazon.com/jp/sagemaker/studio-lab/ より
素晴らしいですね。
全体のアーキテクチャはこのようになっています。
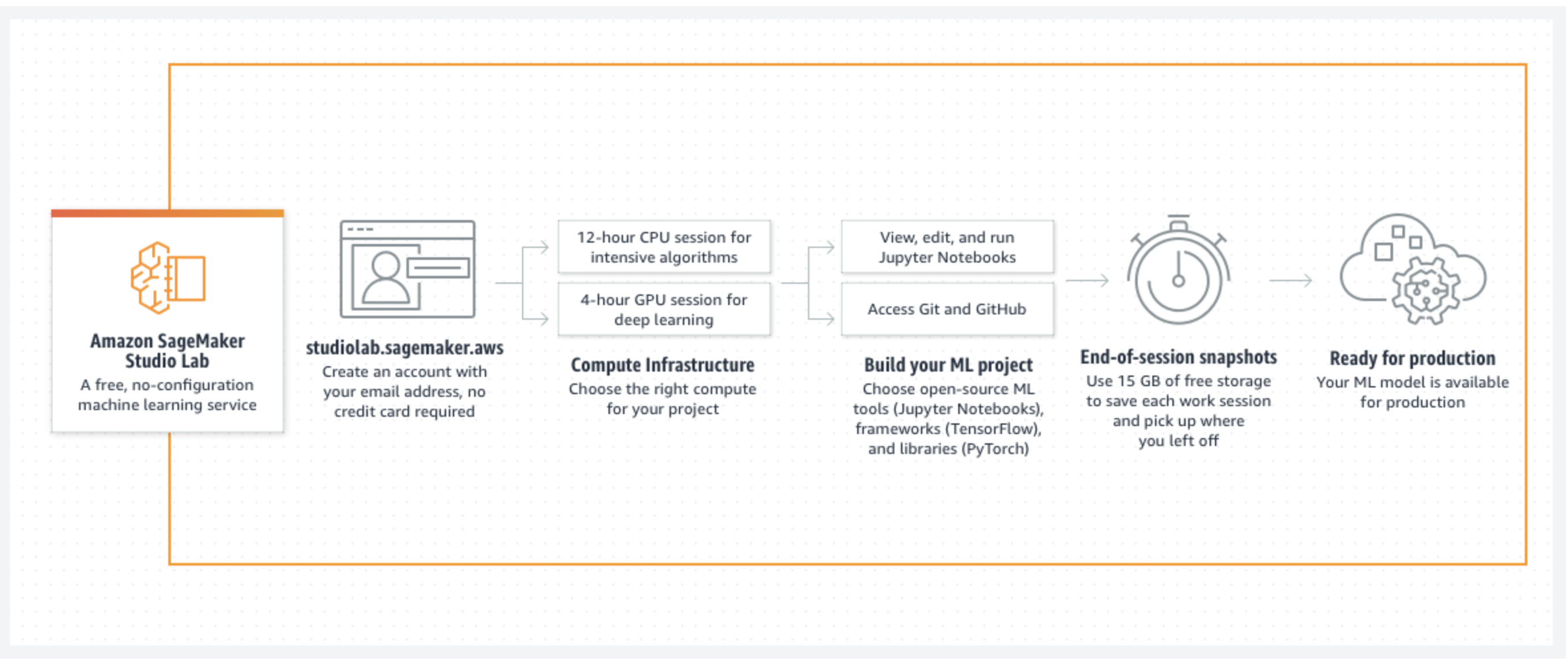
特徴は大きく以下の通りです。
- AWSアカウント不要、請求が発生しないためクレカの登録も不要
- 12 時間のCPUセッション or 4時間のGPUセッション
- 一度に1つのセッションを開始できる。回数に制限はないが、GPUは24時間あたり合計8時間の制限がある。
セッションを開始すると下記のようなインスタンスが建つ
- CPUセッション
t3.xlarge vCPU:4, Memory:16.0GB, ネットワークバースト幅:5Gbps
https://aws.amazon.com/jp/ec2/instance-types/t3/ - GPUセッション
g4dn.xlarge GPU:1(Tesla T4), vCPU:4, Memory:16GB, Storage:1 × 125 NVMe SSD
https://aws.amazon.com/jp/ec2/instance-types/g4/
僕は結局GPUインスタンスを起動できてないのでこちらの情報です。
https://www.hinomaruc.com/registered-amazon-sagemaker-studio-lab-for-free-use-of-gpu/#toc18
- CPUセッション
- 一度に1つのセッションを開始できる。回数に制限はないが、GPUは24時間あたり合計8時間の制限がある。
- 永続ストレージ15GB
セッションを終了しても永続ストレージにデータが残り、セッションを再起動するとそのままデータが使える。 - Jupyter Labがベース、拡張が可能
Git連携やデバッグ機能が特に何もせず使える。簡単なIDEぐらい高機能な開発環境
拡張のインストールでカスタマイズも可能
Sagemaker Studio Labを始めよう
こちらのリンクから必要な情報を入力しSagemaker Studio Labアカウントのリクエストを送ります。http://studiolab.sagemaker.aws/
数日程度でメールにアカウント付与の連絡が来ますので、そちらのメールのリンクからアカウントの設定をするとすぐに使えます。
細かい画面の様子などは公式のこちらが参考になります。
https://aws.amazon.com/jp/blogs/news/now-in-preview-amazon-sagemaker-studio-lab-a-free-service-to-learn-and-experiment-with-ml/
GPUインスタンスを建てよう
ログインできたら、せっかくなのでGPUで建ててみましょう。GPUを選択し、Start Runtimeを押すだけで起動します。
エラーメッセージを検索してみると、自分と同様の状況の方が多くいるようでした。利用者の増加や昨今の機械学習需要の高まりでGPUリソースが厳しいのかもしれません。
有料版でそんなことはしないと思うので、GPUインスタンスが使いたければ諦めてしっかりお金を払った方がいいかもしれません。それか、クラウドなんてやめてアキバでグラボ買ってきて自分のPCに載せた方がいいです。
CPUインスタンスを建てて動かしてみよう
GPUは一旦置いておきましょう。CPUは特に問題なく起動します。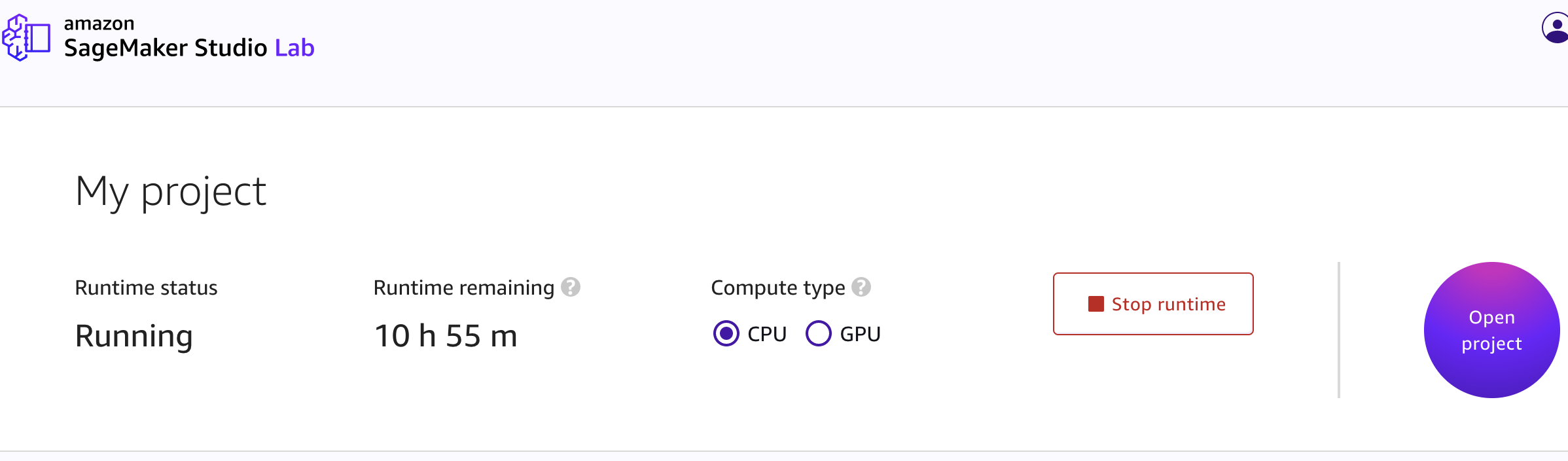
起動したらOpen ProjectからJupyterの画面に遷移します。
すると、sagemaker-studio-notebooks以下にGetting Started.ipynbというノートブックがあるのでこちらに目を通しましょう。
コードの実行やライブラリのインストールなど、基本的なガイドが書かれています。
ここからチュートリアル用のSageMaker Studio Lab example notebooksや、HuggingFaceのGitリポジトリなどをクローンしたりできます。
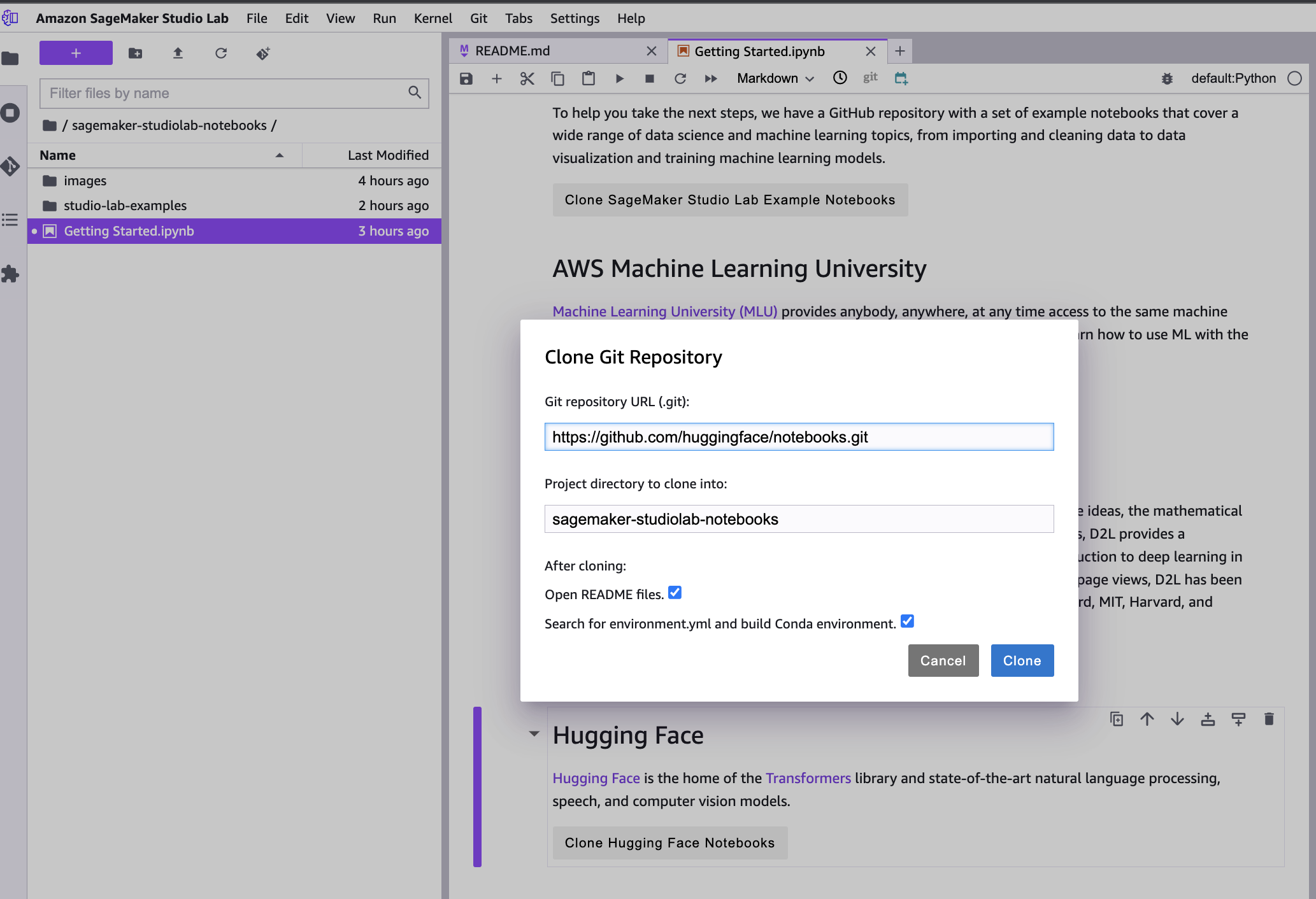
とりあえずSageMaker Studio Lab example notebooksをクローンしてきます。
どれでも良いのですが、今話題なのでNLPのコードを動かしていきましょうか。
natural-language-processing/NLP_disaster_Recovery_Translation.ipynbをCPUインスタンスでそのまま動かしてみます。
こちらのコードはT5という言語モデルを用いた機械翻訳のファインチューニングのハンズオンです。フルスペックのモデルだと重すぎるのか、パラメータ少なめのT5の事前学習済みモデルをhuggingfaceから入手してきて、ファインチューニングするコードとなっています。
This notebook is designed to run within SageMaker Lab, on a g4dn.xlarge GPU instance. If you are not using that right now, please restart your session and select GPU, as this will help you train your model in a matter of tens of minutes, rather than hours.
…まあ、セッションが切れるまでには終わるでしょ。Macbookとかでも回ってた記憶がありますし、回しといてほっときましょう。
# full hugging face Trainer API args available here
# https://github.com/huggingface/transformers/blob/de635af3f1ef740aa32f53a91473269c6435e19e/src/transformers/training_args.py
# T5 trainig args available here
# https://huggingface.co/transformers/model_doc/t5.html#t5config
!python run_translation.py \
--model_name_or_path t5-small \
--do_train \
--source_lang en \
--target_lang es \
--source_prefix "translate English to Spanish: " \
--train_file data/train.json \
--output_dir output/tst-translation \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate \
--save_strategy epoch \
--num_train_epochs 3
# --do_eval \
# --validation_file path_to_jsonlines_file \
# --dataset_name cov-19 \
# --dataset_config_name en-es \
学習終わり。意外と早かったですね。[INFO|trainer.py:2039] 2023-04-09 10:34:50,052 >>
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 3143.6268, 'train_samples_per_second': 2.931, 'train_steps_per_second': 0.733, 'train_loss': 2.233385059568617, 'epoch': 3.0}
100%|███████████████████████████████████████| 2304/2304 [52:23<00:00, 1.36s/it]
[INFO|trainer.py:2868] 2023-04-09 10:34:50,053 >> Saving model checkpoint to output/tst-translation
[INFO|configuration_utils.py:457] 2023-04-09 10:34:50,054 >> Configuration saved in output/tst-translation/config.json
[INFO|configuration_utils.py:362] 2023-04-09 10:34:50,055 >> Configuration saved in output/tst-translation/generation_config.json
[INFO|modeling_utils.py:1839] 2023-04-09 10:34:50,245 >> Model weights saved in output/tst-translation/pytorch_model.bin
[INFO|tokenization_utils_base.py:2171] 2023-04-09 10:34:50,246 >> tokenizer config file saved in output/tst-translation/tokenizer_config.json
[INFO|tokenization_utils_base.py:2178] 2023-04-09 10:34:50,246 >> Special tokens file saved in output/tst-translation/special_tokens_map.json
[INFO|tokenization_t5_fast.py:186] 2023-04-09 10:34:50,288 >> Copy vocab file to output/tst-translation/spiece.model
***** train metrics *****
epoch = 3.0
train_loss = 2.2334
train_runtime = 0:52:23.62
train_samples = 3071
train_samples_per_second = 2.931
train_steps_per_second = 0.733
[INFO|modelcard.py:451] 2023-04-09 10:34:50,373 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Translation', 'type': 'translation'}}
では翻訳のコードを実行してみましょう。input_sequences = ['about how long have these symptoms been going on?',
'and all chest pain should be treated this way especially with your age ',
'and along with a fever ',
'and also needs to be checked your cholesterol blood pressure',
'and are you having a fever now? ',
'and are you having any of the following symptoms with your chest pain',
'and are you having a runny nose?',
'and are you having this chest pain now?',
'and besides do you have difficulty breathing',
'and can you tell me what other symptoms are you having along with this?',
'and does this pain move from your chest?',
'and drink lots of fluids',
'and how high has your fever been',
'and i have a cough too',
'and i have a little cold and a cough',
'''and i'm really having some bad chest pain today''']
task_prefix = "translate English to Spanish: "
for i in input_sequences:
input_ids = tokenizer('''{} {}'''.format(task_prefix, i), return_tensors='pt').input_ids
outputs = model.generate(input_ids)
print(i, tokenizer.decode(outputs[0], skip_special_tokens=True))
/home/studio-lab-user/.conda/envs/default/lib/python3.9/site-packages/transformers/generation/utils.py:1313: UserWarning: Using `max_length`'s default (20) to control the generation length. This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we recommend using `max_new_tokens` to control the maximum length of the generation. warnings.warn( about how long have these symptoms been going on? en el trabajo de sntomas? and all chest pain should be treated this way especially with your age y todos los dolores de la población del and along with a fever y a las fièvres and also needs to be checked your cholesterol blood pressure y es necesario a verificar la pression sanguina del and are you having a fever now? y tu ayuda una fièvre? and are you having any of the following symptoms with your chest pain y ayuda el sntomas c and are you having a runny nose? y tu ayuda un nez agua? and are you having this chest pain now? y tiene el dolor de la población en e and besides do you have difficulty breathing y ahora ahora a la respiración and can you tell me what other symptoms are you having along with this? y tu pueden me dire quels sntomas and does this pain move from your chest? y se movió el dolor de trabajo? and drink lots of fluids y boire lots de fluides and how high has your fever been y como el trabajo de fièvre and i have a cough too y es un toso and i have a little cold and a cough y es un rojo y un tos and i'm really having some bad chest pain today y es el trabajo del trabaほ翻訳できていますね。まあ、GPUが使えなくてもこのくらいはできますよ、ということで。
で、Sparkは?
Sagemaker Studioの方だと、ハンズオンの記事が公式から出ています。このようにすれば使っていけそうです。https://aws.amazon.com/jp/blogs/news/load-and-transform-data-from-delta-lake-using-amazon-sagemaker-studio-and-apache-spark/
結局EC2が建つのでS3に接続したりといった外部のAWSリソースに接続することも可能です。
https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lab-use-external.html#studio-lab-use-external-s3
ただし、既にあるS3へ接続するというものなのでAWSのアカウントやS3を使用するための権限などの設定はやっておく必要があるようです。上記のリンク先を読んでもらえるとわかるのですが、jupyterからシングルノードでコードを実行する以上のことをしようと思うと、結局、AWSの権限管理などが必要でAWSのアカウントを取得し色々と設定する必要があります。
Sagemeker Studio Labを始めるためだけならAWSのアカウントは必要ないので、いい感じにSagemaker Studio Labだけでやってくれるかと思ったけど、流石にそこまでの機能はありませんでした。ストレージについてはSagemaker Studio Labの方で15GB分の永続化ストレージを使えるので、わざわざS3に繋ぐ必要はないっだろうという事ですかね。S3にも無料ストレージがあるのでちょっと試す程度なら財布が痛むわけではないですけど、、、
AWSのアカウントがないとAWS上でほぼ何もできないという当たり前のことをわからされてしまいました。
Sparkについてはまた次の機会に記事にしようと思います。