2021.01.10
○千万規模のコスト減!?OSSでHadoopクラスタを運用・管理したい ~ 序章 ~
1.はじめに
こんにちは。次世代システム研究室新卒のY.S.です。10月から大規模データ分析基盤運用チームに配属となりました。
我々のビッグデータプロジェクトでは分散処理基盤のデファクトスタンダードであるHadoopを使い、主にHive・Spark等のアプリケーションを駆使してETLや解析作業を行っています。クラスタやその上のアプリケーションの管理はOSSのambari(あんばり)でやっていて、Web UIでポチポチするだけでプロビジョニング(クラスタにノードを追加したり、逆に外したり)や、ノード・システム監視や、ディスク逼迫等のアラート通知が可能です。とっても便利です。
さてこの便利ambari、今までは無償で使えていたのですが、今後バージョンアップしていくには有償になりました(涙)。しかも結構お高め。。
そこで今回は、他のOSSを組み合わせてhadoopを管理する方法を模索したいと思います。上手くすれば○千万円のコスト削減になるかも!?それでは行ってみよー
1-1.やりたいこと・このブログでやること
様々なossを駆使して、(無償で)hadoopクラスタをmanageしたいです。今後数回のブログを通して、ambariが搭載していた以下の管理機能を移植できればと考えています。
- ノードのプロビジョニング(HDFS, YARN, HIVE)
- ノードの死活・リソース監視
- 各アプリケーションの監視
- アラート・通知
本稿はその初回ということで、HadoopクラスタのキモであるHDFSとYARNのプロビジョニングを行います。各ノードにconfigを配ったりプロセスを起動したりする必要があるので、AnsibleのWeb UIであるAnsible AWXで構成管理します。目指すゴールは、Ansible AWXでボタンを押すとHDFS上でYARNが起動して、mapreduceタスクがきちんと動くことを確認できれば良しとします。
Hadoopを触らない人がブラウザバックしてしまわないようにHadoopを触らない人でもこの記事を楽しんでいただけるように、以下で軽くHadoopの説明をします。「いっぱいノードがあって、上手く構成管理してやる必要があるなぁ」と思ってください。
1-2.Hadoop
Hadoopは所謂「分散処理基盤システム」で、巨大すぎる(TB以上)データを、多数(数十~数百)のノードでもって寄ってたかってどうにかするシステムです。「分散」というからには、データを複数のノードで保持したり(HDFS)、データ処理をタスクに分割して複数ノードでそれらを同時に効率よく実行したり(YARN)できます。
HDFS: Hadoop Distributed File System
NameNode(マスターノード。通常1~2つ)とDatanode(スレーブノード。多数)で構成される分散ファイルシステムです。ファイルをblock(デフォルトは128MB)と呼ばれる単位に分割し、一つのblockを複数(デフォルトは3)のDataNodeにコピーして保持しておきます。これの良いところは、blockの冗長化による高可用性と、各ノードが並列にblockを読み出すためI/Oコストを軽減できることです。NameNodeはどのファイルのどのblockがどのDataNodeに保管されているかを管理します。NameNodeは単一障害点となるので、もうひとつStandby用のNameNodeを起動してHA(High Availability)構成にすることが多いです。(今回はしません)
YARN: Yet-Another-Resource-Negotiator
クラスタのリソースを管理する仕組みです。マスターノードにはResourceManager、スレーブノードにはNodeManagerが常駐プロセスとして存在しています。HDFS上のアプリケーション毎に立ち上がったApplicationMasterが、ResourceManagerにリソースの割り当てを要求します。ApplicationMasterは割り当てられたリソースを元にNodeManagerにジョブを発行し、スレーブノードで処理が行われます。前身であるmapreduce v1ではマスターノードに多くの役割が集中してしまっていましたが、YARNではそれらをResourceManagerとApplicationMasterに分けて切り出すことで、マスターノードがボトルネックになるのを防いでいます。
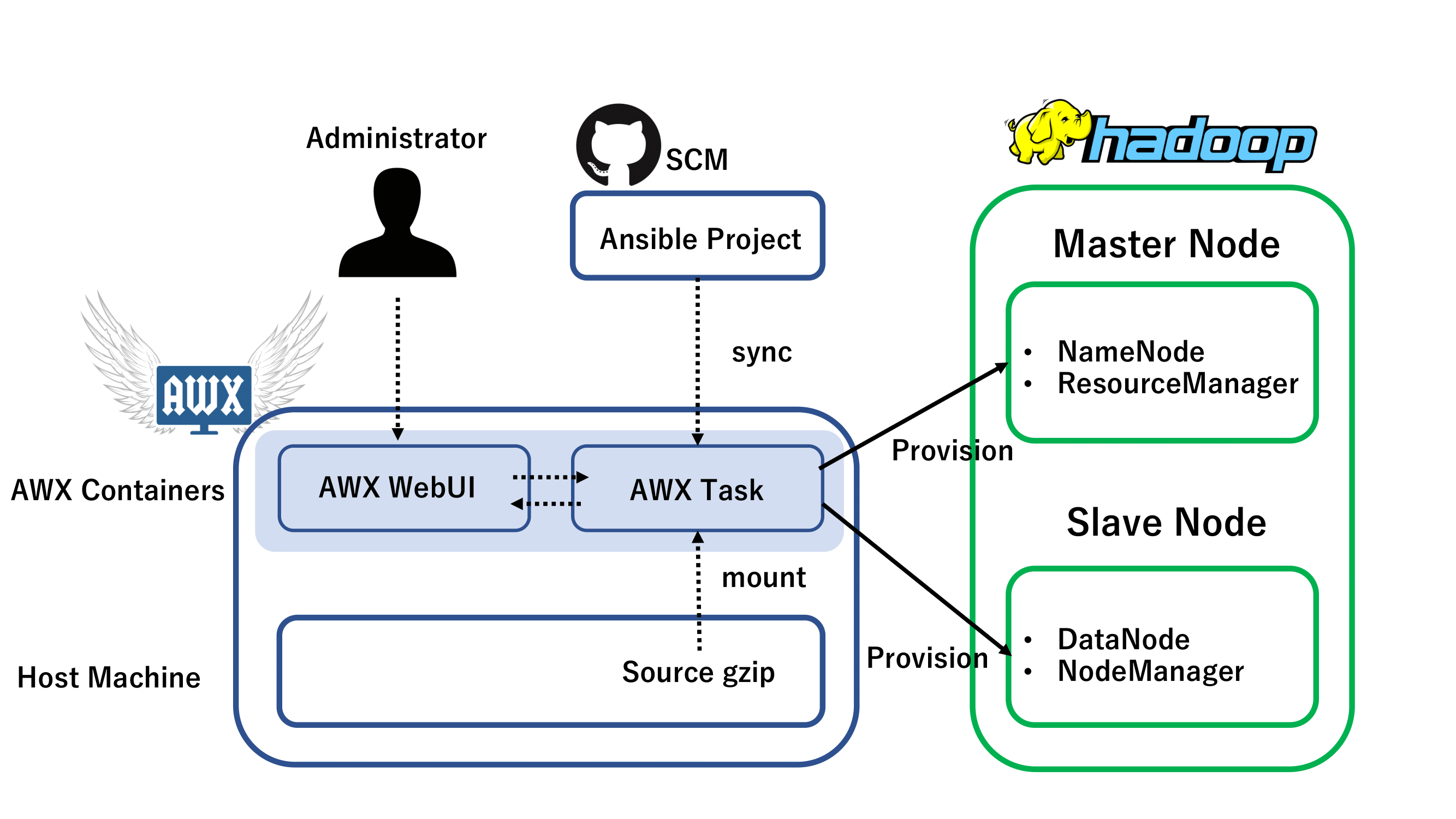
2.Ansible AWXによるHadoopクラスタ構成管理
Hadoopを管理するansibleプロジェクトを作成し、それをAWXから実行します。プロジェクトには、jdkとhadoopのインストール、HDFS・YARNのconfig配布及びプロセス起動をtask化します。ノード間の疎通・ポート設定は事前に手動で済ませてある前提です(この辺も纏めてansibleでやりたい)。
AWXによるHadoop構成管理のイメージは下図のようになります。
2-1.Ansible AWX
Ansible AWXは、AnsibleをWeb UIで使用するためのOSSツールです。scmで管理されているプロジェクトと同期し、ホストの管理やplaybookの実行をボタン操作で行うことができます。
awxをdocker-composeで起動するansibleプロジェクトがgitのリポジトリとしてあるので、cloneしてきてplaybookを叩くとAWXのコンテナが立ち上がります。今回はコンテナから各ノードにJDKとHadoopのgzipソースを配るので、オリジナルのdocker-compose.ymlに加筆してgzipが置いてあるホストのディレクトリとAWX Taskコンテナをマウントします。
また、AWXでは管理対象のホストの設定を、インベントリタブから行います。ansibleプロジェクトのhostsファイルにはhosts_groupのみを定義しておき、AWXのインベントリ設定画面でhostsファイルに合わせてグループを作り、その中にホストを加えていきます。今回はgroupとして、HDFSのNameNode・DataNode、YARNのResourceManager・NodeManagerをgroupを定義します。
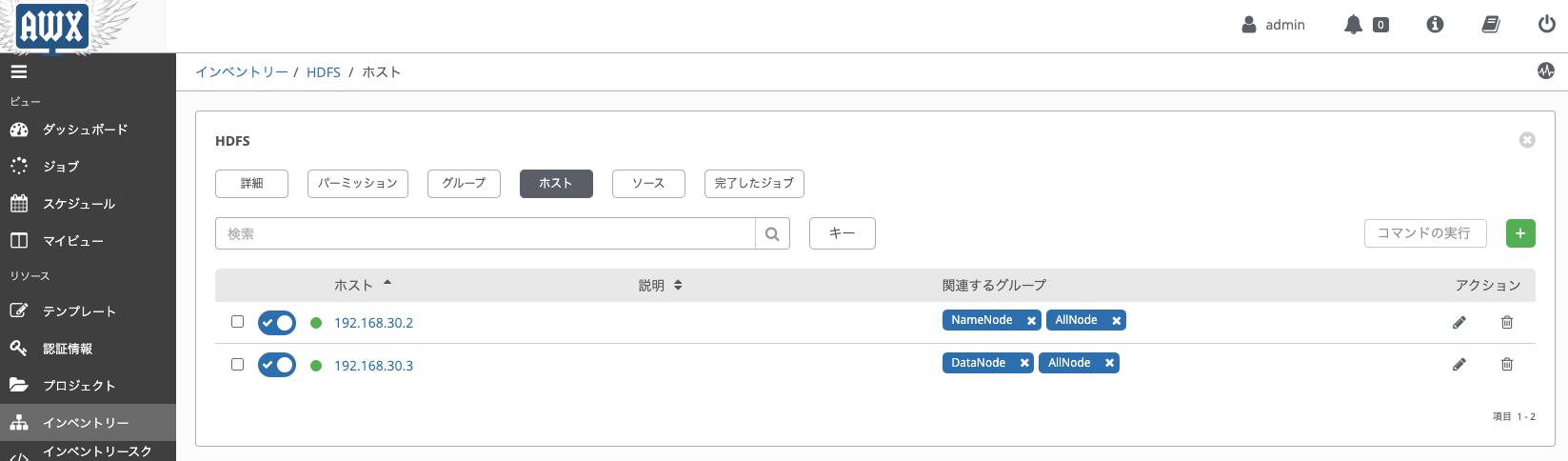
↓hostsファイルはgroupの定義だけ。
[AllNodes] # HDFS [NameNode] [DataNode] # YARN [ResourceManager] [NodeManager]
2-2.プロジェクト構成
こんな感じにしました。roleとして切り出したのは、JDK・Hadoopのインストール、HDFSとYARNのconfig配布・プロセス起動です。各configはテンプレートにして、デプロイ時にgroupsマジック変数を各ホストのipで置き換えます。
↓プロジェクトの構成
roles
hadoop_setup
tasks
hadoop_install.yml
main.yml
hdfs
handlers
main.yml
tasks
deploy_config.yml
main.yml
templates
core-site.xml.j2
hdfs-site.xml.j2
slaves.j2
jdk_setup
tasks
jdk_install.yml
main.yml
hdfs
handlers
main.yml
tasks
deploy_config.yml
main.yml
templates
mapred-site.xml.j2
yarn-site.xml.j2
hadoop_setup.yml #JDK・Hadoopのインストール
hdfs.yml #HDFSのconfig配る、NameNode・DataNodeプロセス起動
hosts
yarn.yml #YARNのconfig配る、ResourceManager・NodeManagerプロセス起動
2-3.JDK・Hadoopインストールタスク
roles/jdk_setup/tasks/jdk_install.yml
JDKのgzipファイルを各ノードに配布して解凍します。
- name: defrost-zip-confirm
stat: path=/etc/jdk1.8.0_202/
register: result
- name: defrost jdk tar file
unarchive:
src: /var/lib/awx/volumes/file/gz/jdk-8u202-linux-x64.tar.gz
dest: /etc
when: not result.stat.exists
- name: Create symbolic link to java
file:
src: /etc/jdk1.8.0_202
dest: /etc/java
state: link
- name: Add paths to etc/profile
blockinfile:
dest: /etc/profile
insertafter: '^# xxxx'
content: |
export JAVA_HOME=/etc/java
export PATH=$PATH:$JAVA_HOME/bin
export CLASS_PATH="."
- name: Apply /etc/profile
shell: source /etc/profile
roles/hadoop_setup/tasks/hadoop_install.yml
JDKと同等にgzipを配布・解凍します。加えて、Hadoopクラスタとして使用するディレクトリを作成します。
- name: defrost-zip-confirm
stat: path=/etc/hadoop-3.1.4/
register: result
- name: Defrost hadoop tar file
unarchive:
src: /var/lib/awx/volumes/file/gz/hadoop-3.1.4.tar.gz
dest: /etc
when: not result.stat.exists
- name: Create symbolic link to hadoop
file:
src: /etc/hadoop-3.1.4
dest: /etc/hadoop
state: link
- name: Create hdfs name dir
file:
path: /opt/hdfs/name
state: directory
owner: hadoop
group: hadoop
- name: Create hdfs data dir
file:
path: /opt/hdfs/data
state: directory
owner: hadoop
group: hadoop
- name: Create hadoop pid dir
file:
path: /var/run/hadoop/pids
state: directory
owner: hadoop
group: hadoop
- name: chenge config permissions for hadoop
file:
path: /etc/hadoop/etc/hadoop/{{ item }}
owner: hadoop
mode: 0755
with_items:
- core-site.xml
2-4.HDFSセットアップタスク
core-site.xml、hdfs-site.xml、slavesを各ノードに配り、新しくノードが追加された時などconfigに変更があった場合は、全てのノードでNameNodeもしくはDataNodeのプロセスを再起動します。
roles/hdfs/tasks/deploy_config.yml
- name: deploy hdfs configs
template:
src: "conf/{{ item.file }}.j2"
dest: "/etc/hadoop/etc/hadoop/{{ item.file }}"
owner: "{{ item.user }}"
with_items:
- { file: core-site.xml, user: hadoop}
- { file: hdfs-site.xml, user: hadoop}
- { file: slaves, user: hadoop}
notify:
- start_hdfs_daemon_namenode
- start_hdfs_daemon_datanode
roles/hdfs/handlers/main.yml
- name: start_hdfs_daemon_namenode
shell: source /etc/profile; /etc/hadoop/bin/hdfs --daemon stop namenode; /etc/hadoop/bin/hdfs --daemon start namenode; jps
async: 15 #ansible sshプロセスが閉じても終了しないようにするための設定。
poll: 0 #ansible sshプロセスが閉じても終了しないようにするための設定。
args:
executable: /bin/bash
become: yes
when: "'NameNode' in group_names"
- name: start_hdfs_daemon_datanode
shell: source /etc/profile; /etc/hadoop/bin/hdfs --daemon stop datanode; /etc/hadoop/bin/hdfs --daemon start datanode; jps
async: 15 #同上
poll: 0 #同上
args:
executable: /bin/bash
become: yes
when: "'DataNode' in group_names"
2-5.YARNセットアップタスク
roles/yarn/tasks/deploy_config.yml
HDFSと同様に、configファイルの配布とプロセスの起動を行います。
- name: deploy yarn configs
template:
src: "conf/{{ item.file }}.j2"
dest: "/etc/hadoop/etc/hadoop/{{ item.file }}"
owner: "{{ item.user }}"
with_items:
- { file: yarn-site.xml, user: hadoop}
- { file: mapred-site.xml, user: hadoop}
notify:
- start_yarn_daemon_resourcemanager
- start_yarn_daemon_nodemanager
roles/yarn/handlers/main.yml
- name: start_yarn_daemon_resourcemanager
shell: source /etc/profile; /etc/hadoop/bin/yarn --daemon stop resourcemanager; /etc/hadoop/bin/yarn --daemon start resourcemanager; jps
async: 15
poll: 0
args:
executable: /bin/bash
become: yes
when: "'ResourceManager' in group_names"
- name: start_yarn_daemon_nodemanager
shell: source /etc/profile; /etc/hadoop/bin/yarn --daemon stop nodemanager; /etc/hadoop/bin/yarn --daemon start nodemanager; jps
async: 15
poll: 0
args:
executable: /bin/bash
become: yes
when: "'NodeManager' in group_names"
2-6.各configのtemplates
groupsマジック変数は、インベントリのgroupに定義してあるホストのipに置き換わります。
core-site.xml.j2
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://{{ groups.NameNode.0 }}</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-data/</value>
</property>
</configuration>
slaves.j2
{% for host in groups.DataNode %}
{{ host }}
{% endfor %}
mapred-site.xml.j2
ambariを使わずにyarnのセットアップを行う場合は、classpathやenvの設定を書く必要があります。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/etc/hadoop/etc/hadoop,
/etc/hadoop/share/hadoop/common/*,
/etc/hadoop/share/hadoop/common/lib/*,
/etc/hadoop/share/hadoop/hdfs/*,
/etc/hadoop/share/hadoop/hdfs/lib/*,
/etc/hadoop/share/hadoop/mapreduce/*,
/etc/hadoop/share/hadoop/mapreduce/lib/*,
/etc/hadoop/share/hadoop/yarn/*,
/etc/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/etc/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/etc/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/etc/hadoop</value>
</property>
</configuration>
yarn-site.xml.j2
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>{{ groups.ResourceManager.0 }}</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value>
</property>
</configuration>
3.実際に動かす
上記のansibleプロジェクトで、下記の構成でHadoopクラスタのセットアップを構築します。サーバーにはConoha VPSを使います。
- CIサーバー Mem:8GB Disk:100GB 1台 (Ansible AWX)
- マスターノード Mem:8GB Disk:100GB 1台 (NameNode, ResourceManager)
- スレーブノー Mem:8GB DISK:100GB 1台 (DataNode, NodeManager)
分散処理とはなんだったのかノードは次回以降で増やしていきます。
3-1.デプロイ
AWXでansibleタスクを実行するには、対象のインベントリや使用するプロジェクト・playbookやsshログインするためのkey等を指定したテンプレートを作成して実行します。
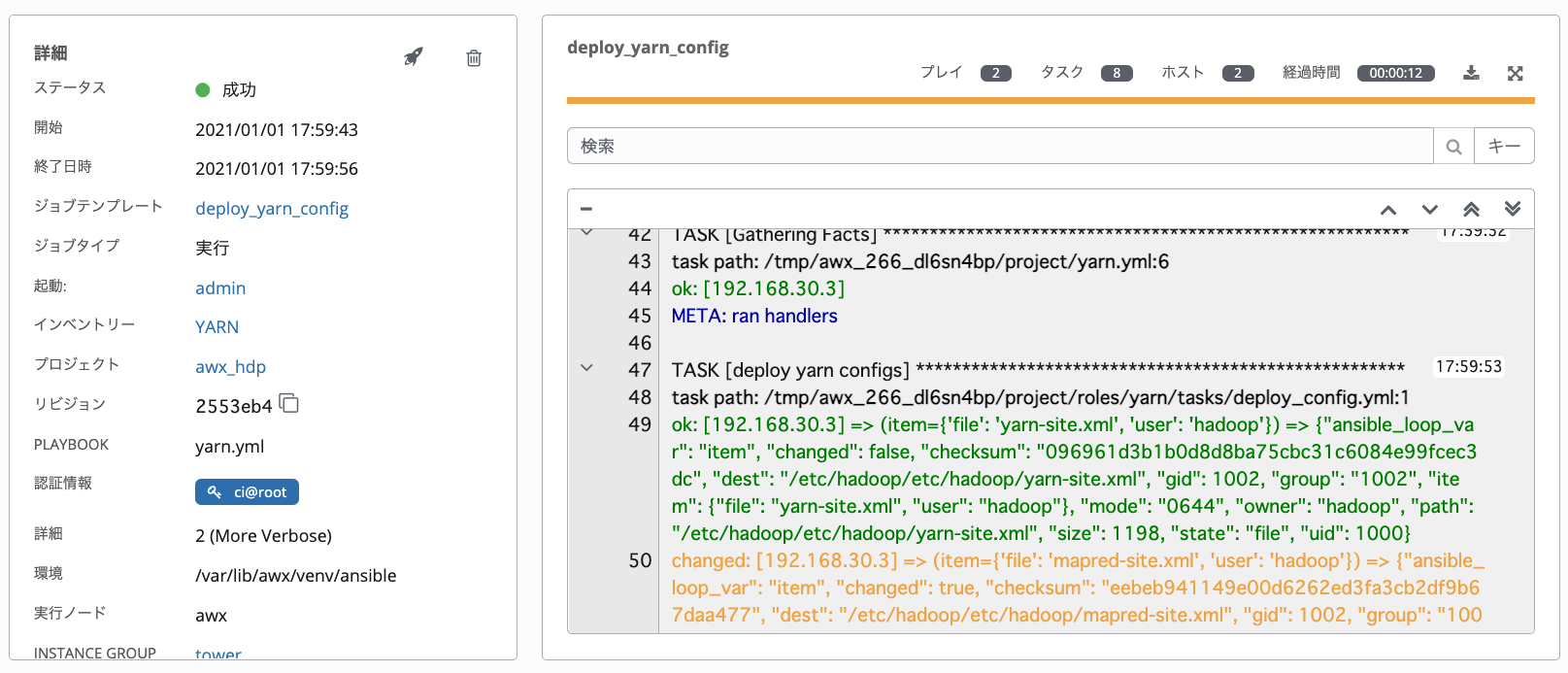
hadoop_setup、hdfs、yarnの順に実行していきます。
3-2.HDFSの確認
デプロイが完了したのでdfsadmin -reportを叩き、HDFSが起動してスレーブノードが認識されていることを確認します。
[root@master1 ~]# /etc/hadoop/bin/hdfs dfsadmin -report Configured Capacity: 105551663104 (98.30 GB) Present Capacity: 94947164160 (88.43 GB) DFS Remaining: 94935957504 (88.42 GB) DFS Used: 11206656 (10.69 MB) DFS Used%: 0.01% Replicated Blocks: Under replicated blocks: 34 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Low redundancy blocks with highest priority to recover: 34 Pending deletion blocks: 0 Erasure Coded Block Groups: Low redundancy block groups: 0 Block groups with corrupt internal blocks: 0 Missing block groups: 0 Low redundancy blocks with highest priority to recover: 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (1): Name: 192.168.30.3:9866 (slave1) Hostname: slave1 Decommission Status : Normal Configured Capacity: 105551663104 (98.30 GB) DFS Used: 11206656 (10.69 MB) Non DFS Used: 6078431232 (5.66 GB) DFS Remaining: 94935957504 (88.42 GB) DFS Used%: 0.01% DFS Remaining%: 89.94% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Sat Jan 02 15:36:54 JST 2021 Last Block Report: Sat Jan 02 12:42:42 JST 2021 Num of Blocks: 246 [root@master1 ~]#
いいかんじです。
3-3.mapredタスクの確認
次にhadoopに用意されている円周率計算のmapreduce exampleを実行して、yarnが機能していることを確認します。
[root@master1 ~]# /etc/hadoop/bin/hadoop jar /etc/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar pi 10 100 Number of Maps = 10 Samples per Map = 100 Wrote input for Map #0 Wrote input for Map #1 Wrote input for Map #2 Wrote input for Map #3 Wrote input for Map #4 Wrote input for Map #5 Wrote input for Map #6 Wrote input for Map #7 Wrote input for Map #8 Wrote input for Map #9 Starting Job 2021-01-01 17:42:18,732 INFO client.RMProxy: Connecting to ResourceManager at /192.168.30.2:8032 2021-01-01 17:42:19,102 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1609490406204_0001 2021-01-01 17:42:19,223 INFO input.FileInputFormat: Total input files to process : 10 2021-01-01 17:42:19,267 INFO mapreduce.JobSubmitter: number of splits:10 2021-01-01 17:42:19,379 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1609490406204_0001 2021-01-01 17:42:19,381 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2021-01-01 17:42:19,525 INFO conf.Configuration: resource-types.xml not found 2021-01-01 17:42:19,525 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2021-01-01 17:42:20,001 INFO impl.YarnClientImpl: Submitted application application_1609490406204_0001 2021-01-01 17:42:20,048 INFO mapreduce.Job: The url to track the job: http://master1:8088/proxy/application_1609490406204_0001/ 2021-01-01 17:42:20,048 INFO mapreduce.Job: Running job: job_1609490406204_0001 2021-01-01 17:42:27,154 INFO mapreduce.Job: Job job_1609490406204_0001 running in uber mode : false 2021-01-01 17:42:27,156 INFO mapreduce.Job: map 0% reduce 0% 2021-01-01 17:42:33,339 INFO mapreduce.Job: map 60% reduce 0% 2021-01-01 17:42:36,393 INFO mapreduce.Job: map 70% reduce 0% 2021-01-01 17:42:38,415 INFO mapreduce.Job: map 100% reduce 0% 2021-01-01 17:42:39,424 INFO mapreduce.Job: map 100% reduce 100% 2021-01-01 17:42:39,437 INFO mapreduce.Job: Job job_1609490406204_0001 completed successfully 2021-01-01 17:42:39,551 INFO mapreduce.Job: Counters: 53 File System Counters FILE: Number of bytes read=226 FILE: Number of bytes written=2453770 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=2620 HDFS: Number of bytes written=215 HDFS: Number of read operations=45 HDFS: Number of large read operations=0 HDFS: Number of write operations=3 Job Counters Launched map tasks=10 Launched reduce tasks=1 Data-local map tasks=10 Total time spent by all maps in occupied slots (ms)=38624 Total time spent by all reduces in occupied slots (ms)=3019 Total time spent by all map tasks (ms)=38624 Total time spent by all reduce tasks (ms)=3019 Total vcore-milliseconds taken by all map tasks=38624 Total vcore-milliseconds taken by all reduce tasks=3019 Total megabyte-milliseconds taken by all map tasks=39550976 Total megabyte-milliseconds taken by all reduce tasks=3091456 Map-Reduce Framework Map input records=10 Map output records=20 Map output bytes=180 Map output materialized bytes=280 Input split bytes=1440 Combine input records=0 Combine output records=0 Reduce input groups=2 Reduce shuffle bytes=280 Reduce input records=20 Reduce output records=0 Spilled Records=40 Shuffled Maps =10 Failed Shuffles=0 Merged Map outputs=10 GC time elapsed (ms)=1811 CPU time spent (ms)=5390 Physical memory (bytes) snapshot=3230367744 Virtual memory (bytes) snapshot=30797205504 Total committed heap usage (bytes)=2794979328 Peak Map Physical memory (bytes)=310697984 Peak Map Virtual memory (bytes)=2808238080 Peak Reduce Physical memory (bytes)=265543680 Peak Reduce Virtual memory (bytes)=2809884672 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=1180 File Output Format Counters Bytes Written=97 Job Finished in 20.92 seconds Estimated value of Pi is 3.14800000000000000000 [root@master1 ~]#
いいかんじです。sample数を100と少なめで実行したのでそこまで正確ではありませんが、円周率が計算されています。
4.まとめ
今後数回に渡って、ambariを使わないHadoopクラスタ管理を頑張っていく予定です。
初回である本稿では、HadoopセットアップとHDFS・YARNのデプロイを行うAnsibleプロジェクトを作成しました。また、AWXからプロジェクトのタスクを起動し、デプロイされたHDFSとYARNの動作確認を行いました。ambariを使わずにYARNをセットアップするためのconfigや、ansibleのsshが切れた後にプロセスが残るようにする(これはansible慣れしてないのが問題)のに手間取りましたが、それ以外は概ねすんなりと進みました。最終的にマスターノード1つ、スレーブノード1つのHadoopクラスタでHDFSとYARNが動作しました。
今後は、プロビジョニングプロジェクトをHA構成に対応させたり、AWXのhostsの更新でノードのcommission/decommissionの切り替えを可能にしたりしていきます。また、今回作成したプロジェクト以外にも、例えばノード監視のプロジェクトなどを作成し、それら全てをAWXで一元管理するようにしていきたいと考えています。
最後に
次世代システム研究室では,データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら,ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD