2022.04.08
PEGASUS:AI文書要約ってどこまで要約できるの? ~Swallow had been waiting for this moment for a long time.~
こんにちは!4月になって新人を名乗れなくなりました、次世代システム研究室のY.T.です!今年度もよろしくお願いします!
はじめに
BERTが出てからというもの、自然言語処理の活躍はすごいですね。最近の機械翻訳はかなり実用に耐えるレベルですし、XLNetを使ったモデルでセンター試験の英語を解かせたら180点ぐらい取ったみたいな話も聞きました。
機械翻訳は自然言語処理でも早くから世に出ている成果なので、触れたことがある人も多いのではないでしょうか。
しかし、AIによる文書生成はどうでしょう。小説を書くAIみたいなのがSNSで流行ったりして、知っている人はいるかもしれませんが、こういったものが世の中に出てきたのは最近のことです。
なぜなら難しいから。AIによる文書生成はざっくり言うと、学習した大量のデータに基づいて尤もらしい言葉を並べていく、というようなものです。そのため、「私は、、。、、私は私は私、は。あの、、する」みたいな出てきやすいけど意味の弱い言葉をやたら出現させたりループさせたりして、文章として破綻した結果を出力してしまったりしていました。普通の文章みたいな感覚はAIにはないですからね。意味は一旦置いといて、文章として破綻していないレベルのものが出せるようになってきたのはかなり最近の話です。
今回はそんなAI文書生成の活用例の一つ、AI文書要約のお話です。AI文書要約が高いレベルでできれば、会議の内容を簡単にまとめたり、大量の資料を捌くのに役立てたりと業務での使い所が色々と思いつくので、会社人間的には期待の技術です。
最近出てきた文書要約モデルで遊んだら結構面白いことになったので、楽しんでみていただければと思います。(遊んでる時点でお察しですが、まだ実業務で積極的に使うのは厳しいという感触を得ました。人間の皆様方、共に地道にお仕事を頑張っていきましょう。)
抽出型要約と抽象型要約
文書要約には大きく分けて2通りのアプローチがあります。抽出型要約と抽象型要約です。
抽出型要約とは、文字通り文章中から重要な部分を抽出することで要約文とします。
機械学習のアルゴリズムとしてどいううことをしているのか具体的に説明すると、「文書中の各パートに対して重要か重要でないかという分類問題を解き、重要なものだけを並べて要約文を生成する」という説明になります。
生成される要約文は少し継ぎ接ぎ感がありますが、、元の文からそのまま抜き出しているので文章としては破綻しづらいです。ただし、要約文に抽出されなかったところの情報は全くないので、人目で見ると重要な文章がごっそり落ちているといったことは起こります。
また、固有の問題として位置バイアスというものがあります。文章を書く時には、例えば、本論序論結論の構成のような決まった書き方があるので、ニュースや論文など正しく情報を伝える目的で書かれた文章は、重要な部分が文章全体においてどの部分かが大体決まっています。そのため、学習データによっては、結果的に文章の最後を重要な部分として抜き出すだけのモデルのような、ほぼ位置だけで判断するモデルができることがあり、これを位置バイアスと言います。
抽象型要約は、入力の文章から全体の意味を捉えて尤もらしい要約文を生成します。そのため、抽出型要約のように分類問題として解くことはできません。
抽象型要約のアプローチを取るには、入力文にない単語の情報を持っておいて適切にそれらを出力に反映できる必要があります。それを可能にしたのがEncorder-Decorderモデルなどのニューラル言語モデルです。Encorder-Decorderモデルは、入力文を文意を表すベクトルに変換(エンコード)し、そのベクトルをもとに要約文を生成(デコード)します。そのため、入力文に無い情報も学習データにあれば、要約文に反映させることができます。一方で、入力にない言葉の情報を反映できる分、不要な情報を多く生成してしまったり、同じような内容を何度も繰り返し生成してしまったりといったことが起こります。抽出型要約に比べて抽象型要約は難易度が高く、生成された要約文の品質は不安定になりやすいです。
抽出型要約の例
抽出型要約は、分類問題として解けることもあり、抽象型要約よりも前からあるアプローチです。しかし、最新のモデルでは使われていない古いアプローチではありません。
ポイントは抽出型要約が分類問題として解けることにあります。
自然言語処理の分野では名前を見ない日はない、様々なSOTAを更新したBERTというモデルがあるのですが、このBERTの優れている点に、事前学習されたモデルのFine-tuningを行うことで様々な分類タスクに適用できるというものがあります。つまり、重要かそうでないかの二値分類とも言える抽出型要約にも、事前に学習されたBERTをFine-tuningを行えば適用できるということです。
このようなBERTベースの抽出型要約には、BERTSumなどがあります。
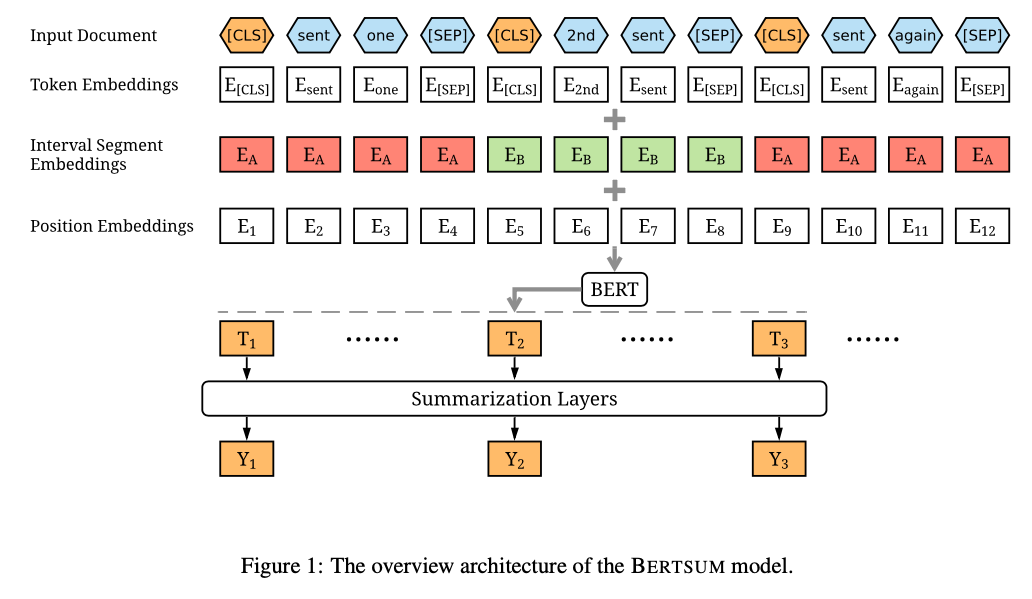
抽象型要約の例
抽象型要約は、抽出型要約よりも文章全体をうまくまとめた自然な文章を生成しますが、文章を生成している分、ノイズが乗りやすく不正確な要約が出力される場合も多いです。そのため、元の文からそのまま抜き出す分、ある程度の正確性が担保される抽出型要約よりは、品質が悪い文が生成されることが多かったです。
しかし、近年では表現力に優れる大規模なニューラル言語モデルをトレーニングすることで、抽象型要約の品質を改善しようとした手法が多く提案され、人目で見ても自然な文を生成できるモデルが増えています。
例えば、BARTやPEGASUSといったEncorder-DecorderモデルのBERTベースの手法が代表的です。
PEGASUS
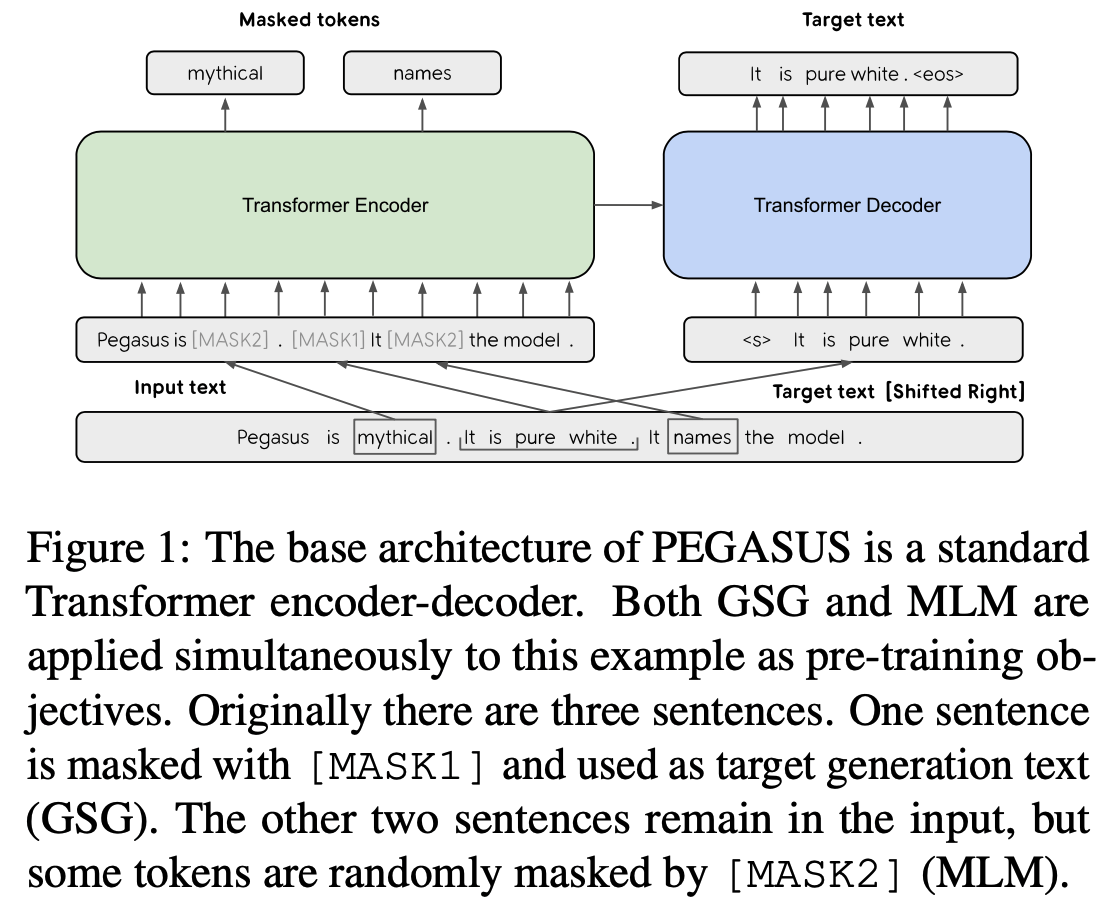
PEGASUS(Pre-tranning with Extracted Gap-sentenses for Abstractive Summarization)はGoogleから発表された抽出型要約のモデルです。基本的にはBERTをベースにしたEncorder-Decorderモデルで要約文を生成する手法です。
PEGASUSのモデルのポイントは、学習の際のGap Sentence Generation(GSG)というタスクです。BERTではMasked Langage Model(MLM)と言って、入力文章中のマスクされた単語を予測することで単語の潜在表現を学習しますが、PEGASUSは文書要約というタスクにより適応するため、文章単位でマスクし、マスクされた文章を予測することで、文書のもつ特徴を抽出します。また、Fine-tuningに必要なデータ数を抑える工夫もされていて、比較的少ないデータで他の手法と遜色ない精度の要約が可能になります。
PEGASUSで遊ぼうのコーナー!
真面目な話が続いて疲れましたね!
それでは簡単にですがPEGASUSを動かして文書を要約してみて遊んでみようと思います!
PEGASUSの事前学習されたモデルはHuggingfaceで公開されており、簡単に利用することができます。モデルサイズや学習に用いたデータセットでいくつかのパターンのモデルが公開されていますが、とりあえず最もオーソドックスなものを使っていきましょう。
今回はgoogle/pegasus-xsumというモデルを使います。このモデルはC4という巨大なニュース記事の要約データセットで学習されたものです。
使い方はこんな感じです。

実行すると要約文が出力されます。(実はここまでに2GBぐらいのファイルが落ちてくるし、それなりに時間もかかりますが割愛)

動かす前の注意点としては、SentencePieceを入れていないとtokenizerのところでエラーが出ます。インストールを忘れがちなので確認しましょう。
インストールはpipですぐできます。私は踏まなかったのですが、transforemersのバージョンの問題でうまく動かないこともあるみたいですよ。
こちらのissueを参考にどうぞ https://github.com/huggingface/transformers/issues/8864
BBCのNewsを適当に要約してみます。いい感じに一文でまとめていますね。

このままではおもしろくないので、私の大好きな名作、”HAPPY_PRINCE”(幸福な王子様)を要約していこうと思います!本当に作品が好きな人がやることではない気もしますが、愛は人それぞれです。
GO!

….
 ….
….

はい、知ってた。
ここまでで触れてなかったんですけど、入力の文章の長さには制限があります。PEGASUSの学習ネットワークの構造はTransformerですが、Transformerはその計算過程のScaled Dot-Product Attentionと呼ばれている部分で入力長をnとしてO(n^2)のメモリを消費します。そのため、入力長に対して必要なメモリ数が急激に増大してしまい、入力の長さに制限がかかります。具体的には512トークンぐらいです。そこを解決しようとしている手法もあるのですが、それはまたの機会に…。
512トークンぐらいが限界だとすれば、小説全部入れたら爆発しますね。
仕方ないので、最後の名シーンを要約してみましょう。
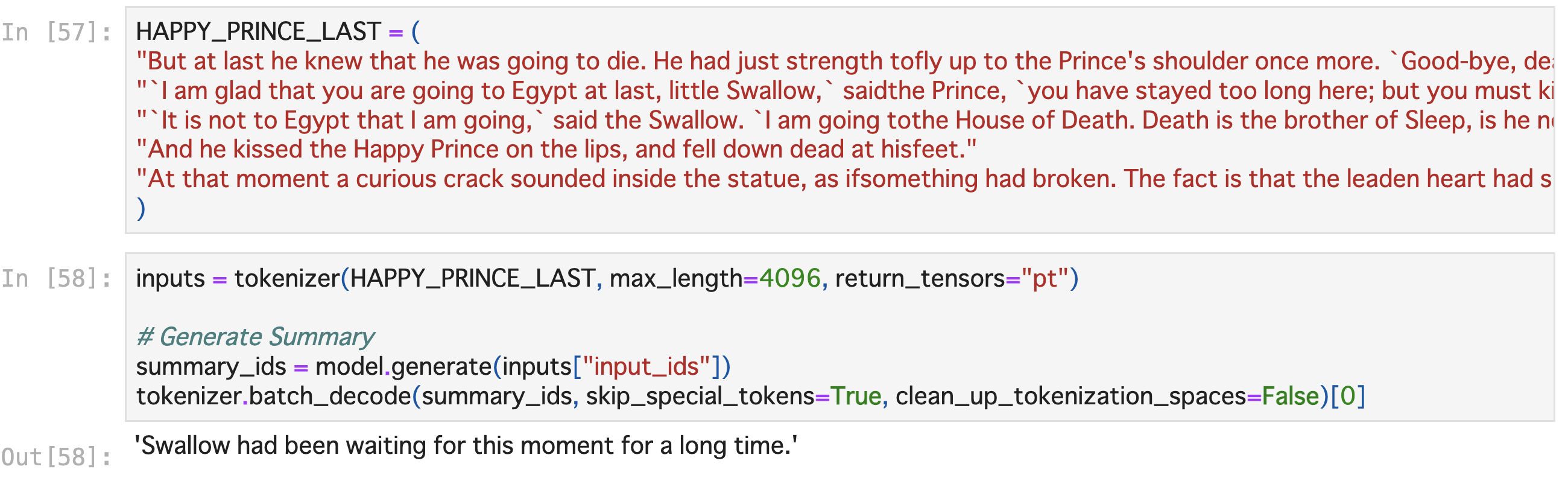
‘Swallow had been waiting for this moment for a long time.’ 「ツバメはこの瞬間をずっと待ち続けていました。」という結果になりました。抽象的な文なので、待っていた’this moment’が好敵手(友)との果たし合いのその時なのか、運命の人と出会う時なのかわかりませんが、文章としては自然ですね。元の文を考慮すると「健気なツバメちゃんは、王子様と結ばれるその時をずっと待ち続けていました。」というような意味合いでしょうか?可愛らしいですね。
しかし、要約元のシーンでは、ボロボロになった王子様と力尽きる最後まで王子様と共にいることを選んだ燕が冬の寒い空の下で二人息を引き取るシーンです。たとえ死ぬとしても、王子様と一緒にいられるようになるその時を燕は待っていた、とAIは言いたいのでしょうか?
シンプルながら意味深な要約結果をお出しされました。
もっと行きましょう。冒頭部分です。
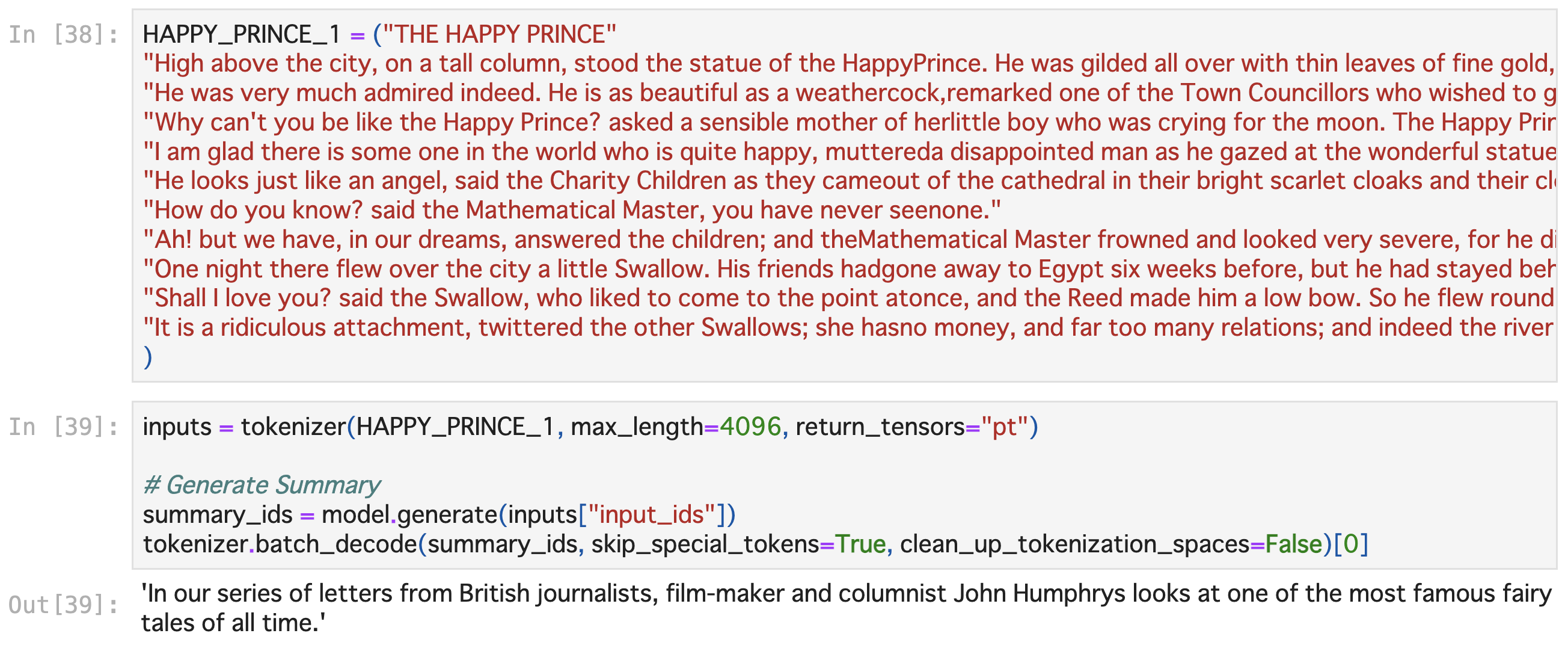
John Humphrysさんって誰〜〜!?
と思って調べたら実在のジャーナリストさんでした。ニュースデータセットが出ちゃってますね。意味は通るし書いてあることはあながち間違ってはいないんですが。。。
出力を日本語に訳すと「英国のジャーナリスト、映画監督、コラムニストから寄せられた記事の連載で、ジョン・ハンフリーが、史上最も有名なお伽噺のひとつとして取り上げています。」という意味でになります。部分で見ると、タイトルと冒頭文を、史上最も有名なお伽噺」として解釈できており、モデルとしてなかなかに強力で驚きです。入力文は幸福な王子様の冒頭部分であり、入力と出力の文章を比較すると登場する単語が全く異なるので、単なる入力文からの抽出になっていないことがわかります。
しかし、元の文章は物語の一部であり、期待される要約はその部分のあらすじのようなものになりますが、生成された要約文では、全く無関係の人物が出てきてしまっています。
このPEGASUSのPre-trainedモデルはニュース全文を入力として、お手本の要約に近い文章を生成し続けて、お手本に出力文を近づけていくという学習をしているので、言ってみればニュースのような文章しか書けないようなモデルになっているのかもしれません。そのため、有名な物語の一部を入力とした時に、それを著名なジャーナリストがニュースの話をする中で挙げたという解釈になったようです。
文章としては自然な要約文で、意味は通るが要約文としては的が外れているという、なんとも抽出型要約らしい結果が出てきました。
僕の実行前の予想では、「ニュースのような文体で物語の内容が出てくる」あるいは「意味が破綻した文章が出てくる」のどちらかだったのですが、結果は予想の斜め上の結果で、やはり学習データの影響は大きかったという結果でした。実業務での利用としてメールの要約を考えると、メールを読んで、勝手にメールの中身と関係ないものを持ってきてそれっぽい文章を作られる、ということになるので少し嫌ですね。
まあ、Pre-trainをそのまま使っているのでFine-tuningである程度改善するとは思いますが、物語の要約の場合はどういうデータを使いましょうかね。あらすじと本文とか?
参考
Liu, Yang. “Fine-tune BERT for extractive summarization.” arXiv preprint arXiv:1903.10318 (2019). ( https://arxiv.org/pdf/1903.10318.pdf )
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186,
Zhang, Jingqing, et al. “Pegasus: Pre-training with extracted gap-sentences for abstractive summarization.” International Conference on Machine Learning. PMLR, 2020.
( https://arxiv.org/pdf/1912.08777.pdf )
Google AI blog ( https://ai.googleblog.com/2020/06/pegasus-state-of-art-model-for.html )
最後に
感想です。今回のブログを書くにあたって、日本語のデータで学習されたPre-trainedのモデルを色々探していたのですが、なかなかうまく見つからないですね!汎用モデルは幾つかあるのですが、要約などいくつかのタスクに優れたモデルだとかなり探すのが難しいです。
他言語モデルのFine-tuningで何かしようかと思いましたが、学習に使うデータセットもなかなか探すのが難しく…。次回以降にご期待ください!読んでいただきありがとうございました。
次世代システム研究室では、 Webアプリケーション開発を行うアーキテクトやデータサイエンティストを募集しています。募集職種一覧からご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD