2023.12.25
データサイエンティストの代わりに、アンケート君がうまく分析してくれるか(GPTsやAssistants API編)
こんにちは。 AI研究開発室のK.S.(女性、外国人)です。
今回はOpenAIのGPTsやAssistants APIを使って、アンケート集計やアンケートの自由回答などの顧客の声(Voice of Customer、 VOC)の分析を試したいと思います。
なぜ、これを試してみたいのかと言うと、、、、個人的に三つの主な理由があります。
1つ目、データサイエンティストをやっていて、「アンケートが溜まっていますよ」とたまに聞かれます。データサイエンティスト以外の方は、自分たちが提供したアンケートを最低限で分析しているようですが、手間がかかるし、特に自由回答の部分は人によって「全部のコメントを頑張って読んでいますよ」のような話を聞きます。「えー!?全部のコメントを読むの?」と外国人の私には無理です! 特に手書きはさらに無理です。大量の日本語を読むのが辛くて、どうにかしたい気持ちがあります。しかし、猫の手でも借りたいくらいです。そこで、最低限の分析がうまく自動化できればよいと思っています。
2つ目、最近、「データサイエンティストが行う仕事の大部分がAIに代替されてしまうのではないか」という話はよく聞いております。特に、ChatGPTの新機能Code Interpreterが登場してから、誰でもお手軽にデータ分析できるようになってきました。そこで、どうせ私の仕事を奪いたいなら、「AIちゃん、君は丁寧にきちんと分析してくれよ」って期待したいのです。
3つ目、単純に最新の技術検証としてGPTsやAssistants APIと遊ぶのが楽しくて仕方がありません。
上記の理由で、私の代わりに、アンケート君がどこまでうまく分析してくれるか、適当なデータサイエンティストの自分が許せる範囲の品質で分析をしてくれるかを試したいと思います。
やりたいことは顧客のアンケートを分析することです。まず、簡単にOpenAIが開発したChatGPTを使って分析してみます。次に、OpenAIが提供しているGPTsやAssistants APIを試してみます。ちなみに、今回使っているChatGPTは有料版のChatGPT Plusです。
目次
1. ChatGPTでアンケートを作成してみた
当たり前ですが、データ分析するためには、データが必要です。しかし、大体のアンケートデータには個人情報があり、極秘データ扱いの場合がほとんどです。今回は技術検証目的で、簡単にMockデータ(サンプルデータ)を作ろうと思います。そこで、人気がありすぎて、説明する必要がないChatGPTを使ってアンケートデータを作成します。インターネットでググると、いくつかのPrompt(AIとの対話のため、ユーザが入力する指示や質問)の例が出てくるかと思いますので、適宜、真似て書きます。
ChatGPT web browserを使って、下記のようなやりとりでデータが作成できました。
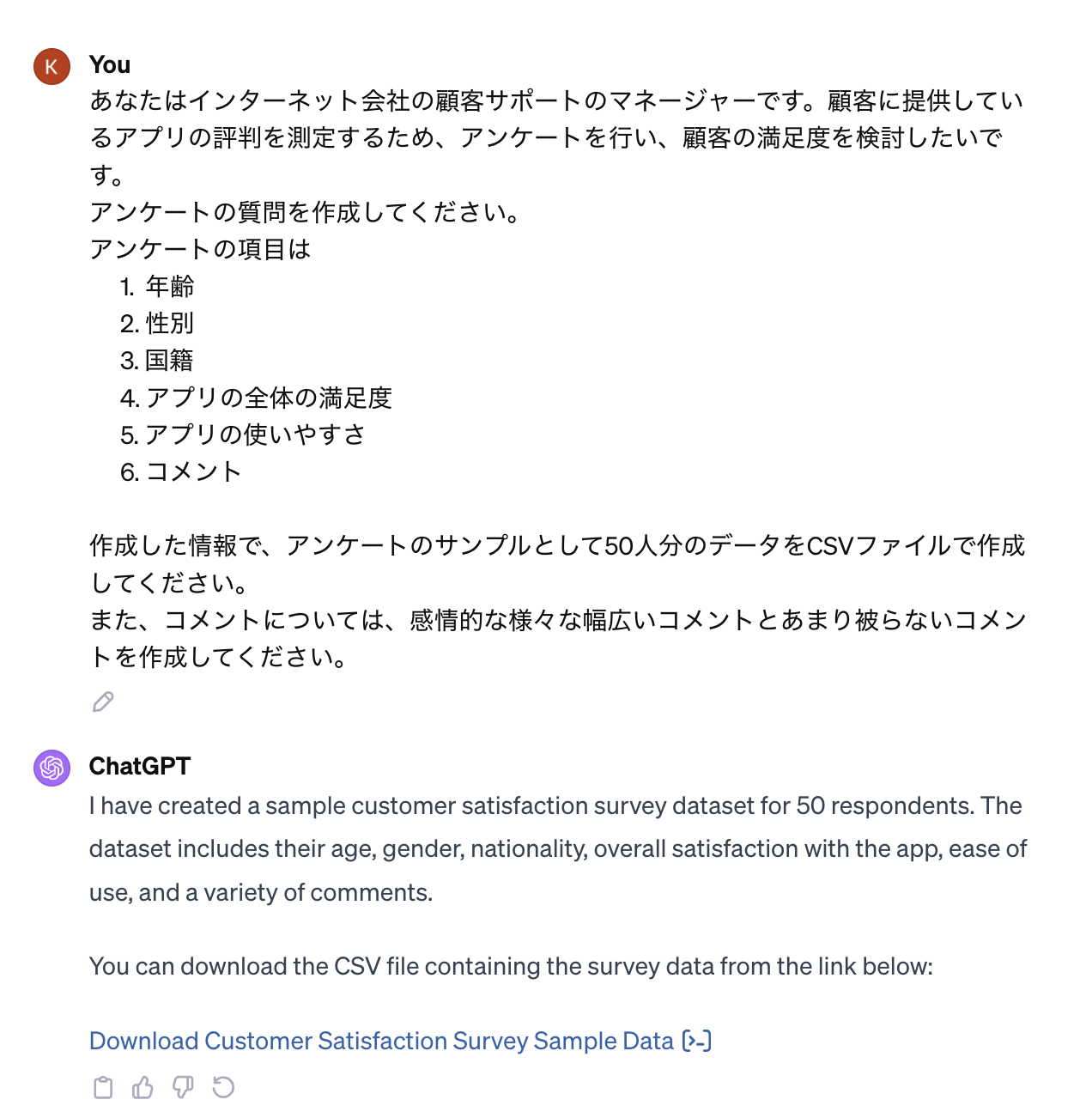
ChatGPTがどうやってアンケートの結果を作ったのかはコードを確認できるので、少し見ていきましょう。
コード: アンケート作成
import pandas as pd
import random
import faker
# Initialize Faker for generating sample data
fake = faker.Faker()
# Define the number of samples
num_samples = 50
# Function to generate random age
def generate_age():
return random.randint(18, 70)
# Function to generate random gender
def generate_gender():
return random.choice(['Male', 'Female', 'Other'])
# Function to generate random nationality
def generate_nationality():
return fake.country()
# Function to generate random overall satisfaction rating
def generate_overall_satisfaction():
return random.randint(1, 5)
# Function to generate random ease of use rating
def generate_ease_of_use():
return random.randint(1, 5)
# Function to generate random comments
def generate_comments():
comment_options = [
"非常に使いやすい",
"機能が豊富で満足",
"改善の余地あり",
"時々バグが発生する",
"インターフェイスが直感的ではない",
"カスタマーサポートが素晴らしい",
"より多くの機能を望む",
"更新による改善を期待",
"価格に見合った価値がある",
"アプリの速度が遅い",
"セキュリティ面で信頼できる",
"使い方が難しい",
"初心者にも使いやすい",
"デザインが素晴らしい",
"もっとカスタマイズできれば良い",
"他のアプリより優れている",
"頻繁な更新がうっとうしい",
"もう少し安定性がほしい",
"ユーザーインターフェースが改善された",
"サポートがもっと迅速に対応してほしい"
]
return random.choice(comment_options)
# Create a DataFrame
data = {
"Age": [generate_age() for _ in range(num_samples)],
"Gender": [generate_gender() for _ in range(num_samples)],
"Nationality": [generate_nationality() for _ in range(num_samples)],
"Overall Satisfaction": [generate_overall_satisfaction() for _ in range(num_samples)],
"Ease of Use": [generate_ease_of_use() for _ in range(num_samples)],
"Comments": [generate_comments() for _ in range(num_samples)]
}
df = pd.DataFrame(data)
# Saving the DataFrame to a CSV file
csv_file_path = "/mnt/data/Customer_Satisfaction_Survey_Sample_Data.csv"
df.to_csv(csv_file_path, index=False)
csv_file_path
ChatGPTが作成してくれたコードを見ると、ランダム的に答えを作ってくれたようですね。面白いのは国(country)を作成するときに、faker libraryを作って作成してくれました。本当の情報を期待していないので、このままで使ってしまいます。
また、少し作成したファイルを見せましょう。ちなみに、「日本語」を書いておかないとたまに英語で返してきますので、英語を読みたくない方は忘れず「日本語」って指示してくださいね。
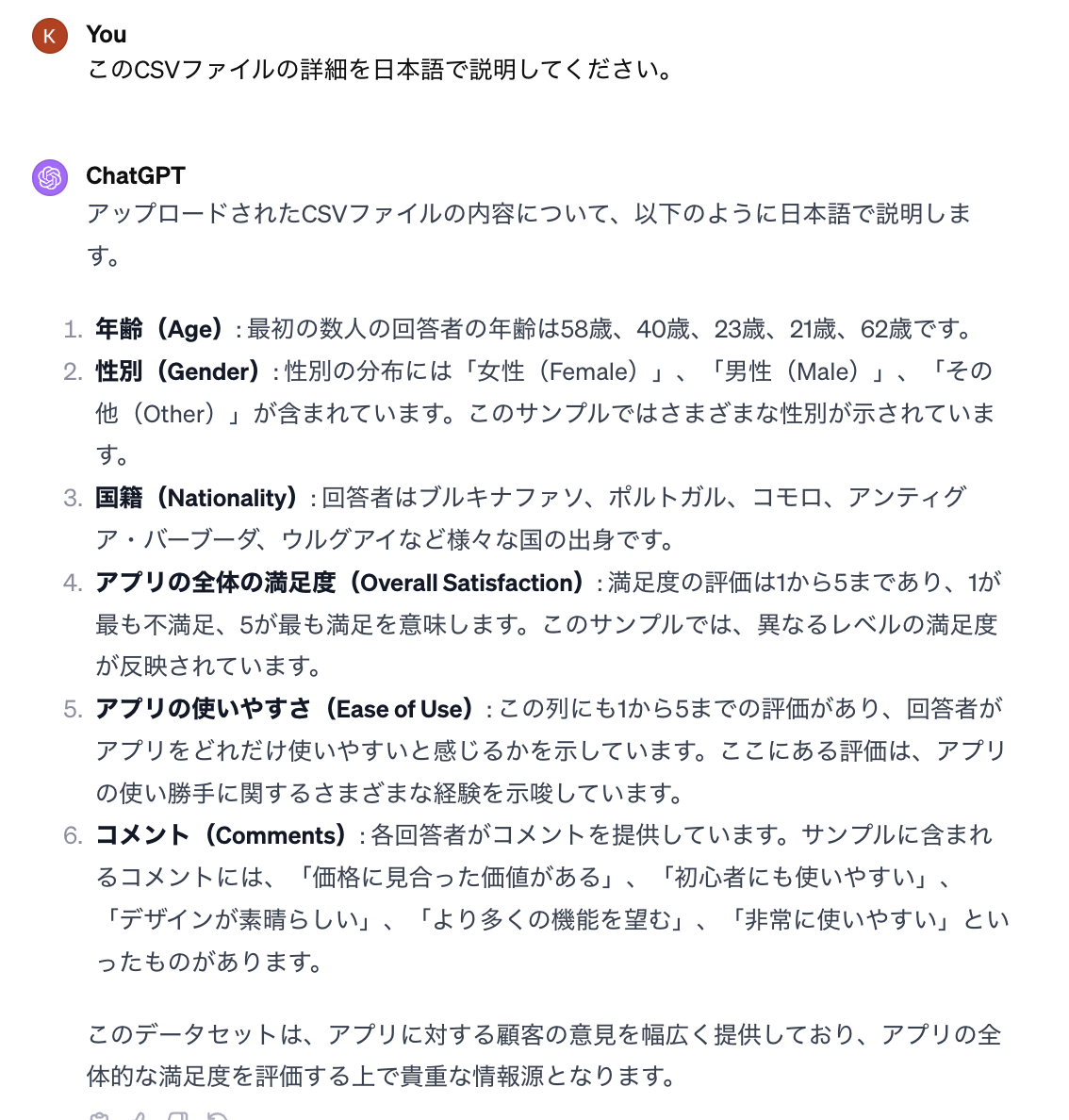
おっと、fakerで作られたから、コモロやアンティグア・バーブーダのような聞いたことがない国が出てきたなあと思いました。しかし、Wikipediaで調べてみたら、コモロはコモロ連合というインド洋に浮かぶ島で人口は2020年には85万人くらいだそうです。また、アンティグア・バーブーダはカリブ海東部の小アンティル諸島にある島国だそうです。ちなみに、人口は10万人があるかないかくらいのようです。詳細は深掘りしていませんが、大体のサンプルデータができたので、本題の解析を試してみましょう。
2. ChatGPTでアンケートを分析してみた
やりたいことは、①複数選択肢質問の探索的データ分析(EDA)、②自由記述回答のWord Cloud、③自由記述回答の感情分析です。
2.1. 複数選択肢質問の探索的データ分析(EDA)
まず、データサイエンティストが基本的に最初によくやることからやってもらいましょう。全体の複数選択肢質問のデータを利用し、ChatGPTにEDAをやってもらったらどうなるかをみていきましょう。

ChatGPTが使ったコードはこちらです。
コード: EDA
# Re-loading the CSV file for Exploratory Data Analysis (EDA)
uploaded_csv_path = '/mnt/data/Customer_Satisfaction_Survey_Sample_Data.csv'
df = pd.read_csv(uploaded_csv_path)
# Performing basic EDA
# 1. General information about the dataset
general_info = df.info()
# 2. Statistical summary of numerical columns
stat_summary = df.describe()
# 3. Checking for missing values
missing_values = df.isnull().sum()
# 4. Frequency distribution of categorical data: Gender and Nationality
gender_distribution = df['Gender'].value_counts()
nationality_distribution = df['Nationality'].value_counts()
# 5. Average satisfaction and ease of use ratings
average_satisfaction = df['Overall Satisfaction'].mean()
average_ease_of_use = df['Ease of Use'].mean()
# Compile the EDA results
eda_results = {
"General Information": general_info,
"Statistical Summary": stat_summary,
"Missing Values": missing_values,
"Gender Distribution": gender_distribution,
"Nationality Distribution": nationality_distribution,
"Average Overall Satisfaction": average_satisfaction,
"Average Ease of Use": average_ease_of_use
}
eda_results
大体、一般的にやられているデータ欠損チェック、データ件数、pandas describeを行なってくれたので、そのまま進みます。
次に、アンケート集計の可視化をChatGPTにやってもらったらどうなるかをみていきましょう。
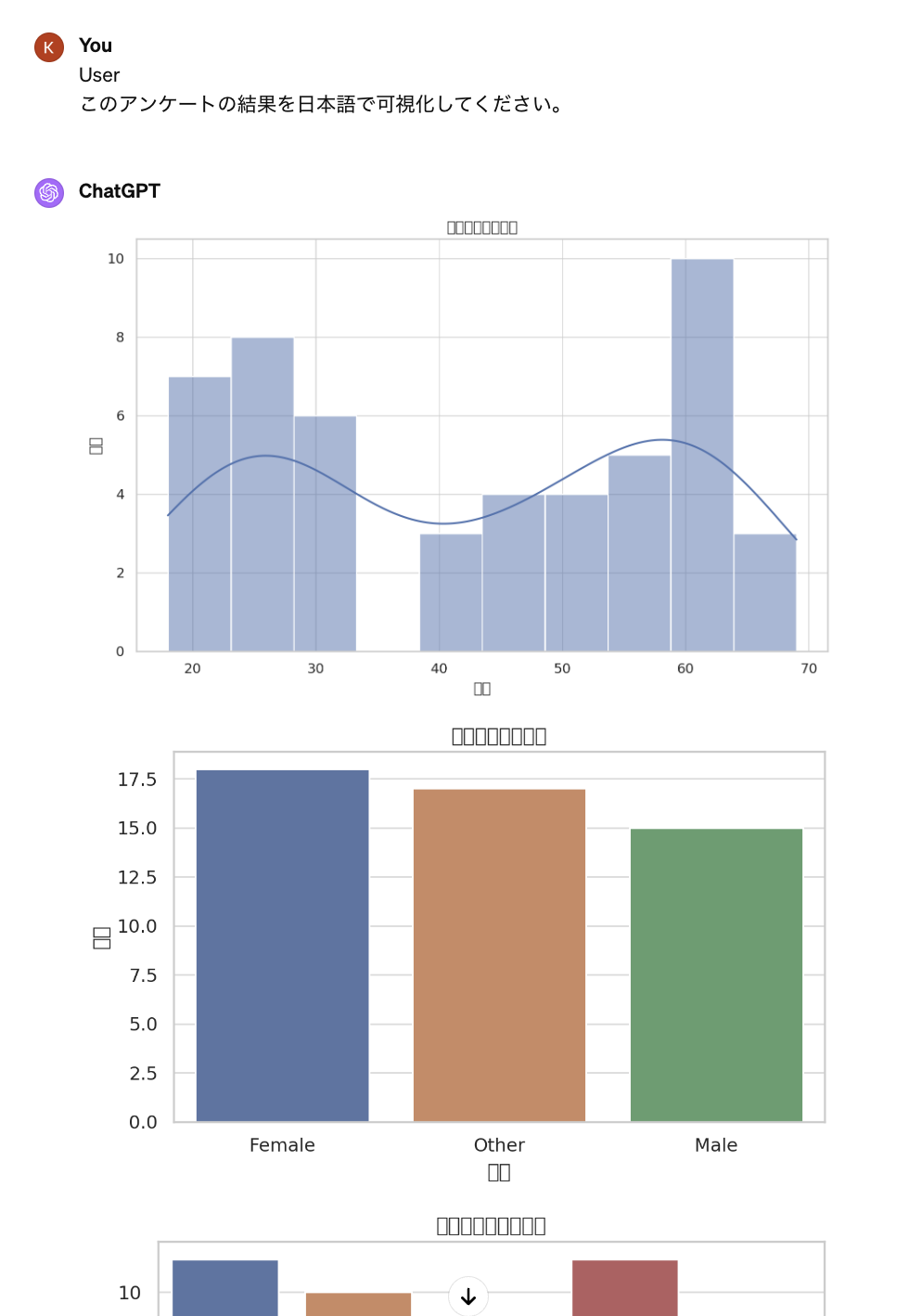
「なんと、読めないぞ! ChatGPTくん、私と同じで日本語を読めないんかい〜」。では、優しく少し助けてあげましょう。

「えー、日本語のフォントがインストールできないようですね」。では、データサイエンティストによく使われているjapanize-matplotlibを与えてみます。

「あーあ、Libraryもないですか」。手動で与えるしかないですね。別途でファイルをダウンロードして、ChatGPTに渡してみます。Githubからjapanize-matplotlibをダウンロードし、ChatGPTにUploadしたら、ようやく日本語で読めるようになりました。
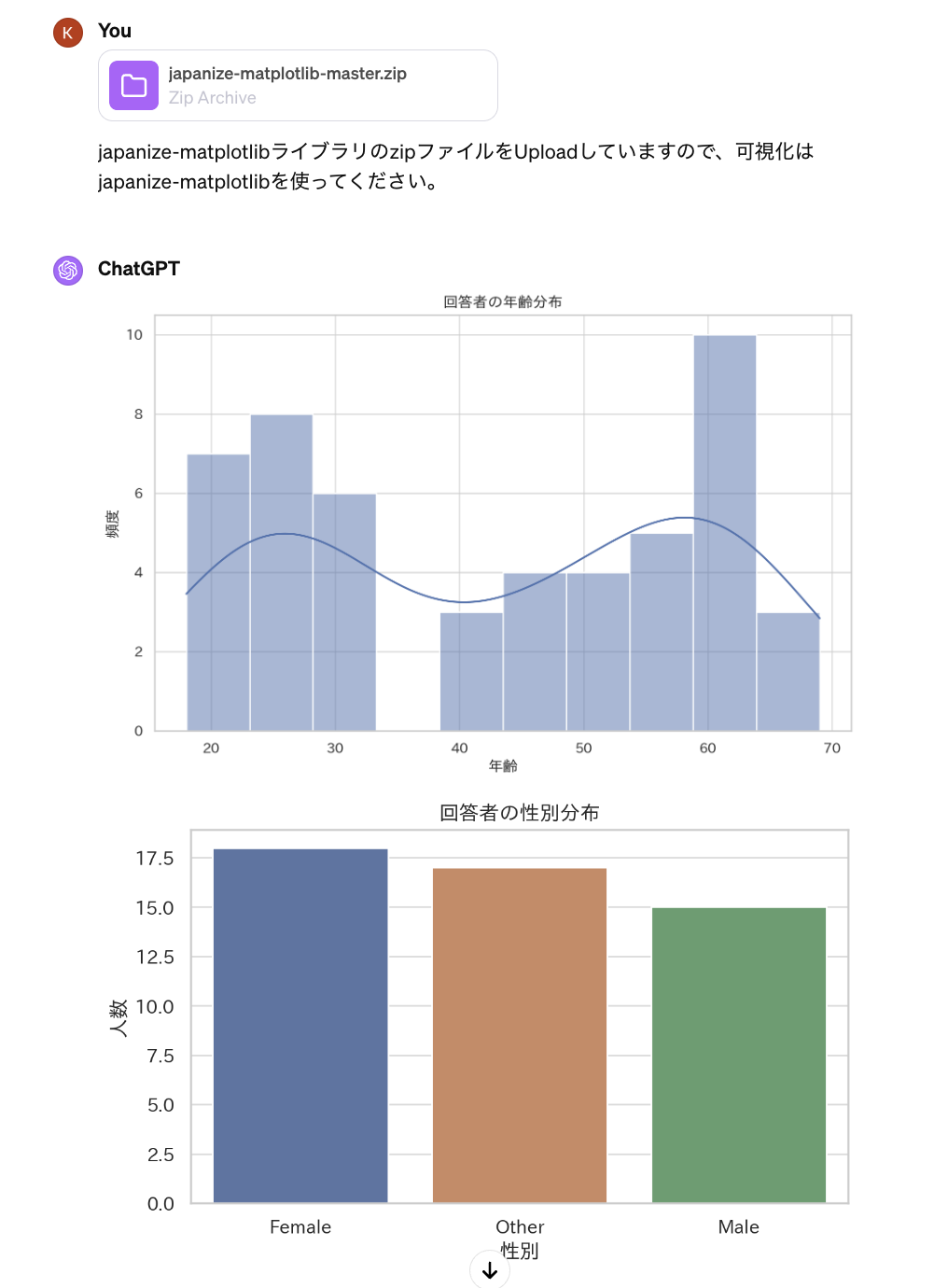
ようやく、日本語でグラフをプロットしてくれました。見た目はそんなに美しくないですね。このままをグラフを出すとデータサイエンティスト失格になりそうですが、結果はどうにか参考にできそうです。普通のデータサイエンティストですと、表示のフォントサイズ・グラフの色などを工夫して、見やすいようにすることが必要だと思います。これは快適なコードのためChatGPTがうまく工夫できるようなPromptを作成するのか必要ではないでしょうか。
ChatGPTが使ったコードは下記のようになります。確認してみると、一般的に簡単に使われているコードのようです。まあ、自分でも快適なコードをコピペしたり、カスタマイズしていますので、その部分をChatGPTに渡せばどうにかなるでしょう。(その場合、ChatGPTと自分の作業スピードはどちらの方が早いかは別にして)
コード: アンケート集計の可視化(日本語)
# Updating the path to the extracted japanize-matplotlib directory
japanize_matplotlib_path = os.path.join(extraction_path, 'japanize-matplotlib-master')
# Importing japanize-matplotlib from the extracted directory
import sys
sys.path.insert(0, japanize_matplotlib_path)
# Now importing japanize-matplotlib
import japanize_matplotlib
# Redoing the visualizations with Japanese labels
# Age Distribution
plt.figure(figsize=(10, 6))
sns.histplot(df['Age'], bins=10, kde=True)
plt.title('回答者の年齢分布')
plt.xlabel('年齢')
plt.ylabel('頻度')
plt.show()
# Gender Distribution
plt.figure(figsize=(7, 4))
sns.countplot(x='Gender', data=df)
plt.title('回答者の性別分布')
plt.xlabel('性別')
plt.ylabel('人数')
plt.show()
# Overall Satisfaction Distribution
plt.figure(figsize=(7, 4))
sns.countplot(x='Overall Satisfaction', data=df)
plt.title('全体の満足度の評価')
plt.xlabel('評価')
plt.ylabel('人数')
plt.show()
# Ease of Use Distribution
plt.figure(figsize=(7, 4))
sns.countplot(x='Ease of Use', data=df)
plt.title('使いやすさの評価')
plt.xlabel('評価')
plt.ylabel('人数')
plt.show()
# Nationality Distribution - Top 10
top_nationalities = df['Nationality'].value_counts().head(10)
plt.figure(figsize=(10, 6))
sns.barplot(x=top_nationalities.values, y=top_nationalities.index)
plt.title('回答者の国籍分布(トップ10)')
plt.xlabel('人数')
plt.ylabel('国籍')
plt.show()
次に、自由記述の回答分析をChatGPTにやってもらったらどうなるかをみていきましょう。
2.2. 自由記述回答のWord Cloud
アンケートからは自由記述回答は厄介な部分ですね。よく使われている分析手法はWordCloudや感情分析などです。アンケートから、どんなコメントが多いかを大まかに、把握するため、WordCloudを作成したいと思います。WordCloudをChatGPTにやってもらったらどうなるかをみていきましょう。
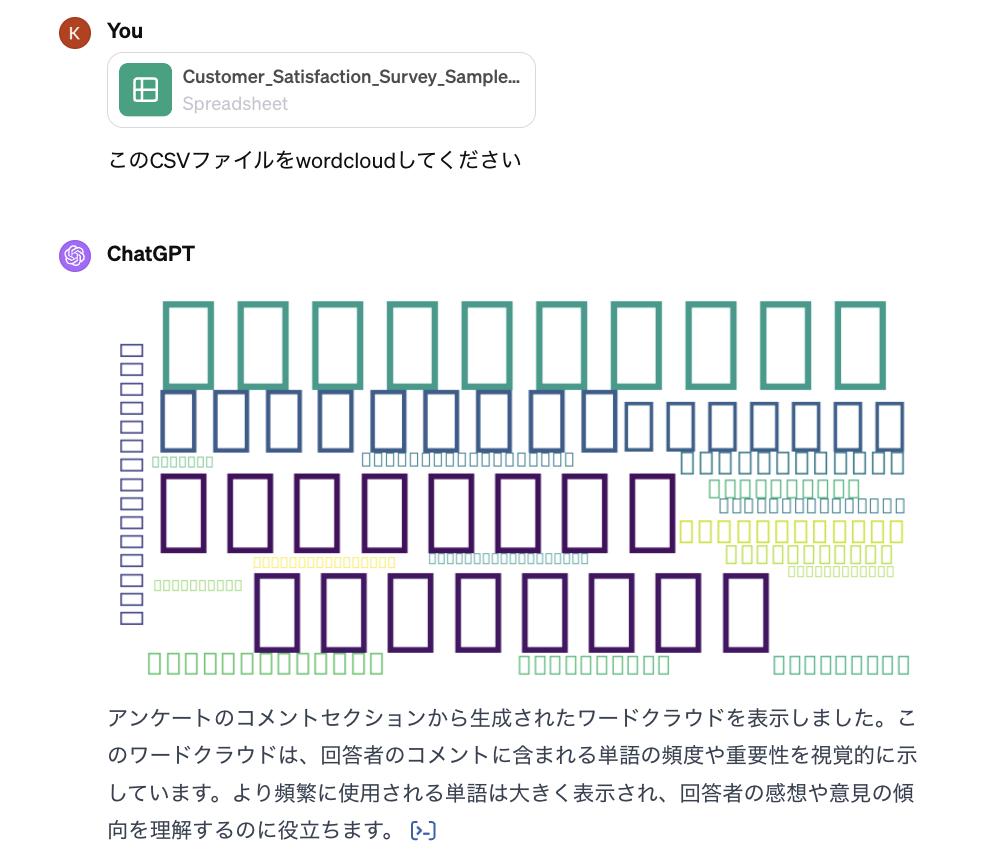
「あーあ、なにこれ〜 なにも読めません」。また日本語のフォントを与えないとダメのようですね。日本語のフォントのIPAfont00303をダウンロードし、ChatGPTにUploadしたら、ようやく日本語を読めるようになりました。
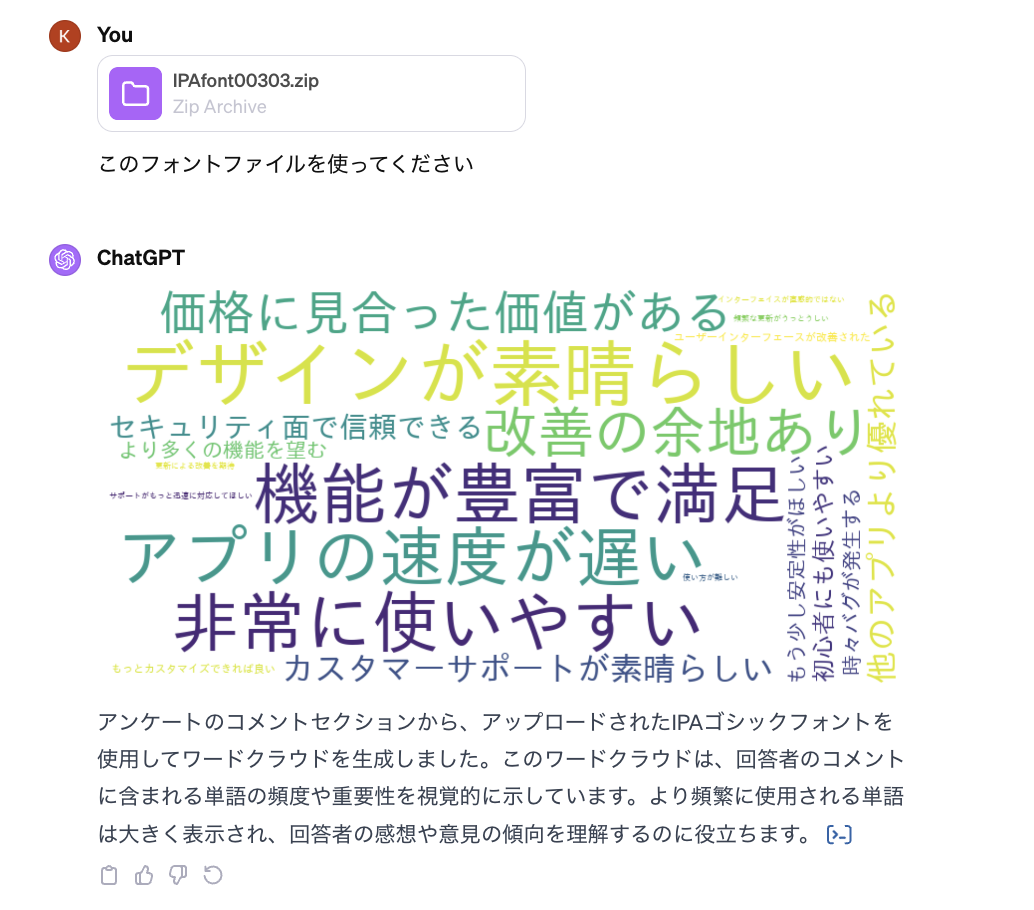
解析してもらったコードは下記です。私が使っているコードと比べたら、見覚えのある部分が多いです。一般的なコードを使ってくれたので、よしよし
コード: 自由記述の回答分析
# Generating a word cloud using the IPA font
ipa_font_path = os.path.join(font_directory_path, 'ipag.ttf')
# Generating a word cloud with the IPA Gothic font
wordcloud_ipa = WordCloud(
font_path=ipa_font_path,
width=800,
height=400,
background_color='white'
).generate(text)
# Displaying the word cloud using matplotlib
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud_ipa, interpolation='bilinear')
plt.axis('off')
plt.show()
2.3. 自由記述回答の感情分析
最後に、顧客のコメントがpositiveかnegativeかを集計するため、感情分析を行ってもらいます。
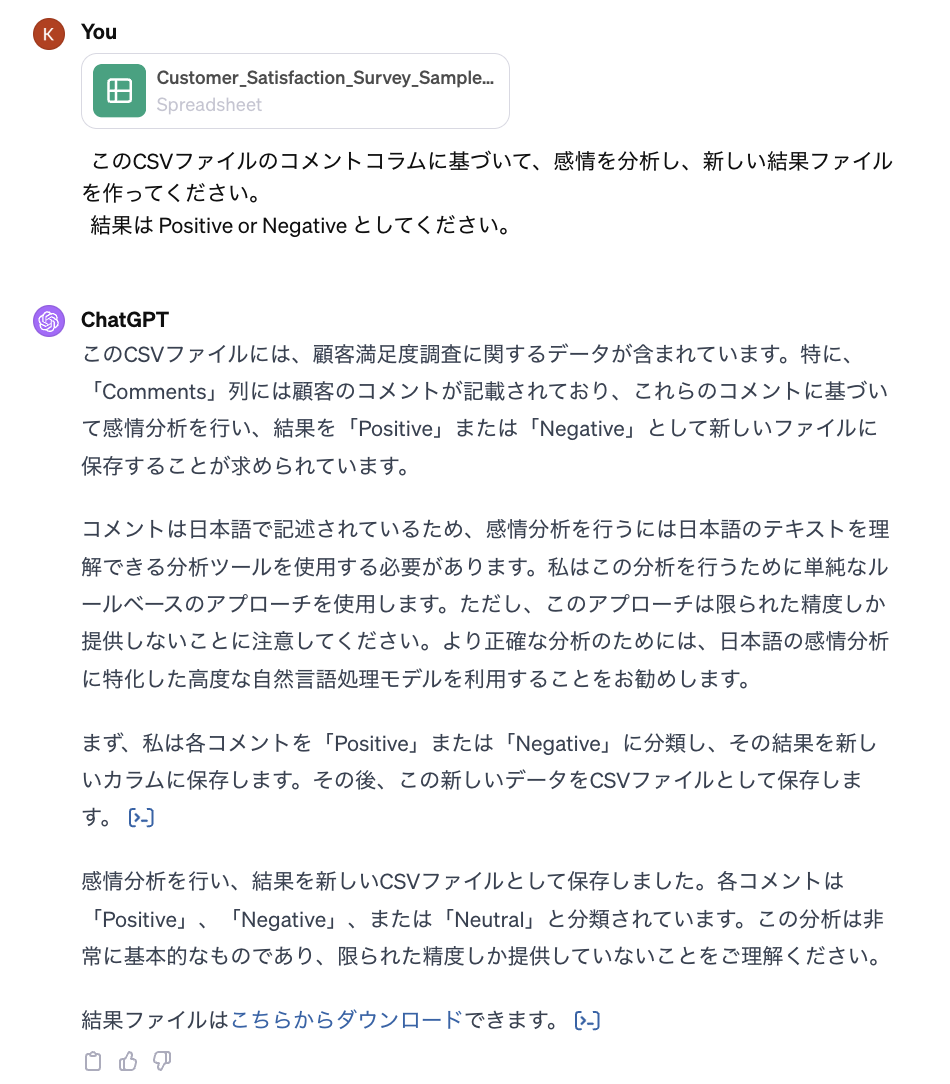
微妙なところがありますが、ある程度の結果を出してくれました。

このように、ChatGPTと喧嘩しながら、やりとりするのは楽しいですが、効率的ではありません。もう少しまとまった形にしてくれないかと期待して、GPTsを使ってみます。
3. GPTsで自分専用のアンケート君を作って分析してみた
3.1. GPTsとは
GPTsは特定の目的のために作成できるカスタムバージョンのChatGPTで、2023年11月6日にOpenAIが公開しました。コーディングが必要なく、誰でも簡単に自分のChatGPTを作成できます。詳細はOpenAIのサイトに説明がありますので興味がある方は公式サイトに目を通して頂ければと思います。
しかし、この機能は無料ではなく、利用するためには$20/monthの有料版(ChatGPT Plus)が必要です。有料版の機能は会社のAccountで試させて頂きました。面白くて、個人のAccountでも自腹で払ってしまって個人の携帯でも遊んでいます。
ところで、現時点(2023年12月23日)では、GPTsはまだ、beta版です。うまく行けば、今後は様々な改善が期待できる機能ではないでしょうか。
3.2. GPTsを使ってみた
やってみたいことは、上記のChatGPTとの面倒なやりとり作業を自分専用のアンケート君でまとめることです。GPTsを使って、自動化してくれるかを試したいと思います。
まず、GPT builderを使ってアンケート君を作成します。このサイトで「Create a GPT」を押せば、作成画面が出てきます。それから、「Configure」を選ぶと、Promptを記入することができます。
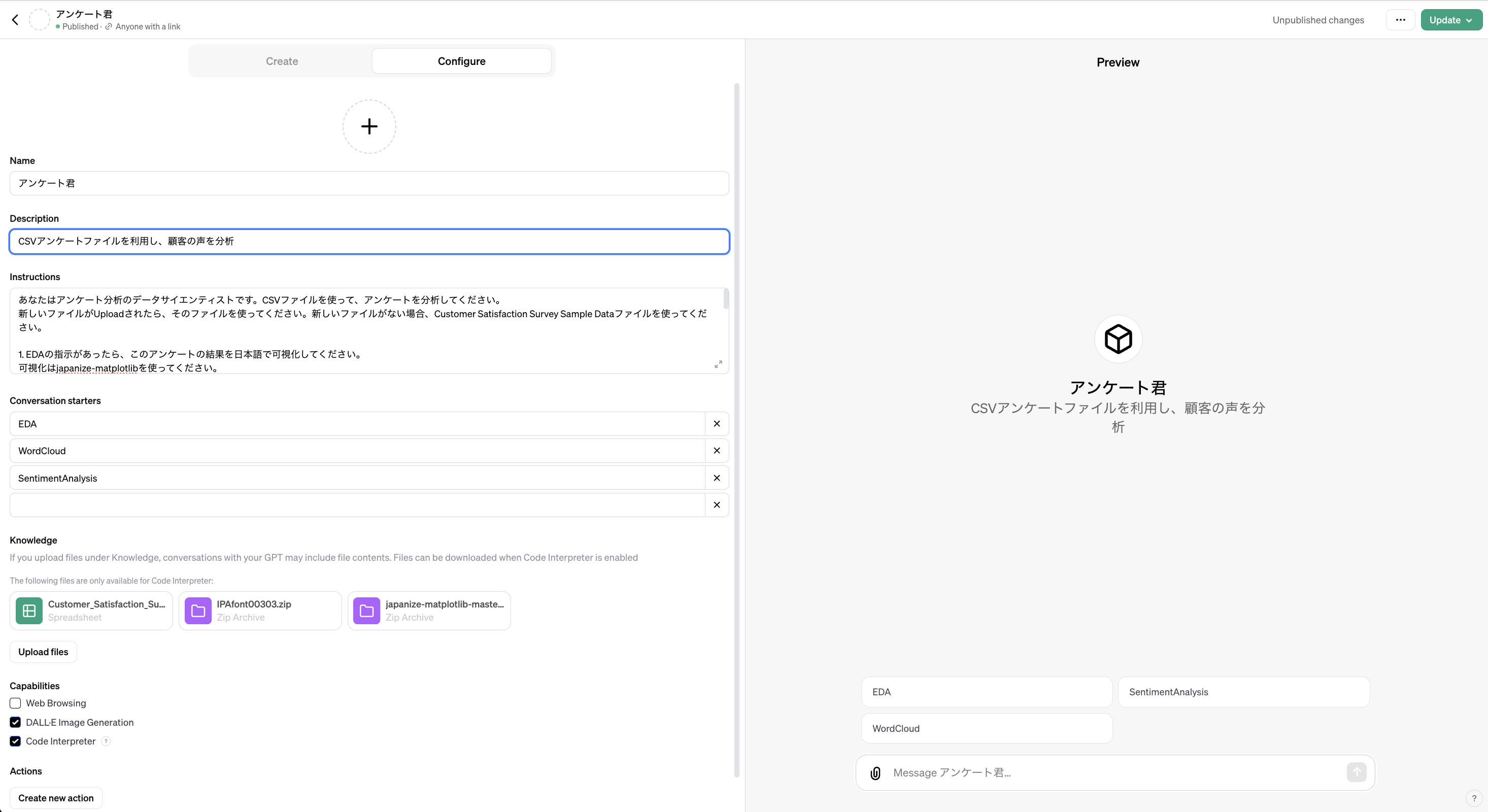
下記のPromptを記入します
コード: GPTs prompt
あなたはアンケート分析のデータサイエンティストです。CSVファイルを使って、アンケートを分析してください。
新しいファイルがUploadされたら、そのファイルを使ってください。新しいファイルがない場合、Customer Satisfaction Survey Sample Dataファイルを使ってください。
1. EDAの指示があったら、このアンケートの結果を日本語で可視化してください。
可視化はjapanize-matplotlibを使ってください。
japanize-matplotlib-master.zipファイルはUploadされていますので、/mnt/data/ directoryに解凍してください。
可視化のために、以下のコードを使ってください。
```
import sys
sys.path.append('/mnt/data/japanize-matplotlib-master')
import matplotlib.pyplot as plt
import japanize_matplotlib
```
可視化結果はファイルに保存してください。ファイル名はなんでもいいです。
2. WordCloudの指示があったら、このCSVファイルのコメント(Comments)コラムをwordcloudしてください。フォントはIPAcont00303.zipファイルを使ってください
3. SentimentAnalysisの指示があったら、このCSVファイルのコメント(Comments)コラムに基づいて、感情を分析し、新しい結果ファイルを作ってください。
分析はキーワードベースの簡易的な感情分析を行ってください。まず、ポジティブとネガティブな感情を示す日本語のキーワードのリストを作成してください。次に、これらのキーワードを用いてアンケートのコメントを分析し、感情を判定してください。
また、分析後後、それぞれのPositiveとNegativeの結果を二つずつ見せてください。
最後に、全体の顧客感想の結果をDALL-E Imageを作成してください。
作成が完了しましたので、試してみましょう。

面白いことをやってくれましたね。上述通り、GPTsは簡単にカスタムGPTを作ることができる機能で、文字入力するだけでAIと色々なやりとりができます。
下記のように、作成したGPTsのリンクをCopyして、他のユーザーにも共有することができ、誰でもアンケート君を使うことができます。
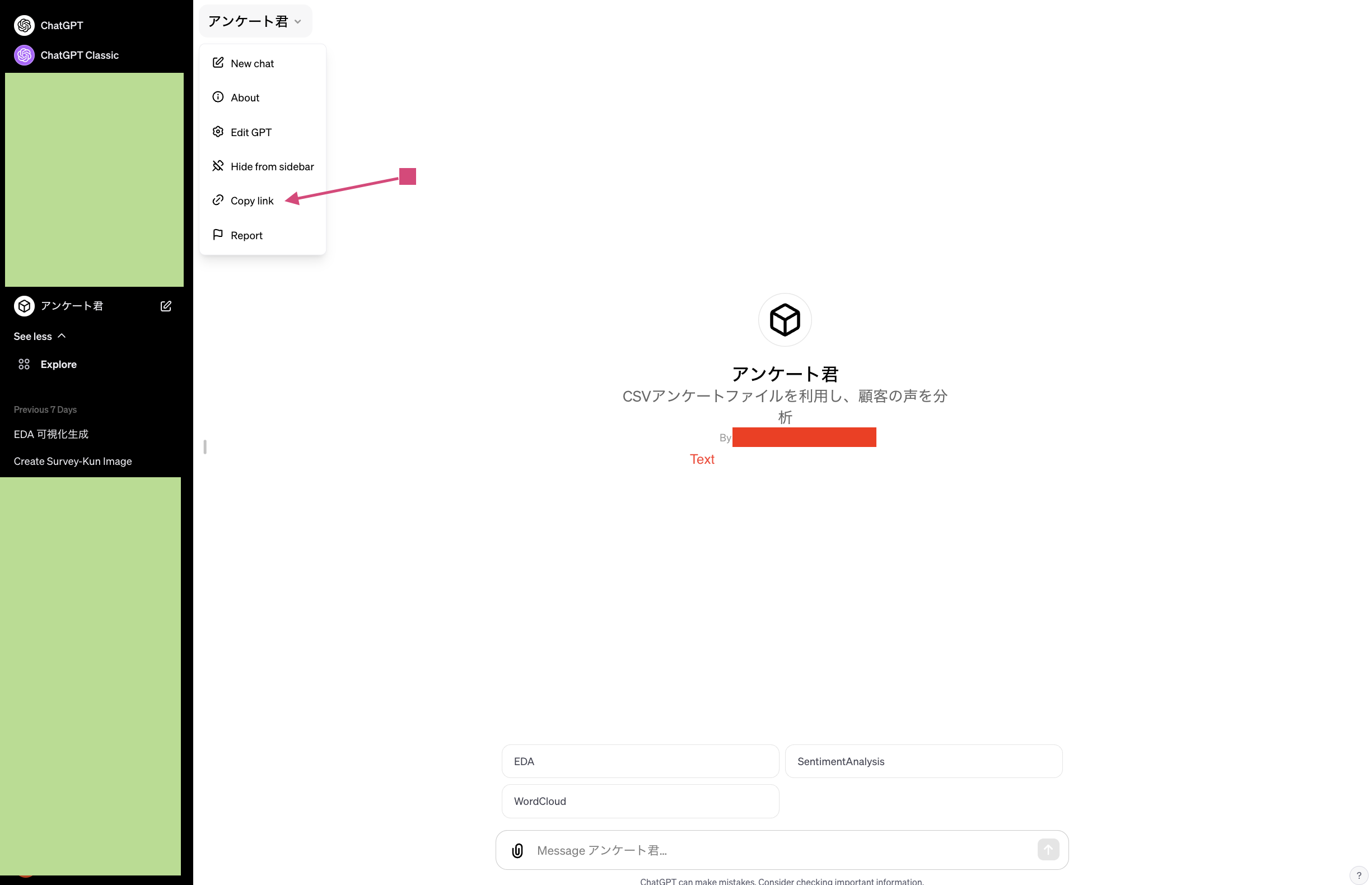
注意点ですが、今回の指示は曖昧な部分がありますので、出てきた答えの再現性はまだ不安定です。データ分析の結果提供は正確性と再現性が大事ですから、本当に利用したいときに、その辺の扱いを検討することが必要です。
また、詳細にコードを変更したり、細かい設定をしたりしたい場合は、Assistants APIを使うことができるようです。
4. Assistants API (+Code Interpreter)で開発用のアンケート君を作ってみた
Assistants API(+Code Interpreter)を使って、アンケート君を作ってみます。まずは、Assistants APIとは何かを説明します。それから、Assistants APIを使ってみます。
4.1. Assistants APIとは
Assistants APIは、さまざまなタスクを実行できる強力なAIアシスタントを開発者が構築できるように設計されているようです。詳細はOpenAIのサイトに説明がありますので、参考にしてください。
現時点(2023年12月23日)、Assistants APIはbeta版ですので、より改善を期待できるのではないでしょうか。公式サイトによると、
- アシスタントは、OpenAIのモデルを特定の指示に基づいて呼び出し、その性格や能力を調整することができます。
- アシスタントは、複数のツールに同時にアクセスすることができます。これには、コードインタープリターや知識検索などのOpenAIがホストするツールだけでなく、開発者が構築・ホストするツール(関数呼び出しを通じて)も含まれます。
- アシスタントは、永続的なスレッドにアクセスできます。スレッドは、メッセージ履歴を保存し、会話がモデルのコンテキストの長さを超えた場合にそれを切り捨てることで、AIアプリケーションの開発を簡素化します。スレッドは一度作成すると、ユーザーからの返信に応じてメッセージを追加するだけです。
- アシスタントは、作成の一部として、またはアシスタントとユーザー間のスレッドの一部として、複数の形式のファイルにアクセスできます。ツールを使用する際、アシスタントはファイル(例えば、画像、スプレッドシートなど)を作成し、作成したメッセージで参照するファイルを引用することもできます。
Assistants APIの流れは以下のようになります。
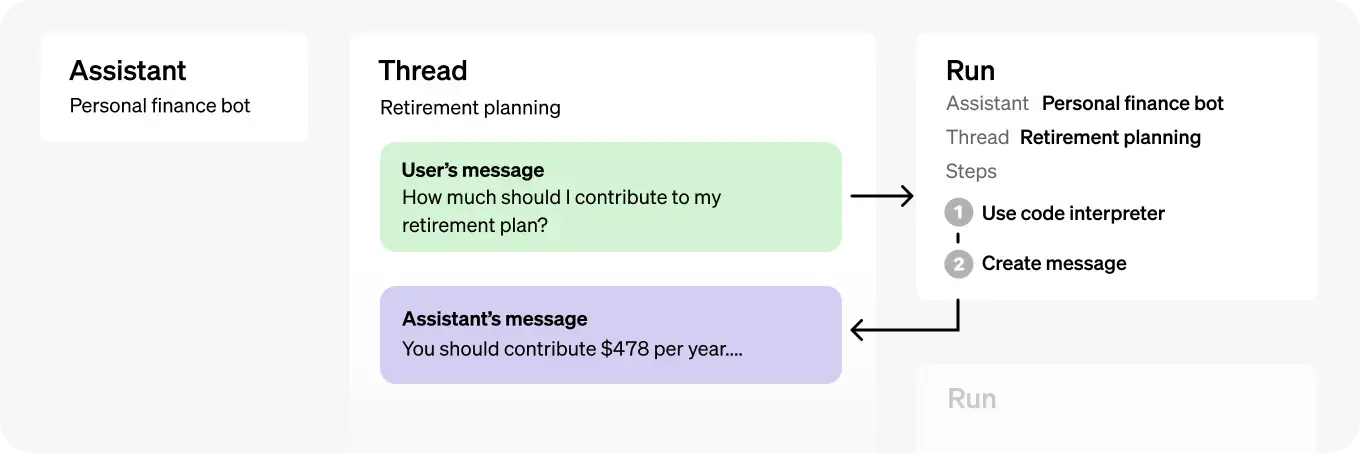
- アシスタント(Assistant):OpenAIのモデルを使用し、ツールを呼び出すために特別に構築されたAI。
- スレッド(Thread):アシスタントとユーザー間の会話セッション。スレッドはメッセージを保存し、モデルのコンテキストに内容を適合させるために自動的に切り捨てを行います。
- メッセージ(Message):アシスタントまたはユーザーによって作成されたメッセージ。テキスト、画像、その他のファイルを含むことができます。スレッド上のリストとしてメッセージが保存されます。
- 実行(Run):スレッド上でアシスタントが呼び出されること。アシスタントは、その設定とスレッドのメッセージを使用して、モデルやツールを呼び出しタスクを実行します。実行の一環として、アシスタントはスレッドにメッセージを追加します。
- 実行ステップ(Run Step):実行の一部としてアシスタントが取った詳細なステップのリスト。アシスタントは実行中にツールを呼び出したり、メッセージを作成することができます。実行ステップを調べることで、アシスタントが最終結果に至るまでの過程を内観することができます。
ところで、Assistants APIを利用した分が課金される従量課金です。沢山遊んでしまったら、どんどん課金されてしまいます。
4.2. Assistants APIを使ってみた
やってみたいことは、上記にChatGPTとの面倒なやりとり作業はGPTsがまとめてくれました。さらに、Assistants APIを使って、開発用のGPTsが作れるかを試したいと思います。
主に以下のステップで進めていきます。
- 0. Set up
- 1. Upload File
- 2. Create an Assistant
- 3. Create a Thread
- 4. Add a Message to a Thread
- 5. Run the Assistant and Check the Run status
- 6. Display the Assistant’s Response
- 7. Download a result file
0. Set up
前提ですが、OPENAI_API_KEYは別途で用意する必要があります。今回の実装はconstants.pyでOPENAI_API_KEYを入れて管理していますので、そこからImportします。
コード: Assistants API: install
# install openai !pip install openai --upgrade # import import pandas as pd import openai import time from constants import OPENAI_API_KEY from openai import OpenAI client = OpenAI( api_key=OPENAI_API_KEY, )
1. Upload File
Asssistants APIに使って欲しいファイルをUploadしておく必要です。これは上記に説明したGPTsの「Upload files」と同じ感じです。ファイルをUploadしておくと、参照するだけで使い回しできますので、何回もUploadする必要はありません。
コード: Assistants API: Upload files
# Step 1: Upload Files
font_file = client.files.create(
file=open("IPAfont00303.zip", "rb"),
purpose='assistants'
)
csv_file = client.files.create(
file=open("Customer_Satisfaction_Survey_Sample_Data.csv", "rb"),
purpose='assistants'
)
matplotlib_file = client.files.create(
file=open("japanize-matplotlib-master.zip", "rb"),
purpose='assistants'
)
csv_file_id = csv_file.id
matplotlib_file_id = matplotlib_file.id
font_file_id = font_file.id
print(font_file)
print(csv_file)
print(matplotlib_file)
ファイルIDを覚えていないときに、「client.files.list()」コマンドで確認することができます。必要ない時に、file id(例えば、file_id=file-xxxxxxxxxx)を使って、client.files.delete(“file-xxxxxxxxxx”)」で、ファイルを削除することができます。一瞬で消えますので、削除するときに慎重に気をつけてください。
必要なファイルをUploadしましたので、次はAssistantを作成します。
2. Create an Assistant
課金を節約するため、GPTsを使ってpromptsではなく、もう少し簡単なpromptsを書きます。
下記のように、assistantsをcreateすると、専用なアンケート君(Questionnaire Analyst)が作成されます。
作成されたAssistantsは「client.beta.assistants.list()」コマンドで確認できます。誤った作成したり、したら、assistant id(例えば、assistant.id=”asst_yyyyyyyyyyy”)を使って、「client.beta.assistants.delete(“asst_yyyyyyyyyyy””)」で削除できます。
また、GPTモデルを選ぶことができます。今回はコスト節約、かつそこまで性能が必要ない指示のため、gpt-4ではなくて、gpt-3.5を使いました。
コード: Assistants API: Create an Assistant
# Step 2: Create an Assistant
assistant = client.beta.assistants.create(
name="Questionnaire Analyst",
instructions='''あなたはアンケート分析のデータサイエンティストです. CSVファイルを使って、アンケートを分析してください。
''',
tools=[{"type": "code_interpreter"}],
model="gpt-3.5-turbo-1106", # gpt-3.5-turbo-1106 and gpt-4-1106-preview
file_ids=[csv_file.id]
)
print("assistant", assistant)
print("assistant.id:", assistant.id)
3. Create a Thread
Assistantが作成されたら、スレッド(Thread)を作成します。同じAssistantsで幾つかのスレッドで管理できます。GPTsと違って開発用としては、一度スレッドを作成すると、ユーザーからの返信に応じてメッセージを追加するだけです。
コード: Assistants API: Create a Thread
# Step 3: Create a Thread
thread = client.beta.threads.create()
print("thread:", thread)
print("thread.id:", thread.id)
4. Add a Message to a Thread
作成したスレッドに、指示を追加します。簡単に、EDAをしてもらうようにしました。
コード: Assistants API: Add a Message to a Thread
# Step 4: Add a Message to a Thread
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content='''
このアンケートの結果を日本語で可視化してください。
可視化はjapanize-matplotlibを使ってください。
japanize-matplotlib-master.zipファイルはUploadされていますので、/mnt/data/ directoryに解凍してください。
可視化のために、以下のコードを使ってください。
```
import sys
sys.path.append('/mnt/data/japanize-matplotlib-master')
import matplotlib.pyplot as plt
import japanize_matplotlib
```
可視化結果はファイルに保存してください。ファイル名はなんでもいいです。
''',
file_ids=[matplotlib_file.id]
)
print(message)
5. Run the Assistant and Check the Run status
それでは、用意できたら、実行します。
コード: Assistants API: Run the Assistant and Check the Run status
# Step 5: Run the Assistant and Check the Run status
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
# instructions=""
)
completed = False
while not completed:
# Get status of the run
run = client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
)
print("run.status:", run.status)
if run.status == 'completed':
completed = True
elif run.status == 'failed':
raise Exception("Run failed")
elif run.status == 'in_progress' or 'queued':
time.sleep(5)
else:
pass
下記のように、実行のstatusを確認することができます。Tutorialでは failedを確認していないようですが、個人のAPIで使うときに、スレッドのやりとり回数が制限されますので、failedだとfailedとして表示しています。
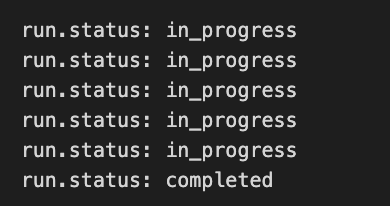
6. Display the Assistant’s Response
実行したら、Assistantとのやりとりを確認することできます。
コード: Assistants API: Display the Assistant’s Response
# Step 6: Display the Assistant's Response
messages = client.beta.threads.messages.list(
thread_id=thread.id
)
messages
for message in messages:
print("loop")
# print(message.content[0])
try:
print(message.content[0].image_file)
print(message.content[0].image_file.file_id)
file_id = message.content[0].image_file.file_id
cited_file = client.files.retrieve(message.content[0].image_file.file_id)
print(cited_file)
except:
print(message.content[0].text)め
メッセージを確認したら、ChatGPTと似たようなやりとりが自動的に生成されることがわかります。
7. Download a result file
最後に、結果をDownloadすることもできます。
コード: Assistants API: file download
# file download
! curl https://api.openai.com/v1/files/{file_id}/content -H "Authorization: Bearer $OPENAI_API_KEY" > file.png
%matplotlib inline
from IPython.display import Image
Image('file.png')
Downloadした結果は下記のようになります。
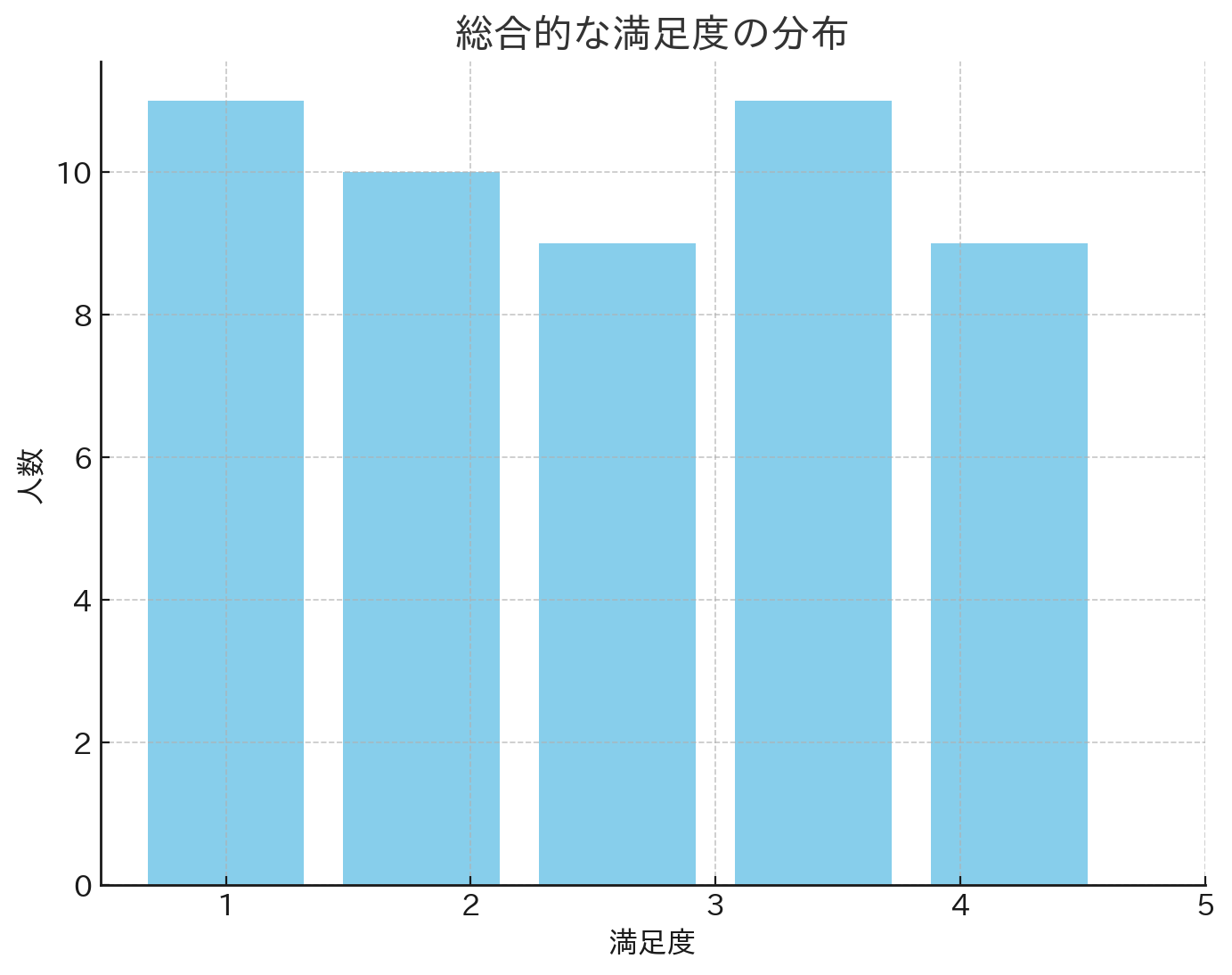
どうにか作ることができました。いかがでしょうか。
5. まとめと考察
今回は顧客アンケートに「ChatGPT, GPTs, Assistants API」を使ってみました。日本語を使うのは工夫が必要でした。
コスト面では、ChatGPTとGPTsはChatGPT Plus ($20/month)で利用できますが、Assistants APIは別の料金が発生します。簡単に試すだけでも、一回あたりで数十円課金になりますので、繰り返しコードを叩いたり、kernelを再起動したりする習慣がある方は気をつけてくださいね。
分析結果の正確性を評価していませんが、ChatGPTはたまにバレないような書き方で嘘をつくので、分析結果が正確かどうかのレビューが必要でしょう。これはテータサイエンティストはチームで働いている大きいプロジェクトでも行なっていることです。楽観的かもしれませんが、人はミスをするし、ChatGPTもミスをします。うまく再確認すれば、ミスを減らせるでしょう。人の成長と共に、AIも成長することを願っています。
おまけに
今回のアイキャッチ画像はChatGPTに作ってもらいました。アンケート君は十分に可愛いでしょうか。

最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD