2020.07.06
Restricted Boltzmann Machine(RBM)で映画を推奨してみた(PyTorch版)
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
今回はRestricted Boltzmann Machines(RBM)について書かせて頂きます。
なぜ、今回はRBMになったのか。実は今回は自分の勝手な内容で、なんの意味もなく、単純に新型コロナウィルスの影響に流されてRBMの記事になったのです(すみません)。新型コロナウィルスの感染騒ぎで外出自粛の日々が続いて、自然が大好きな私は山にも海にも遠いところにもいけなくなって、家で過ごす時間が増えてきました。おうち時間の中、映画も見たりしていました。映画を見終わると、次の映画が推奨されます。次々に、私の興味がありそうな映画が推奨され、飽きずにずっと時間を潰すことができるようになりました。皆様もこの状況があったりしたのではありませんでしょうか。もし、そうなら、どうやって人がハマりそうな映画を推奨しているのかという疑問がわきませんでしょうか。
ということで、今四半期は映画推薦システム(movie recommender system)について勉強しようと思いました。かつ、勉強という意味もあって、前回のブログでも少し紹介し自分が気になったEnergy-based modelも一緒に勉強できればいいなあと思いました。そして、気分転換もあって、今回の実装はTensorflowやKerasではなく、PyTorchを利用することにしました。そのような流れで、映画推薦システムとRBMについて紹介し、実装例はPyTorchでやらせて頂きます。
さて、このブログの構成は、以下の通りです。
①映画推薦システム(movie recommender system)の紹介
映画推薦システムはユーザーに興味がありそうな映画を探索しながらおすすめするためのシステムです。インターネット上でNetflix、Hulu、Amazonプライムビデオなどの会社は動画配信サービスを提供しています。ユーザーがそれらのサービスを利用し、パソコンや携帯で動画を見ることができます。今日、「なにを見ようかなあ?」と思ったときに、映画が多すぎて選べないといった経験を皆さん一度くらいお待ちなのではないでしょうか。そのようなとき、ウェブサイトの中に、なにげなく、出てきたおすすめ順から選んだりなさいませんか。出てきたおすすめ順の裏には推薦システムがあります。
では、推薦システムはどのように作られているのか軽く説明してみたいと思います。
- 一番簡単には単純に人気度(popularity)から作られます。沢山の人が見た映画をランキングして、お勧め順に並べて、ウェブサイトに載せます。
- ユーザーの興味や映画の種類に合わせて、機械学習を利用し推薦します。ここでは入力されたデータによって、主な三つに分割、2.1.collaborative filtering, 2.2.content-based recommender system, 2.3.hybrid recommender systemです
2.1. collaborative filteringはユーザーベースシステムです。ユーザーの明示的履歴(購入履歴、評価結果、アンケート記入)や暗黙的履歴(ウェブサイトの閲覧履歴)を学習し推薦します。例として、簡単な推薦方法はモデルベースで、singular value decomposition (SVD ; 特異値分解)のような行列分解の手法が利用されています。例えば、あるユーザーが沢山の映画を評価し、ある映画も沢山のユーザーからの評価情報が集まります。SVDでそれらの情報を分析し、似たような映画を計算することができ、それに基づいて、各ユーザーの評価が高い映画と似たような映画を推薦したら、同じような評価をすると予測することが可能になります。
2.2. content-based recommendationは商品ベースシステムです。商品のアイテムとユーザー情報(年齢、性別、など)をマッピングし、似たような商品を推薦します。テキスト、画像、ビデオなどの情報も考慮することもできます。例として、簡単な推薦方法はk nearest neighbor(k-NN)といった教師なし学習が使われています。例えば、商品の情報を数字化して、各ユーザーにk-NNで数字的に近いものを推薦します。
2.3. hybrid recommender systemは様々な推薦戦略を結合したシステムです。説明した一つ目と二つ目はそれぞれの 利点と欠点があります。ユーザーベースだと、商品の情報がなくても、推薦可能ですが、ユーザーのレビューがないと推薦できないし、レビュー個数によるバイアスがかかってしまう可能性があります。一方、商品ベースだと、ユーザーレビューがなくても推薦可能ですが、それぞれの商品の詳細情報が必要であり、大規模だと実践が厳しくなります。このような利点と欠点に合せて、hybrid recommender systemが使われています。
また、上記の例は簡単な説明ですが、実際は沢山の情報があります。データは複雑になり、簡単な手法だけでは、うまく推薦できない可能があります。そこで、複雑なシステムに対応するためのディープラーニングという機械学習の発展版が利用されます。その中の一つの手法は今回紹介するRestricted Boltzmann Machines(RBM)です。それでは、RBMとはなにかが次のセクションになります。
②Restricted Boltzmann Machines(RBM)とは
Restricted Boltzmann Machine (RBM)は教師なし機械学習の一種で、Netflix Prizeコンペティション(collaborative filteringアルゴリズムのコンペ)で成功したモデルの一つです。
少し復習しますと、機械学習は主に三つの枠組みに分けられ、「教師あり学習」、「教師なし学習」、「強化学習」です。今回紹介するのは「教師なし学習」で、学習データに正解を与えない状態で学習させる手法です。例として、大量の映画のアンケートの解析をします。アンケートの中にある文章から、満足度を解析します。「教師あり学習」ですと、学習するときに、「いいね、素晴らしい」のような単語は満足度が高い、「つまらない、眠い」のような単語は満足度が低い、とラベルをして、学習します。しかし、「教師なし学習」は、ラベル(正解)がありません。そうすると、「いいね」や「素晴らしい」が似ているグループに分けることができますが、ラベルがないためそのグループがなにを示すのかわかりません。そこで、分けられたグループから、どのグループか満足度が高いのかを解釈する必要があります。
さて、Boltzmann Machineは教師なし機械学習の一つです。Boltzmann Machineは分類、回帰分析、collaborative filteringなどのため、1985年に有名なHinton、Sejnowski先生らが開発されたものです。Restricted Boltzmann Machine(RBM)はEnergy-based Models(EBMs)を利用したBoltzmann Machineの発展版です。さらに、RBMを発展させたものはDeep Belief Network(DBN)やDeep Boltzmann Machine(DBM)になります。
今回は発展させたものの技術抜きでBoltzmann Machinesの基礎から、EBMs を通して、RBMまでを書かせて頂きます。
Boltzmann Machine
Boltzmann Machineは確率的(stochastic)に作動するニューラルネットワークです。決定論的(deterministic)なニューラルネットワークと異なり、ランダム性があり、データ生成過程を確率モデルで学習します。ディープラーニングの視点でいえば、Boltzmann Machineは深層生成モデルの枠になります。
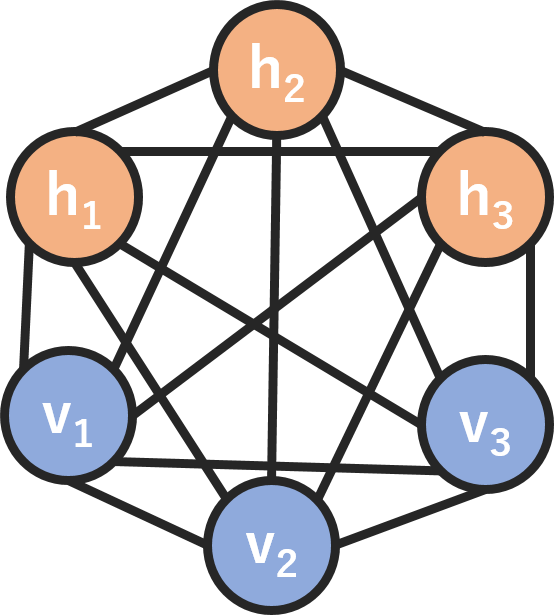
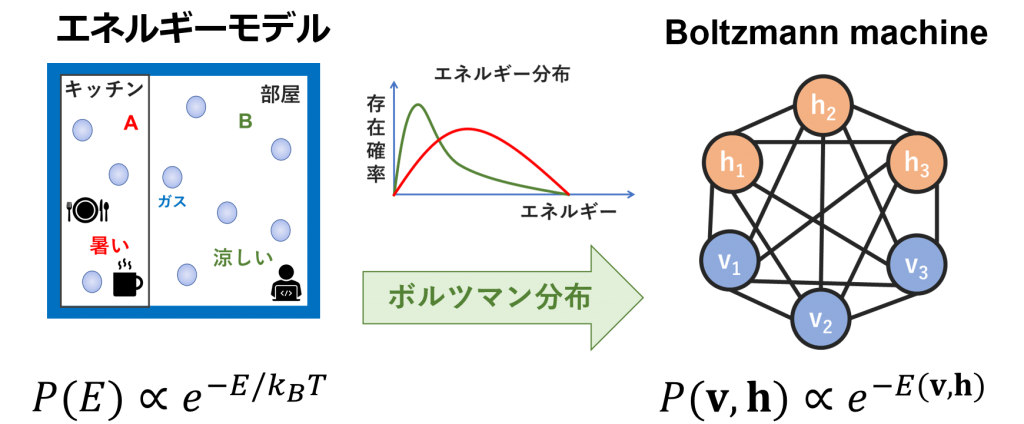
下記の図はBoltzmann machineのネットワークです。この例は6ノードあり、隠れノード(hidden node; h)と可視ノード(visible node; vすなわち入力)が繋がっています。一般的なニューラルネット(CNN, RNNなど)を扱っている方は違和感がありませんでしたか。このネットワークは一般的なニューラルネットワークと異なって、①出力(output)がありません ②入力が繋がります。全てのノードがお互いに情報交換し、自己データを生成しているので、深層生成モデルの一つになります。データを入力したら、ノードが全てのパラメータを学習し、お互いの特徴や相関関係を見つけ出し、教師なし学習のシステムを作成します。
では、エネルギー等分配はどういうものなのか、どのようにボルツマン分布に繋がっているのかが次のセクションになります。
Energy-based models (EBMs)
このセクションでは、エネルギーとはなにか、どうやってモデルに適用されるのか、を話します。
エネルギーとは物体が持っている仕事をする能力ということです。物体が運動して、他の物体に当たったときに、動かしたり変形させたりすることが出来ます。この運動している物体の持つエネルギーは運動エネルギー(kinetic energy)といいます。それぞれの物体(分子)が内部エネルギー(internal energy)を持っています。それぞれの分子がどのようなエネルギーを持つか、統計的に考えることもでき、エネルギー分布で説明できます。エネルギー分布といえば、学生時代の授業でボルツマン分布(maxwell-boltzmann distribution)という単語を思い出したりしませんか。私は勉強が好きではなかったので、この単語は悪夢のような記憶ですが、外出自粛の環境での妄想の例として、復習しています。
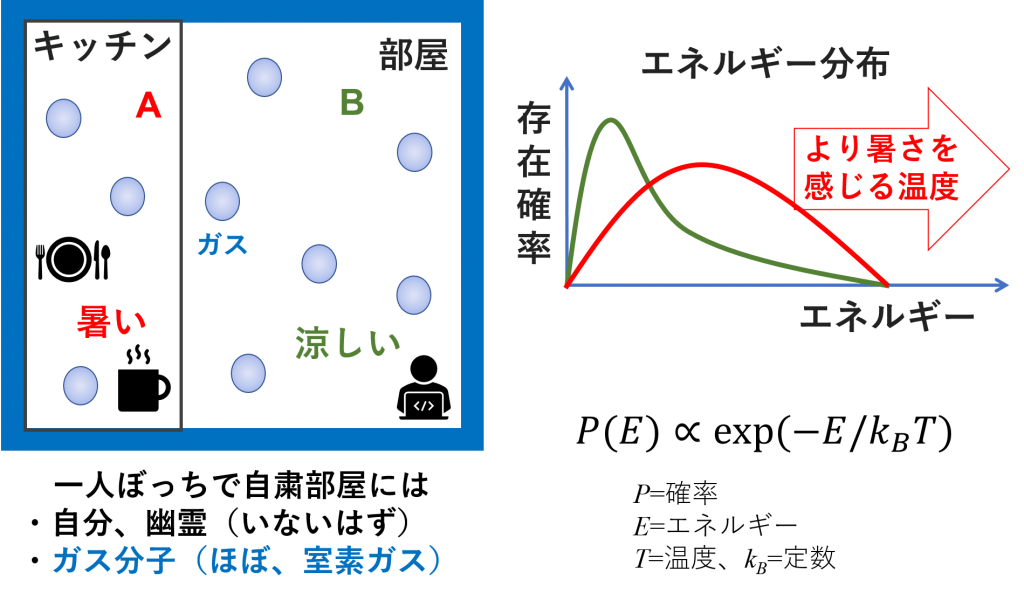
下記の図で、多くの人が一人ぼっちで外出自粛しているかと思います。その自粛部屋には幽霊はいないはずですので、自分だけがいます。後は部屋の中に、自分と一緒に存在しているのがガス分子(ほぼ、窒素)です。我々はガス分子が見えないけれど、キッチンでも部屋でも、どこにでもあります。キッチンの周りは料理をしたりするから、温度が高いです。温度が高いほど、ガス分子はよく動いて、運動エネルギーも増加します。ただ、ガス分子がたくさんあって、温度が高くなっても、全てのガス分子のエネルギーが高いわけではありません。どこでも、過半数グループがいれば、少数グループもいます。ガス分子も同じです。そうすると、キッチンの中のガス分子は、エネルギーが高い過半数グループ、もっとエネルギーが高い少数グループ、そして、エネルギーが低いままの少数グループもあります。確率を考えると、下記のようなグラフのイメージになります。一方、部屋の中は涼しくて温度が低いです。この場合ですと、運動エネルギーが低いガス分子の確率が高くなります。このシナリオによる、エネルギーは確率で説明可能ということがわかり、簡単な式で表現することもできます。このような分布を表す数式はボルツマン分布と呼ばれています。
Boltzmann machineは上記のボルツマン分布を利用し、可視ノードと隠れノードの確率を導きます。
ボルツマン分布についての詳細参考はこの講義のスライド、Boltzmann machineについては Geoffrey Hinton先生の講義がお勧めです。
また、エネルギー関数の適用はボルツマン分布だけではなくて、Energy-based models (EBMs; エネルギーベースモデル)という生成モデルの一つで使われています。モデルの主な目的は変数(未知あるいは不定の数・対象を表す文字記号)の依存関係を表すことです。Generative Adversarial Networks (GANs)、Variational Autoencoders(VAEs)、Flow-based modelといった深層生成モデルと違って、EBMsはサンプルを生成するための明示的なニューラルネットワークが必要なく、サンプルは暗黙的に生成されます。
Restricted Boltzmann Machine (RBM)
Restricted Boltzmann Machines (RBM)はBoltzmann Machineの特別版で、可視ノード(visible node; v)と隠れノード(hidden node; h)の繋がりが制限(restricted)されます。ニューラルネットワークは2部グラフ(bipartite graph)のような二つ層になります(下記の図)。
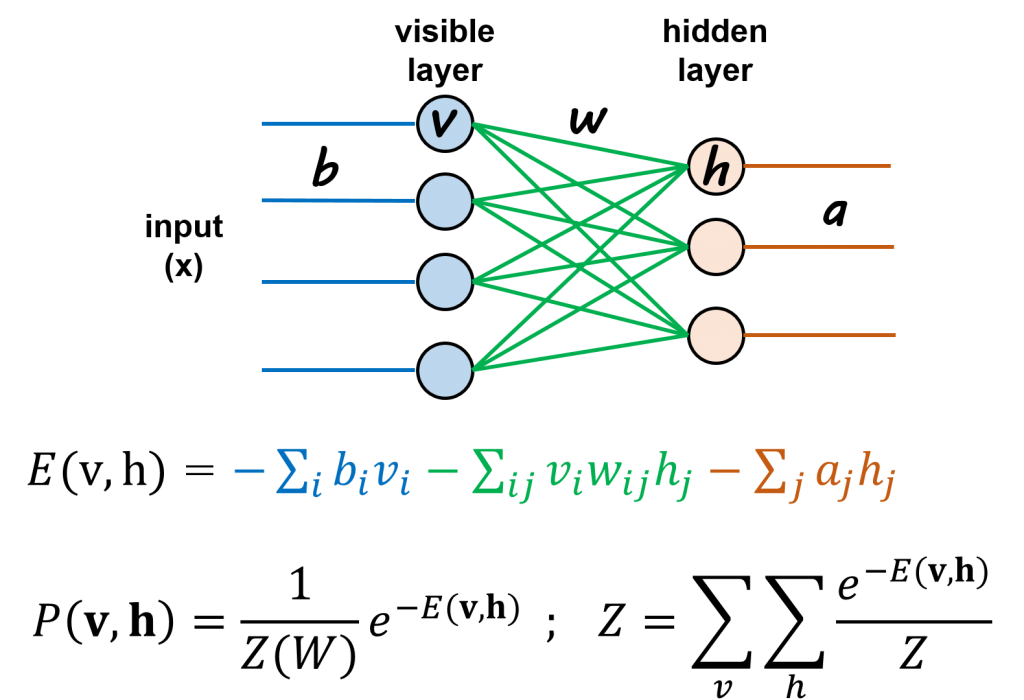
ニューラルネットワークと似て、前方(forward)で左から、入力(input x)がvisible layerに入り、visible nodesがhidden nodesに繋がります。だた、出力(output)がありません。かつ、教師なしですので、比較できるラベル(正解)もありません。そこで、左から、出力した値がさらに、後方(backward; 右から左に)で、hidden nodesからvisible nodesに戻ります。後方で戻ることはreconstructionと言います。Reconstructionから出た値が入力値に近ければ、モデルを学習でき、入力にないものも一緒に予測可能になるという考え方です。
RBMモデルの計算については、単純でvisible nodesとhidden nodesの計算式がエネルギー関数「E(v,h)」で表せます。さらに、上記に説明した確率分布(ボルツマン分布)のように、エネルギー関数が変化したことが確率で表すことができます「p(v, h)」。そこで、前方は出力のwで重みづけられた条件下vのもとでhが発生する確率「p(h|v; w) 」になります。一方、後方は 「p(v|h; w) 」で表せます。
確率モデルを計算するために、エネルギー関数のパラメータ(w, b, a)を勾配でで解きます。ここで、最尤推定(maximum likelihood estimation)が利用されます(下記のサブセクションに復習)。Visible nodesに与えられた入力データ(v)を確率「p(v, h)」計算し、入力したデータ分布と出力データ分布がより近い分布になるようなパラメータを見つけ出します。厳密な計算は結構複雑ですので、ここでは省略しますが、興味がある方は下記の参考を見てみて下さい。複雑な式を導いたら、下記のような式が出てきます。
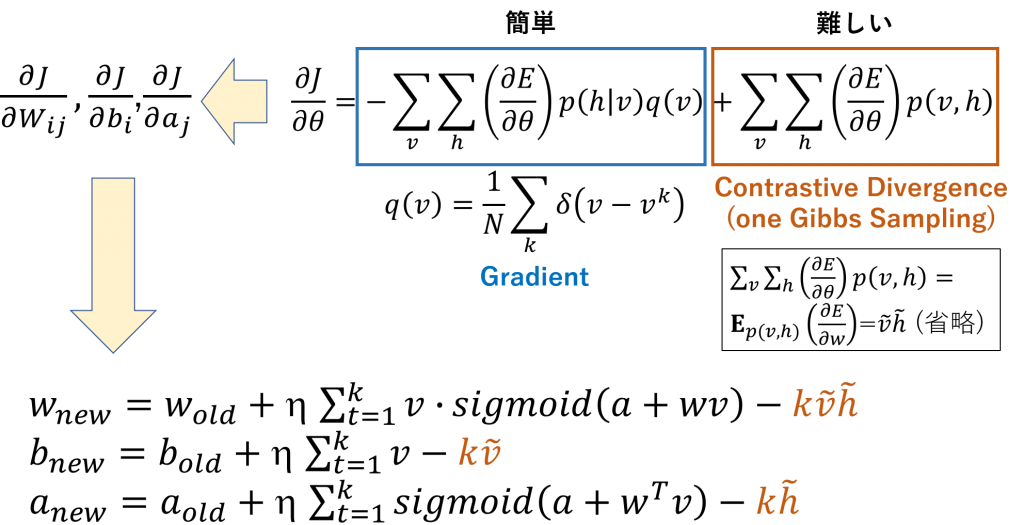
また、パラメータの式に、二つ項があります。第一項はsigmoid関数で計算が簡単です。p(h|v)は確率の計算で、q(v)についてはv(入力)とvk(出力)の差になり、答えが0か1を掛ける1/Nになります。しかし、第二項の計算はp(v,h)の依存関係で計算が難しいです。そこで、Hinton先生らがContrastive Divergence (CD)を提案しました(下記のサブセクションに説明)。CDを利用すると、簡単に、第二項を解くことが可能になります。SigmoidとCDの組み合わせで、三つのパラメータ(b, w, a)を解くことが可能になります。適切なパラメータが解けると、モデルの作成が完了です。
データをモデルに入力し、結果が出力されます。入力したものと出力されたものを比較しながら、未知をものの予測することも出来、collaborative filteringのような推薦方法にも適用可能です。
最尤推定(maximum likelihood estimation)
最尤推定(maximum likelihood estimation)は統計学において、観測データに対しての確率分布の特徴に合うようなパラメータを推定する方法です。下記の図に参考しながら復習します。確率(probability)は分布の中にある領域です。尤度(likelihood)は分布においてあるデータ点のためのy軸の値です。簡単な説明のため、上記の部屋のガスの例を利用します。確率はx1からx2までのエネルギー(x軸)が分布の中にどれくらい起こる可能性があるのかを示します。尤度はx1のときに、確率はどれくらいになるのかを示します。式に表すと逆の見方になります。
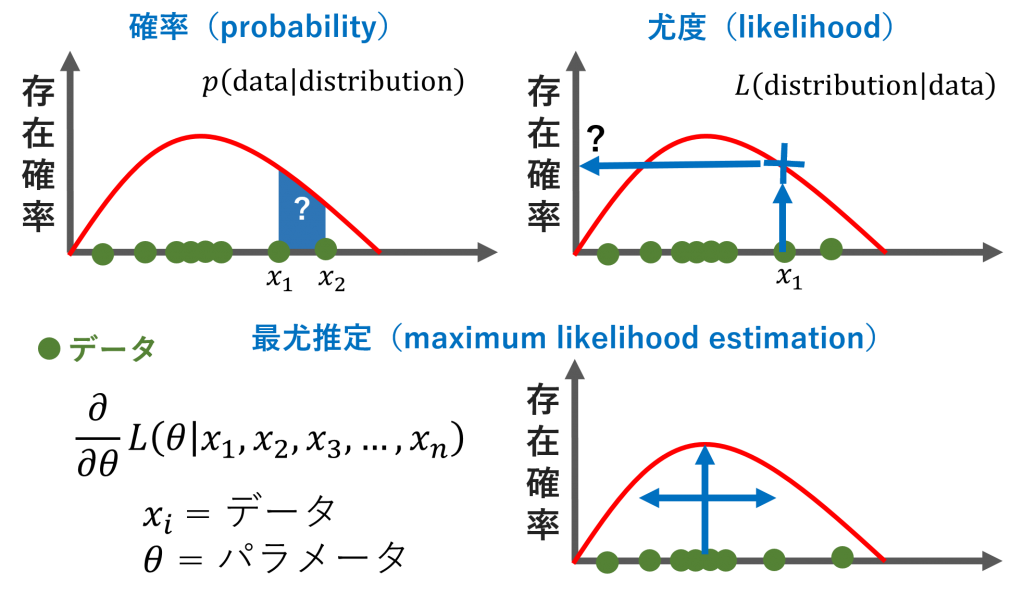
また、最尤推定は尤度を最大化なるようなパラメータを推定することです。そのパラメータを計算するため、L式を微分します。
Contrastive Divergence (CD)
Contrastive Divergence(CD)は一回サンプリングのみのGibbs Sampling手法です(下記の図)。RBMを簡単に計算できるようにするため、Hinton先生らが提案した手法です。 Gibbs SamplingはMCMC法(Markov chain Monte Carlo algorithm)の一つ、サンプリングが難しい確率分布の変わりに、近似するサンプリング例を生成する手法です。CDはGibbs Samplingの一回のみですので、Gibbs Samplingより少し大ざっぱな手法になります。誤差が少しある可能性が高いですが、計算が簡単でうまく行く場合も多いようです。
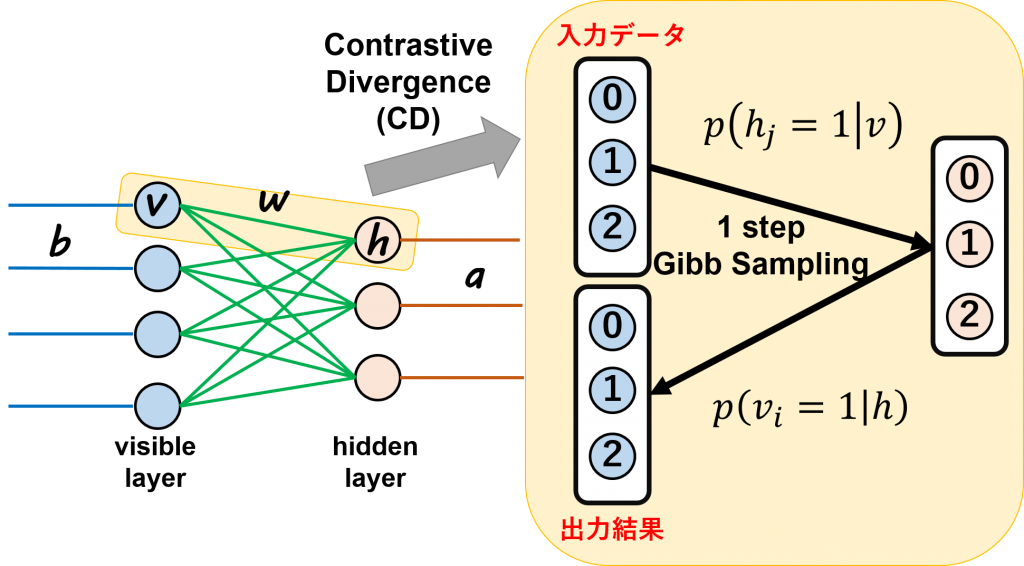
CDアルゴリズムはまず、入力したデータ(v0)は初期値として使います。条件付き確率p(hj=1|v)を用いてhidden layerのnodeごとにサンプリングします。次に、条件付き確率p(vi=1|h)を用いてvisible layerにnodesごとにサンプリングします。そうすると、全てのデータに対しのサンプリングを行うことで、上記説明した第2項の複雑な式で解くことが必要なくなり、答えを出すことが可能になります。
参考:
• https://www.slideshare.net/MingukKang/restricted-boltzmann-machine-87195518
• http://deeplearning.net/tutorial/rbm.html#implementation
• https://www.youtube.com/watch?v=JKw4z2tKl_4
• https://www.slideshare.net/takumayagi/rbm-andlearning
• https://qiita.com/t_Signull/items/f776aecb4909b7c5c116
• https://heartbeat.fritz.ai/guide-to-restricted-boltzmann-machines-using-pytorch-ee50d1ed21a8
③実装:RBMで映画を推奨してみた
それでは、いよいよ、実装です。
やりたいことはRBMモデルを用いて、ユーザーの評価情報から、ユーザーに映画を推薦してみることです。全部の実装コードは github に置いてありますので、詳細はそちらを参考になさってください。
実装環境
今回の実装では、Google Colaboratoryを利用しました。
データ
データはMovieLens datasets を利用しました。データはユーザー番号と映画番号が含まれた映画評価(rating)情報です。データは2セットあり、学習用(train)79999件、とテスト用(test)19999件です。それぞれのデータセットの中には943ユーザー、1682映画、がばらばらに入っています。
ユーザーと映画の関係が捕まえられるような形にデータを処理しました。データがないところは-1、低評価は0、高評価は1に設定しました。処理したデータ(下記の図)を見てみると、評価されていないところが半分以上あることがわかります。ユーザーが全部の映画を見たわけではないし、見ても評価しないケースが多いのだろうと思われます。
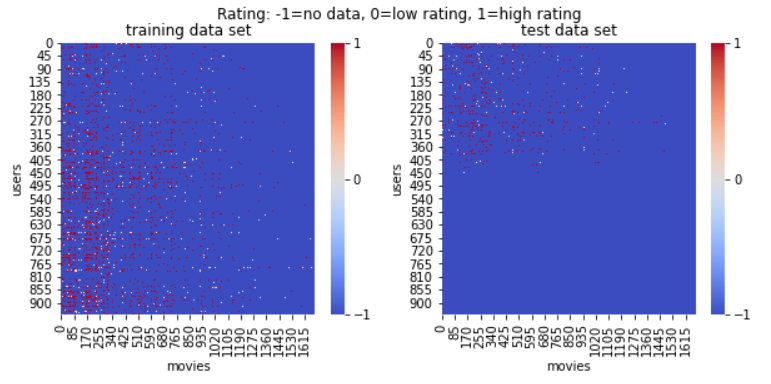
このtrainデータセットを使って学習し、RBMモデルを作成します。そして、テストデータをRBMモデルに入れて、ユーザーが評価していないところの評価を予測してみます。ここで、予測できたら、各ユーザーに映画を推奨できるという考え方です。
モデル
RBMモデルは三つの部分で分け、hidden nodes、visible nodes、trainです。モデルは主にPytorchの本とこのgithubを参考しながら、作成しました。
class RBM():
def __init__(self, num_visible_nodes, num_hidden_nodes):
##initialize all weights
##a tensor with size of num_hidden_nodes, num_visible_nodes in normal dis mean 0 var 1
self.W = torch.randn(num_hidden_nodes, num_visible_nodes)
self.a = torch.randn(1, num_hidden_nodes) #bias for hidden nodes - #1st dimension is batch, 2nd is num of hidden nodes
self.b = torch.randn(1, num_visible_nodes) #bias for visible nodes
#activate the hidden nodes by sampling all hiddens node, given values of visible nodes
def sample_hidden_nodes(self, x):
#x is values of visible nodes
#probablity of hiddens h to be activated, given values of visible nodes v
wx = torch.mm(x, self.W.t())
#use sigmoid fuc to activate visible node
## a is bias for hidden nodes
activation = wx + self.a.expand_as(wx)
##ith of the vector is the probability of ith hidden nodes to be activated,
##given visible values
p_h_given_v =torch.sigmoid(activation)
#samples of all hiddens nodes
return p_h_given_v, torch.bernoulli(p_h_given_v)
def sample_visible_nodes(self, y):
#y is hidden nodes
#probablity of visible h to be activated, given hidden nodes v
wy = torch.mm(y, self.W)
#use sigmoid fuc to activate hiddens nodes
activation = wy + self.b.expand_as(wy)
##ith of the vector is the probability of ith visible nodes to be activated,
##given hidden values
p_v_given_h =torch.sigmoid(activation)
#samples of all hiddens nodes
return p_v_given_h, torch.bernoulli(p_v_given_h)
#visible nodes after kth interation
#probablity of hidden nodes after kth iteration
def train(self, v0, vk, ph0, phk):
self.W += (torch.mm(v0.t(), ph0) - torch.mm(vk.t(), phk)).t()
#add zero to keep b as a tensor of 2 dimension
self.b += torch.sum((v0 - vk), 0)
self.a += torch.sum((ph0 - phk), 0)
# for prediction, input pass hidden nodes and reconstruct back to visible nodes
def predict(self, x): # x is visible nodes
_, h = self.sample_hidden_nodes(x)
_, v = self.sample_visible_nodes(h)
return v
学習
上記で作成したモデルを使ってtrainデータセットで学習しました。
# define model parameters
num_visible_nodes = len(training_set[0]) #number of movies
num_hidden_nodes = 100 #number of hidden nodes or num of features
batch_size = 100
rbm = RBM(num_visible_nodes, num_hidden_nodes)
##train the RBM
nb_epoch = 10
train_loss_list = []
for epoch in range(1, nb_epoch+1):
##loss function
train_loss = 0
#normalize the loss, define a counter
s = 0.
#implement a batch learning,
for id_user in range(0, nb_users - batch_size, 100):
#input batch values
vk = training_set[id_user: id_user+batch_size]
#target used for loss mesarue: rating
v0 = training_set[id_user: id_user+batch_size]
##initilize probablity
#pho: given real rating at begining, probablity of hidden nodes
ph0, _ = rbm.sample_hidden_nodes(v0)
#k step of constrative divergence
for k in range(10):
_, hk = rbm.sample_hidden_nodes(vk)
_, vk = rbm.sample_visible_nodes(hk)
#training on rating that do exist, rating as -1
vk[v0<0] = v0[v0<0] phk, _ = rbm.sample_hidden_nodes(vk) #update weights and bias rbm.train(v0, vk, ph0, phk) #update train loss train_loss += torch.mean(torch.abs(v0[v0>0]-vk[v0>0]))
s += 1
print('epoch: '+str(epoch)+' loss: '+str(train_loss/s))
train_loss_list.append ( train_loss )
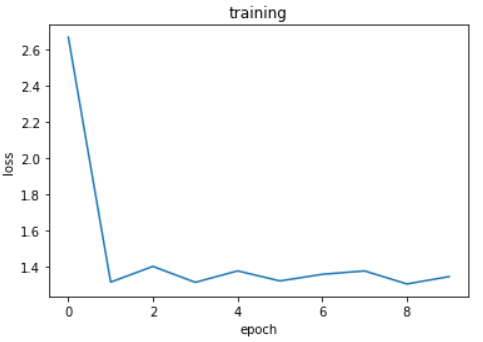
学習回数は10回でしたが、学習結果のようにlossが減っていくことが見られ、学習ができたことを確認できました。
テスト結果
学習したモデルを使って予測します。下記のコードのように、テストデータを入れると、hidden nodesを通って、visible nodesに戻ってきて、結果が出力されます。
##loss function
test_loss = 0
#normalize the loss, define a counter
s = 0.
#implement a batch learning,
predicted_v_input = []
test_input = []
for id_user in range(0, nb_users):
#use input of train set to activate RBM
v_input = training_set[id_user: id_user+1]
#target used for loss mesarue: rating
v_target = test_set[id_user: id_user+1]
#use only 1 step to make better prediction, though used 10 steps to train
if len(v_target[v_target>=0]):
# predict data
v_input = rbm.predict(v_input)
#update test loss
test_loss += torch.mean(torch.abs(v_target[v_target>0]-v_input[v_target>0]))
predicted_v_input.append ( v_input.detach().numpy()[0] )
test_input.append ( v_target.detach().numpy()[0] )
s += 1
predicted_v_input = np.array(predicted_v_input)
print('test loss: ' +str(test_loss/s))
予測結果は下記になります。左はテストデータセットで、右はテストデータを用いてRBMで予測した結果です。データがなくても、RBMで穴を埋めることが可能になります。
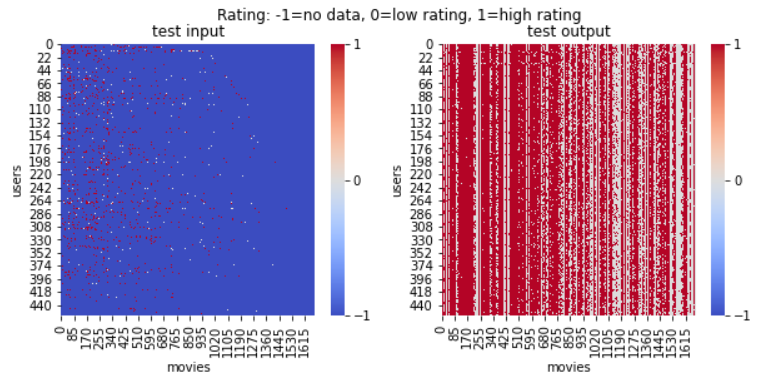
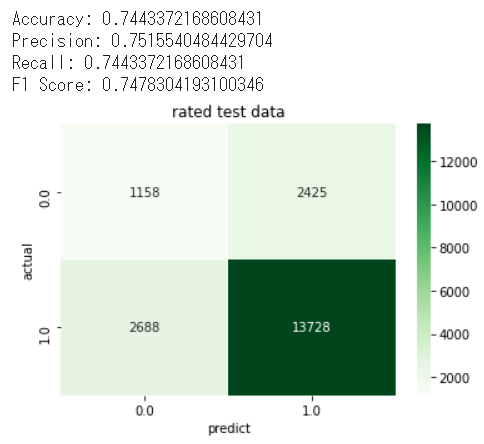
高評価が多く見られます。モデルが適当に高評価ばかりを推薦したか疑問になりましたので、データがあるところは正しく予測したかどうかも確認してみました。結果、予測精度(accuracy)は74%くらいでした。さらに、Confustion matrixを見てみると、実データでも、高評価に偏っていることが見られます。個人的には、このくらいの精度で、かつ、データがないところも埋めてくれるので、これで各ユーザーに映画推薦するのを期待できるのではないかと思います。
④まとめと考察
今回は、教師なし学習の関連技術で、Boltzman machine、Energy-based model(EBM)、Restricted Boltzmann Machine (RBM)の周りを紹介しました。実装はRBMを使って映画推薦してみました。
紹介した技術は最新のものではなかったですが、個人的な勉強や復習は楽しかったです。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD