2017.12.17
Apache ArrowでPySparkとPandasをスピードアップしてみました
お疲れ様です。次世代システム研究室のK.S.(女性、外国人)です。
前回のブログでは、機械学習の技術とそれを用いた予測 「AIで株をやる!~株の売り買いを深層強化学習で予測~」 について紹介しました。今回は少し話題を変えて、機械学習やデータ解析などに用いるビッグデータを取り扱う技術について共有したいと思い、PySparkと呼ばれる大規模データ分散処理フレームワークとその関連技術(Apache Arrow)について試してみたことを紹介したいと思います。
「急いで解析結果を出したいのに計算が遅い」、「取り扱うデータが大きすぎて、計算リソースが足りない」といった悩みを抱えたことはありませんか?
最近、ビッグデータを用いた機械学習やデータ解析などを行う機会が多くなってきました。データ量が増えるほど、データの処理に要する時間が増え、ストレスを抱える方も多いのではないでしょうか。私は当初、素人感覚ではありますが、PySparkという分散処理フレームワークを用いて、データをあらかじめ分散させておけば、同時並列でデータを処理することが可能となり、計算が早くなるのではないかと考えました。しかし、これだけですべてが解決されるわけではないということが分かりました。つまり、分散したデータを分析するプロセスも考えておかなければならないということです。例えば、PySparkという分散処理フレームワークを用いて得たデータを、データ分析ライブラリPandasを用いて取り扱いたいとき、PySparkやPandasでのデータの読み書きが遅く、さらに、PySparkのデータフレームからPandasのデータフレームに変換するのも容易ではなく、時間を要してしまいます。これらのデータ処理やデータ変換スピード問題を解決するため、最近Apache Arrow(インメモリで列指向データを扱うためのデータフォーマット仕様とアルゴリズム+ライブラリ)が開発されてきました「IBM Spark Technology CenterのBryan Cutlerさんの記事に参考」。
そこで今回は、PySparkという機械学習やデータ解析などに用いるビッグデータを取り扱う技術について共有し、PySparkの問題に対処可能なApache Arrowも検討したいと思います。主な実験は、「PySpark」と「PySpark+Apache Arrow」のパフォーマンスの最適化の比較です。
このブログの構成は、以下のとおりです。
最初に「① 概要」で、PySparkとApache Arrowについて、簡単に説明します。分散処理やデータベースなどについて基本知識をお持ちの方は、「② 実装環境」から読んで下さい。また、データ分析ライブラリPandasは、いろいろな場面で使われていますので、今回は説明を割愛させていただきます(参考はこちら)。
①概要
PySpark
PySpark(Spark Python API)は、オープンソースの分散クエリと処理エンジンであるApache Spark(Sparkと呼びます)に組み込まれている、PythonとSparkを連携するフレームワークです。
PySpark を説明する前に、まずSparkを説明したいと思います。Sparkは、高速計算ができるように一般化されたクラスタコンピューティングプラットフォームです。Sparkは、分散システム(例えば、バッチ・アプリケーション、反復アルゴリズム、インタラクティブクエリ、ストリーミングなど)を必要としていた広範なワークロードをカバーするように設計されています。Sparkでは、これらの作業負荷をサポートすることで、データ解析の場面でしばしば必要となるさまざまな処理を簡単かつ低コストで組み合わせることを可能にしています。例えば、ビッグデータを用いた機械学習を行いたいが、大量のデータを1台のマシンで処理できない場合、Sparkを用いて様々なタスクを簡単に複数台のマシンに分散させて処理することができます(図1)。

図1:Sparkでの分散イメージ: Apache Spark: An Engine for Large-Scale Data Processingより転載
PySparkはPython+Sparkです。PySparkフレームワークの基盤は、Pythonで一般的な実行エンジンであるSpark CoreのJava APIの上に構築されています(図2)。PySpark shellはPython APIをSpark Coreにリンクし、Spark context(Sparkで操作を行うための主な入り口)を初期化します。それから、Spark contextはPy4Jを利用し、Java Virual Machine(JMV)を立ち上げます。JMVはデータをキャッシュやシャッフルし、様々なクラスターにデータを分散します。分散されたデータはPythonで処理することができます。PythonとJVMのデータ交換コストが発生します。結果、大規模データを扱うときには、データ交換プロセスのための計算時間はかなりかかってしまいます。そこで、今回この問題を対応するために、Apache Arrowを検討してみました。

図2:PySparkプラットフォームの基盤: PySpark Internalsより転載
より詳細に興味がある方はLearning Sparkに関する本とLearning PySparkに関する本をおすすめします。ちなみに、最近 Learning PySparkに関する本の日本語版も出版されました。
Apache Arrow
Apache Arrowは計算コストを減らしたいという目的で開発されたものです。例えば、インメモリでデータを配置して高速に処理できるようにしたり、各システムを連携するときのデータ交換コストを減らしたりするためのライブラリです。
インメモリについて、Apache Arrowは階層的なインメモリの列指向データを取り扱うためのシリアライズのフォーマットとアルゴリズムです。Apache Arrowのメモリフォーマットは、シリアライズオーバーヘッドなしで瞬間的なデータアクセスのためのゼロコピー読み取りができます。Apache Arrowは列型(列指向)ですので(図3)、行型より、データを格納する上で効率が良いようです。
図3:Apache Arrowメモリ:Apache Arrowより転載
システム連携について、Apache Arrowはさまざまなシステム間の新しい高性能インターフェースとして機能します(図4)。様々なツールとの連携が(特にクラスターローカル間や、言語間)手間がかからないし、PySparkのセクションで述べた問題(PythonとJVMのデータ交換コスト)も可能になってきます。
図4:Apache Arrowインターフェース:Apache Arrowより転載
Apache Arrowを使用すると、実行エンジンは最新のプロセッサーに搭載されたSIMD(Single Input Multiple Data)操作を利用して、分析データ処理をベクトル化して最適化することができます。カラムレイアウトは、CPUやGPUなどの最新のハードウェアでパフォーマンスを向上させるために、データのローカリティに最適化されています。
② 実装環境
環境準備
PySparkのパフォーマンスを最大限に発揮させるには、大きなサーバ内に、複数のマシンがあるような環境が一番よいですが、今回は簡単にだれでもPySparkの魅力を知ってもらえるような実装環境を作りたいので、ノートパソコン(スタンドアローン)でも計算できるような環境を作りました。詳細を下に示します。
ノートパソコンのスペック
-
OS: Windows 7
CPU: Intel® Core(TM) i5-6300U CPU @ 2.40GHz
Memory(RAM): 8GB
System: 64 bit
計算環境
Clouderaの仮想マシンを利用しました。
-
VMware Workstation 14 Player
Cloudera QuickStarts VM (CDH 5.12)
実装するときに、メモリ4GB、Core 2を利用しました。
加えて、Arrowを利用するため、Sparkなどのバーションをアップデートすることが必要です。下記のように実装環境を構築しました。
まず、anacondaをインストールし、SparkとJavaをアップデートしました。それから、anaconda を利用し、PySpark 2.2.0、PyArrow 0.7.1、Pandas 0.21.0もインストールしました。
install anaconda:
wget http://repo.continuum.io/archive/Anaconda2-2.5.0-Linux-x86_64.sh bash Anaconda2-2.5.0-Linux-x86_64.sh source ~/.bashrc
update Spark (Spark 2.2.0 hadoop 2.7):
tar -zxvf spark-2.2.0-bin-hadoop2.7.tqz sudo mv /home/cloudera/Downloads/spark-2.2.0-bin-hadoop2.7/* /usr/lib/spark/
update Java (download):
sudo tar -zxvf /home/cloudera/Downloads/jdk-8u144-linux-x64.tar.gz cp -r jdk-8u144-linux-x64 /usr/java/ sudo update-alternatives --install "/usr/bin/java" "java" "/usr/java/jdk1.8.0_144/bin/java" 0 sudo alternatives --config java sudo update-alternatives --set java /usr/java/jdk1.8.0_144/bin/java
install pyspark, pyarrow, pandas via anaconda
conda install -c conda-forge pyspark conda install -c conda-forge pyarrow conda install -c anaconda pandas conda install -c anaconda pytz
set bash
sudo nano ~/.bashrc
# added by Anaconda2 2.5.0 installer export PATH="/home/cloudera/anaconda2/bin:$PATH" export JAVA_HOME=/usr/java/jdk1.8.0_144 export SBT_HOME=/usr/share/sbt-launcher-packaging/bin/sbt-launch.jar export SPARK_HOME=/usr/lib/spark export PATH=$PATH:$JAVA_HOME/bin export PATH=$PATH:$SBT_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin export PATH=$PATH:$SPARK_HOME/bin export PYSPARK_SUBMIT_ARGS="--master local[2] pyspark-shell" export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH export PYTHONPATH=$SPARK_HOME/python/lib/py4j-0.9-src.zip:$PYTHONPATH export PYSPARK_DRIVER_PYTHON=ipython export PYSPARK_DRIVER_PYTHON_OPTS="notebook --port=8999" export SPARK_DIST_CLASSPATH=`hadoop classpath`
sudo source ~/.bashrc
これで、準備完了です。実装するときに、terminalでpysparkを入力すれば、jupyter notebookが立ち上がり、notebook環境でこのブログの内容をテストできるようになります。
ファイル準備
図3で説明しましたが、データフォーマットは二つがあり、列型(Column-oriented)と行型(Row-oriented)になります。行型はCSVといったテキストファイルです。列型はParquet、ORCといったデータ形式です。今回は、両方のデータフォーマットを使います。CSVとParquetの変換はPandasで行うことができます(③実験と結果に参考)。
今回使ったデータは前回のブログ で使ったものを利用しました。データはHDFS (Hadoop Distributed File System : Hadoop分散ファイルシステム)から読み込む必要がありますので、ファイルをHDFSへコピーする方法は下記になります。
hadoop fs -copyFromLocal -f /home/cloudera/Documents/logistic/7201_nissan_daily_20160101_20161231.csv hdfs://quickstart.cloudera:8020/user/cloudera/ hadoop fs -copyFromLocal -f /home/cloudera/Documents/logistic/7201_nissan_daily_20160101_20161231.parquet hdfs://quickstart.cloudera:8020/user/cloudera/
③ 実験と結果
実験は4つに分けます。まず、よく使われているPySpark/Pandasのデータ処理パフォーマンスを確認しました。次に、Apache Arrowを用いてデータ処理の計算負担を軽減できるかを検討しました。それから、Apache Arrowを用いてPySparkのデータフォーマット交換コストを軽減できるかをテストしました。最後に、近いうちに期待できる例(PySpark+Apache Arrowで機械学習に適応可能な例)も作ってみました。
PySpark/Pandasのデータ処理パフォーマンスの確認
具体的に行ったのはPySpark/Pandas(JVM object/Python)におけるParquet/CSV(列型/行型)ファイルの読み書きスピードの比較です。
読み込み
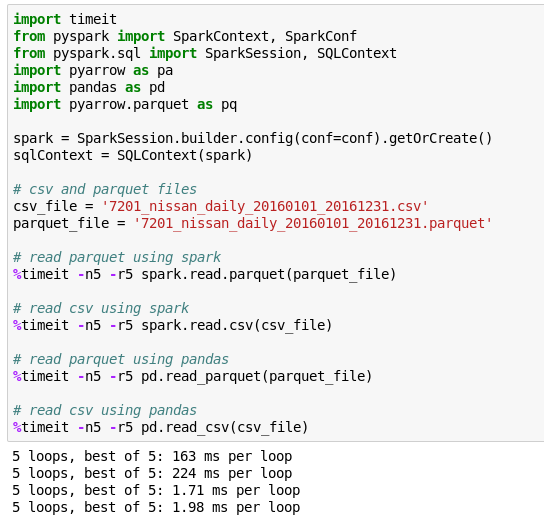

書き込み

想定されたように、PySpark、Pandasのどちらを用いても、Parquet(列型)のほうが、CSV(行型)より、読み書き時間が短い結果となりました。また、今回の実験環境では、思ったより、PySparkとPandasのデータ読み書き時間に差が見られました。PySparkよりPandasのほうが読み書き時間が短かったようです。
Apache Arrowを用いてデータ処理の計算負担を軽減できるか
具体的に行ったのはPyArrow(Apache ArrowのPython実装)でParquetファイルの読み書きをスピードアップしてみました。例はPandasでのデータ読み書きです。
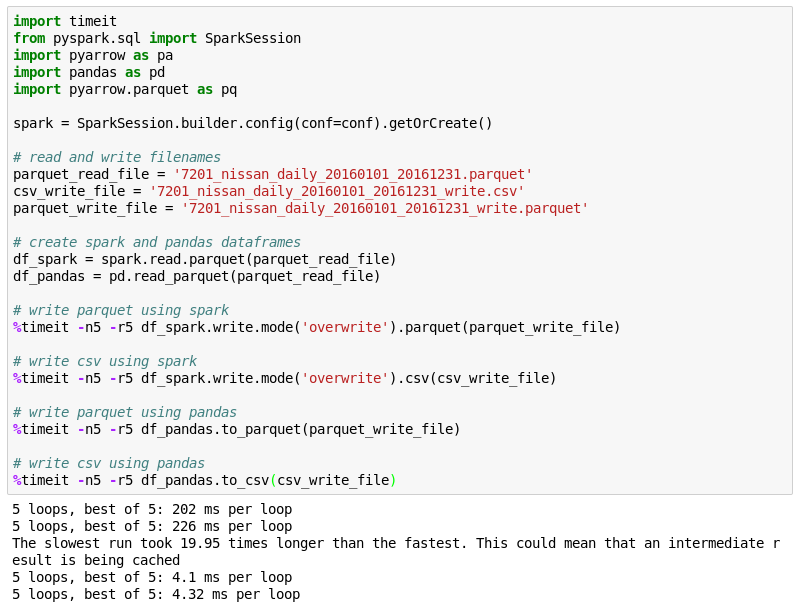
読み込み
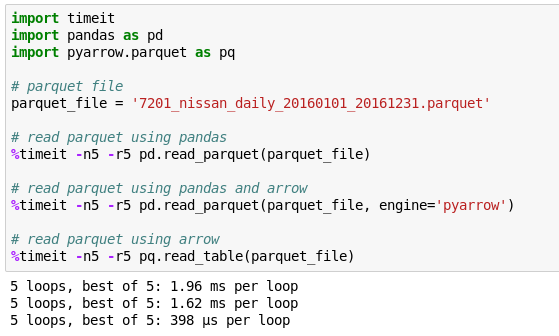

書き込み
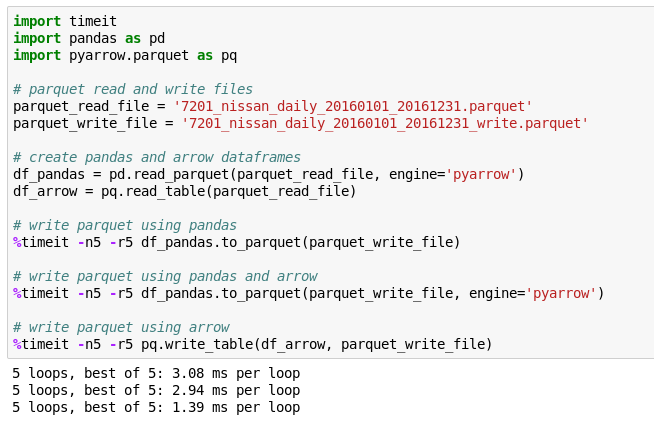

engine=’pyarrow’を入れるだけで、Pandasでのデータ読み書き時間を早くすることができました。また、PyArrowのデータフォーマットをそのまま用いると、読み書き時間はさらに早くなりました。
Apache Arrowを用いてPySparkのデータフォーマット交換コストを軽減できるか
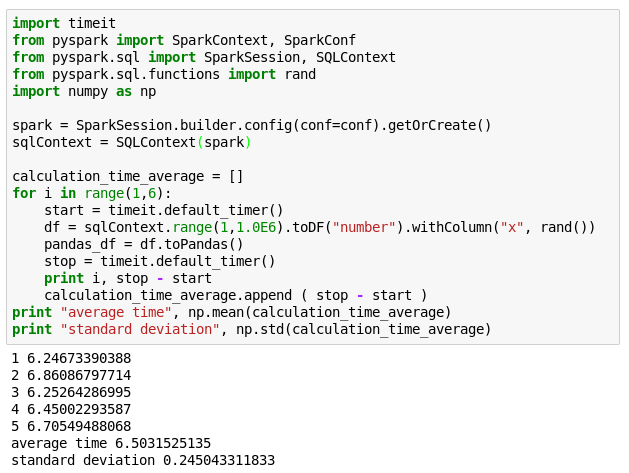
Apache ArrowがPySparkからPandasへ(JVM→Python)のデータフォーマット交換するための計算分担に対処可能かどうかの確認するため、Apache ArrowでtoPandasのスピードアップテストを行ってみました。
PySparkからspark.conf.set(“spark.sql.execution.arrow.enabled”, “true”)と入力する事でApache Arrowへの対応をオンにできるので、この設定を有効にして実行してみました。結果は下記になります。
toPandasでArrowなし

toPandasでArrowあり
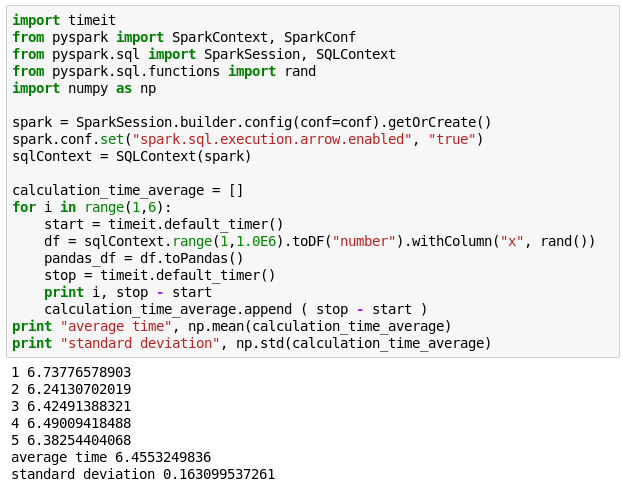

残念ながらスピードは変わりませんでした。Sparkのgithubを確認すると、今回使ったSpark2.2にはArrowが部分的にしか対応していないようです。Arrowブログによると、Spark2.3から大きな変更が加えられるようです。toPandasがスピードアップされるのは、Spark2.3がリリースされたあとになりそうですね。
近いうちに期待できる例
ここまで、Apache Arrowは読み書きスピードアップできることを示しましたが、実際の問題に適用したいときはどうやってApache Arrowを用いるのかイメージするため、簡単な機械学習(線形解析)の例を示したいと思います。
下記の図のように、PySparkで線形解析を行うことが可能になってきました。しかし、詳細分析や可視化するため、PySparkデータフォーマットからPandasデータフレームに変換する必要です。このときに、toPandasを使います。分析や可視化したいデータが多いほど、toPandasの計算時間が増えていきます。したがって、近いうちにApache Spark2.3でApache Arrowが使えるようになると、計算時間の節約が期待でき、機械学習など様々な応用に役に立つだろうと思います。

まとめ
よって、Apache Spark 2.3がリリースされれば、Apache Arrowを利用し、PySparkでデータ処理やデータフォーマット交換するための計算時間をさらに改善することができると期待されます。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方の応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD