ChatGPTにデータ分析をしてもらう
みなさんこんにちは、グループ研究開発本部 AI研究開発室のK.Fです。
日々の業務やミーティングにおいて、「昨日の新規インストールユーザのアクティブ率はどのくらい?」など、すぐに知りたいけど、データ分析者に依頼しないと分からないといった状況良くあるのではないでしょうか?あーそれ、ChatGPTにきいてみましょうよ!で解決できたらかっこよくないですか??今回は、ChatGPTにデータ分析をしてもらう方法ってどうしたらいいの?を調査して、簡単にデモアプリを実装してみました。
1. ChatGPTにデータ分析をしてもらう方法を調査
ChatGPTにデータ分析をさせようとする取り組みはすでに研究の分野でも行われており、中国のアリババが発表した「ChatGPTがどれくらい優れたデータ分析者なのか?」を評価した論文[1]があります。この論文では、GPT-4とシニアデータアナリストのアウトプットを、ベンチマークのデータセットによる評価指標と人間による評価指標の総合評価をもとに、GPT-4のアウトプットが人間に匹敵することを示しました。(とはいえ、GPTはウソも平気でつくので注意が必要ですとの注意書きもありました。)この論文のメインのポイントは、「GPT-4にデータ分析をさせるためのフローの整理」です。
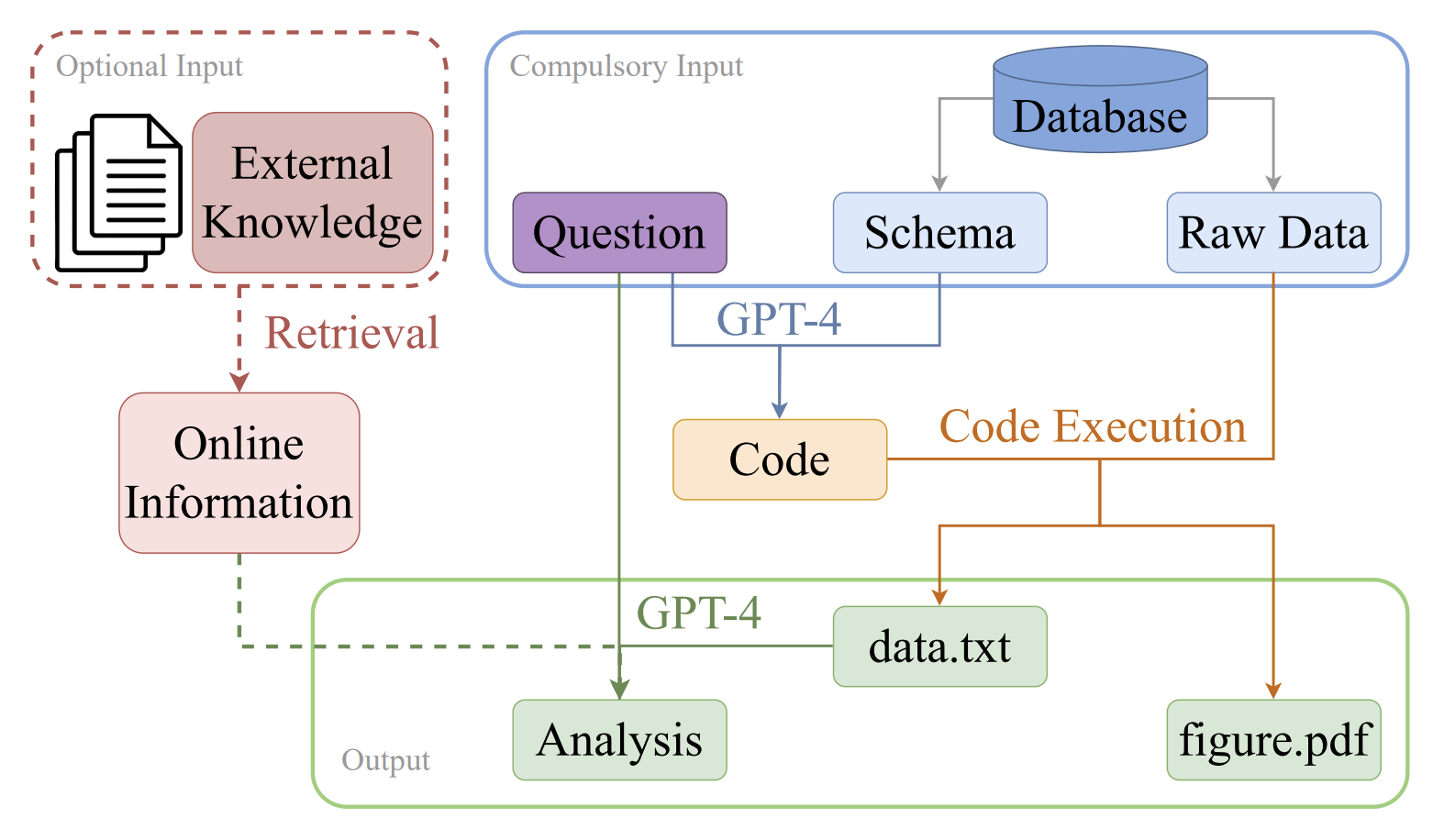
上図は、Questionがユーザの入力文章にあたります。まず、右上の青枠に注目すると、QuestionとSchemaをもとに、データの可視化を行うコードを生成しています。そのコードには、データベースからデータを取得する処理も記述されており、コードを実行することでdata.txtとfigure.pdfをアウトプットととして得ます。だたデータを抽出するだけではなく、インサイトを提供することがデータ分析者としての価値なので、この論文ではデータとインターネットから取得できる情報をもとに、最終的なインサイトを提供するところまでを担っています。
2. 論文を参考に、システムのユースケースを考える
このシステムのユーザは、必ずしもデータのスキーマや関係性に詳しくない人が多いでしょう。そのため、ユーザは自然言語で入力できるようになっているべきでしょうし、必ずしもテーブルの情報が問い合わせに充足する形で入力されることは難しいでしょう。システムとしては、ユーザの問い合わせに対してもっとも関連度の高いデーブルのスキーマをデータ抽出対象とするべきでしょうし、ユーザの問い合わせに必要な情報が不足している場合は追加の情報を要求するべきです。
システムの流れは以下のようになるのがよさそうです。
システムの流れ
- データベースのスキーマをJSONで吐き出す
- JSONファイルをOpenAI embedding ada-002 APIでベクトル化する
- ベクトルをvector_storeに保持する
- ユーザの問い合わせに応じて、documentサーチを行い、関連度の高いテーブルのスキーマ情報を取ってくる
- プロンプトに、ユーザの問い合わせとスキーマ情報、指示を記述し OpenAI gpt-3.5/4 APIに問い合わせる
- ユーザの問い合わせに対して、最適な答えを回答できない場合は追加の情報を要求するように指示する
- ユーザは所望のデータが出力されるまで、チャットで問い合わせる
3. 実装する
今回は、データの可視化までは行わず、SQLでデータの抽出するところまでが可能なのかデモ実装してみます。そこで、上の章のシステムの流れに沿って必要なパーツを考えていくことにします。
langchain
embedding APIを叩き取得したベクトルをvector_storeに格納し、ドキュメント検索を行うのは、langchainを使用するのが簡単です。langchainで、Chromaなどのベクターストアを利用してドキュメント検索する方法は少し検索するとたくさん情報がでてくるので、今回は省略します。弊部門のブログにLlamaindex(類似ツール)を使ってドキュメント検索する方法を紹介した記事があったのでご参考までに!
streamlit
ユーザの問い合わせに応じて、最適な答えを要求し問い合わせを繰り返すのはチャットUIがよいでしょう。チャットUIは、streamlitというpythonのライブラリを利用すると簡単に実装できます。
import streamlit as st
st.text("データ分析アシスタントに質問してみましょう!")
chat_container = st.container()
input_container = st.container()
with input_container:
with st.form(
"データ分析アシスタントに質問する",
clear_on_submit=True
):
user_question = st.text_area(
"データ抽出条件を教えてください",
key="input",
)
is_submitted = st.form_submit_button("質問する👂")
if is_submitted and user_question:
docs = self.docs_service.get_relevant_documents(
query=user_question
)
tables = self._format_docs(docs)
# chat apiに質問を投げる
answer = chain.run({
"tables": tables,
"questions": self._get_questions(user_question),
})
st.session_state.user_messages.append(user_question)
st.session_state.system_messages.append(answer)
with chat_container:
if st.session_state["system_messages"]:
for i in range(len(st.session_state.system_messages)):
message(
st.session_state.user_messages[i],
is_user=True,
key=f"{i}_user"
)
message(
st.session_state.system_messages[i],
is_user=False,
key=f"{i}"
)
のような簡単な実装で
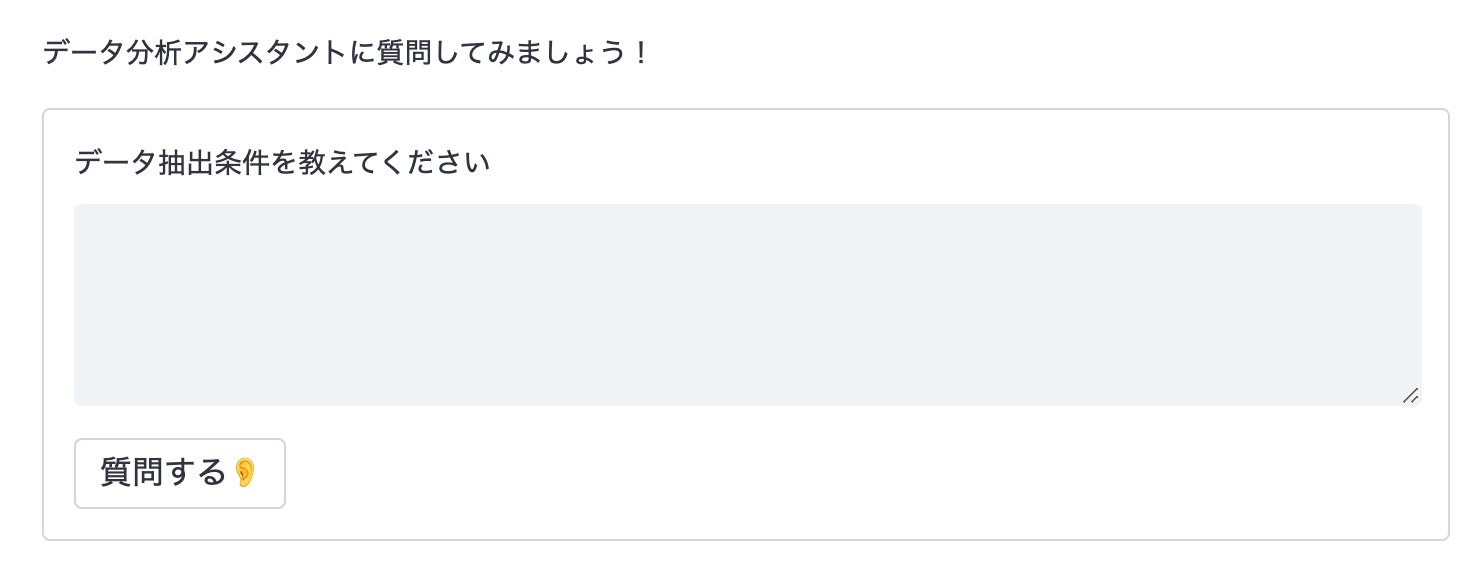
のようなChatUIが実装できます。ポイントは、チャット履歴の下に入力フォームが常に表示されるように、containerを利用して表示順序を固定することです。
プロンプト
筆者が担当するプロジェクトでは、サービスがGCP上で動いています。データ基盤もBigQuery上に構築されており、BigQueryにクエリを発行する前提で考えていくことにします。ユーザの問い合わせに対して必要な情報が足りない場合は追加の情報を要請するように、プロンプト内で指示する必要があります。プロンプト作成のコツは、プロンプトエンジニアリングガイドによくまとまっています。
以下のようなプロンプトを作成しました。ポイントは、指示やゴールなどを明確にsession分けして記述することと、jinjaのテンプレートを利用し動的に変数をrenderingできるようことです。
# ゴール
以下の文脈、指示、テーブルスキーマ、問い合わせに基づいて、適当なSQLを記述してください。
# 文脈
- あなたは、熟練で経験豊富なデータアナリストです。
- 問い合わせに対して、With句やJOIN句、window関数などを適切に利用して、SQLを記述することができます。
# 指示
- Google Cloud BigQueryのスタンダードSQLを使用してください。
- コメントや装飾は不要です。問い合わせの答えとなるSQLのみを記述してください。コードブロックで囲う必要もありません。
- 最高のアウトプットをするために追加の情報が必要な場合は、先頭に(確認)をつけて、質問を行ってください。
# テーブルスキーマ
{% for table in tables -%} - {{ table.name }}
```
{{ table.schema }}
```
{% endfor %}
# 問い合わせ
{{ questions }}
CloudRun
GCP上でstreamlitなどdockerで動かせれるツールの環境構築するには、CloudRunを利用するのが簡単です。社内環境のみで利用できるようにするには、cloud load balancingやcloud armorを利用してIP制限をする必要があり少し複雑になりますが、単純にデプロイするだけだとdockerfileを作って、デプロイコマンドを実行するだけで簡単にデプロイすることができます。BigQueryを利用するに当たって、注意するポイントは意図していないデータの更新事故を防ぐために、BigQuery読み取り権限のみを付与したサービスアカウントを作成します。
4. 実際どれくらい使えるの?
単一テーブルにクエリを発行するのはそこそこの精度でできそうです。ユーザの問い合わせにカラム名を入れてもらうとセレクトするカラムの精度があがりますが、表現がゆれるとうまく引っ張れないことが多いです。BigQueryのスキーマ情報のdescriptionにカラムの説明を自然言語で追加できるので、うまく活用すると精度があげられそうです。
複数のテーブルに渡って、JOIN句でデータを引っ張ってくるのはうまく行かないことが多いです。明らかに違うSQLを記述するのはまだいいのですが、あっていそうで少し間違ってるSQLを出されるのが一番厄介です。データ抽出からデータ可視化まで自動化する場合は、データ抽出条件を併記しすこしでも間違いがなくなるようにすると良さそうです。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集要項一覧からご応募をお願いします。 一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
参考
[1] Liying Cheng, Xingxuan Li, and Lidong Bing. Is gpt-4 a good data analyst? arXiv preprint arXiv:2305.15038, 2023.
[2] Prompt Engineering Guide, available at https://www.promptingguide.ai/jp, 2023