2020.07.06
Open AI Gymに基づく強化学習環境の実装と検証
こんにちは。次世代システム研究室のY.R.です。外国人です。よろしくお願いします。
1 はじめに
近来自分は強化学習(reinforcement learning)をいろいろ勉強しいています。為替取引においてA2Cという強化学習アルゴリズム[1]も検証しました[2][3]。今度強化学習環境(Env)のカスタマイズすることについて自分の学習を皆さんに共有致します。
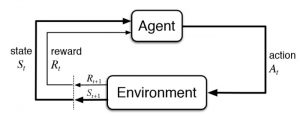
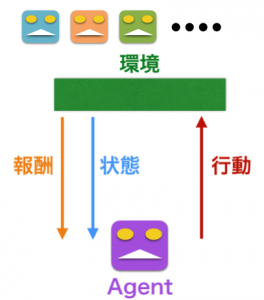
図(1)
強化学習は上記の図に従って動けることです。普段皆さんは強化学習アルゴリズムつまりAgentのことに注目していますが、強化学習の環境にあまり重視していないです。
Open AI gym[4]のおかげで、以下のような複数の面白い環境はいくつが公開されています。強化学習に興味が持っている方々アルゴリズムに専念できますようになります。



しかし、本番のサービスに強化学習の応用を検証するために、具体的なサービスに合わせている環境を構築しなければならないです。OpenAI Gymに基づいて簡単的な環境の開発方法をこちらで共有致します。
2 OpenAI Gymに基づく強化環境を実装
強化学習においてOpenAI Gymは人気がある開発ツールキットです。OpenAI Gymで検証のビジネスに合わせている環境を作ることは簡単になるようになっています。大部分の環境はゲームに向かっていますが、普通の為替取引方々[5]に向けと仮想通貨マーケットメーカーの視点からの環境[6]も公開されています。これから簡単的な環境実装を通してOpenAI Gymの使用方法を共有致します。
2.1作る環境の説明
皆さんがわかりやすいために、作る環境を以下のように説明致します。
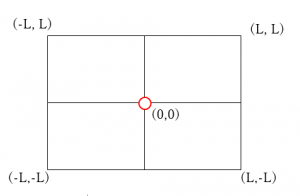
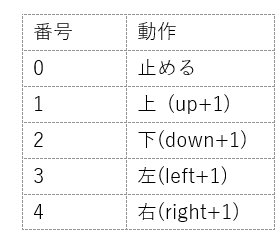
作る環境は地図のような「正方形の世界」ですが、支えられる動作は右側のテーブルにおいてあります。
開始のポイントは正方形にランダムに生成されるが、目標は赤い原点になっています。
2.2 環境の実装
ゲーム向けよく使われている環境と違って、作る環境は可視化のことは含まれていないです。
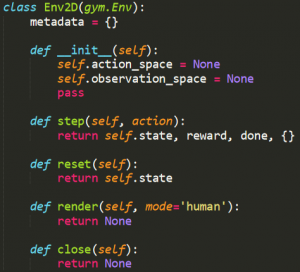
OpenAI Gymに基づく開発は紹介したように、gymのEnvというクラスをけい継承していくつ重要な関数を実現することです。紹介した「正方形の世界」の実装は以下の通り:
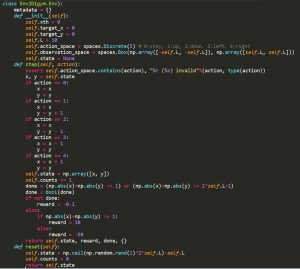
先ず__init__の初期化処理で作る環境の動作空間(action space)と観察空間(observation space)を実現しておきます。今度実装する動作空間と観察空間は2.1の説明に合わせています。
次はstepという関数を通してAgentはに従って動けます。これらで、報酬(reward)の設定は大事なことです。適当な報酬はトレーディングしたagentのパータンに大きく影響を与えます。具体的に説明すると、今度「正方形の世界」に二つの報酬があります。reward=10の設定はagentを原点に戻すことを励ますが、今度reward=-50は「正方形の世界」の縁に流しのことを罰します。二つの報酬は近いほど目標に探りは難しくなります。
最後にresetという関数で、agentをランダムの開始ポイントに調整します。そして、改めてトレーディングができますようになります。
実装の環境に可視化のことは必要ではないので、renderという関数の実現は必要ではないです。
3 作った環境を検証
これから作った環境の使用方法と動きを検証します。今度Open AI BaselinesとKeras-rlという二つフレームワークを指定しました。
Open AI Baselines[7]: BaselinesとGymは同じくOpenAIから公開される強化学習のツールです。DQN、A2CやPPO2などよく利用されているアルゴリズムを含まれています。
Keras-rl[8]: Keras-rlのおかげで、皆さんはkeras[9]のように強化学習モデルを開発できます。新しいアルゴリズムの実装は追加中です。
今度DQNを利用して作った環境を検証します。
Open AI Baselines(バージョン:0.1.5)とインタラクション
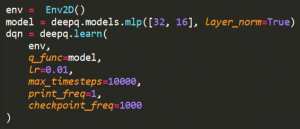
こちらで単なる二層のパーセプトロン(英: Multilayer perceptron、略称: MLP)を試しています。相関のコードは公開されています[10]。
Keras-rl(バージョン:2.4)とインタラクション

今度、 BoltzmannQPolicy という方策とSequentialMemoryという設定を使用しています。
相関のコードは公開されています[10]。
4.感想
始まり紹介したように強化学習の環境のディザインと実装は重要なことですが、常に無視されています。Open AI Gymのおかげで、強化学習の環境の開発は難しくないし、標準化にされていると気がします。Gymに基づく環境は様々なフレームワークと一緒に協力できます。
本番のサービスに合わせている環境を作れるかまた挑戦性が高いタスクです。動作空間と観察空間は重要な要因であるし、報酬の定義は大切な要因です。報酬はトレーディングのagentの動きと直接的に関わっています。
更に、gymのstep関数からagent単なる受け取りのことではない、agent自身が置いている環境にも影響を与えることも分かっています。
最後に、つまらないですが、強化学習のハイパーパラメータ調整は挑戦性が高い問題です。
最後に
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD