2020.07.07
Amazon Personalize を用いたレコメンドシステム構築
こんにちは。次世代システム研究室のT.M です。
はじめに
ECサイト等において、ユーザへ商品をレコメンドするという要件はありがちかと思います。そういった場合、機械学習を用いたレコメンドシステムを構築するのが理想ですが、アプリケーションエンジニアには荷が重く、また、開発に時間が掛かってしまいます。そこで、Amazon Personalize を利用することで、アプリケーションエンジニアだけでも容易に機械学習を用いたレコメンドシステムを構築することが可能です。本稿では、Amazon Personalize でのレコメンドシステムの作り方を紹介します。
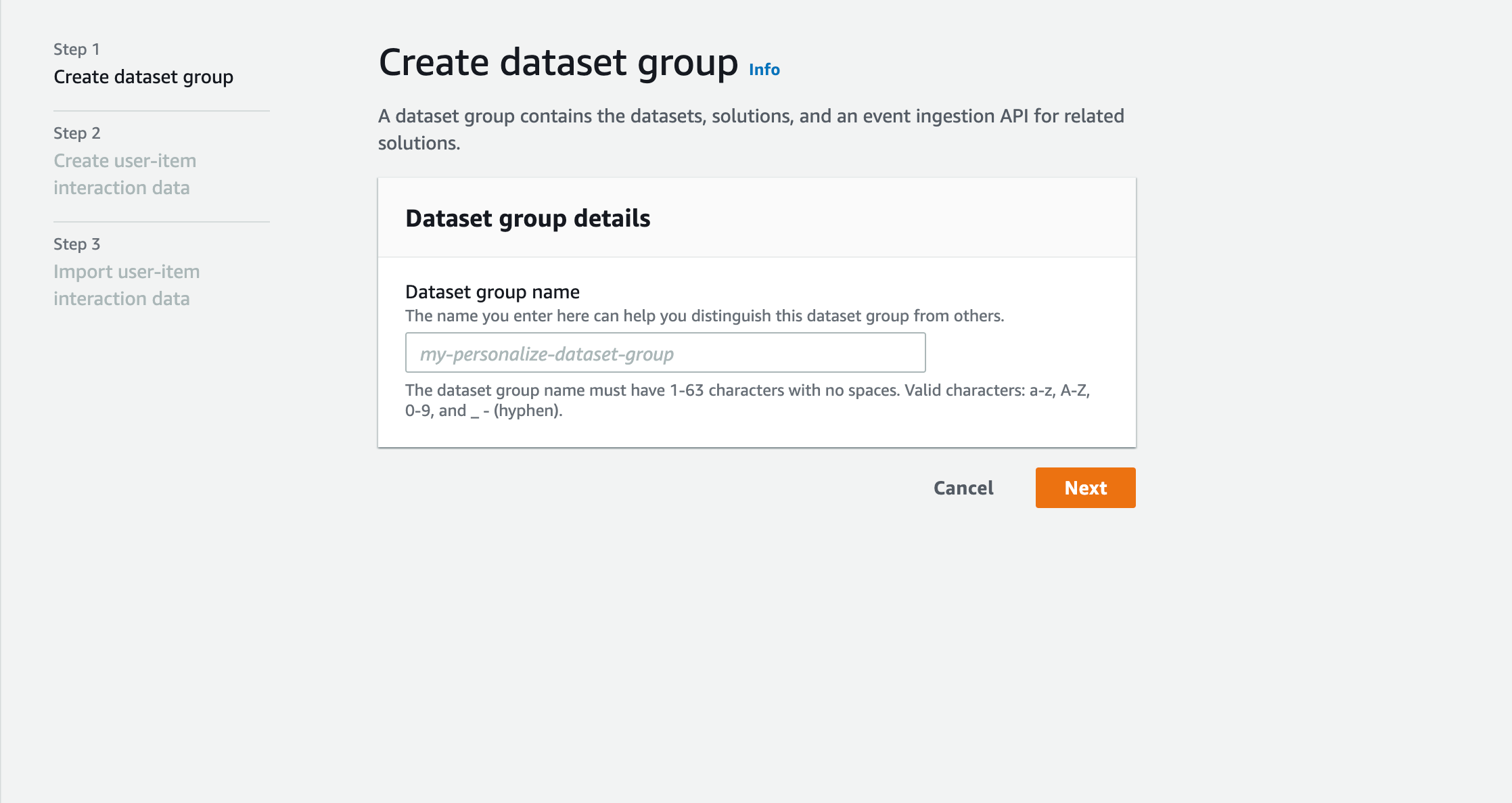
Dataset group
まずはDataset group を作成します。Dataset group とは、作成するレコメンドシステムを指します。下記画面で名前を付けて作成します。
Dataset 作成
次にDataset を作成します。Dataset とは、学習させるデータを指します。Recipe と呼ばれる学習アルゴリズムによって必要なデータが異なりますが、ここでは、User, Item, User-item interaction のデータを作成します。
各データのスキーマは、Apache Avro と呼ばれる形式で記述します。まずはUser スキーマを作成します。ここでは必須であるUSER_ID に加えて、年齢と性別の属性を付けるためにAGE, GENDER を追加しました。AGE は数値であるため、type をint にしました。GENDER はmale またはfemale が入るように、type をstring にして、categorical を付けます。
{
"type": "record",
"name": "Users",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "AGE",
"type": "int"
},
{
"name": "GENDER",
"type": "string",
"categorical": true
}
],
"version": "1.0"
}

Item、User-item interaction も同様にスキーマを定義します。以前は、1つのスキーマに5つのフィールドしか持てなかったのですが、現在は50ものフィールドが持てるようになり、様々なデータを学習できるようになっています。
今回は、以下のようなItem, User-item interaction スキーマを作成します。Item には、ジャンルを追加しています。User-Item iterations のスキーマにある、EVENT_TYPE は購入や商品閲覧などのイベントが入ります。
{
"type": "record",
"name": "Items",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "GENRE",
"type": "string",
"categorical": true
}
],
"version": "1.0"
}
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "EVENT_TYPE",
"type": "string"
},
{
"name": "TIMESTAMP",
"type": "long"
}
],
"version": "1.0"
}
スキーマを定義した後は、実際にデータを入れていきます。データは定義したスキーマに合わせたCSV ファイルであり、S3 に保存しておきます。下記画面でDataset import job に名前をつけて、S3 からCSV を読み取る設定をします。
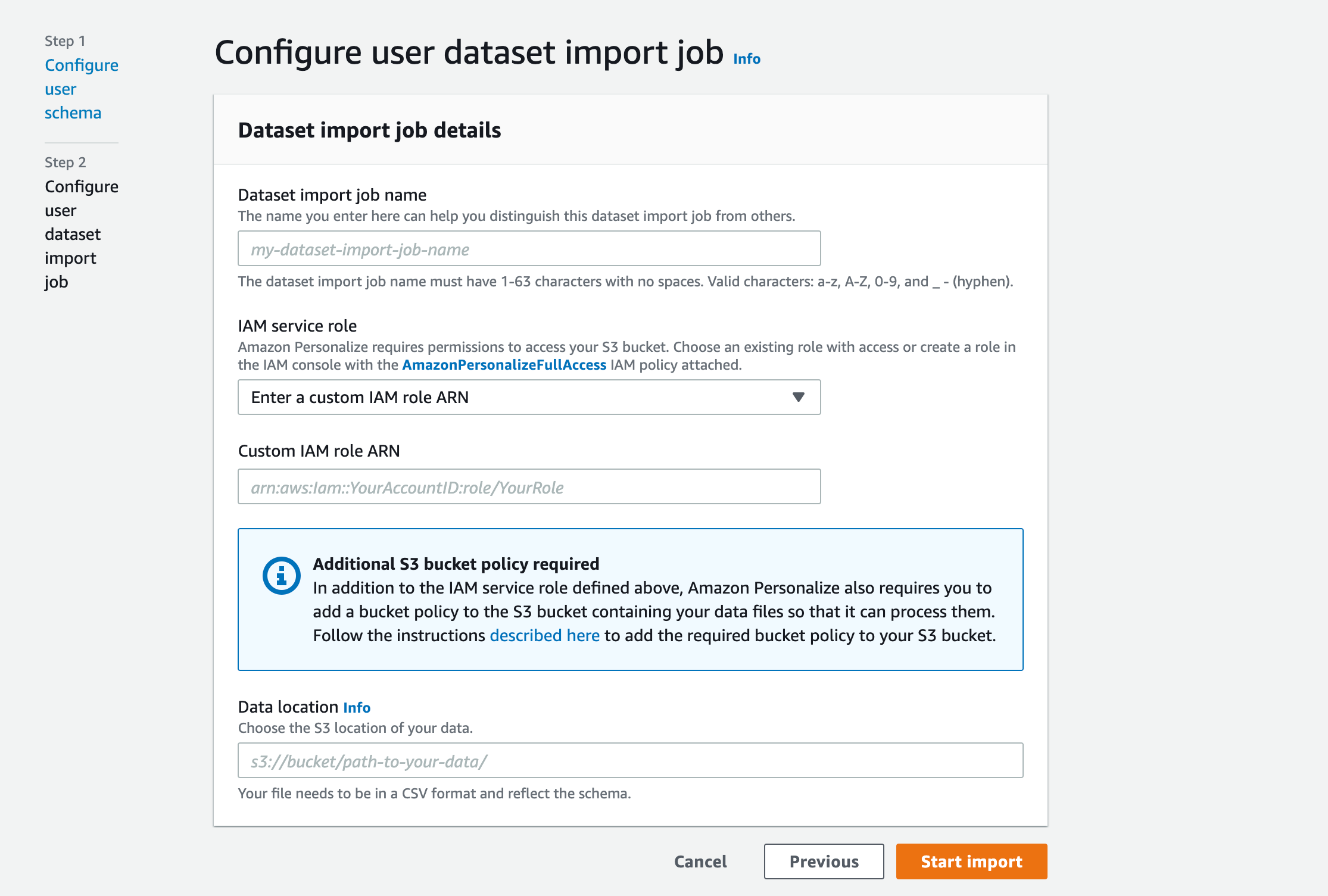
CSV はスキーマに合わせて作成すれば良いのですが、Item にあるGENRE など1つのItem に複数データが持つ場合は、以下のように、”|” で区切ります。
ITEM_ID,GENRE i100,g200 i101,g200|g201
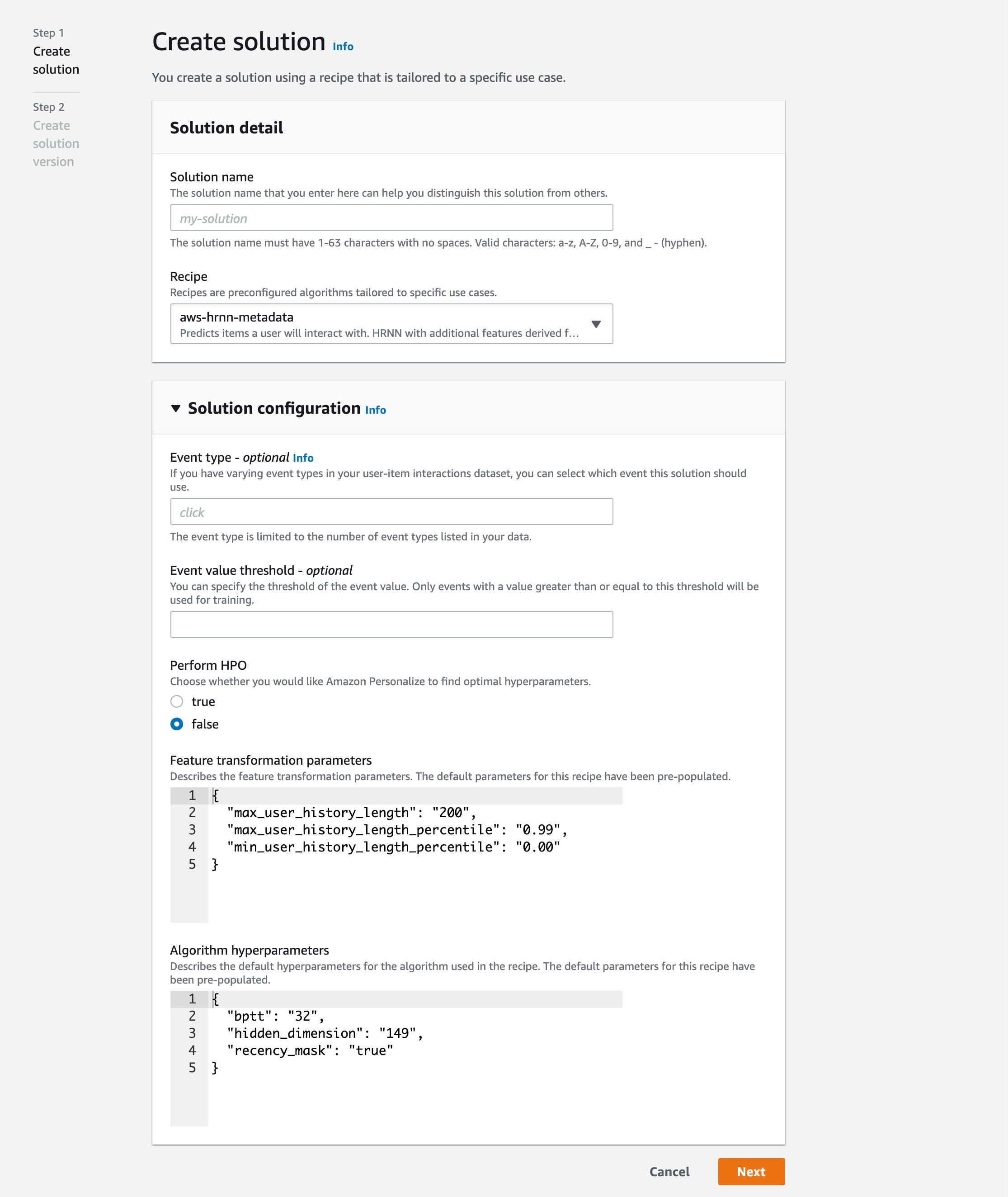
Solution 作成
Solution を作成します。Solution とは、レコメンドのモデルを指します。
ここでは、Recipe として、aws-hrnn-metadata を使います。パラメータを調整して、チューニングすることができますが、デフォルトで作成します。
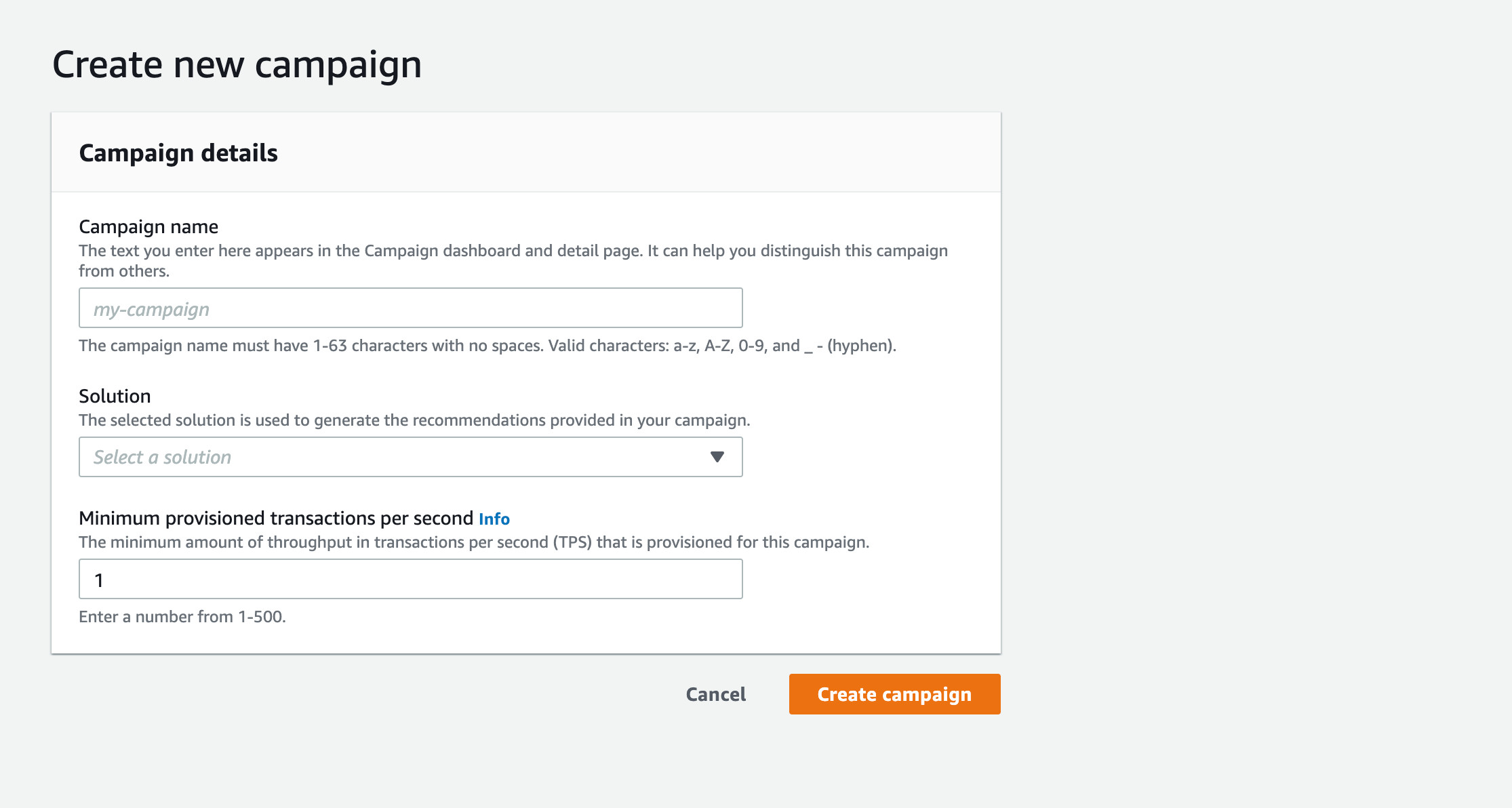
Campaign 作成
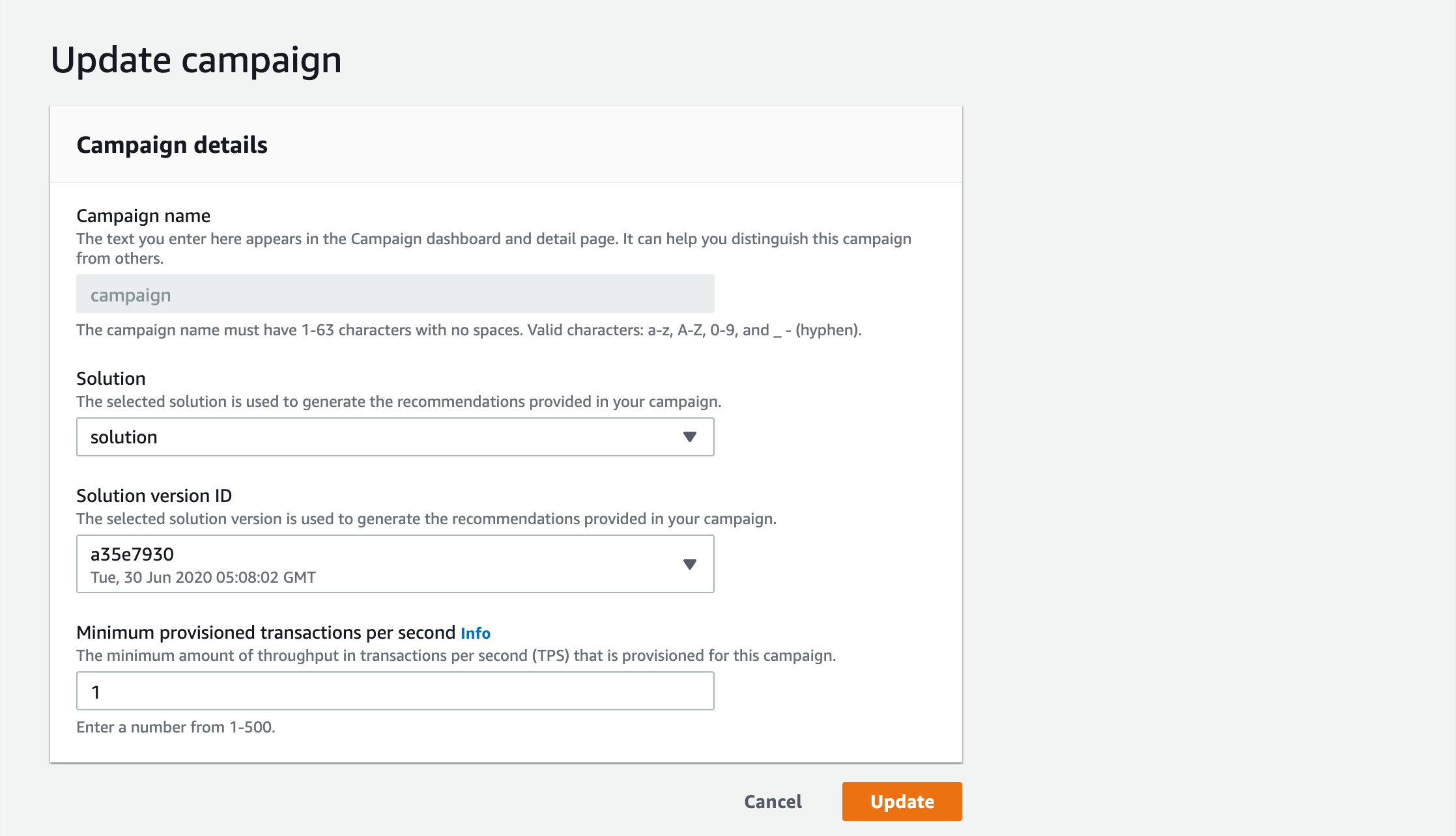
最後にCampaign を作成します。Campaign とは、レコメンドAPI を指します。先ほど作成したSolution を選択し、また、同時に作成されたSolution version を選択します。Minimum provisioned transactions per second はスループットを意味し、この値に比例して料金が加算されますので、今回は1 を設定します。
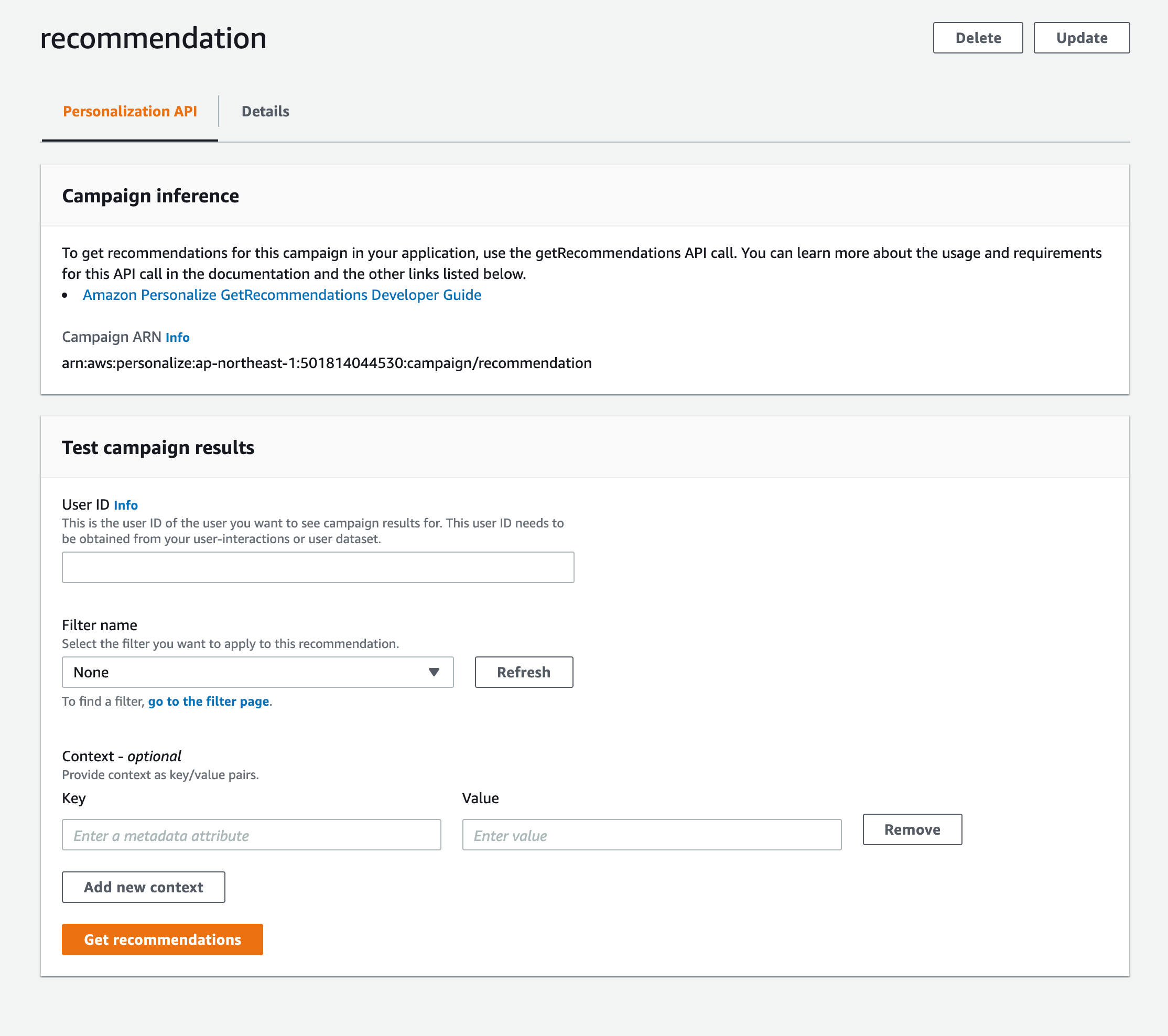
Campaing が作成されると、レコメンドをすることができます。UserId を入力すると、そのユーザに適したItemId が返却されます。
学習するデータが更新された場合は、Dataset import job、Solution version を作成し、Campaing を更新します。Dataset やSolution は改めて作成する必要はありません。
コンソールからレコメンドするのは動作確認で便利ですが、実際にアプリケーションで利用するには不便です。その場合は、API を利用してレコメンドを取得することもできます。
Batch interface job の作成
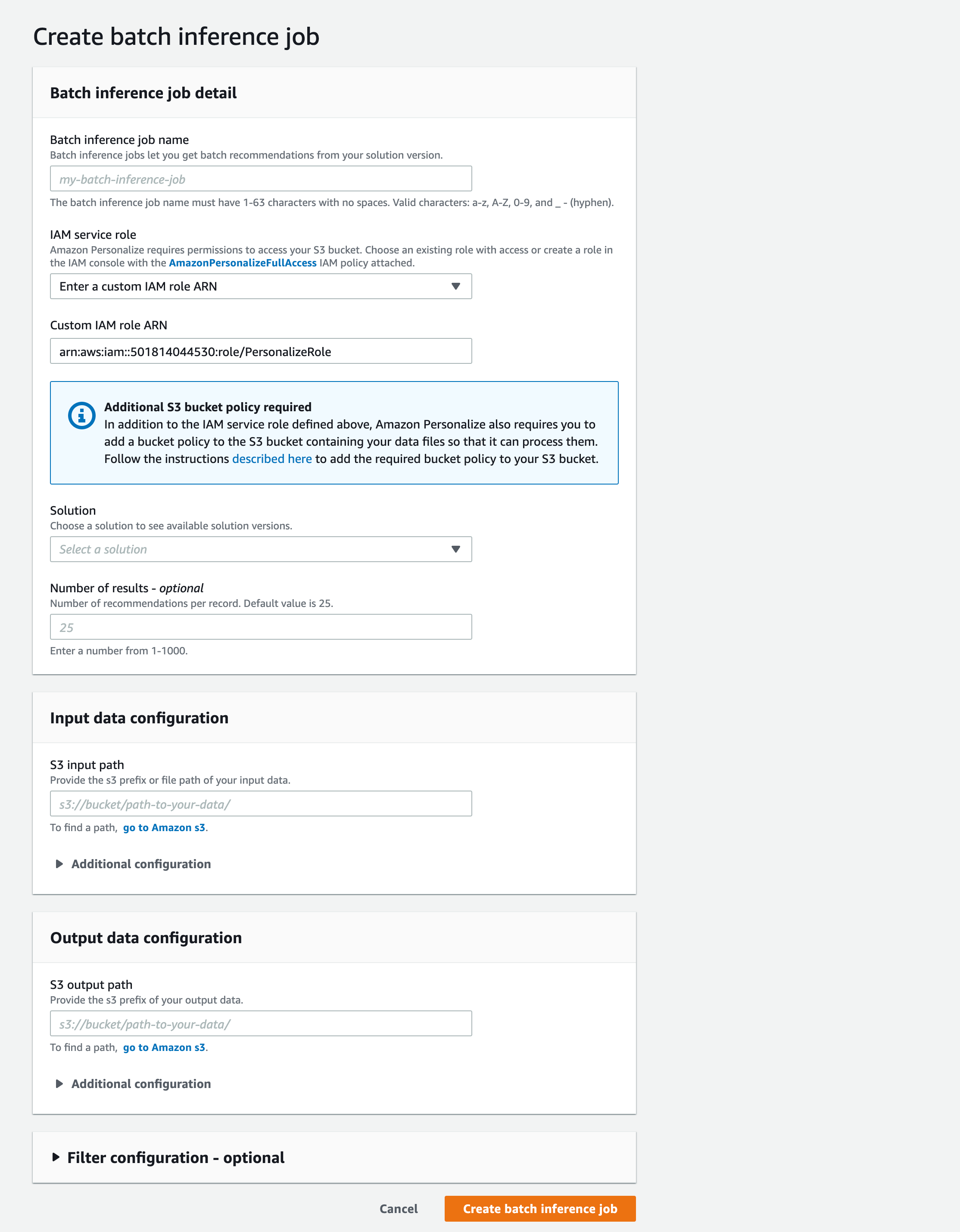
Campaign では、1ユーザごとにレコメンドの結果を取得できますが、複数ユーザの結果を一括で取得したいことがあります。その場合、Batch interface job を作成することで、一括で結果を取得することができます。
Campaign と同様にSolution, Solution version を選択します。取得したいユーザ一覧をS3 に保存しておき、そのパスを設定し、結果を保存するS3 のディレクトリを設定します。取得したいユーザ一覧は、以下のような形式で保存します。
{"userId": "u100"}
{"userId": "u101"}
{"userId": "u102"}
結果は以下のような形式で作成されます。
{"input":{"userId":"u100"},"output":{"recommendedItems":["i100","i101",...], "scores":{0.0536518,0.0413711,...],errors:null}
{"input":{"userId":"u101"},"output":{"recommendedItems":["i200","i201",...], "scores":{0.0536518,0.0413711,...],errors:null}
最後に
Amazon Personalize を用いて、アプリケーションエンジニアでも容易にレコメンドシステムを作成することができました。Amazon Personalize は比較的新しいサービスであり、一括で取得することができるBatch Interface job の機能が追加されたり、学習させることができるスキーマのフィールド数が5から50 に増えたり、より便利に進化しています。
今後は、Solution のパラメータの設定などでチューニングをして、より精度の高いレコメンドシステムを作っていきたいと考えています。
次世代システム研究室では、グループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD