2016.10.05
Deep Q-LearningでFXしてみた
次世代システム研究室のJK(男)です。よろしくお願いします。
今回はDeep Q-Learningという手法でFXをやってみたので紹介します。前回のブログでは、LSTMというディープラーニング(Deep Learning; 深層学習とも)の一種を使って、株価変動の予想をしました。これは「教師あり学習」という手法で、コンピュータに常に「正解」を教えて学習させます。でも、よくよく考えると金融商品って時間変動の予想が最終目標じゃないですよね。最終目標は(基本的に)金融商品の売買で儲けること。つまり予想を元に、いま売るのか、買うのか、何もしないのか、という「行動」を決めることです。完全に未来がわかるのでもない限り、この行動に「正解」が無いことがわかります。
完全に予想するのは無理(短期的には買ったり負けたり)かもしれませんが、長期的には儲けるような「方針」は立てられるかもしれない。このように「方針」を学習する技術を「強化学習」といいます。「教師あり学習」と違い、逐一、正解を与えなくても自律的に学習してくれる便利な奴です。
というわけで、今回は「強化学習でロボットに売買の方針を学習させて、FXで儲けられないかな?」という不純な動機でやってみました。以下、表題にあるDeep Q-Learningについて説明した後、実装方法、実験結果、考察について書いていきます。
1. Deep Q-Learningとは?
Deep Q-Learningとは「Deep Learningの技術を用いたQ-Learning」です。Deep Learningについては次のサイトなどを参照してください。ここでは学習することで、複雑な処理/表現ができるスゴイ関数とだけ覚えてください。Q-Learningは強化学習の一種です。Q-Learningという数十年前から存在する強化学習のフレームワークに、Deep Learningという新しい技術を応用したものがDeep Q-Learningで、近年目覚ましい成果を上げています。強化学習についても、ここでは以後の説明で必要となる最低限の知識を説明するにとどめます。Q-Learningについては強化学習の一種だとわかっていれば十分ですので説明は割愛します。詳しい説明については、記事を参考にしてください(1)(2)。

図1 強化学習の概念図
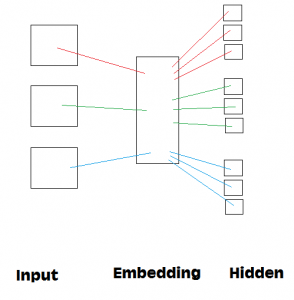
強化学習では図のように、実際に方針を学習し行動する「Agent」、Agentの行動を受け変化する「環境」が存在します。この2者間で、「行動」、「状態」、「報酬」をやりとりします。例えば囲碁の例を使うと、Agentがロボットプレーヤー、環境が囲碁の盤(+敵プレーヤー)、行動がロボットが「自分の石を打つ」、状態が盤上の石の配置、報酬が勝ち負け、となります。ロボットが「状態」=「盤上の石の配置」を観測して、「行動」=「石を打つ」する。次に敵が石を打つ;自分と敵が打った分だけ盤上の石の配置=「状態」が変化するので、その新しい「状態」を観測して、新たな「行動」をする。このサイクルが回ります。「報酬」はこの場合、試合の勝負ですので最終的に勝ち負けが決まった時点で、Agentが「報酬」を得ます。この「報酬」=「 勝つ」ような、「状態の観測」=> 「行動」の方針を決めるAgentがほしいわけです。強化学習では何度も試合を行い、成功例を重ねることでこの「方針」を学習していきます。したがって、試合数(以後、学習数)が多くなるほど、Agentは適切な方針が学べると期待できます。
2. 実装
強化学習を実装するには上述した通り、Agent、環境、2者間でやりとりする行動、状態、報酬を設計して実装する必要があります。Agent部分は学習する頭脳部分であり、Deep Leraningの技術を実装します。今回はKeras, TensorFlowを用いました。KerasはTensorFlow/Theanoをバックエンドとして使えるフレームワークで、今回はDeep Learningモデルを簡潔に書くために使用しました。学習に必要な計算部分はTensorFlowで書いています。コーディングは、先程紹介したDeep Q-Learningの紹介サイトを参考にしました。
次に環境 、行動、状態、報酬を設計する必要があります。これ、囲碁の場合を例にすると、囲碁というゲームそのものを作ることに相当します。大変ですし、自由度がありすぎます。今回の目標は「FXで儲ける」こと。この目標を達成できるような学習ができる「ゲーム」を設計する必要があります。正直、色々とパラメータがありすぎます。今回はえいやっと、以下のように設計しました。まず任意のスタート日時を決めます。元金は100万円です。ゲーム終了は2週間後で、Agentはスタートから毎ステップ行動を選択して、終了時ににそれまで売買した外貨を(その時点のレートで)日本円に精算して、合計の資産を計算します。この総資産がスタート時より儲かるよう、Agentに頑張って学習してもらいましょう!そのため、
- 行動:売る、買う、何もしない
- 状態:過去2週間のレート
- 報酬:終了時の総資産
と決め実装しました。今回扱う通貨ペアは2種類: ドル円(USD/JPY)とユーロ円(EUR/JPY)です。1種類の時より状態のパターンの複雑性が増すので、機械にしか学習できないパターンが現れることを期待しました。
3. テスト
実際のデータを使う前にテストを行います。テストのため、擬似通貨レートのデータを2種類作りました。一つ目はパターンが周期的なデータで、予想が簡単にできると期待できます(図2上パネル)。通貨ペアもUSD/JPY一つに絞っています。
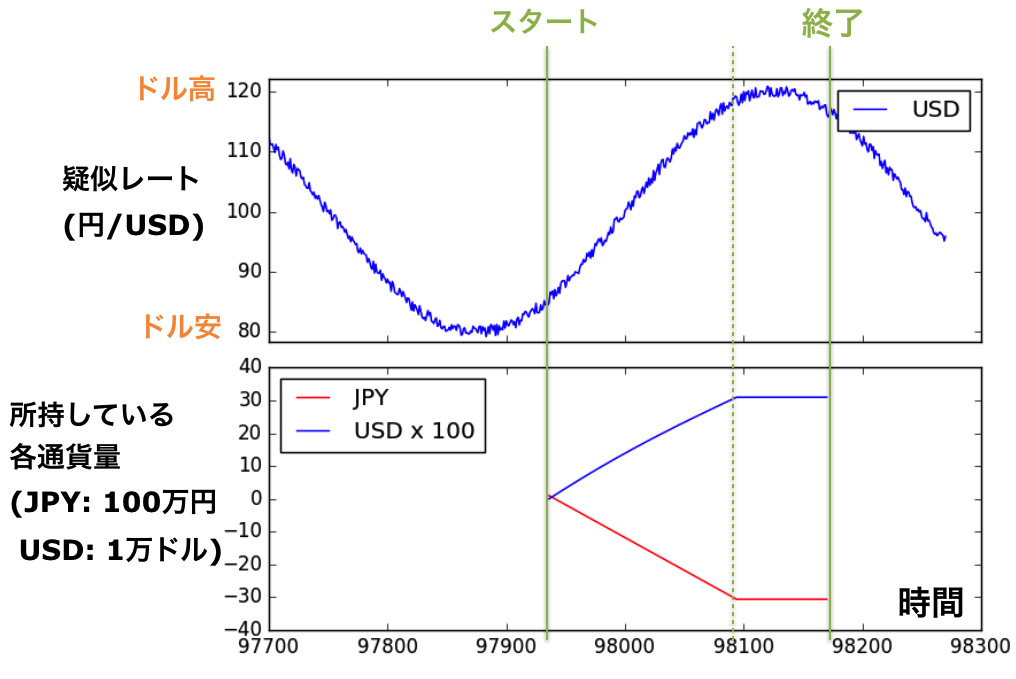
図2 テスト用の疑似データ1(上)と、対応するトレード期間のJPYとUSDの通貨量(下)
Agentに学習させた結果が図3です。横軸が学習した回数で、その回数が多くなるほど儲けが上昇しているのがわかります。期待どおりです。10,000回学習の時点で、なんと元金100万円を2週間で800万円にする方針を学習しています。素晴らしい。学習後のAgentが疑似データに対してどのように行動をしているか調べるため、Agentが持っている日本円、USDの資産の時間変化をトラックしたのが図2下です。過去のデータから未来のドル高/ドル安を予想し、適切に売買しているのがわかります。
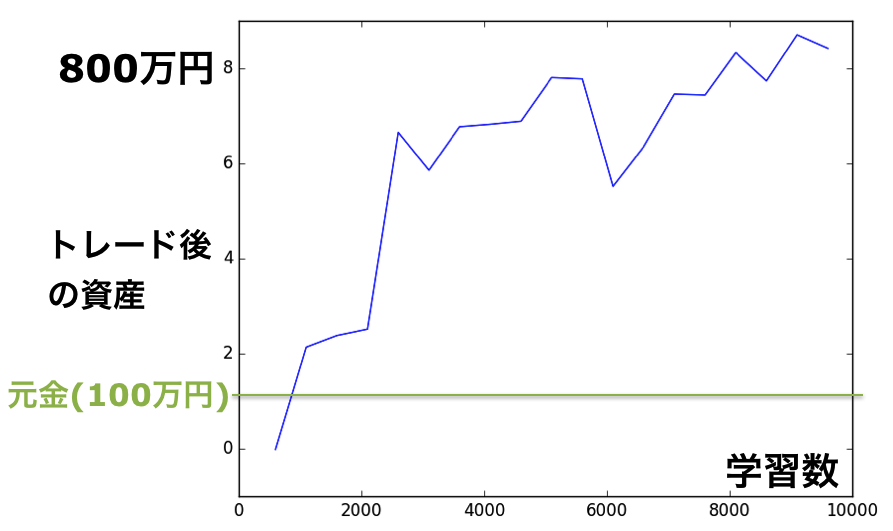
図3 テスト用の疑似データ1の結果
二つ目に作成したテスト用の疑似データは、より複雑な場合(2つの通貨ペア)です。一つの通貨ペア(USD/JPY)はほぼランダムに変化させ、 2つ目の通貨ペア(EUR/JPY)のレートの動きをUSD/JPYのデータより2日ほど遅らせました(図4上)。USD/JPYはほとんど予測ができないけど、EUR/JPYはUSD/JPYを観測すれば予想が可能なはずです。私としては、USDは売買せずEUR/JPYで売買するように学習することを期待しました。しかしよく考えると終了時、円換算するときのレートが(ランダムなので)予想できないので、「必ず儲ける」ようなシンプルな方針がないことに気づきました。この疑似データはテストとしてはあまり適切ではありませんでした。。
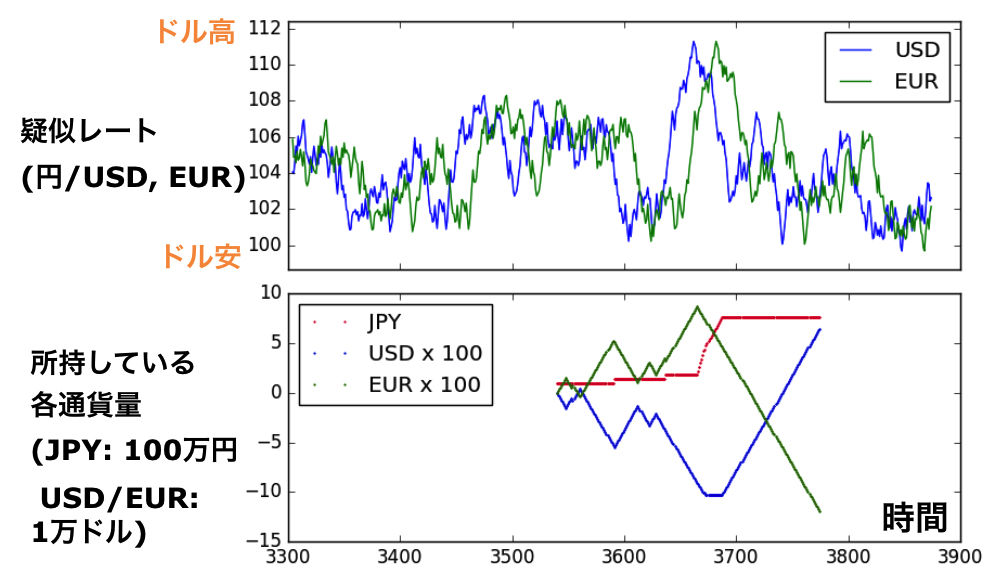
図4 テスト用の疑似データ2(上)と、対応するトレード期間のJPY, USD, EURの通貨量(下)
とき既に遅くAgentの学習時間は数十時間に達していたので、結果をとにかく見ると(図5)、何かしら学習して儲けているように見えます。実際の行動を見てみると、図4下のようにEURとUSDで逆方向に売買している行動が多いことに気づきました。EURのレートは2日後までであれば予想が可能なので、ある程度の確率でEURの資産を増やすことができる;一方、USDを逆張りすることで、終了の精算時に円高だった場合のリスクヘッジをしているのだと考えられます。少なくとも2ペアのデータを使って、方針を学習しているのがわかります。しかもこの方針で、(学習回数20,000回付近では)元金の30%程度ですが儲けられています。まさに人間(=私)が思いつかない方針をAgentが自ら学んでくれた事がわかり、面白い例となりました。
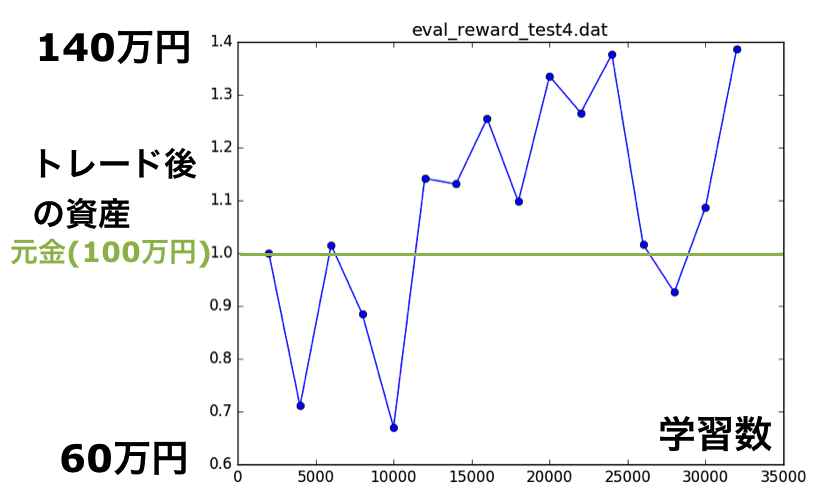
図5 テスト用の疑似データ2の結果
4. FX – 実データ
では実際のデータを使って学習しましょう。データはForex historical dataを用いました。結果は図6(左上)のようになりました。パっとみるとガタツキが多く学習していないようにみえますが、40,000回、 60,000回付近で儲けがある状態をキープしている期間があります。見やすいように移動平均をとったのが右上のパネルです。70,000回くらいまで儲けが上昇した後(105万円程度 = 儲け率5%)、80,000回あたりから急激に落ちていき元本割れしています。
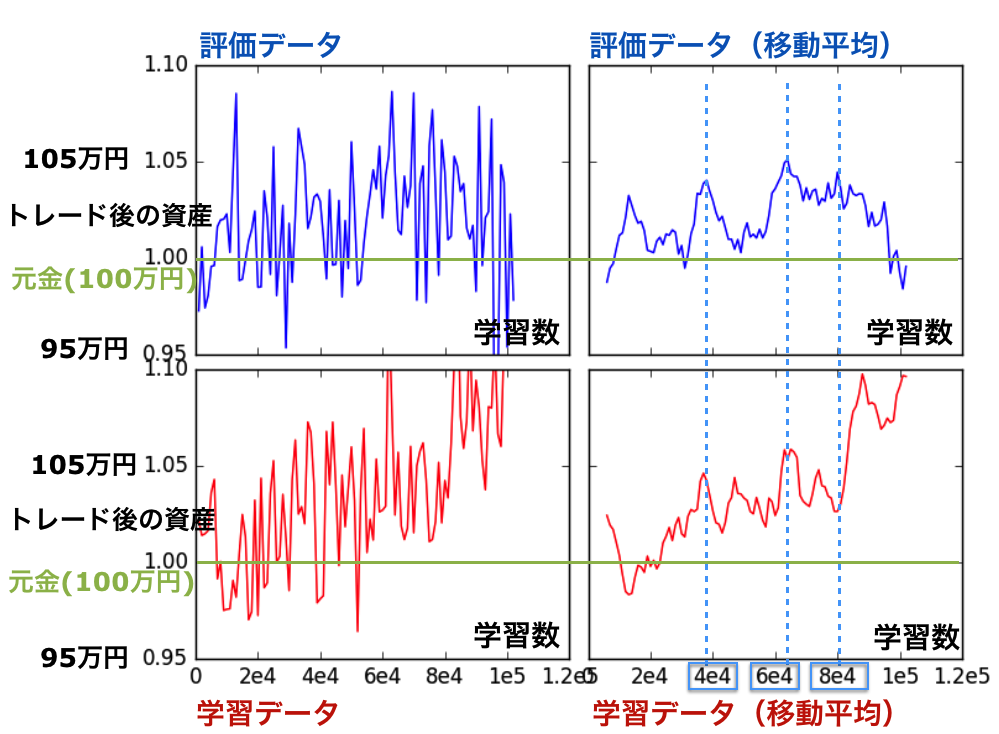
図6 実データの学習結果。評価データを用いた結果(青色。生データ;左上、移動平均データ;右上)。学習に用いたデータによる結果(赤色。生データ;左下、移動平均データ;右下)。
上記の結果は、学習に使わなかった期間(= 評価データ)の結果です。学習に使った期間のデータを用いた、儲けの変遷は図6の左下パネルのようになります。途中にピークがありつつ、順調に儲けが上昇しているのがわかります。こちらも見やすさのため移動平均をとります(右下)。評価データの40,000/60,000回のピークに対応するピークが確認でき、その儲け率もほぼ評価データと同じです。このことから、(偶然ではなく)適切にAgentが売買の方針を学習した結果、儲けが出ている可能性があります。一方80,000回以降、学習データでは儲けが急峻に上がっていますが、テストデータでは逆に下がっています。これは過学習を起こしたためと考えられます。
以上をまとめると、「Agentは80,000回程度までは(ばらつきはあるものの)儲けが上がるように学習し、40,000/60,000回付近では特に儲けが高くでる方針を学んだ(儲け率 ~ 5%)。80,000回以降、Agentは過学習を起こし評価データの儲けは下がった。」という解釈が可能です。もちろんバラツキが大きく儲け率も5%程度と小さいので、上述した解釈で正しいかはさらなる検証が必要です。
5. まとめ&改善点
Deep Q-LearningでFXを行いました。テストデータを用いて、FXのレートデータにパターンがあれば、儲けられるようにAgentを学習させられることを確認しました。実データを用いた実験ではノイズが大きいものの、特定の学習回数付近で儲けられる方針をAgentが学んだようにも見えます。が、これに関してはさらなる検証が必要でしょう。
もちろん他にも試すべきことはあります。インプットデータは適切だったのカートトレード期間は適切だったのか?通貨ペアは適切だったのか?Agentのモデルは適切だったのか?この辺りをさらに調査していければ、より良い結果が出るのではと期待しています。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
私自身、この4月より天文学のポスドクから機械学習という全く新しい世界に来ました。学ぶこともたくさんありますが、データ解析である以上、共通点もたくさんあります。未来を担う技術である機械学習、ディープラーニングに興味のある方は思い切って飛び込んでみるのも一興かと。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD