2022.01.12
マーケット情報不均衡性指標VPINの紹介とFXへの簡単実戦
はじめに
こんにちは、次世代システム研究室のC.Z.です。本文はマーケット測定指標であるVPINの解説、且つVPINを用いてリアルタイム予測の簡単な実験を行います。
前回はファイナンス分野でのマーケットのミクロストラクチャーに関する理論と研究を紹介しました(マーケットのミクロストラクチャーの紹介~information tradeの評価へ | GMOインターネットグループ 次世代システム研究室)。その中に、第三世代の代表的な理論として、informed traderのモデリングによりマーケットの不確実性を捉えるPINとVPIN指標が挙げられました。
直観的に、PIN(VPIN)は「マーケットの変動指標」としてVolatilityと似ている作用を持っていますね。一方、PIN(VPIN)と比べ、Volatilityがもっと解釈しやすいし、幅広いファイナンス理論に活用されています。だとすれば、PINを使うメリットはあるか、若しくはvolatilityより優位性が本当あるかという疑問が自然に生じます。
この疑問を明かすため、PIN(VPIN)だけではなく、volatilityの本質も少し探索する必要が出てきました。
Volatilityとorder flowのtoxicity
Historical volatilityとimplied volatility
volatilityは金融業界で特にデリバティブ金融市場でもっともよく使われている指標の一つである。Volatilityの種類を大きく分けると、historical volatility(もしくはrealized volatility)とimplied volatilityという2種類があります。
Historical volatilityは名前の通り、過去のプライス変更(リターン)からマーケット変動の激しさを測定する指標である。「過去」の生情報しか使っていないので、評価指標としてtime lagの性質を持つことが容易に想像できますし、本当のマーケット変動度合い(realized volatility)への予測には精度も悪いという結論も、数多くの研究に証明されていました。
一番シンプルなclose-to-closeボラから、色々な改善モデルが提案されました。例えば、Garman and KlassのOHLC Volatility、ParkinsonのHigh-Low Volatility、Yang and ZhangのOHLC Volatilityなどが挙げられている(volatility function – RDocumentation)。しかし、どちらの改善意図と言っても、基本はプライス平均のdriftやopening gapを解決する工夫となります。前回のブログで紹介したように、マーケットのミクロストラクチャー理論上で、これらのモデルは第一世代のモデルに過ぎず、プライスだけを情報として利用し、トレードプロセスの構成や戦略などが考慮されていません。
一方、implied volatilityはblack-scholes式を用いてオプションのプライスから逆算して得られたvolatilityになります。一見見れば、特別なところはないですが、使う用途のポイントとしては、単純な一つや数個のオプションチケットから計算することではなく、もっと網羅的で「マーケット全体」の数多くオプションらから集計し、indexとしてマーケットを評価する。そのなかで、「VI」いわゆる 「volatility index」がよく知られています。VIは実際にオプションから試算した指標ですが、デリバティブ商品に限らず、現物商品のマーケットへの評価もよく利用されています。
ファイナンスに関する研究のなかで、volatilityつまりマーケットの変動度合いへの予測は一つ大きいテーマになります。数多い研究はhistorical volatilityよりimplied volatilityのほうがもっと強い予測パフォーマンスを持つことを主張していました。なぜかといいますと、直観的でも容易に解釈できると思いますが、implied volatilityはオプションの提示価格、つまりmarket maker施策後のプライスとなり、ミクロストラクチャー理論の話をすると、プライスやボリュームだけではなく、取引者間のトレード戦略も考慮した指標となります。ゆえに、「VI」は金融機関でも一般投資家のなかでも幅広く使われている指標ではあります。
Order flowのtoxicity
次はようやくVPINの出番になります。Easleyはorder flowのtoxicityというコンセプトを提出しました。論文の定義は以下のようになります。
Order flow is toxic when it adversely selects market makers, who may be unaware they are providing liquidity at a loss.
いわば、market makerが意識していない情報があるため、market makerが「逆選択」されることになり、こういう逆選択されたフローがtoxicと定義します。ここの逆選択は、上記定義の通り、情報の不均衡から生じた現象です(取引一方がもっと多い情報を持っている)。
つまり、market makerがトレンド戦略を考慮し、リストをpremiumによりカバーしようとしても、order flowのtoxicityが存在するため、最後提示するオプション価格はまた評価足りない部分があります。VPINはorder flowのtoxicityを推定することで、情報の不均衡性を評価し、「VI」と比べよりよい指標という理論の基礎根拠はまさにここにあります。
VPIN(PIN)ロジックの紹介
PINの概要
前回のブログでも紹介したように、PINは以下の環境を仮定します。
- マーケットで2種類の取引者が存在する(情報ありと情報なしの取引者)
- Buy発動取引の取引量をBに、Sell発動取引の取引量をSに
- 取引プロセスの確率グラフ
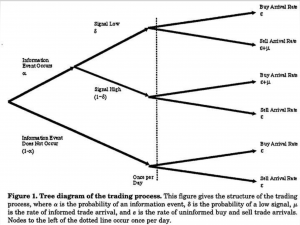
上記の条件でpoison分布を仮定し、最大尤数法で各パラメータの推定を行うことができる
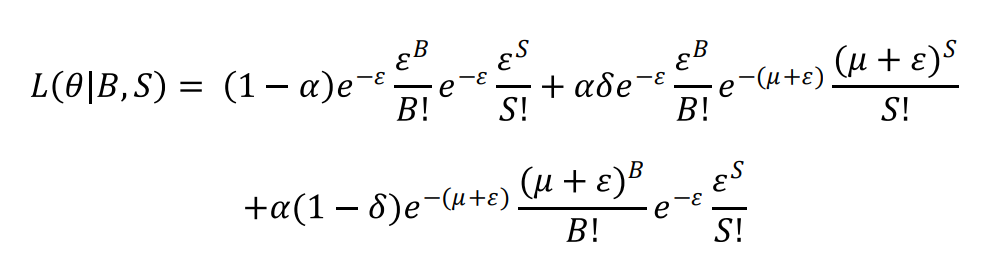
最後のPINは上記パラメータを用いて推計する
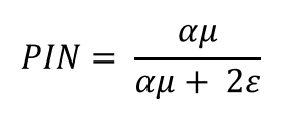
但し、PINの問題は、注文数が大量あり、上記パラメータの推定に時間がかかるなので、HFTデータの測定には使えないです。
VPIN
VPIN指標の測定対象はPINとほぼ同じ(つまり、情報不均衡性の高さ)ですが、パラメータの推定が不要となるので、リアルタイムの測定が可能になります。David Abada, José Yagüe(2012)がまとめたグラフを借りますと、主に以下の4つの点を変更しました。
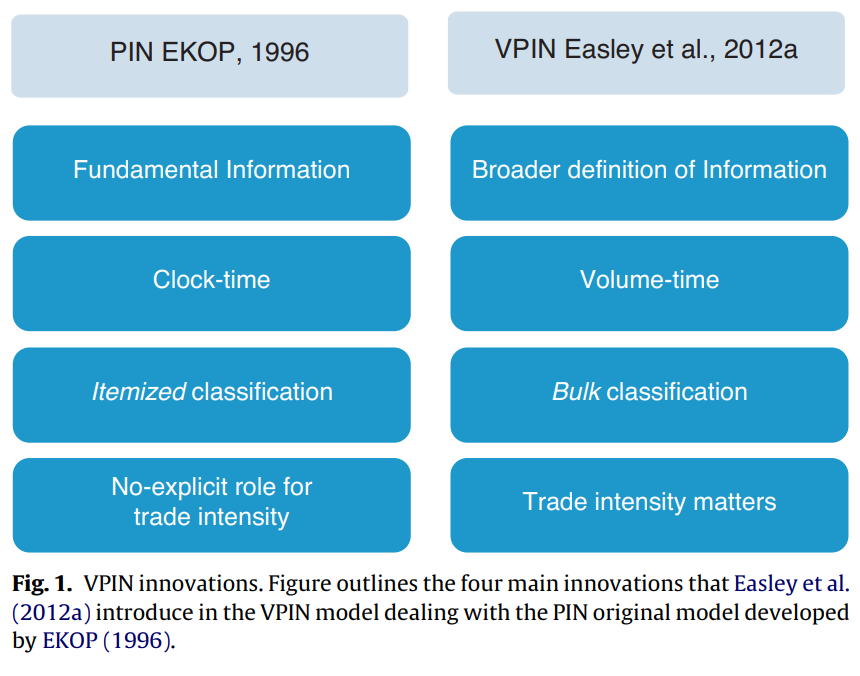
- 測定情報の範囲:VPINのほうがもっと広い(adverse selectionにsystemic 情報も含まれる可能性が高い)
- Time bar:VPINのほうがvolatility clusteringの問題がもっと低減できる(実際はclock-timeも可能)
- 売買の分類:PINのほうは個別の取引ごとに売買を分類し、VPINのほうは各volume bucketの標準正規分布から売買の分類を行う
- Trade sizeの考慮:VPINのほうはトレードの密度情報も入っている
VPIN具体の処理手順について、以下のイラストで例を挙げました。
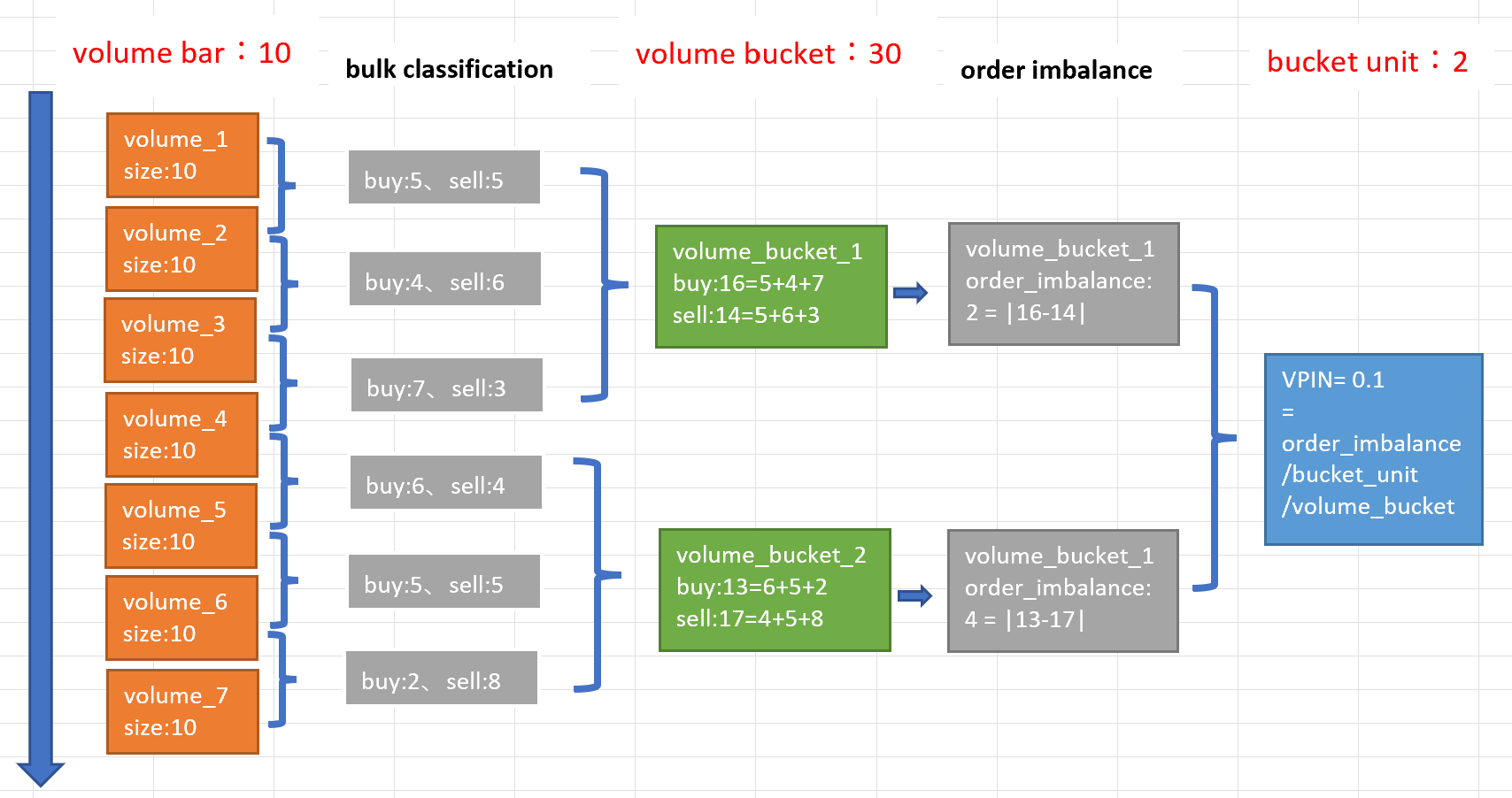
ここでは、bulk classificationは累計分布(標準正規分布など)で取引の売買発動の分類を行います。式から分かるように、buyかsellの取引量のいずれかが分かれば、もう一方のほうが簡単に計算できます。
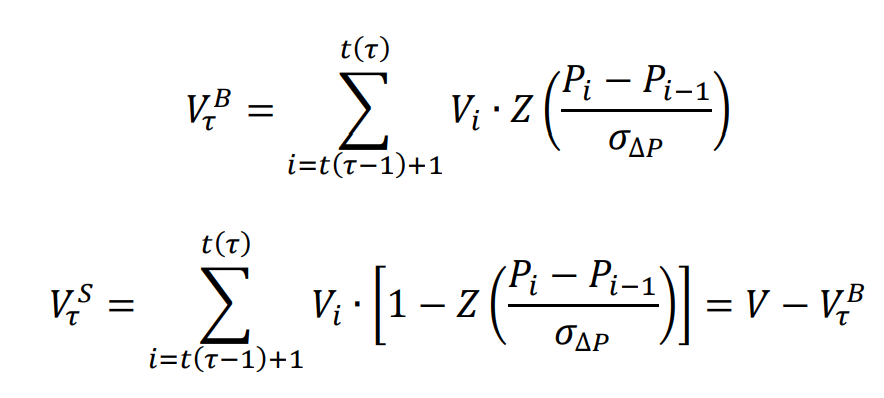
最後、VPINが以下の式で近似的に得られます。
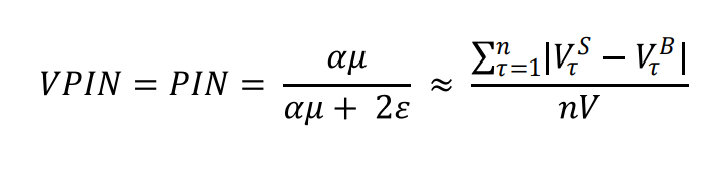
Easleyの論文の実証として、アメリカストック市場のフラッシュ・クラッシュを予測できましたことが挙げられました。その後で、VPINを巡って沢山な論争が続いて、特にVPINは「VI」と比べて優位性がないという批判が多いですが、Easleyまだ複数の論文よりVPINの有効性を主張し続けています。
FXへの実験
コンセプトの復習という意味で、理解しやすいVPIN作成ロジックのpythonコードを添付します。
まずbucketの作成から始めます。
# generate volume bucket with buy sell direction
delta_p_std = std(delta_p)
bucket_size = 1000
bucket_buy_dist = list()
bucket_sell_dist = list()
j = 0
while sum(volumes) > j*bucket_size:
return_norm = delta_p/delta_p_std
return_norm_b = return_norm[(j-1)*bucket_size+1:j*bucket_size]
zp = return_norm_b.apply(norm.cdf)
bucket_buy_dist.append(sum(zp))
j+=1
bucket_sell_dist = bucket_size - bucket_buy_dist
この後で、VPINを作成できるようになりました。
## VPIN
bucket_n = 100
VPIN = ()
i = 0
while i+bucket_n < data_length:
sells = V_sell_dist[i:i+bucket_n]
buys = V_buy_dist[i:i+bucket_n]
order_imbalance = sum(abs(sells-buys))
n_volumes = (bucket_n+1)*bucket_size
i+=1
VPIN.append(order_imbalance/n_volumes)
単純なVPINより、もっと敏感度が高いVPINのCDFも作ります。
# CDF of VPIN dist_position = VPIN/sum(VPIN) sorted_dist = sorted(dist_position) VPIN_cdf_ = np.cumsum(sorted_dist) VPIN_cdf = [x for _, x in sorted(zip(ins, VPIN_cdf_))]
最後で、以下の条件で簡単な実験行います。
- データ:Forex Historical Data Download in CSV or JSON – EA Trading Academy
- 通貨ペア:USD/JPY
- データ単位:1分
- time_bar:5分
- bucket_size:1000
- bucket_unit:5
データのvolumeの少なく、本当のマーケットはおそらく反映できないので、同じ原因で論文手法の設定値も使えないことになり、あまり有意な結果が見られていないです。
なお、各集計パラメーターの設定値により、VPINのパフォーマンスもかなり変わると思いますが、そのあたりの研究まだ少ないです。
最後に
VPINを用いてトレーニングシミュレーションしてみたいところでしたが、無料のvolume情報付のプライスソースがほぼなくて、またはvolume情報あっても一つの小さいECNならマーケットの実態が反映出来かねると思います。やはり検証するにはまず実データを入手しないといけないですね(大学院で結構高価そうなデータを使えました)。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD