2018.04.23
深層強化学習で集団行動を機械に学習させたい!
次世代システム研究室のJK(男)です。よろしくお願いします。
前回のブログは最近(2017/10)出た論文をベースに、深層強化学習によるself-playの勉強をしました。今回も引き続き、強化学習について勉強したいと思います。前回の実験を軽くサマると、「相手より早くゴールする」という単純なゲームにでagentを学習させましたが、agentが「相手を先に倒してからゴールする」という行動を学習した(ように見える)ことがわかりました。これはself-playにより、単純な環境から複雑な行動を学習したと解釈できました。
強化学習は、正解のない世界でベターな方法を模索する手法です。これは私達の普段の行動の選択に似ていますね。具体的な説明は前回のブログなどを見て下さい。今回は前回のself-playの延長として、マルチエージェントの強化学習についてfocusします。参考にする論文は、これとこれです。
Section1はマルチエージェント強化学習の簡単な説明で、Section2は今回の実験の環境と使用したアルゴリズムの説明です。Section3と4で、今回行った実験の結果と考察を行い、Section5はまとめです。このブログでは行った実験のハイライト部分を紹介します。他の実験結果については、githubにまとめてありますので、興味のある方は参照してください。
1. マルチエージェント強化学習(MARL)
マルチエージェント強化学習(multi-agent reinforcement learning; MARL)とは、そのままの意味で複数のエージェントがいる環境の強化学習です。深層強化学習で有名どころといえば、Atari、AlphaGoなどでしょう。これらはそれぞれ1 agentと2 agentの学習環境で、どちらもゲームです。実際の世界を考えてみればわかりますが、agentが一人とか二人しかいない状況というのは考えにくいです。ゲームなどの特殊な状況を作り出さない限り、中々ない状況でしょう。強化学習を現実世界に応用しようと思った時、このマルチエージェントという環境は避けては通れない道です。
また1–2 agentの間の相互作用は単純になりがちで、複数のagentになって初めて現れる行動もあります。たとえばAlpha Goだと2 agentは常に敵対的な行動を取りますが、複雑な環境下では状況によって「敵対」と「協力」的行動が現れるのが普通でしょう。
以上のようにMARLはとても重要なのですが、あまり盛り上がっていないのも現状です。この理由はおそらく、単純に「難しいから」だと思います。1–2 agentというsimpleな状況であっても、その環境のrewardを最大化する強化学習は不安定な場合が多く、そのために色々なアルゴリズムが開発されているのが現状です。これが>2以上のagentsになれば、agent間の相互作用は爆発的に膨れ上がり、その行動や学習の難しさも上がります。
もう一つの問題は計算量です。教師あり学習ではトレーニングでは所与のものですが、強化学習では学習しながら、自らの行動とその結果得たrewardをトレーニングとして使います。したがって、非常に多くの計算量が必要になるのです。これが複数のagentについての計算となれば、ただでさえキツイ計算量がさらに増え、学習が大変になります。
こんなわけで、MARLは非常に重要な学習方法ではあるのですが、なかなか研究の進んでこなかった分野だと(個人的には)思います。しかし最近は、アルゴリズムや計算機の発展により、ようやく研究が活発になりつつある感じがしています。
2. 実験環境とアルゴリズム
今回はOpenAIによって開発されたマルチエージェントの実験環境と、MARLを行うアルゴリズムのライブラリを使って実験を行います。実験環境はMAPEで、以下のサンプル動画の通り2次元上の単純な環境のため、計算量が少なくて済むというメリットがあります(たとえば簡単な学習なら手元のmacbook airでも10分もあれば終わります)。難しいsetupも要らず、git cloneしてinstallすればすぐ使えるのも嬉しいポイントです。見た目はMujocoなどを使ったものに比べると地味ですが、計算量を抑えることで本質的な学習にfocusすることができます。
MAPEで学習したagentの例
MARLのアルゴリズムとしてこの実験ではとMADDPGを使います。MADDPGはDDPG(Actor-criticの一種)をmulti agent用に応用したものです。MARLの難しさは、学習するagentが複数になることで学習が不安定になるところです。MADDPGではtraining中、本来はagentが知り得ない「神の視点」の情報をagentに与えることで、学習を安定化させます(一方で、実際に使う時には「神の視点」を除きます)。以下は、論文から抜粋した図です。なんのこっちゃいな人もいると思いますが、ここが詳しくわからなくても以下は読めますので、この部分はスルーしてもらって大丈夫です。
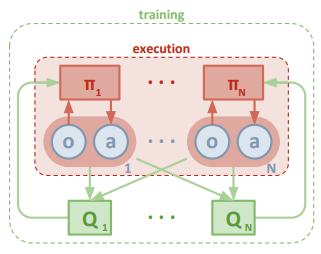
MADDPGの学習サイクルの概念図(R.Lowe et al. 2018)
3. 実験1(default scenarios)
まずMAPEのライブラリに付属しているデフォルトのシナリオ(実験環境)を動かしてみます。ここではそのうち特に面白いと感じた2つのシナリオについて紹介します。残りの結果について知りたい方はこちらを参照してください。
3-1. simple_spread
一つ目は”simple_spread”という実験環境です。これはagentが3体いて、ゴールも3つある環境です。報酬は、agentがゴールに近いほど多くもらえます。どのゴールでも同じ報酬ですので、一つの場所に集まるより3体のagentがそれぞれ別々のゴールにいくとき、agent達が最も多くの報酬を得られます。
まずは学習途中の結果です。
agent達はゴールに近づくと、報酬がもらえるというのはある程度学習したようで、ゴールに向かう動きを見せています。しかし、他のagentの動きには注意を払っていないため、一箇所に固まる場合も多く見られます。
次に十分に学習した後の結果です。
スムーズにagent達がそれぞれ別のゴールに向かって動く事を学習しています。見ればわかるように、一つのゴールで複数のagentがかち合うはありません。これが意味する所は、agentは(自分の行き先を決めるときに)それぞれ他のagnetの動きを見て、他のagentがどこに動くのかを察知して、自分の行先を決めているということです。Agentが「空気読んで動いてる」ように見えますね(笑)。もちろん、単純に報酬を最大化するように学習した結果なのですが、それを言えば人間の感情も、報酬を最大化した結果の進化の産物にすぎないかもしれず、実はこれらのagent達とあまり変わりないのかもしれません。
3-2. simple_tag
二つ目は”simple_tag”という実験環境です。これは単純にいえば、サバンナの草原で1匹のガゼル(緑agent)が3匹のライオン(赤agent) に追われている環境です。黒色の円は障害物です。本物のサバンナと違って、ガゼルは食べられることはありませんが、ライオンに接触されると負の報酬(マイナスポイント)を受けるので、できるだけライオンに接触されないよう逃げ回ります。ライオンは接触すると報酬(プラスポイント)がもらえるので、できるだけ当たろうとガゼルを追いかけます。
以下は十分に学習した後の結果です。
まずライオンがガゼルを追い、ガゼルが障害物を上手く使いながら逃げる、という学習がちゃんと期待通りにできていることがわかります。面白いのは複数のライオンが、単純に一体ごとに別々にガゼルを追うのではなく、(挟み撃ち、待ち伏せなど)チームプレイでガゼルを狩るという学習をしているところです。単数agentではあり得ない、マルチエージェント学習でのみ起きる学習で、期待した通りの成果です。
ところで、もしライオンagentの学習方法をMADDPGでなく、普通のDDPGにした場合どのように変化するでしょうか?(Sectoin2参照)
以下が学習結果です。
MADDPGと比べて違いはないように見えますが、よく見ると、(MADDPGの場合と比較すると)ライオンは個別にガゼルを追いかけ回す傾向があり、あまりチームプレイをしていないのがわかります。まぁ定量的な測定はしていませんが。。チームプレイを学習する上では、他のagentがどのように動くのかを察知する学習方法が必要である、ということですね。この結果は、常識的にも考えても納得の行く結果です。逆の見方をすれば、ライオンなどチームプレイをする動物達は、自分勝手に動いているのではなく、相手がどのように動くのかを観測し予測しながら動いているのだ、ということがこれらの学習過程からもわかります。さらに、MADDPGなどの単純なアルゴリズムで学習できることを考えると、チームプレイというのは複雑に見えますが案外単純なものなのかもしれません。
4. 実験2 (スイカ割り)
実験1ではMAPEに付属している実験環境を使いましたが、ここではMAPEを使って自分で新しい環境を作り実験した結果を見せます。新しい環境はずばり「スイカ割り」です。その名の通り、スイカが1つ、スイカ割るagent1体、指示するagent1体です。動けるのはスイカを割る人だけですが、目隠しされているためどこにスイカ(=ゴール)があるかわかりません。指示する人しかゴールがわからないので、指示する人の声(= action)を聞いて(= inputして)どこに向かって動くのかを決めます。スイカを割るagent(移動agent), 指示agentどちらも、移動agentがスイカに近づいたら報酬がもらえます。この実験では、指示agentのaction(指示する声)は5種類(便宜上、A, B, C, D, Eと呼ぶことにする)に設定しています。
この環境で報酬を得るためには、指示agnetはスイカに近づくような指示(= action)を学習し、移動agentは”指示”を聞いてそれが何を意味するのかを理解しスイカの方向に動く(= action)を学習する必要があります。つまり伝達の学習をする実験です。以下、実験の一部を紹介します。残りの実験結果については、こちらを参照してください。
4-1. suikawari2 (MADDPG)
まずデフォルトの場合です。以下は学習途中の結果です。
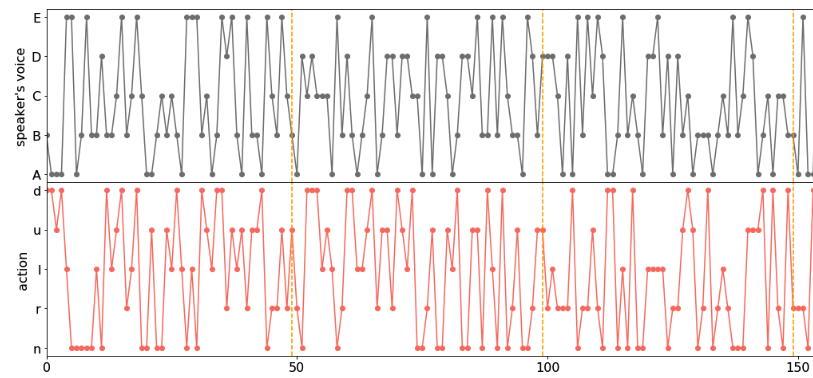
動画の緑色がスイカ、赤色が移動agent、灰色が指示agentです。動画の下にある図は、指示agentの行動(声;上図)と、移動agentの行動(動く方向;下図)のstepごとの値です。動画のagentの各step(~時間)ごとの行動に対応します。黄色い点線はepisodeの区切りです。下図の横軸はニュートラル(n)と上(u)、下(d)、右(r)、左(l)、への移動に対応します。移動agentはスイカにはたどり着けていないですね。実際、指示agentの行動(声)と移動agentの行動に対応はほとんどなく、ランダムに行動しているように見えます。
次に十分に学習した後の結果です。
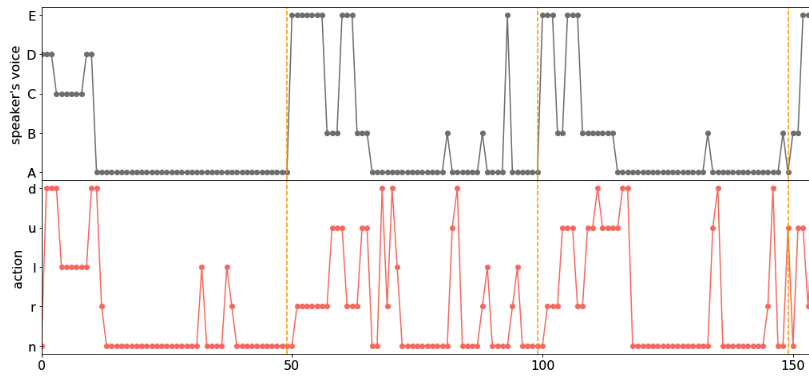
ちゃんと学習しているのがわかりますね。この実験では指示agentの声の種類と移動agentの動きの種類の数と合わせています。これは指示agentの”声”と移動agentの動く方向が1対1に対応することを期待して設定しました。
実際、図の解析結果から、
という意味に対応することがわかり、期待通りの学習ができたことがわかりました。つまり指示agentから移動agentへ、行動を促す意味を生成して伝達する学習ができていることがわかります。
4-2. suikawari2 (DDPG)
ではマルチエージェント用のアルゴリズムであるMADDPGではなく、(単体agentでよく使われる)DDPGを使ってみたらどうなるでしょうか?
結果は以下です。
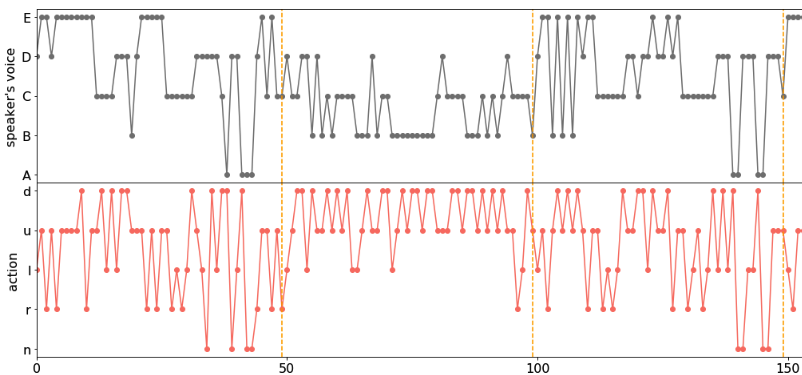
ある程度は学習できているものの、MADDPGに比べると適切に学習できていません。このsuikawari2の実験環境は非常に単純ですが、それでも伝達の学習は容易ではないことがわかります。なぜ難しいかと言うと、まず指示agentは声を伝え、移動agentはその伝えられた声を解釈して行動に変換する必要があります。報酬は、移動agentの行動の結果でしか得られませんので、適切に学習するには、agent間の伝達が適切に行われる必要があります。MADDPGはtraining中にagentの情報の全てを取得するので、容易に伝達を学習できます。したがって、この実験環境(意味の生成と伝達)とMADDPGの相性は良いことがわかります。
4-3. suikawari3
この実験環境ではデフォルトの環境(Section4-1)に”移動agent”をもう一体追加しました。以下、学習結果です。
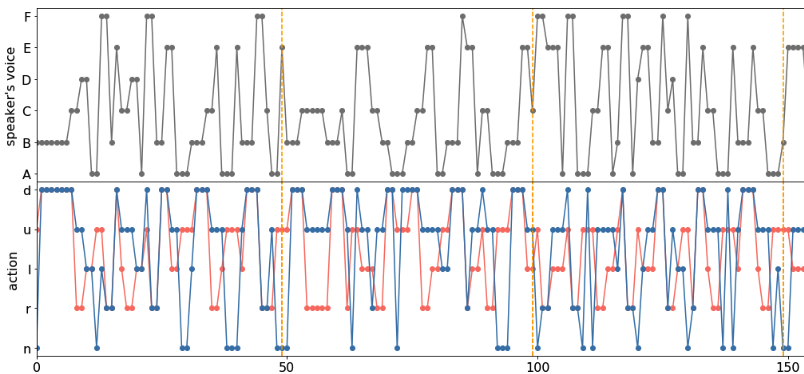
ちゃんと学習できていますね。人の場合を考えると「agent0は右に行って、agent1は左に行って」のように指示する必要があるので、伝えるべき情報量が2倍になり学習するのは少し難しいかなと思っていました。しかし結果を見ると、suikawari2とほぼ同じ精度で学習できています。どのように学習しているかというと、指示agentが”C”と発したとき、移動agent1にとっては「右に行け」を意味し、移動agent2にとっては「上に行け」を意味する、というように異なる解釈をagentにさせることで、うまく対応していることがわかります。もちろん、二つのagentを同時に操作する必要があるので、どの状況でどの文字を発するべきかを考えるのは(人間的には)大変な作業ですが、機械はこのあたりの複雑(退屈?)な計画は得意なので問題ないようです。この実験は、機械の方が人間よりも得意なタスクといえるでしょう。
4-4. suikawari5
この実験環境では、デフォルトの環境(Section4-1)から指示agentの行動(発する声)を変えました。デフォルトではどちらのagentも、指示agentが過去に発した声は覚えていません。ここでは3文字分を覚えているように設定しました。つまり指示agentが発した文字のログが、”AACBAB”だったとしたら、デフォルトは”B”しか覚えていませんが、suikawari5では”BAB”を覚えている、ということです。つまり文字から単語になったようなものですね。記憶ができた分、情報量が増えるので、発する文字の種類をデフォルトの5から2に減らします(つまりAとBだけ)。学習結果は以下です。
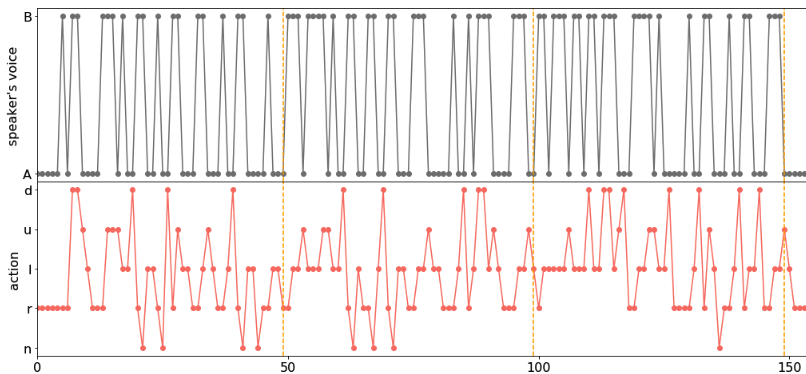
ちゃんと学習できていますね。このままだと見づらいのですが、簡単な解析をすると(詳細はこちら)、”BBB”なら「上に行け」、”BAA”や”AAA”なら「右に行け」という様に、(文字ではなく)単語と意味が対応していることがわかりました。
ちなみにこのモデルではLSTMなどは使わず単純なMLPを使っているので、移動agentのinputは、1文字だろうが単語だろうがただのvectorです。一方で、指示agentは自分の過去の発言と、移動agentの状況を考慮して次の文字を発するので、指示agentが「単語を作って意味を伝えている」という解釈ができる気がします。
5. まとめ&今後やりたいこと
OpenAIによって開発されたマルチエージェントの実験環境用のMAPEとMADDPGを用いて、実験を行いました。まずMAPEのライブラリに付属する実験環境でagentに学習を行わせ、問題なく学習できること確認して、結果の考察から、マルチエージェントという環境ならではの協力関係、チームプレイなどが学習されていることがわかりました。またMADDPGが、チームプレイを創出する上で(単体用のアルゴリズムより)優れていることも確認しました。さらにMAPEの環境を用いて、新しい実験環境suikawariを作り、実験を行いました。これは意味の伝達の実験でしたが、ここでもMADDPGによって適切な学習ができることがわかりました。今後は、MAPEの環境で他の実験環境を作り遊んでみようかと思います!
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD