2021.10.08
ポストクッキー時代における自然言語処理技術の応用(キーワード・エンティティのCTR予測応用集)
こんにちは。次世代システム研究室のA.Z.です。
今回のブログは前回のブログ続き、ポストクッキー時代における自然言語の技術の応用について、紹介したいと思います。前回のブログでは、キーワードまたはエンティティのフィーチャ表現方法を紹介し、今回は実際に加工たキーワードの特徴量がctrの予測に入れたらどうなるか紹介したいと思います。
前回からのサマリー
インターネットユーザーの個人情報を保護法律が次々様々な国が確立されており、ブラウザー側に、それに合わせて、クッキーの利用制限も行います。これまでインターネット広告業界が対応しているサードパーティクッキーの利用はこちらの制限で、利用できなくなり、高い効果の広告配信が困難になります。
クッキの制限の問題を解決するために、大きく2つの方法のアプローチがあります。
- サードパーティクッキを利用する代わりに、新たな代用できるuidを発行し、ユーザーのトラッキングや広告の効果測定に利用する
- 国内だと、Intimate Merger社が提供しているIM Universal IDがあります。Googleは個人てくていできないトラッキング方法, Federated Learning on Cohorts(FLOC) が提案しました。欧州では、複数の大手メディアを連携し、同じidでログインできるように動きがありました
- しかし、こちらのアプローチは将来的にされに制限が厳しくなり、uidの発行精度や仕組みには新たな問題が出てくる可能性が高いです。一番最近では IOSの新バージョン機能で、ip adressが取れなくなることもあり、uidの発行には影響が出ると思われます。
- 完全にユーザーのトラッキングを行わずに、現在ユーザーが訪問しているページのコンテキストの分析を行い、マッチング率が高い広告を配信する
- ユーザーのトラッキングが完全に行わないため、将来的に、制限が厳しくなっても、影響されにくい
- 主に自然言語処理技術を利用するのは一般的です。直近の最先端の自然言語処理のモデルの活用はでき、高い効果が期待できると思います。
本調査は(2)のアプローチの中心に行っていました。また、自然言語処理の中に、完全に文章単位で解析を行うと、工数や運用コストもかかり、もっと小さい単位、キーワードをフォーカスしてました。
キーワードを利用するには今回の調査では直接単語として利用ではなく、先にエンティティに変換してからその利用する方針で行ってました。理由として、同じ単語でも違う意味を持つこともあります。そのまま単語のみを利用すると、その違う意味のケースが区別できなくなり、利用する前に、NER(Name Entity Recognition) 先に利用し、semanticのコンテクストから、ある単語はどんなものを表しているか明確になっています。また、判定したエンティティに対して、実際にモデルを入れるときにどのような方法で良いのか調べてみました。判定したエンティティは確率的な数値になる可能性があるため、autoencoderを利用し、特徴量のembeddingのほうが良さそうという結果でした。
キーワードをどうモデルに組み込むか
autoencoderを利用したため、featureのembeddingがctrの予測モデルと一緒に行うことが難しいようと思います。なので、今回、2つのモデル、autoencoder model, ctr modelを分けて学習を行います。具体的には、先にautoencoderのモデルを学習行い、
学習済のautoencoderモデルを利用し、ドキュメントのentityのembeddingを行います。
embeddingの結果、ctrモデルのインプットとして、利用します。
具体的に、以下の図になります。
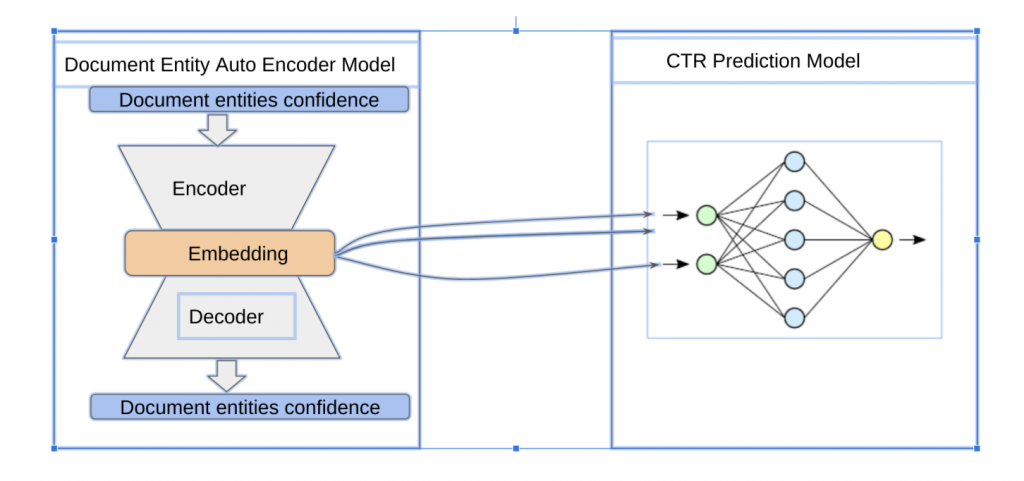
今回の実験はドキュメントのエンティティのフィーアチャーのみを利用したら、ctr予測ができるかという目的です。
具体的な実験の内容な設定は次になります。
データセット
今回利用しているデータセットは前回の検証と同じで、以下です:
https://www.kaggle.com/c/outbrain-click-prediction/data
今回利用するテーブルやデータについて、簡単に説明します。
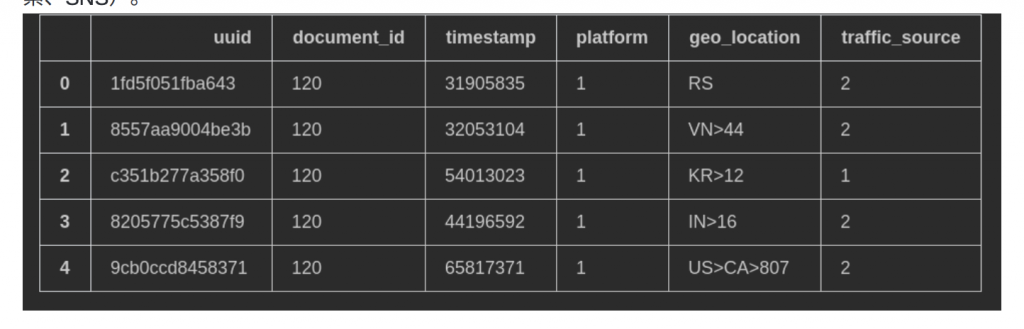
page views
page viewsは全ユーザーのアクセス履歴になります。platformというカラムはPC,SPなどを表すカラムです。traffic_sourceは該当のアクセスはどこから遷移されたかの情報です(例:サイト内の遷移、検索、SNS)。
events
eventsのテーブルはページご覧履歴の中に、クリックが発生したアクセスです。
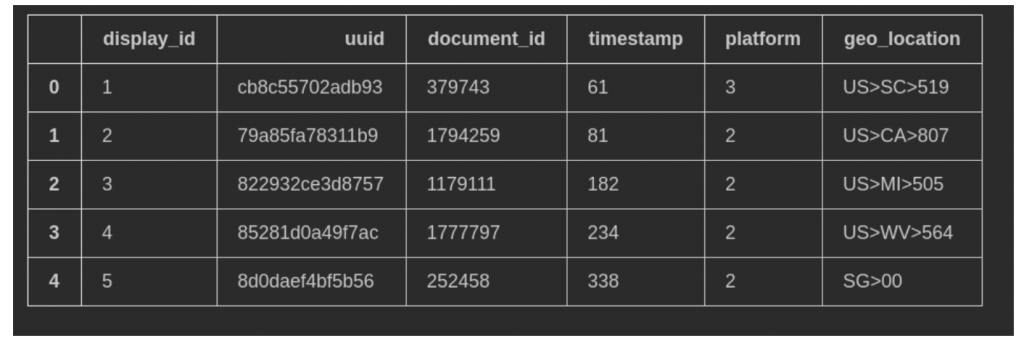
click_data
広告のクリックのデータになります。
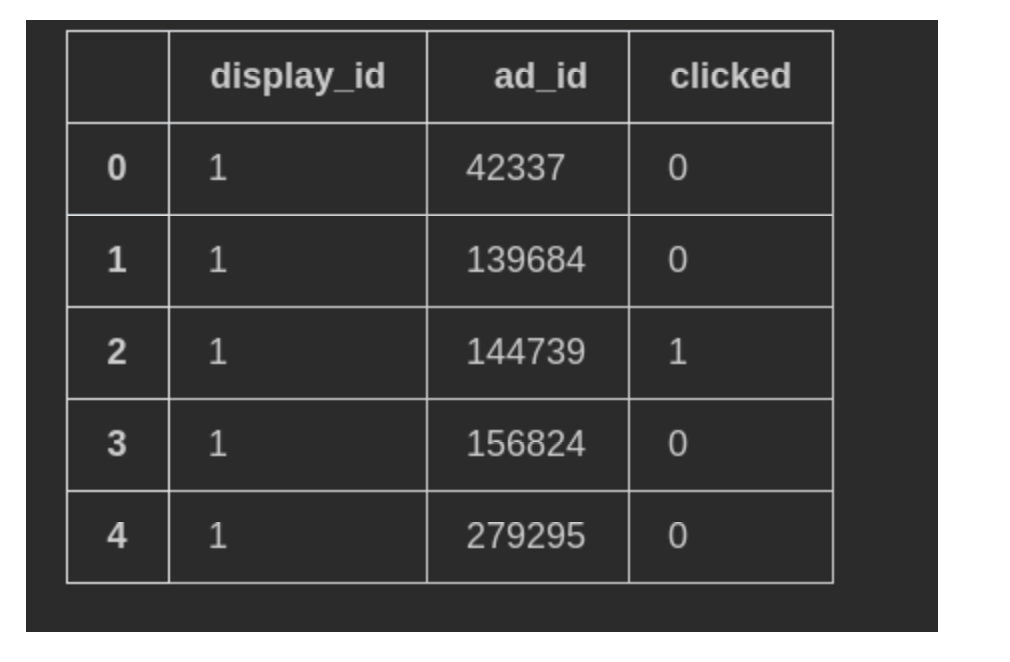
promoted_content
こちらは広告のmaster tableのように役割なっています。
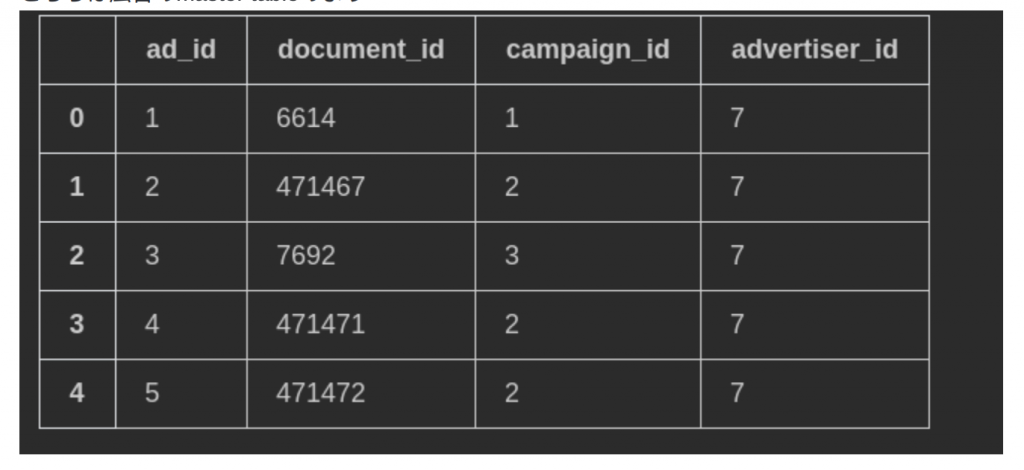
document_entity
こちらは今回のフォーカスした特徴量です。entity_id自体はhash化されたものとそれぞれにentityに対して、信用度のスコアーで表してます。
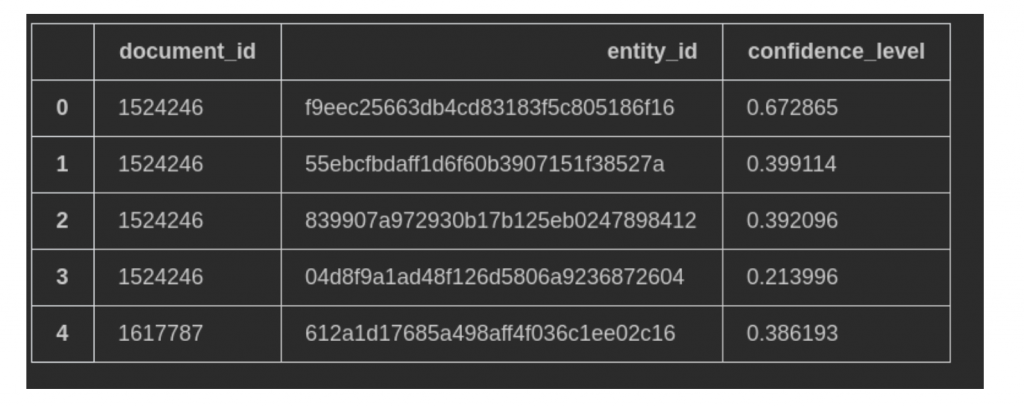
上記のテーブルの関連性は以下の図になります。
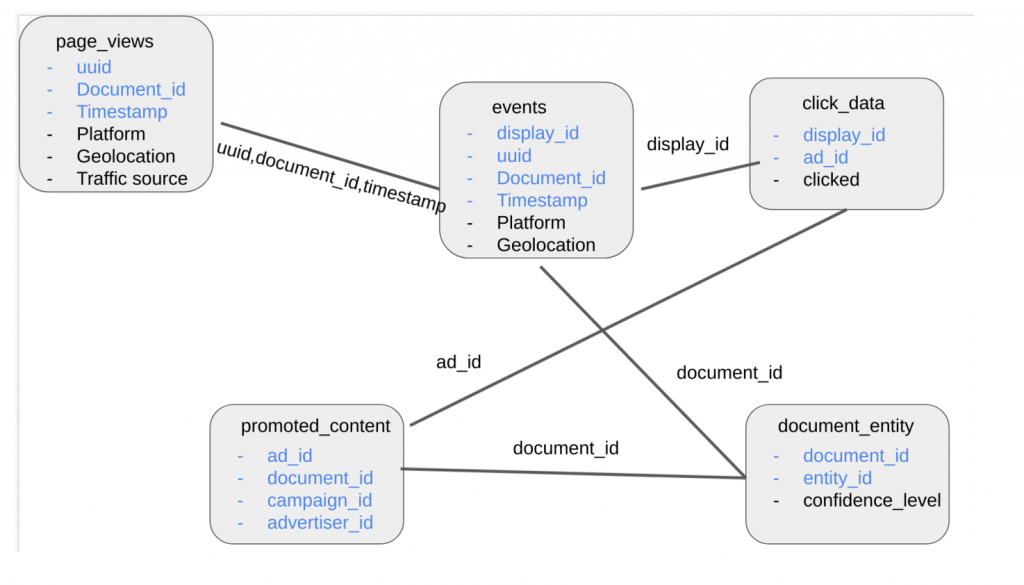
page_viewsはすべてのユーザーのアクセス履歴を含まれており、利用する場合は、ユーザーの行動履歴・ユーザートラッキングを利用すると同じ意味になっています。今回はpage_viewsのデータを利用せずに、eventsのデータをベースでfeatureの加工を行います。
加工したfeatureについて
今回は、eventsのテーブルをベースに学習データを作成しました。一つのeventsのdisplay_idに、複数広告が表示されることがあり、その場合は、広告(ad_id)ごとに、学習データを作成しました。
特徴量に関して、今回entityのフィーチャの検証のみのため、できるだけフィーチャを最小限を利用します。ユーザーがアクセスしているページと広告はそれぞれのドキュメントとして定義され、それぞれエンティティの情報を持っています。なので、今回は主に「アクセスしているページのエンティティ情報」と「広告のエンティティ情報」のみのフィーチャを利用します。具体的に変換したフィーチャは以下のとおりです。

モデル構造について
今回利用したモデルはかなりシンプルなモデルのみです。パラメータチューニングやモデルの構造の最適化などは軽く行いました。
Autoencoderモデルの構造は以下のとおりです。
Model: "autoencoder" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= sequential (Sequential) (None, 256) 1247744 _________________________________________________________________ sequential_1 (Sequential) (None, 4873) 1252361 ================================================================= Total params: 2,500,105・・・・ Trainable params: 2,500,105 Non-trainable params: 0 _________________________________________________________________
また、ctrモデルの構造は基本的にすべてFull-Connected Multi Layer Perceptron(MLP)を利用し、具体的な構造は以下になります。
Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_2 (Dense) (None, 100) 51300 _________________________________________________________________ dense_3 (Dense) (None, 50) 5050 _________________________________________________________________ dense_4 (Dense) (None, 30) 1530 _________________________________________________________________ dense_5 (Dense) (None, 10) 310 _________________________________________________________________ dense_6 (Dense) (None, 1) 11 ================================================================= Total params: 58,201 Trainable params: 58,201 Non-trainable params: 0 _________________________________________________________________
結果と考察

今回検証した結果、AUCのscoreは約0.56になります。実運用のモデルの精度から考えると、スコアーが低いですが、単独フィーチャとしては意味があると思います。少なくても、こちらフィーチャのみを利用した場合は、0.5 のAUCのラインを超えて、ctrの予測にはある程度意味があると思います。他のフィーチャと組み合わせ、またはモデルの最適化を行えば、実運用のモデルまでには持っていける期待があります。
まとめ
- 今回、ポストクッキー時代に向けて、CTR予測にキーワードやエンティティの応用について、紹介しました。
- 単独フィーチャーのみとして使うのはまだ精度が物足りないが、他のフィーアチャーと組み合わせやモデル構造の最適化を行ったら、もっと精度が改善できるではないと思います。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD