2018.01.17
深層強化学習のself-playで遊んでみた!
次世代システム研究室のJK(男)です。久々の更新となりましたが、よろしくお願いします。
今回は最近(2017/10)に出た論文をベースに、深層強化学習によるself-playの勉強をした成果を紹介します。深層強化学習は以前のブログでもフォーカスした事がありましたが、そのときは金融系の課題に応用できるかを試しました。今回は応用ではなく、self-playという手法そのものにフォーカスします。
強化学習は、正解のない世界でベターな方法を模索する手法です。これは私達の普段の行動の選択に似ていますね。こういった手法がより実践的に使われるようになれば、私達の生活もより豊かになるかもしれません、、、まー、これは建前で、実際は人間っぽい動きを学習する機械(Agent)が作れたら面白そー、というのが勉強する最大のモチベーションだったりします(笑)。深層強化学習の中で使われるself-playという手法は、AlphaGoで一躍有名になった手法ですね(次のSectionで説明します)。単純な環境から、複雑な行動が創発されるところが面白いと思い、今回取り上げました。
Section 1は深層強化学習のおさらいですので、既に知っている方はSection 2から見てください。またSection 3の実験結果のアニメーションがリンク先にあります(実験2: exp2_results.ipynb)。面白いと思うのでぜひ見てください。
1. 深層強化学習 x self-play
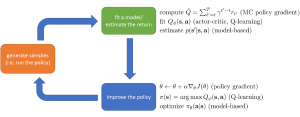
深層強化学習とは、深層学習の技術を用いた強化学習のことです。もう少し詳しい説明は、以前のブログを見てください。とりあえず、このブログを読む上で覚えていて欲しいのは、Agentという学習者(機械)がいて、変化する環境に対して、行動を起こし、その結果に対して報酬を得る、という一連の流れです。強化学習では、この一連の流れがループして物事(ゲームなど)が進むと仮定します。たとえば、囲碁の場合がわかりやすいですね(図1)。このサイクルを回しながら、最終的に得られる報酬が大きく(囲碁の場合は勝利する事)なるように、Agentのモデルを学習させるのが強化学習です。ここでいうモデルとは、囲碁でいえば「盤上の状態を見て次の手をどこに打つか」を決めるものです。
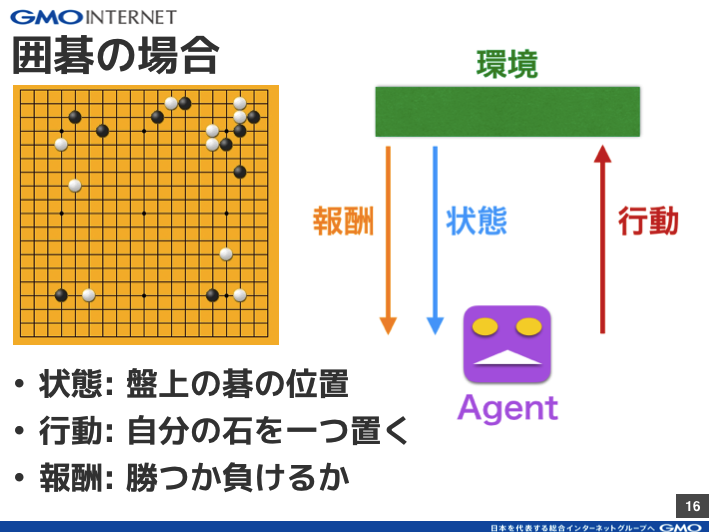
図1: 強化学習を囲碁に応用した場合
Self-playとは、人間(世界チャンピオン)を破ったAlphaGoで一躍有名になった手法です。ちなみにAlphaGoではself-playの果たす役割はそこまで大きくなかったのですが、最近発表されたAlphaGo Zeroでは重要な役割を果たしています。実力は、人間 < AlphaGo Zero << AlphaGo Zero でありその差はますます広まるでしょう。イヤになりますね。
Self-playを一言でいうと、機械(Agent)同士で対戦させて切磋琢磨させることでAgentを強くする手法です。2 agentsの場合を考えると図2のようになります。つまり学習する際、片方のAgent(= Agent0)に注目して、残りのAgent(= Agent1)は環境の一部として見ます(図2の左側)。すると、図1の1 agentの場合と同じことになるので、強化学習が普通にできます。ある程度学習したら、次に逆側のAgent1を学習させます。今度はAgent0を環境とみなして学習させず、Agent1のみ学習させます(図2の右側)。こうすることで、Agent0, 1ともに少しずつ強くなり、強くなった相手に勝とうと両Agentが互いに学習し合うのでどんどん強くなれる、ということです。まさに切磋琢磨ですね
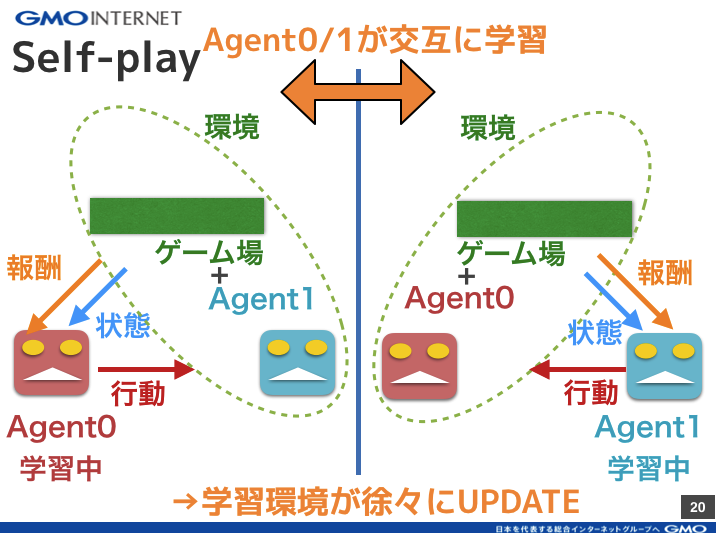
図2: Self-playの学習プロセスの概念図
ちなみに図2ではわかりやすいように、2つのAgentごとにモデルを分けましたが、囲碁のように対称なゲームならモデルは一つで十分です。モデルを1つにしても2つにしても本質的には同じですが、学習時間は1つの方が少なくすみますね。図2は非対称なゲームの学習にも適用できる、より汎用的な概念図です。
Self-playの手法の良い所は、人の知識なしで機械だけで学習できることです。そうすると、
(a) 人が強化学習の環境の設計(報酬設計など)に頭を悩ませなくて良い。
(b) 人が思いつかないような行動を学習する可能性がある。
(c) 単純な環境やルールから、複雑な行動を学習する可能性がある。
のような嬉しいことがあります。(b)に関してはAlphaGo Zeroなどでは実際にそうなっている事が確認されています。AlphaGoでは人の棋譜をデータに学習する過程がありましたが、Zeroではその過程は無くなり機械同士で勝負したデータのみで学習しています。これがZeroで強くなった理由の一つと言われています。(c)に関しては、(a)と(b)の組み合わせとも言えます。強化学習の難しい点の一つは、環境や報酬を上手く設計してあげないと適切な学習ができない所です。ところがself-playを使えば、(学習途中の)敵Agentが環境として振る舞ってくれるため、学習するごとに(敵Agentのモデルが異なるため)異なる環境でAgentを学習させる事ができます。このため、(設計をあまり凝らずに)単純な環境やルールを設定しても(相手Agentが複雑な行動を学習してくれれば)環境が徐々に複雑になるため、Agentが複雑な行動を学習できる可能性があります。
2. 実験セットアップ
今回の実験では、この論文の再現実験を行います。論文では4種類のゲームを扱っていますが、ここでは1種類のゲーム(run-to-goal-ants)を扱います。図3にゲームの概観を示します。非常に簡単なゲームで、Agentが2体いて、それぞれ自陣からスタートして、相手より早く走って相手の陣地(図3の赤線)にゴールすれば勝ちです。2体のAgentは何も学習していない(ランダムな動きしかしない)状態から勝負を始めて、self-playによって相手に勝てるよう交互に学習していきます。ゲーム環境は論文作者が公開しているコードを使いました。論文にならい、強化学習のアルゴリズムとしてPPOを使っています。PPOのコードはOpenAIが公開しているコード(TensorFlow)をベースに、2 agentsのself-play用にコードを修正して使いました。

図3: ゲーム(run-to-goal-ants)の概観
図3の通り、AgentはAnt型(足は4本しかないですが、RL界隈ではこう呼ばれます)です。MuJoCoという物理エンジンを使うことで、Agentと環境の相互作用が計算され実際の物理空間のようにAgentが振る舞います。強化学習の学習サイクルを回すのに必要な情報(行動、状態、報酬)は図4のように定義しています。Agentは生物のように振る舞うものとして設計されています。つまり、状態については、Agentの観測情報であり、生物が知覚できるだろうと思われる情報(見る、触る)のみを取得して、行動も関節部分が動くようになっています。見たり触ったりした情報(= 状態)から、次にとるべき行動を決めて関節を動かす。これは生物の動きと同じですね。

図4: ゲームで使用される状態、行動、報酬
3. 実験結果 & 考察
マシンにGMOアプリクラウドのtype XL (12 vCPU, 2.66 GHz)を用いて、Section 2のセットアップでトレーニングをしました。論文の通りのパラメータだとトレーニングが時間がかかりすぎたので、トレーニング量を論文の~1/8に減らしました。これで1日弱でトレーニングは完了して、得られた学習曲線が図5です。横軸:学習サイクル(=iteration)の回数、縦軸:報酬です。ちゃんと学習していれば、学習回数が増えるほど報酬が増えると期待されますが、実際その通りになります。iter ~300で収束(報酬が一定になる)しているのがわかります。またAgent0と1の学習曲線がほぼ一致することもわかります。このゲームは対称性(Agent0とAgent1で同条件)があるので、妥当な結果と言えます。これらの事から、この実験においてself-playを使ってAgent0と1は適切に学習できていると期待できます。
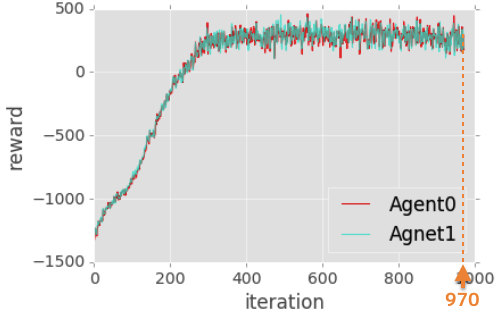
図5: 学習曲線
まず学習前のゲームのアニメーションが以下です。学習前なので、4本の足をランダムに動かしており、ゴールどころかまともに歩くのすらままならない事がわかると思います。この状態から、強化学習でゲームに勝てるように行動(=足を動かす)することを学んでいきます。
学習前のAgent
ではトレーニングをするとどうなるか?下のアニメーションは、十分に学習したモデル同士の戦いです。アニメーションはAgent0, 1ともに最新モデル(iter=970)です。ちゃんとゴールに行くように学習しているのがわかります。両者、一歩も譲らずといった感じですね。
最新モデル(iter=970)を搭載したAgent同士の戦い
最新モデルのアニメーションから、Agentが学習した戦略が、(基本的には)相手に体当たりをして相手が怯んだらその隙にゴールに走り込む、というものだと見てとれます。ただし、相手を倒す事に固執したような行動も見られます(ゴールとは反対方向なのに、相手の方に向かって行く、など)。これはただ単に「できるだけ早くゴールに走る」のではなく、「相手を倒してからゴールに向かう」ことを学んだように見えます。さて、このブログのハイライトです。今回の設計では「相手を倒す」事に報酬は与えていない事に注意してください。報酬は「相手より早くゴールすること」のみに与えています。Self-playで相手に勝とうと学習した結果、「相手より早くゴールする」という単純なゲームにおいて、「相手を倒す」という一見遠回りに思える行動(~ 複雑?な行動)をAgentは学習しました。実際、下記のアニメーションは学習途中(iter=300)のモデル同士の戦いですが、最新のiter=970のモデルと比べると、ゴールを目指すこと(報酬そのもの)に重きを置いていた戦略に見えます。このことから学習が進むほど、相手を倒す戦略を学習していったと推測することができます(めっちゃ定量的です。”お話”程度に聞いてください)。
学習途中のモデル(iter=300)を搭載したAgent同士の戦い
最後におまけです。片方のAgent (Agent0) のモデルを固定して、もう片方 (Agent1) のモデルを学習途中のモデルにして、(複数の異なる学習断崖のモデルに対して)勝負をしたときのAgent0の勝率を求めました (図6)。モデル同士が互角なら勝率が50%なので、最新モデルが最強であることがわかります。いい感じで学習しているのが確認できます。
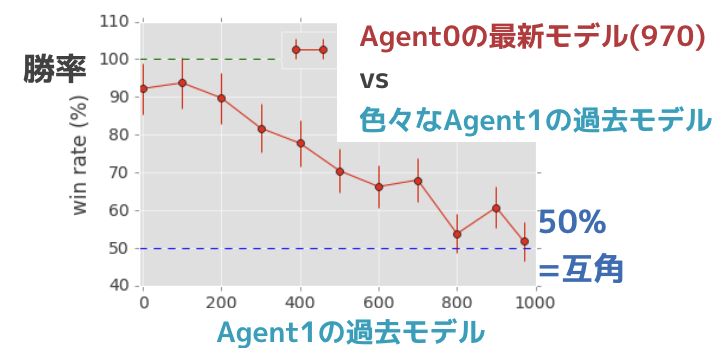
図6: Agetn0 (最新モデル) vs Agent1 (過去モデル)の勝率
実際、Agent0(赤)に最新モデル(iter=970)を搭載して、Agent1に学習途中のモデル(iter=300)を搭載して勝負した場合のアニメーションが下です。明らかにAgent0の方が強いですね(図6より、この組み合わせの場合、Agnet0の勝率は~80%)。まさにAgent1を蹴散らす、という言葉が適当な感じです。学習(iteration)が進むにつれて強くなるのが、このアニメーションからもわかりますね。
Agent0(iter=970) vs Agent1(iter=300)
4. まとめ & 今後やりたいこと
Bansal+17の実験(run-to-goal-ants)の再現を試み、ほぼ成功しました。論文に記載されているgithubには学習済みのモデルがあるだけなので、再現実験をすることで、学習途中の結果などは初めて得ることができました。これを学習の進んだモデルと比較することで、相手より早くゴールを目指すという単純なゲームにも関わらず「相手を先に倒してからゴールする」という行動を学習しているのではないか、と推測する事ができました。これはself-playにより、単純な環境から複雑な行動を学習したと解釈できる(気がします)。今後のやりたいことは、参考にした論文にある他のゲームを試してみることや、ゲーム設定を変更して新しいゲームを作ることなどです。例えば敵対するだけでなく、協力するAgentは作れたら面白いんじゃないかなぁ、とか思っています。あとは学習に時間がかかりすぎるので、もっと効率的な学習方法の模索をしてみるのも面白そうだなとも思ってます。色々やりたいことがあって困りますね。どうしよう、悩むなぁ。。。
ともあれ、今回のブログはここまでです。最後までお付き合いいただき、ありがとうございました!
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD