2022.07.06
続・Python で映画をオススメしてみる
〜Field-Aware Factorization Machines によるレコメンデーション〜
導入
こんにちは、グループ研究開発本部 AI研究開発室の T.I. です。
さて、一応は密かなシリーズとなっておりますが、前々回の Blog では、ユーザーからの明示的な評価(explicit feedback)を Matrix Factorization による推薦アルゴリズム、前回は、 クリックなどの暗黙的な評価(implicit feedback)から Alternative Least Square という手法による推薦アルゴリズムについて紹介しました。
今回は、ユーザー属性とアイテム評価の情報を組み合わせた推薦アルゴリズムとして、 Factorization Machines という手法と、その発展系について紹介したいと思います。
Factorization Machines とその応用
前回、前々回で紹介した Matrix Factorization では、ユーザー \(i\)のアイテム \(j\) に対する評価や反応 \(r_{ij}\) の行列 \(R\) として表現し、その欠損した未知の数値をユーザー行列(\(P\))とアイテム行列(\(Q\))の積として推定する手法でした。
\(R \approx P^T Q\)
今回紹介する Factorization Machines (https://ieeexplore.ieee.org/document/5694074)では、ユーザーやアイテムが持つ特徴量を組み合わせて予測精度を改善する手法です。
Factorization Machines
Factorization Machines (FM) とは、ユーザーやアイテムの属性情報を使って、性能をあげる手法ですが、そのデータの持ち方に大きな特徴があります。これまでは、ユーザーを行にアイテムを列に持っている行列を扱ってきました。
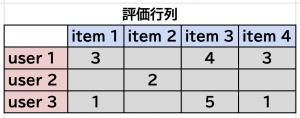
これを FM では、以下のように持ち替えます。
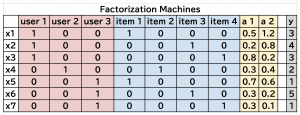
ユーザーもアイテムも列として取り扱い、されに補助情報や評価値も列として持ちます。評価の1点1点を行として持ちます。このユーザー・アイテム、補助情報を含む特徴量 \(x_i\) を基に、正解 label \(y\) を以下のモデルで推定します。
\(\hat{y} = w_0 + \sum_j w_j x_j + \sum_{j=1}^n \sum_{k+1}^n \langle f_j, f_k \rangle x_j x_k\)
特徴量同士の掛け算(2次の項)を含むことが特徴となります。通常の特徴量の交絡、一般的には
\(\sum_{j=1}^n \sum_{k+1}^n w_{ij} x_i x_j\)
と \(n^2\) 個のパラメータで表されますが、アイテム推薦の場合のように殆どの特徴量がゼロで巨大な sparse な行列の場合ではパラメータを増やすと計算コストの増加と過学習の懸念があります。
そのため、FM の特徴として、この2次の項の重み(係数)が、\(f_i \in \mathbf{R}^k\) というベクトル(\(k\)-dim.)の内積で表し naive には、\(n^2\) 個の parameter が必要なところを、\(n\) のベクトルで表現することです。そのため、FM では、さまざまな特徴量を計算コストを気にせずに追加できます。また、この計算ですが、
\(\sum_{j=1}^n \sum_{k=j+1} \langle f_j, f_k \rangle x_j x_k = \frac{1}{2} \sum_{l=1}^k \left( \left(\sum_{j=1}^n f_{j,l}x_j)\right)^2 – \sum_{j=1}^n f_{j,l}^2 x_j^2 \right)\)
と工夫することで \(\mathcal{O}(kn^2) \rightarrow \mathcal{O}(kn)\) の計算量に抑えることができます。
目的変数 \(\hat{y}\) は、ユーザー評価などの予測(regression)でもよいですし、click するか否かなどの classification など、様々な予測モデルに汎用的に利用できます。上の式は2次までの交絡を含めましたが、さらに一般的に \(n\) 次の項まで含めることもできます。
Field-Aware Factorization Machines
FM では、補助的な特徴量を one-hot vector で表していました。これらは全て同等に扱われてしまいますが、例えば、性別、年齢などの情報はそれぞれのグループ化されるわけですので、
その “field” の特性を考えて交絡の影響を考えた方が良さそうです。そのような観点で提唱されたモデルが、 Field-Aware Factorization Machines (FFM) (Y. Juan et al 2016)です。
FFM は FM と似ていますが、以下のようになります。
\(\hat{y} = w_0 + \sum_j w_j x_j + \sum_{j=1}^n \sum_{k+1}^n \langle f_{j,F(k)}, f_{k,F(j)} \rangle x_j x_k\)
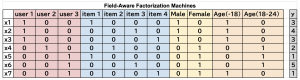
同じ種類の特徴量ごとにグループ化されている点が FM との違いになります。この FFM はその後も、Deep な Neural Network と組み合わせたり、特徴量の性質を活用するなど様々な拡張・発展しています。
詳細については、こちらの記事にきれいにまとめられています(「Field-aware な Factorization Machines の最新動向」(https://qiita.com/guglilac/items/6c8971d27c143e2567a4))
FFM のデモ
今回は、xLearn (https://github.com/aksnzhy/xlearn)という library を利用します。また、上記で触れたように FFM はその後も様々な形での拡張が提唱されております。それらの拡張版を利用するには PyTorch FM (https://github.com/rixwew/pytorch-fm) という library を利用すると便利です。
MovieLens Dataset & User Info.
データセットとしては、前々回利用した MovieLens Dataset (https://grouplens.org/datasets/movielens/) を再び利用します。
wget -nc --no-check-certificate https://files.grouplens.org/datasets/movielens/ml-1m.zip -P . unzip -n ml-1m.zip -d .
以前は、映画の5段階評価の情報のみを利用していましたが、実は、このデータセットには評価したユーザーの属性情報が含まれていました。これについて、最初に簡単に見ておきます。
import pandas as pd
df_users = pd.read_csv('ml-1m/users.dat', sep='::', header=None, engine='python',
names=['user_id', 'gender', 'age', 'occupation', 'zip'])
ユーザーの情報として利用可能なのは、以下の項目です。
- 年齢(age)
- 性別(gender)
- 職業(occupation)
- Zip Code(zip)
ただ、元のファイルでは、年齢は代表値、職業は ID で割り振られているので、少し前処理が必要です。
age_map = {
1: " -18",
18: "18-24",
25: "25-34",
35: "35-44",
45: "45-49",
50: "50-55",
56: "56+"
}
occupation_map = {
0: "other",
1: "academic/educator",
2: "artist",
3: "clerical/admin",
4: "college/grad student",
5: "customer service",
6: "doctor/health care",
7: "executive/managerial",
8: "farmer",
9: "homemaker",
10: "K-12 student",
11: "lawyer",
12: "programmer",
13: "retired",
14: "sales/marketing",
15: "scientist",
16: "self-employed",
17: "technician/engineer",
18: "tradesman/craftsman",
19: "unemployed",
20: "writer"
}
df_users['age_'] = df_users.age.map(age_map)
df_users['occ_'] = df_users.occupation.map(occupation_map)
簡単に可視化してみます。
ax = (
df_users.pivot_table(index='age_',
columns='gender',
values='user_id',
aggfunc='count')
.plot.barh(stacked=True, width=0.8, figsize=(8,6))
)
ax.set(xlabel='User Count', ylabel='Age', title='MovieLens 1M Dataset');
ax = (
df_users.pivot_table(index='occ_',
columns='gender',
values='user_id',
aggfunc='count')
.loc[df_users['occ_'].value_counts().index[::-1],:]
.plot.barh(stacked=True, width=0.8, figsize=(8, 12))
)
ax.set(xlabel='User Count', ylabel='Occupation', title='MovieLens 1M Dataset');
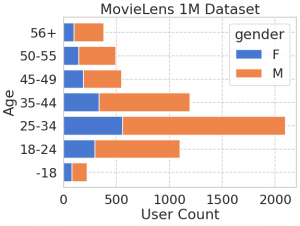
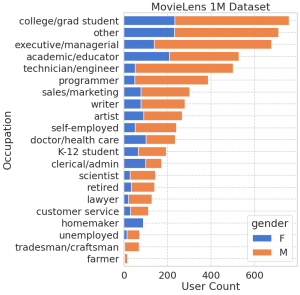
性別としては男性、年齢としては25-34代が中心、そして職業としては大学生が最も多いです。なお、このようなデータ可視化のコツとして、年齢のように順序に意味があるカテゴリーについては年齢順に並べ、職業のように順番がつけられない場合は、件数が多い順に並べると分かりやすいですね。
US の Zip code の情報もありますので、こちらも可視化してみましょうか。そのために、uszipcode package (https://pypi.org/project/uszipcode) を利用します。(日本の郵便番号の場合、jusho (https://github.com/nagataaaas/Jusho)という類似の python package があります。)
!pip install uszipcode
from uszipcode import SearchEngine
from uszipcode.state_abbr import MAPPER_STATE_ABBR_SHORT_TO_LONG
sr = SearchEngine()
def get_state(zipcode: str) -> str:
z = sr.by_zipcode(zipcode)
try:
state = z.state
except:
state = 'N/A'
return state
df_users['state'] = df_users['zip'].apply(get_state)
df_users['state_name'] = df_users['state'].map(MAPPER_STATE_ABBR_SHORT_TO_LONG)
州の数は多いので、上位10位までに絞って件数を確認してみます。
(
df_user['state_name'].value_counts()
[:10][::-1].plot.barh(width=0.8)
)
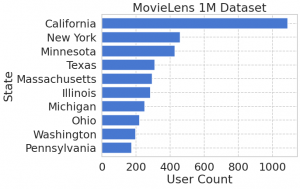
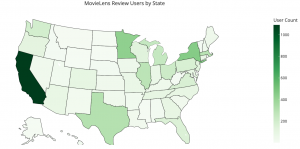
州でいうと California, New York, Minnesota, Texas からの評価が多いようです。しかし、私は、どうにもアメリカの地理には疎いのでどこらへんかよくわかりません。plotly を使うとこんな感じに可視化もできます。
df_state = (
df_users['state'].value_counts()
.to_frame().reset_index()
.rename(columns={'index': 'state', 'state': 'count'})
)
df_state.head()
fig = go.Figure(data=go.Choropleth(
locations=df_state['state'],
z = df_state['count'],
locationmode = 'USA-states',
colorscale = 'Greens',
marker_line_color='black',
colorbar_title = "User Count",
))
fig.update_layout(
title_text = 'MovieLens Review Users by State',
geo_scope='usa',
height=800
)
fig.show()
さて、これらのユーザーの個人属性(性別・年齢・職業・地域)+映画のジャンルを特徴量として映画の推薦をしてみようと思います。
xLearn の実践
さて、xLearn を利用するにあたって、必要なデータの前処理を進めましょう。
# movielens preprocessing
df_ratings = pd.read_csv('ml-1m/ratings.dat', sep='::', header=None, engine='python',
names=['user_id', 'movie_id', 'rating', 'timestamp'])
df_movies = pd.read_csv('ml-1m/movies.dat', sep='::', header=None, engine='python',
names=['movie_id', 'title', 'genre'], encoding='latin1')
genre_list = [
"Action",
"Adventure",
"Animation",
"Children's",
"Comedy",
"Crime",
"Documentary",
"Drama",
"Fantasy",
"Film-Noir",
"Horror",
"Musical",
"Mystery",
"Romance",
"Sci-Fi",
"Thriller",
"War",
"Western"
]
for genre in genre_list:
df_movies[f'genre_{genre}'] = df_movies.genre.str.contains(genre).astype(int)
df_movies.drop(['genre'], axis=1, inplace=True) # one-hot-vectorizer
df_ml = pd.merge(df_ratings[['user_id', 'movie_id', 'rating']],
df_users[['user_id', 'gender', 'age_', 'occ_', 'state']],
on=['user_id'], how='left')
df_ml = pd.merge(df_ml, df_movies.drop('title', axis=1), on=['movie_id'], how='left')
df_ml.head()
ただ、このままではデータ量が多く、処理が大変なので減らしておきます。
import numpy as np
rng = np.random.default_rng(1235)
valid_user_ids = rng.choice(df_users.user_id.unique(), size=1000, replace=False)
_df_ml = df_ml.query('user_id in @valid_user_ids').copy()
_df_ml['rating_count'] = _df_ml.groupby('movie_id')['user_id'].transform('count')
fig, ax = plt.subplots(figsize=(8, 5))
sns.ecdfplot(_df_ml.groupby('movie_id')['user_id'].count().sort_values(), ax=ax)
ax.set(ylabel='Proportion', xlabel='Number of Reviews', title='MovieLens 1M (1000 users)');
threshold = 150
df_ml_reduced = _df_ml.query('rating_count >= @threshold').copy()
print(f'total rating = {len(df_ml_reduced):,d}, use ids = {df_ml_reduced.user_id.nunique():,d}, movie ids = {df_ml_reduced.movie_id.nunique()}')
# total rating = 60,899, use ids = 1,000, movie ids = 266
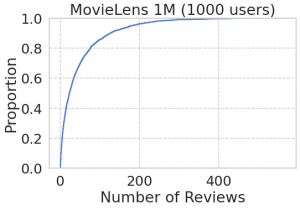
このようにデータ量を減らす際の閾値を決める際には、累積分布プロットを確認しながらやると良いですね。結果的に、1000 人のユーザーと266の映画で、合計約6万件のデータとなりました。
FFM を利用するためには、libffm (https://github.com/ycjuan/libffm)のデータフォーマットに変換する必要があります。少々わかりにくいですが、field : index : value の3つの組みで設定します。
libffm format:
label field_1:index_1:value_1 field_2:index_2:value_2 ...
今回の場合、label は rating になり、以下の column にそれぞれ field ID を連番で割り振ります。
field – index – value
- user id – 1:user id:1
- movie id – 2:movie id:1
- user gender – 3:gender id:1
- user age – 4:age id:1
- user occupation – 5:occupation id:1
- user state – 6:state id:1
- movie genre action – 7:0:0 or 7:0:1
- movie genre adventer – 8:0:0 or 8:0:1
- …
field 1-6 については、index として、その対応する ID があるという意味で value = 1 となります。また、7- の映画のジャンルに関しては1つの映画で重複することもあり、それぞれ別個の field で管理し、index は1つのみで、そのジャンルか否かの binary で書き込みます。
user_ids = sorted(df_ml.user_id.unique())
user_id2index = dict(zip(user_ids, range(len(user_ids))))
movie_ids = sorted(df_ml.movie_id.unique())
movie_id2index = dict(zip(movie_ids, range(len(movie_ids))))
gender_ids = sorted(df_ml.gender.unique())
gender_id2index = dict(zip(gender_ids, range(len(gender_ids))))
age_ids = sorted(df_ml.age_.unique())
age_id2index = dict(zip(age_ids, range(len(age_ids))))
occ_ids = sorted(df_ml.occ_.unique())
occ_id2index = dict(zip(occ_ids, range(len(occ_ids))))
state_ids = sorted(df_ml.state.unique())
state_id2index = dict(zip(state_ids, range(len(state_ids))))
with open('train_data.txt', 'w') as fout:
train_data = ''
for i, row in tqdm.tqdm(df_ml_reduced.iterrows()):
_line = f'{row["rating"]} 0:{user_id2index.get(row["user_id"])}:1 1:{movie_id2index.get(row["movie_id"])}:1'
_line_user_info = f'2:{gender_id2index.get(row["gender"])}:1 3:{age_id2index.get(row["age_"])}:1 4:{occ_id2index.get(row["occ_"])}:1 5:{state_id2index.get(row["state"])}:1'
_line_movie_info = ''
icol = 6
for col in ['genre_Action', 'genre_Adventure', 'genre_Animation',
"genre_Children's", 'genre_Comedy', 'genre_Crime', 'genre_Documentary',
'genre_Drama', 'genre_Fantasy', 'genre_Film-Noir', 'genre_Horror',
'genre_Musical', 'genre_Mystery', 'genre_Romance', 'genre_Sci-Fi',
'genre_Thriller', 'genre_War', 'genre_Western']:
_line_movie_info += f'{icol}:0:{row[col]} '
icol += 1
train_data += f'{_line} {_line_user_info} {_line_movie_info}' + os.linesep
fout.write(train_data)
!head train_data.txt 4 0:1:1 1:2013:1 2:1:1 3:6:1 4:16:1 5:21:1 6:0:1 7:0:0 8:0:0 9:0:0 10:0:0 11:0:1 12:0:0 13:0:1 14:0:0 15:0:0 16:0:0 17:0:0 18:0:0 19:0:0 20:0:0 21:0:0 22:0:0 23:0:0 4 0:1:1 1:627:1 2:1:1 3:6:1 4:16:1 5:21:1 6:0:1 7:0:1 8:0:0 9:0:0 10:0:0 11:0:0 12:0:0 13:0:0 14:0:0 15:0:0 16:0:0 17:0:0 18:0:1 19:0:0 20:0:0 21:0:0 22:0:0 23:0:0 5 0:1:1 1:2078:1 2:1:1 3:6:1 4:16:1 5:21:1 6:0:0 7:0:0 8:0:0 9:0:0 10:0:0 11:0:1 12:0:0 13:0:1 14:0:0 15:0:0 16:0:0 17:0:0 18:0:0 19:0:0 20:0:0 21:0:0 22:0:0 23:0:0 3 0:1:1 1:2426:1 2:1:1 3:6:1 4:16:1 5:21:1 6:0:1 7:0:1 8:0:0 9:0:0 10:0:0 11:0:0 12:0:0 13:0:0 14:0:1 15:0:0 16:0:0 17:0:0 18:0:0 19:0:0 20:0:1 21:0:0 22:0:0 23:0:0 3 0:1:1 1:2708:1 2:1:1 3:6:1 4:16:1 5:21:1 6:0:1 7:0:1 8:0:0 9:0:0 10:0:0 11:0:0 12:0:0 13:0:0 14:0:0 15:0:0 16:0:0 17:0:0 18:0:0 19:0:0 20:0:1 21:0:1 22:0:0 23:0:0 4 0:1:1 1:1120:1 2:1:1 3:6:1 4:16:1 5:21:1 6:0:1 7:0:1 8:0:0 9:0:0 10:0:0 11:0:0 12:0:0 13:0:0 14:0:0 15:0:0 16:0:0 17:0:0 18:0:0 19:0:1 20:0:1 21:0:0 22:0:1 23:0:0 2 0:1:1 1:1123:1 2:1:1 3:6:1 4:16:1 5:21:1 6:0:0 7:0:0 8:0:0 9:0:0 10:0:0 11:0:1 12:0:0 13:0:1 14:0:0 15:0:0 16:0:0 17:0:0 18:0:0 19:0:0 20:0:0 21:0:0 22:0:0 23:0:0 5 0:1:1 1:3341:1 2:1:1 3:6:1 4:16:1 5:21:1 6:0:1 7:0:0 8:0:0 9:0:0 10:0:0 11:0:0 12:0:0 13:0:1 14:0:0 15:0:0 16:0:0 17:0:0 18:0:0 19:0:0 20:0:0 21:0:0 22:0:0 23:0:0 3 0:1:1 1:2892:1 2:1:1 3:6:1 4:16:1 5:21:1 6:0:0 7:0:0 8:0:0 9:0:0 10:0:1 11:0:0 12:0:0 13:0:1 14:0:0 15:0:0 16:0:0 17:0:0 18:0:0 19:0:1 20:0:0 21:0:0 22:0:0 23:0:0 5 0:1:1 1:1478:1 2:1:1 3:6:1 4:16:1 5:21:1 6:0:1 7:0:0 8:0:0 9:0:0 10:0:0 11:0:0 12:0:0 13:0:0 14:0:0 15:0:0 16:0:0 17:0:0 18:0:0 19:0:0 20:0:0 21:0:1 22:0:0 23:0:0
また予測用のデータも作成しておきます。容量の都合なども考えてさらに100名のユーザーに絞っておきます。
_df_users = (
df_users.query('user_id in @valid_user_ids').copy()[['user_id', 'gender', 'age_', 'occ_', 'state']]
.sample(100, random_state=42)
)
valid_movie_ids = df_ml_reduced.movie_id.unique()
_df_movies = df_movies.query('movie_id in @valid_movie_ids').copy().drop('title', axis=1)
_df_users['tmp'] = 1
_df_movies['tmp'] = 1
_df_ml = pd.merge(_df_users, _df_movies, how='outer')
df_ml_test = pd.merge(df_ratings[['user_id', 'movie_id', 'rating']], _df_ml, on=['movie_id', 'user_id'], how='right')
df_ml_test['rating'] = df_ml_test['rating'].fillna(0).astype(int)
with open('test_data.txt', 'w') as fout:
train_data = ''
for i, row in tqdm.tqdm(df_ml_test.iterrows()):
_line = f'{row["rating"]} 0:{user_id2index.get(row["user_id"])}:1 1:{movie_id2index.get(row["movie_id"])}:1'
_line_user_info = f'2:{gender_id2index.get(row["gender"])}:1 3:{age_id2index.get(row["age_"])}:1 4:{occ_id2index.get(row["occ_"])}:1 5:{state_id2index.get(row["state"])}:1'
_line_movie_info = ''
icol = 6
for col in ['genre_Action', 'genre_Adventure', 'genre_Animation',
"genre_Children's", 'genre_Comedy', 'genre_Crime', 'genre_Documentary',
'genre_Drama', 'genre_Fantasy', 'genre_Film-Noir', 'genre_Horror',
'genre_Musical', 'genre_Mystery', 'genre_Romance', 'genre_Sci-Fi',
'genre_Thriller', 'genre_War', 'genre_Western']:
_line_movie_info += f'{icol}:0:{row[col]} '
icol += 1
train_data += f'{_line} {_line_user_info} {_line_movie_info}' + os.linesep
fout.write(train_data)
準備ができましたので、FFM のモデル学習と推薦をします。
!pip install -q xlearn
# for Google Colab set USER = test
import os
os.environ['USER'] = 'test'
import xlearn as xl
ffm_model = xl.create_ffm()
ffm_model.setTrain('train_data.txt')
param = {'task': 'reg', 'lr': 0.2, 'lambda': 0.01, 'metric': 'rmse', 'epoch': 10, 'k': 10, 'opt':'sgd'}
ffm_model.fit(param, './model.out')
ffm_model.setTest('test_data.txt')
ffm_model.predict("./model.out", "./output.txt")
結果は以下のようにテストデータに対する予測 Rating が出力されました。
!head output.txt 3.00818 3.09555 3.05435 2.99251 2.9766 3.10428 3.06962 3.36699 2.80599 3.42526
では、実際に推薦してみましょう。適当にユーザーを抽出してみます。
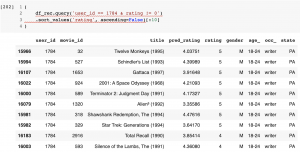
df_output = pd.read_csv('./output.txt', header=None, names=['pred_rating'])
df_rec = df_ml_test.copy()
df_rec['pred_rating'] = df_output['pred_rating']
df_rec = pd.merge(df_rec, df_movies[['movie_id', 'title']], on='movie_id', how='left')
df_rec = df_rec[['user_id', 'movie_id', 'title', 'pred_rating', 'rating', 'gender', 'age_', 'occ_', 'state']]
df_rec.head()
この方(Pennsylvania在住の男性(18-24歳)、職業(writer)の映画評価とモデルの予測は以下のようになっています。確かに高評価の映画に対しては、それなりの高いスコアを予測しています。
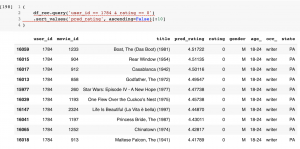
このユーザーがまだ評価していない映画に対する予測スコアが高い順に推薦してみます。
推薦方法の改善
しかし、映画のタイトルだけだと今ひとつピンとしませんね。これで映画を見るというアクションにつなげることは難しそうです。(UXとしてはダメダメですね)
実は、GroupLens では、 MovieLens 20M YouTube Trailers Dataset というものも公開しています。これは、Youtube で公開されている trailer の ID が記録されています。これにより推薦した映画の trailer へのリンクを作成することができます。
!wget https://files.grouplens.org/datasets/movielens/ml-20m-youtube.zip .
!unzip ml-20m-youtube.zip
df_youtube = pd.read_csv('ml-youtube.csv')
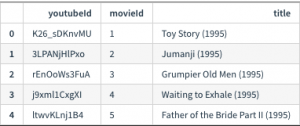
この ID で、https://www.youtube.com/watch?v=ID をアクセスすれば対応する映画の trailer が見れます。推薦リストと一緒に link を表示しても良いですが、毎回クリックする必要があり、タイトルだけではどのような映画か判らない場合、クリックへのハードルが非常に高くなります。そこで、いっそのこと、IFrame で YouTube player を埋め込んでしまいましょう。ちなみに、Jupyter Notebook などでは、IPython.display.YoutubeVideo という module に video ID を与えるだけで簡単に表示ができます。(こんなものがあったなんて初めて知りました。)
from IPython.display import YouTubeVideo
YouTubeVideo('K26_sDKnvMU')
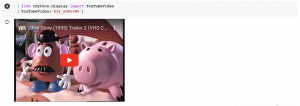
それを 3 x 3 のタイル状に並べてみました。
おお、なんだかそれっぽい感じになりましたね。
これなら
- アイテムの推薦
- アイテムに興味を持つ
- クリック
- 視聴(Conversion)
というフローが進みそうですね。
さいごに
今回は、推奨システムの実践編の続きとして、Factorization Machines (FM) と、その発展系である Field-Aware Factorization Machines (FFM) の紹介と MovieLens Dataset を利用した映画の推薦のデモを行いました。ただ、映画のタイトルだけでなく、YouTube で公開されている予告編を表示することでより(多少なりとも)実践的な推薦ができたと思います。
今回の FFM ではユーザーの属性、映画のジャンルを特徴量に利用しましたが、ユーザーの個人情報などは今後は利用が難しくなると思われるので注意が必要です。実際に、MovieLens Dataset の最近のものでは、これらの性別年齢などのデータは含まれておりません。その代わりといってはなんですが、 MovieLens Tag Genome (https://grouplens.org/datasets/movielens/tag-genome-2021/) という tag の情報が公開されています。今回は利用しませんでしたが、映画の内容や評価についての情報が含まれており興味深いデータです。
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
参考資料
- 「推薦システム実践入門」(https://www.oreilly.co.jp/books/9784873119663/)
- 「Grouplens」(https://grouplens.org/datasets/movielens/)
- 「Factorization Machines」(https://ieeexplore.ieee.org/document/5694074)
- 「Field-aware factorization machines (FFM)」(https://dl.acm.org/doi/10.1145/2959100.2959134)
- 「Field-aware な Factorization Machines の最新動向」(https://qiita.com/guglilac/items/6c8971d27c143e2567a4)
- 「xLearn」(https://github.com/aksnzhy/xlearn)
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD