AIで株をやる!~株の売り買いを深層強化学習で予測~
はじめまして、次世代システム研究室のK.S.(女性、外国人)です。
今回は「深層強化学習で株の売り買いの予測ができるか」、にチャレンジしてみました。これについて紹介したいと思います。
初めてのブログ投稿ですが、どうぞよろしくお願いしますね。
「残業が大変だ!」 「働きすぎて疲れた!」 「働かずにお金が勝手に増えないかなあ」、と思うことはありませんか? それなら、お金を増やす方法を知ることが必要です。
お金を増やす方法の一つは株式投資です。たくさん株で儲かったら、どんどんお金が増えていきます。しかし、株の売り買いはそんなに簡単ではありません。株価は上がったり下がったりするので、いつ買っていつ売れば儲けられるかを予測するのは難しいです。なので、今回は過去の株価情報を使って、株の売り買いを予測する技術をご紹介します。
最近、人工知能(AI)が進化してきて、人が見出せないことをデータから見つける専門的能力が高くなってきました。2015年にNatureという世界トップクラスの総合科学誌でも紹介されたように、機械学習のひとつである「深層強化学習」という人工知能(AI)の学習技法を利用して、全ての行動を最適化し、ゲームで人間を打ち負かすことができるようになりました。そのあと、それらに関係する技術も圧倒的に発展してきました。そんな深層強化学習で、ゲームに代わって、株で勝つことができないかと考えました。
今回のブログの目的は、最先端の深層強化学習を用いて、株式市場の情報を学習し、株の売り買いで儲けることができるかチャレンジしたことをみなさんと共有したいと思います。
このブログの内容は、以下のとおりです。
① 深層強化学習とはなにか? それを使ってなにができるのか?
② 株式市場のマーケットインパクトとはなにか?
③ 深層強化学習で株の売り買いを実践した結果。
深層強化学習と株式市場の基本知識がある場合は①と②を飛ばして、③からを読んで下さいね。
1. 深層強化学習
深層強化学習は深層学習と強化学習を組み合わせたものです。人工知能の分野では、新たな研究分野と言われているようです。深層強化学習の基本知識ついては以下のサイトのブログで説明がたくさんありますので、興味がある方はそれらも参考([1] [2] )にしてみて下さいね。ちなみに、英語を読むのが好きな方はこのサイトの説明がわかりやすいですよ。今回は、AI初心者向けに説明したいので、複雑な数式を抜き、深層強化学習をイメージできるように、簡単に書かせていただきますね。がっつり読みたくて、さらに興味のある方には科学論文がおすすめです。
1.1. 強化学習 (Reinforcement Learning)
強化学習は機械学習の一つで、AIが結果の良い報酬を期待し、行動を最適化するように、試行錯誤を重ねる学習です。強化学習は特定の環境において、状態、行動、報酬の3つをもとに学習を行います。簡単に説明したいので、図1を見ながら、お読み下さい。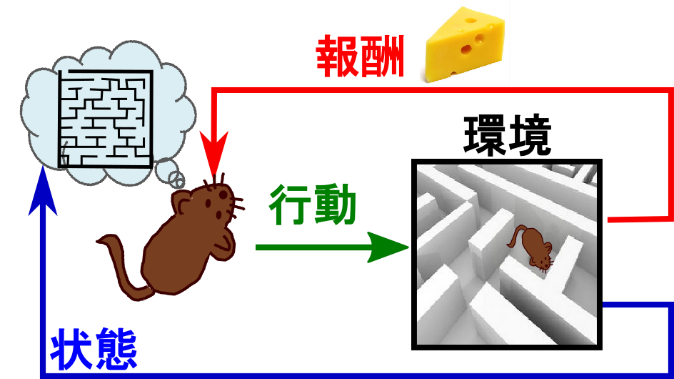
まず、学習して「行動」するものをAgentと呼びます。今回はAgentをねずみにします。そして、「状態」はねずみのいる位置、「報酬」はチーズに置き換えます。そのねずみが迷路という環境の中にいます。迷路で自分のいる位置(状態)から、左右どっちの方向に進むとたくさんチーズ(報酬)をもらえるのかを考えます。正しいルートを進めば、報酬がもらえます。間違ったルートにいったら、報酬がもらえません。迷路(環境)に関する情報が一通りわかれば、環境モデルを作って多くの報酬をもらえるように行動を最適化できます。
ただし、最初に述べたように、今回の目的は株です。株の環境は迷路ではなく株式市場です。一社の株価データ(状態)の取得は簡単ですが、株式市場全体のデータ(環境)の取得は困難です。そのときに、Q-learningという強化学習の代表的なアルゴリズムが使えます。Q-learningは環境情報を必要とせず、最終的な報酬を最適化できます。
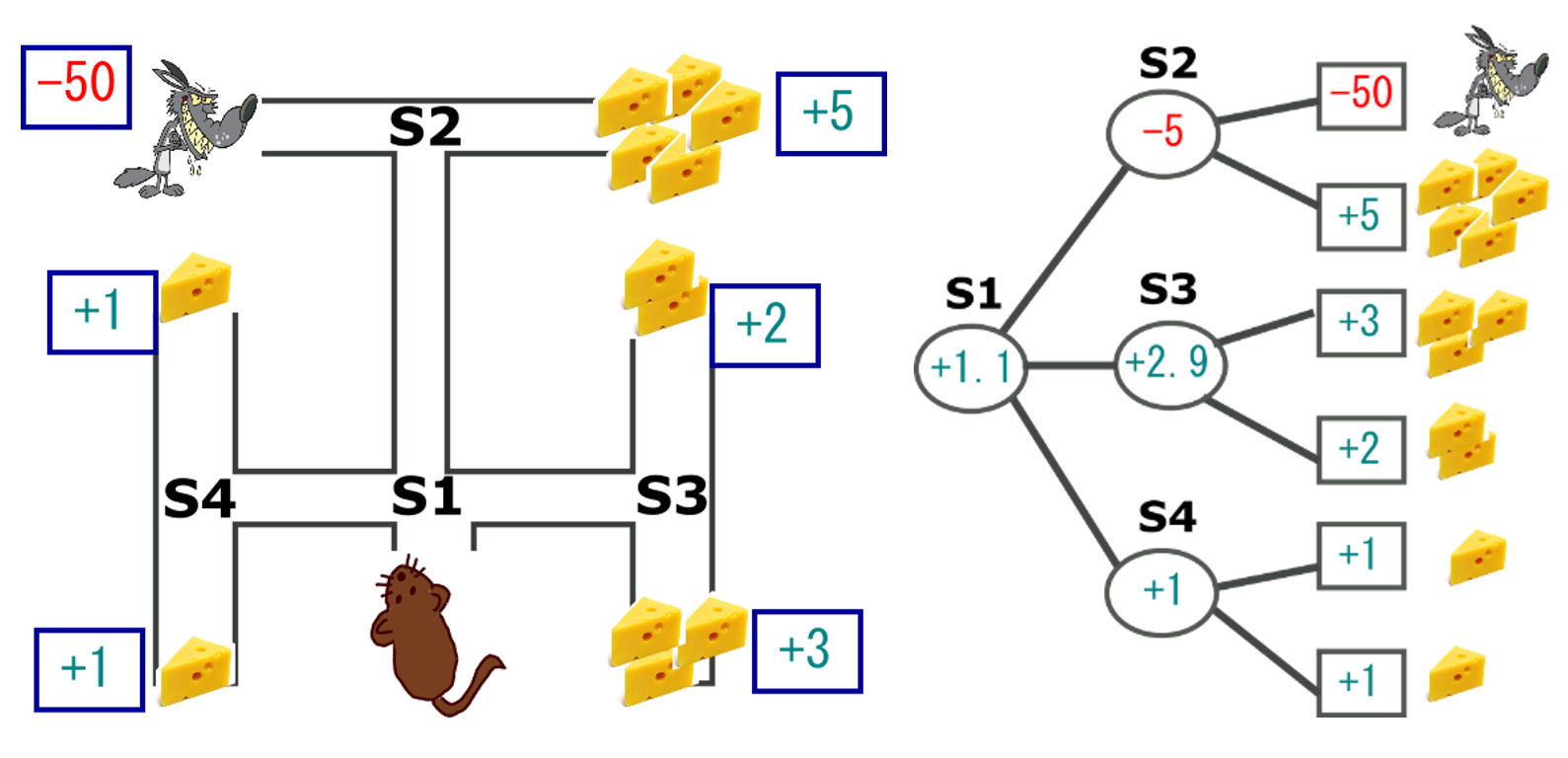
図2のようなルートでいくつかの報酬をもらえる位置(状態)だと、その全部の組み合わせを計算して、よりよい報酬をもらえるルートを見つけることができそうですね。しかし、実際はもっとたくさん状態があります!!!
そこで、実際に使われているQ-learningの学習ステップは下記の通りです~。
① ランダムに行動します(学習)。そのランダムのルートで最終報酬を記録します。
② 報酬が高い経路の近くを選択して行動します。新たに得られた最終的な報酬を記憶します。
③ 最終的な報酬がよくなると期待し、繰り返し、繰り返し、学習します。
ねずみちゃんと迷路のシステムだったら、どうにか学習できそうですが、株価にすると、株価(状態)データがたくさんありますね。とても複雑なデータとネットワークになって、学習が難しくなります。その複雑なネットワークを処理するためには、深層学習(セクション1.2に参考)を使います。
1.2. 深層学習(Deep learning)
深層学習(Deep learning)はニューラルネットワークという脳神経系をモデルにした情報処理システムです。深層学習によって、複雑なネットワークで複雑なパターン認識問題を解く方法を学習できるので、複雑処理が可能となります。今回は詳細を説明しませんが、興味がある方は他のデータサイエンティストのブログを参考にしてくださいね。また、深くに勉強したい方は有名なAndrew Ng先生のコースを体験してみて下さい。
1.3. Deep Q-Network(DQN)の追加機能
Deep Q-Network (DQN)は深層学習(Deep Learning)と強化学習(Q-learning)を組み合わせた深層強化学習の一つです。Natureで発表されてからDeep Q-Networkについて、認識度が高まり、その関連技術と共に大きく発展しています。今回は学習精度を向上するため、二つの追加機能を紹介したいと思います。A. Prioritised Experience Replay (参考文献)
ランダム処理を改善する機能です。優先順位を付けてサンプリングし、学習の進行が期待されるところを、頻繁にリプレイ(再生)します。例えば、図2(右の図)の一番上ルートに行ったら、ねずみが食べられますので、行かないように低い優先順を付けています。結果、学習が早くなるし、最終報酬もよくなります。B. Dueling Architecture (参考文献)
DQNの学習を改善する機能です。最終的な報酬(Q)に対する影響度(A)と、状態ごとの報酬(V)を組み合わせて学習します。例えば、従来のアーキテクチャは図2(右の図)のように、それぞれの状態で報酬(V)をもらっていきます。しかし、S4状態みたいに、どう行動しても、最終的な報酬に影響ないです(どう行動しても最終的な報酬は+1)。ここで、この行動は大切ではないですよということも考えます。なので、デュエリングアーキテクチャではそれぞれの状態のときの報酬に加えて、影響度も一緒に考えます。影響度が高いとき(S2状態みたいに)にきちんと考えて行動するので、学習精度がよくなると期待できます。これらの科学論文によると、この二つの機能を使えば、学習時間が早くなり、学習精度も高くなることが期待されるので、今回の株の売り買いも、これらの機能を使って行いました。
2.株式市場:マーケットインパクト
株式市場は、証券会社(例えば、自撮りしながら旅するガッキーさんが主演するGMOクリック証券)を通して、株を売買するところです。株式市場では、大勢の投資家たちが売り買いしています。会社業績などによって、投資家の心理が変わり、買い取引量と売り取引量も変わっていきます。その取引量の変化は株価に影響します(図3)。ちなみに、実際に売買された取引量は出来高と呼ばれますので、これから出来高という言葉を使いますね。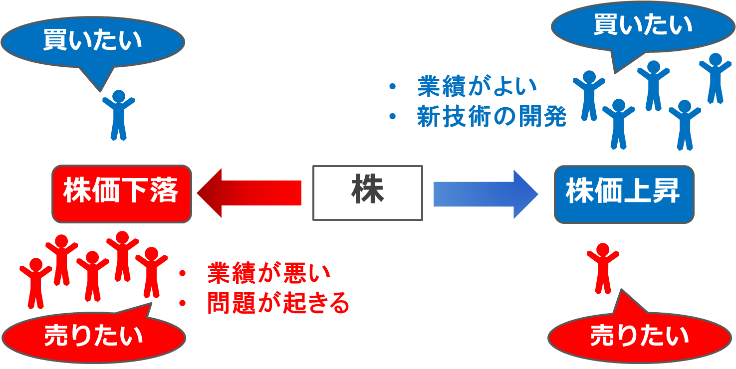
例えば、会社の業績がよいとき、たくさんの投資家が買いたくなり、売りたい投資家も少なくなり、株価が上昇していきます。逆に、会社の業績が悪いときは、その会社は信用を失い、投資家は株を売りたくなり、株価が下落します。このような、出来高と株価の関係は マーケットインパクトといいます。マーケットインパクトが発生する時にその出来高を見ることで、ある程度株価の変動を予測できる可能性があります。
3.深層強化学習で株の売り買いの実践
このセクションは出来高と株価の変化(マーケットインパクトの情報)を使って、最先端の深層強化学習で売り買いの実践し、収益が上がるかどうかの結果を検討します。深層強化学習の流れは下記のフローチャート(図4)になります。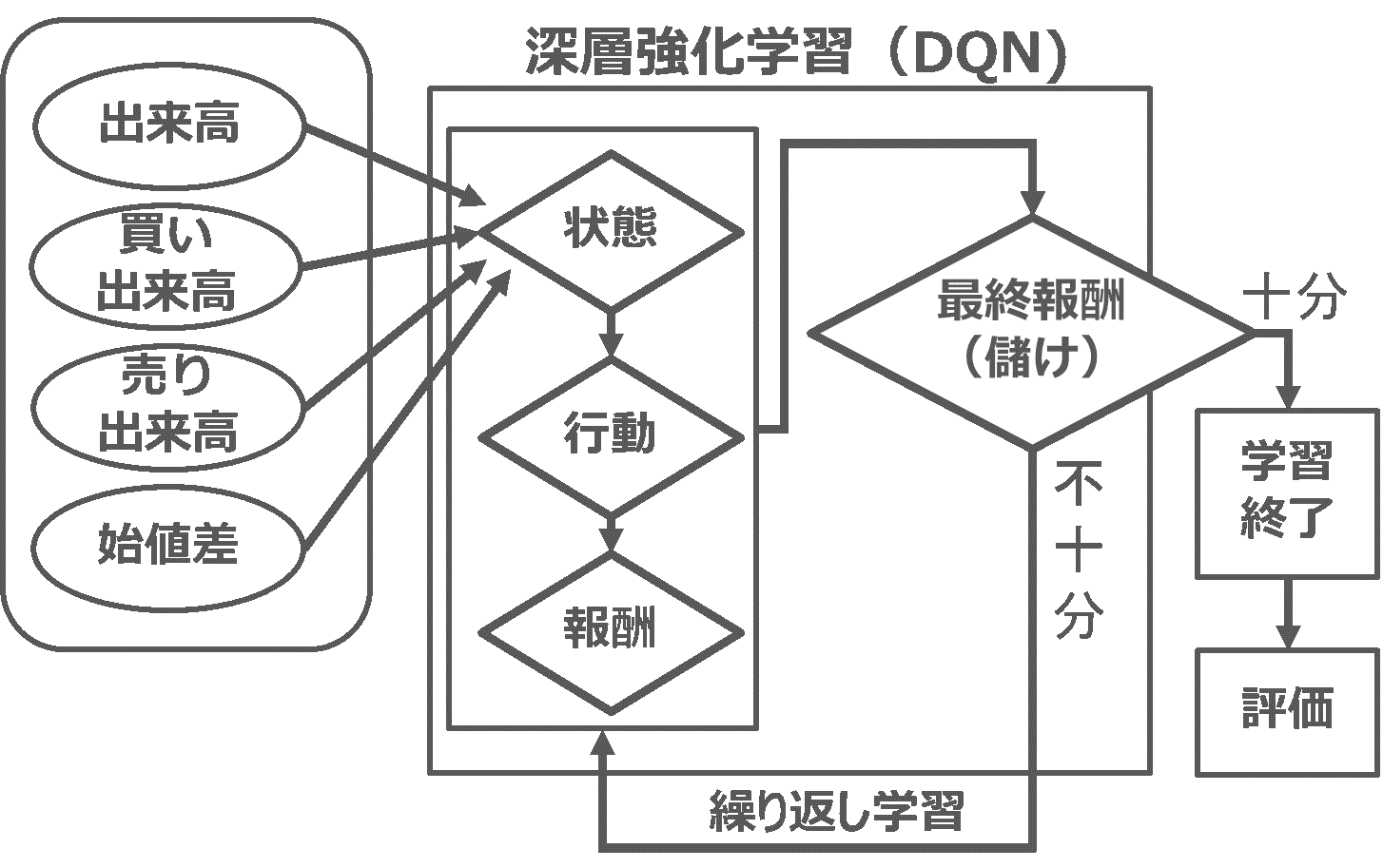
3.1.データ準備
出来高と株価はYahooファイナンスからダウンロードすることができます。今回はDeep-Q-Networkを用いて、出来高と株価の変化を予測することが出来るかを検討するため、変動が大きい大型株を選択しました。例として2016年の日産自動車(7201:大型株)のデータを使いました。だたし、一つ問題があり、Yahoo ファイナンスでダウンロードできる出来高データは、買いか売りの判別が出来ません。そこで今回はRSIという相対力指数を買い出来高の割合と見なして、全体の出来高から買い出来高と売り出来高を算出します。
ちなみに、RSI(Relative Strength Index)とは、ある期間の値動き(上昇幅と下落幅の合計)のうち、上昇幅が占める割合です。今回は期間を5日間で計算しましたので、下記の式になります。
3.2.深層強化学習の準備
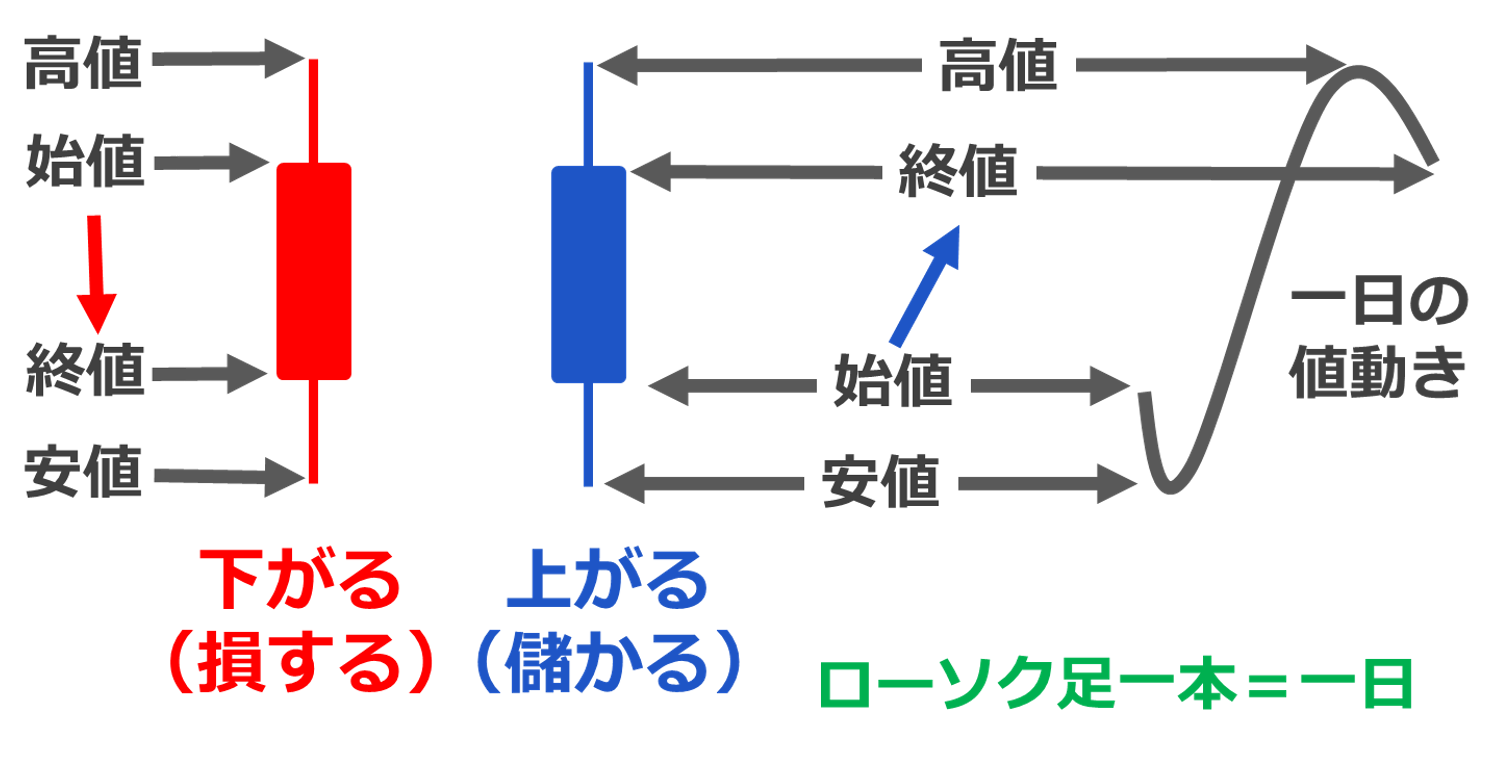
今回は一日ごとに評価したいので、一日で儲けが確定する方法(デイトレード)で深層強化学習を実施しました。始値で買って終値で売りますので、日をまたがず儲けを確定させることができますよ。そうすると、儲けは終値マイナス始値になります。デイトレードを聞いたことがない方のため、図5で少し説明しますね。まず、株の世界で、株価の動きを表すときに、ローソク足を使います。ローソク足とは一定期間の株価の動きを1本の棒で表現します。ローソク足は始値・終値・高値・安値の4つの株価情報が含んでいます。今回は1本=1日です。一日ごとで始値から終値まで株価が動きます。今回はデイトレードで、始値で買って終値で売ります。青いローソク足は始値から終値まで株価が上がるので、買ったら、儲かります。逆に、赤いローソク足は始値から終値に株価が下がるので、買ったら、損します。
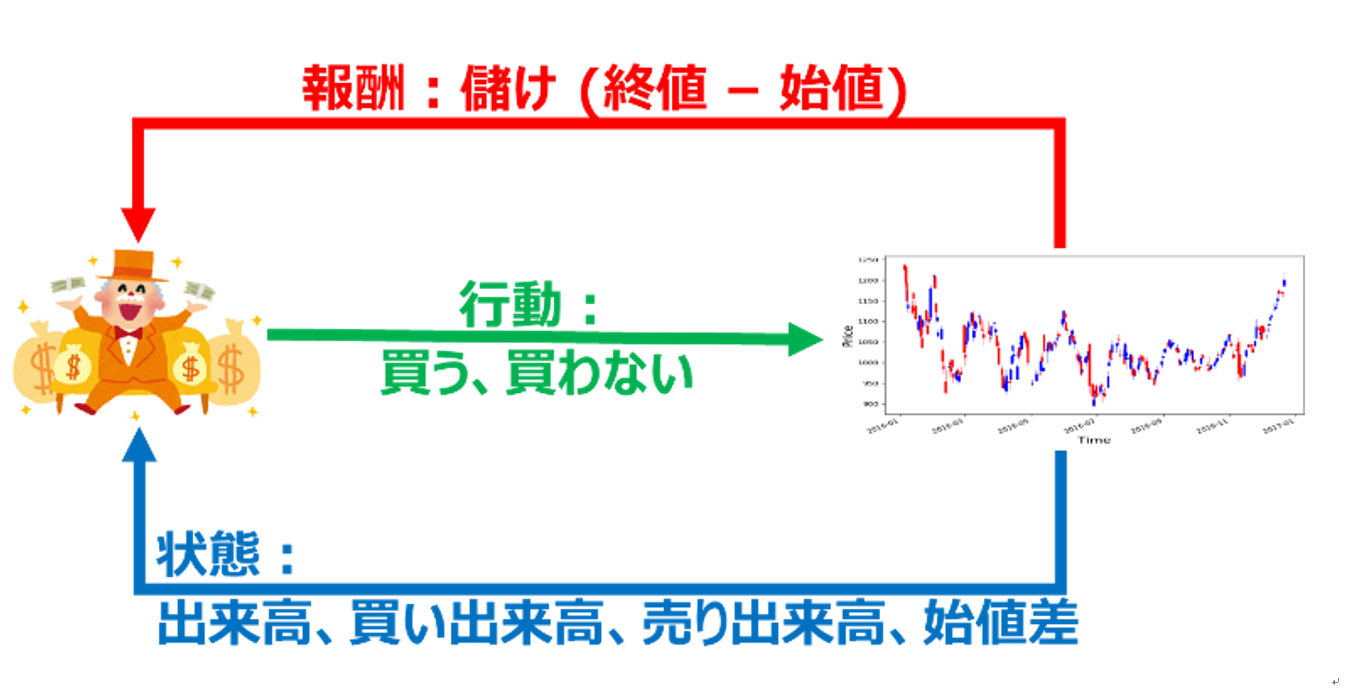
次に、デイトレードにおける強化学習に必要な3つのもの(状態・行動・報酬)ですね。強化学習をまだ慣れていない方は図6と図1の説明を見比べてみて下さいね。Agentは私たち(実はコンピュータでしょうか、笑)にします。私たちが、出来高と株価の変化(マーケットインパクト情報)などの状態を見て、行動します。ここで言う行動とは、買うと買わないになります。買った日に必ず売って儲けを確定させる前提としているので、売り行動をなくして学習をシンプルにしました。あとは、報酬ですね。もちろん、報酬は儲けですよ~。 買った日の終値マイナス始値をすると儲けになりますね。
3.3.検証環境
マシンスペックはGPU : NVIDIA GeForce GTX 1070を使いました。言語環境はPython 3.5です。ツールは3つのパッケージを利用しました。深層強化学習はOpenAI Gym、Prioritised Experience ReplayはOpenAI Baselines、Dueling ArchitectureはTensorFlowを利用しました。3.4.実践
3.4.1.精度確認
深層強化学習はランダム処理が入っているため、正確に同じ答えが再現できるとは限りません。そこで、精度を確認するために、計算を100回繰り返しました。図7は精度確認結果になります。左の図は深層強化学習と二つの機能(Dueling ArchitectureとPrioritised Experience Replay)の比較した分布です。横軸は儲けで、縦軸は確率です。まず、儲けを見てみましょう。儲けは0より大きい結果になりますので、深層強化学習を使って、株の売り買いが可能になることがわかりますね。念のため、深層強化学習をランダムトレードと比較してみました(右の図)。結果を見てみると、ランダムトレードより、深層強化学習のほうが儲け確率が高いですね。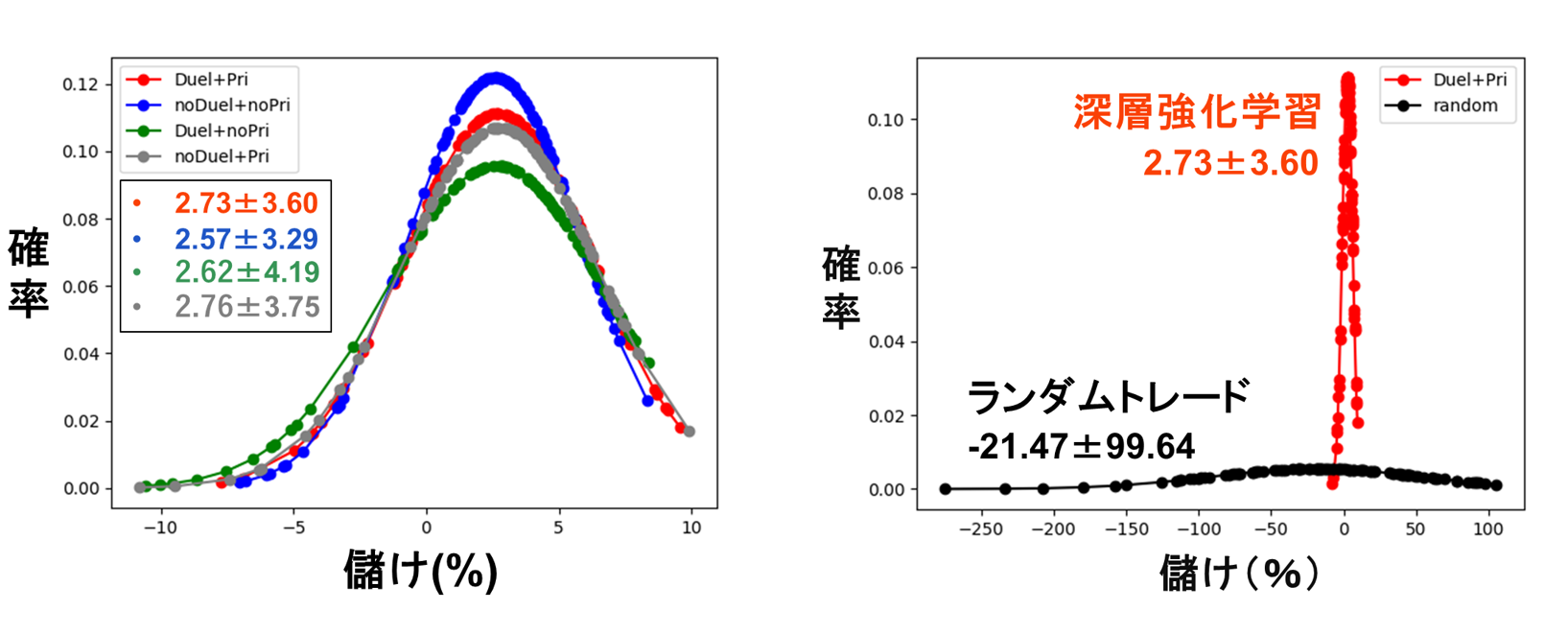
3.4.2.学習の結果
株の売り買いを予測する前に、学習データを使って学習効率を確認します。日産自動車の2016データを期間によって、学習用と評価用の2グループに分けて使いました. データ一年分の70%は学習データで、データの一年分30%は評価データです。その結果が図8です。学習回数が増えると報酬が増えているので、学習効果があることが確認できました。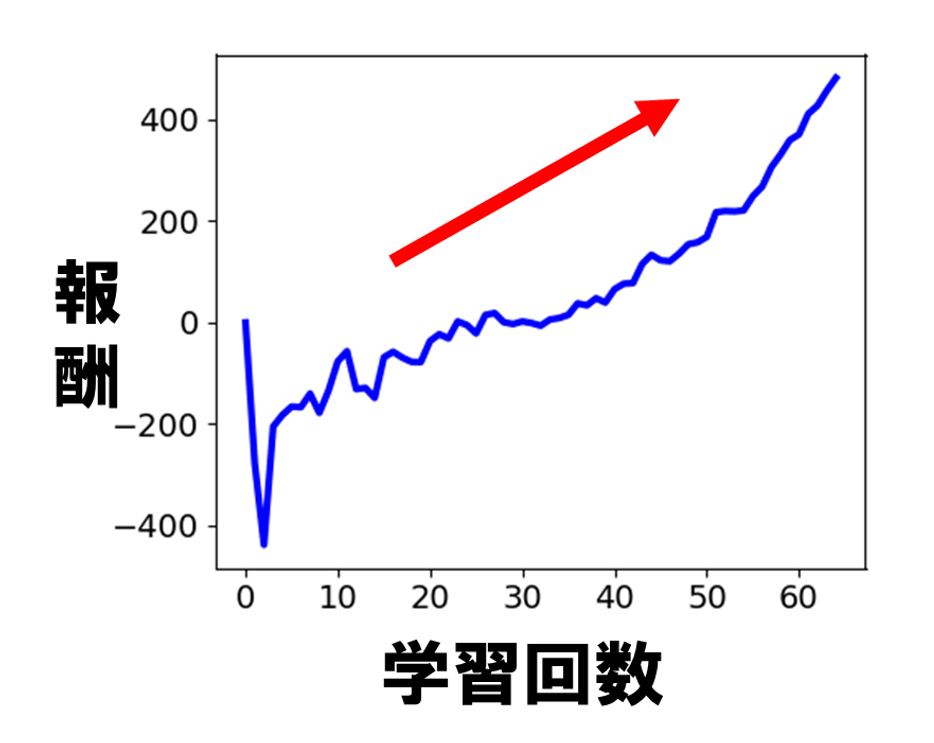
ちなみに、学習のイメージは下記のビデオを参考してみて下さい。報酬(収益)が高くなるのを期待し、どこで買ったら儲けれるのか、繰り返して学習していきます。
train_vdo from ks on Vimeo.
3.4.3.株の売り買い結果
このセクションは深層強化学習の評価です。上記に書いたように、評価のため、データの一年分30%を使いました。評価結果は図9になります。上の図は評価するための株価のトレードです。青いローソク足(3.2に参考)は始値から終値には株価が上がったときなので、上がる日で買うと儲けます。逆に、赤いローソク足は下がる日なので、買うと損します。下の図は深層強化学習で株を売り買いした結果です。青いローソク足の日は買って儲けた日、赤いローソク足の日は買って損した日、グレーは買わなかった日です。結果を見てみると、深層強化学習が効果的である事がわかります。計算すると、収益は3.41%くらいでした。ということは100万を投資すると、3万の利益がでますね。銀行の利子よりよさそうではないでしょうか。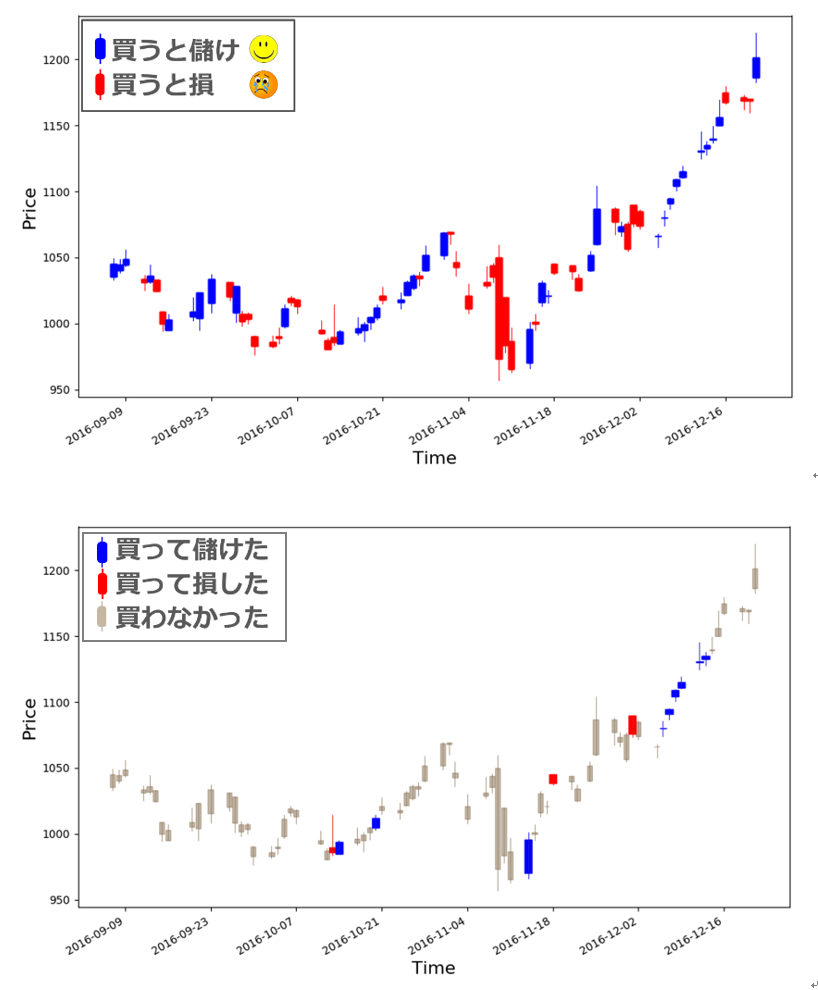
今までの話しを整理します。出来高と株価の変化(マーケットインパクト情報)をもとに、ある程度の大型株についての変動を、強化学習によって予測可能になり、株の売り買いすべきタイミングも予測できました。なかなかよかったですね!
まとめ
今回、試して色々なことがわかってきました。深層強化学習と株価を入力データとした売り買いの予測はまだ難しいです(結果は載せていないです)が、デイトレードで、株価と出来高の組み合わせからは、株の売り買いの予測が可能になってきました。ただ、まだ予測の精度と再現性を改良する必要があると思います。また、今回は手数料などを考慮していないので、その辺も改良した方がよいかもしれません。最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧募集職種一覧 からご応募をお願いします。私も、今年の5月までシステム生物学の研究者でしたが、ビックデータ解析など、今までとは違った新しい分野に興味を持ちその中でもAIの機械学習というテーマにチャレンジしてみたいと考え、弊社に入社しました。次世代システム研究室では国際的な環境で、毎日仲間と一緒に楽しく最新な技術を学んで、挑戦していくところが魅力的な職場です。興味がある方は是非ご応募下さい。みなさんのご応募をお待ちしております~。