2023.01.11
ML Pipeline CI/CD
こんにちは。AI研究開発室のS.Y.です。
今回は機械学習パイプラインのCI/CDを試します。
1.はじめに
GoogleCloudが公式リポジトリで、機械学習プロダクトのテンプレートを公開しています。VertexAIへのデプロイ機能はもちろん、kfpコンポーネントの単体テスト、パイプラインのEnd-to-Endテスト、Cloud BuildによるCI/CD、Terraformを使ったパイプラインスケジューリングの自動構成などの要素が入っています。
GCPで機械学習パイプラインの本格運用を開始するにあたり、CI/CDやスケジューリングの要素まで一発でデプロイできるのは非常に便利ですね。
リポジトリのREADME.mdにあるGetting startedでは、デモ用パイプラインのcompile → GCSへassetをコピー → VertexAI Pipelineへdeployしてrunという流れをコマンド一発で実現します。必要な機能を網羅したパイプラインが動いてこれだけでも十分感動的ですが、今回はこれとは別に、より実践編としてプロダクションの本番環境での使い方をしていきます。
テンプレート機能をフルで活用すると、最終的に下記のようなシステムがGCPにデプロイされます。
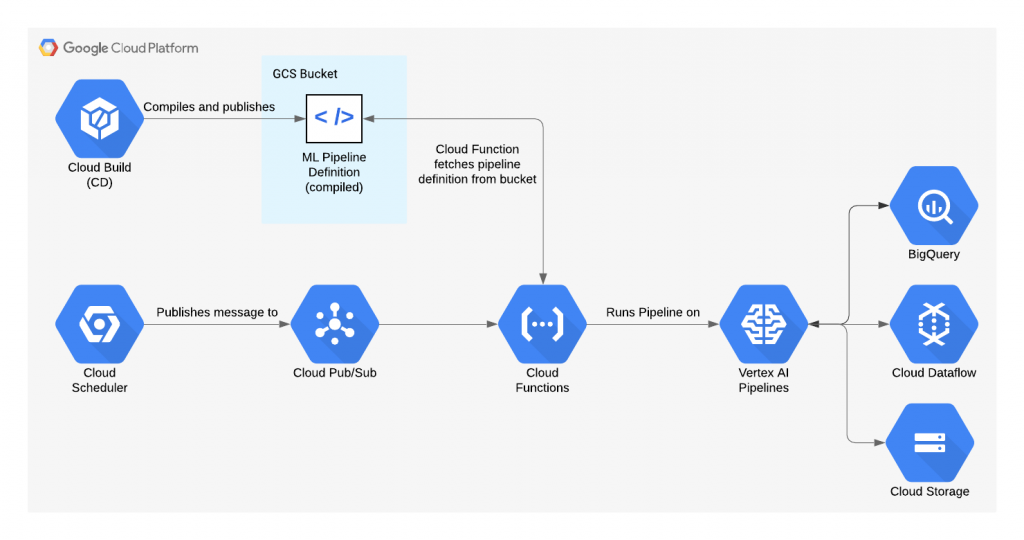
公式リポジトリより
2. プロダクトテンプレートの特徴
このプロダクトテンプレートを元にした機械学習プロダクトの運用の考え方について書いていきます。
2-1.運用環境について
このプロダクトテンプレートは、test/prod/cicdの3つの環境を使って運用します。それぞれに対応したGCPプロジェクトを作成することが推奨されています。
環境の使い分けについて最初は少し混乱したのですが、compileしたパイプライン定義のjsonファイル(VertexAI Pipelineにデプロイされるパイプライン定義)は、cicd環境のgcsに保存されます。このgcsのディレクトリ はrelease毎にバージョニングされていて、スケジューリング実行では任意のバージョンのパイプラインを指定できます。
prod環境には、terraform stateファイルが格納されます。(最初はprod環境にパイプラインのjsonが置かれると思った)
test環境には、terraform stateファイルの他、End-to-Endテストで実行されるパイプラインに関するファイルが格納されます。
2-2.実行環境の管理について
pipenvで行います。
pipenvではPipfile.locファイルを元にpip install --devで仮想環境を作ることができ、pyenv + requirement.txtよりも環境の管理・再現がしやすいです。
2-3.開発フロー
このプロダクトテンプレートを使用すると、開発からデプロイまでのフローは下記のようになります。
- パイプラインの開発・改修
- localで
mainbranchからfeaturebranchをcheckout featurebranchで、パイプラインを開発・改修- branchをmerge・pushし、Pull Requestを作成
- PRをMerge
- localで
- リリース
mainbranchにrelease tagを追加
- (optional) パイプラインスケジュールを変更
- test環境
- localで
mainbranchからtest-env-shedulingbranchをcheckout test-env-sheduling- branchをmerge・pushし、Pull Requestを作成
- PRをMerge
- localで
- prod環境
- localで
mainbranchからpred-env-shedulingbranchをcheckout - 以下、test環境と同じ
- localで
- test環境
2-4.ディレクトリ構成
こんな感じです。
.
└── root/
├── cloudbuild/ #Cloud Buildのtrrigerで呼ばれる構成ファイル
│ ├── e2e-test.yml
│ ├── pr-checks.yml
│ ├── release.yml
│ ├── terraform-apply.yml
│ └── terraform-plan.yml
├── envs/ #環境毎のterraform構成
│ ├── prod/
│ │ ├── main.tf
│ │ ├── variables.auto.tfvars
│ │ └── variables.tf
│ └── test/
│ ├── main.tf
│ ├── variables.auto.tfvars
│ └── variables.tf
├── pipelines/
│ ├── kdf_components/
│ ├── tensorflow/ #Tensorflowモデルのデモパイプライン
│ │ ├── prediction/
│ │ ├── training/
│ │ └── pipeline.py
│ ├── trigger/ #VertexAI Pipelineにデプロイするためのトリガー
│ │ └── main.py
│ └── xgboost/ #XGBoostモデルのデモパイプライン
│ ├── prediction/
│ ├── training/
│ └── pipeline.py
├── terraform/
│ ├── modules/ #各gcpリソース
│ ├── main.tf
│ ├── variables.auto.tfvars
│ └── variables.tf
├── tests/
│ ├── e2e/
│ ├── kfp_components/
│ ├── tensorflow/
│ ├── tfdv/
│ ├── trigger/
│ └── xgboost/
├── env.sh
├── Makefile
├── Pipfile
└── Pipfile.lock
3-5.パイプライン テンプレートの種類
パイプラインテンプレートは、ML FrameworkとしてXGBoost/TensorFlowの2種類、パイプラインの種類としてTraining/Prediction(Batch)の2種類の、計4種類あります。
BigQueryのpublicデータセットであるペンギンのデータセットを使ってモデルの作成/予測を行います。
Trainingパイプライン
どちらのML Frameworkにおいても、trainingパイプラインは以下の構成となっていてます。データload・データValidation・データ分割・トレーニング・評価・祝福(現行モデルとの比較)・デプロイを含んでいて、必要なコンポーネントは一通り揃っています。ちなみに、正規化等のpreprocessingはモデルに含まれています。
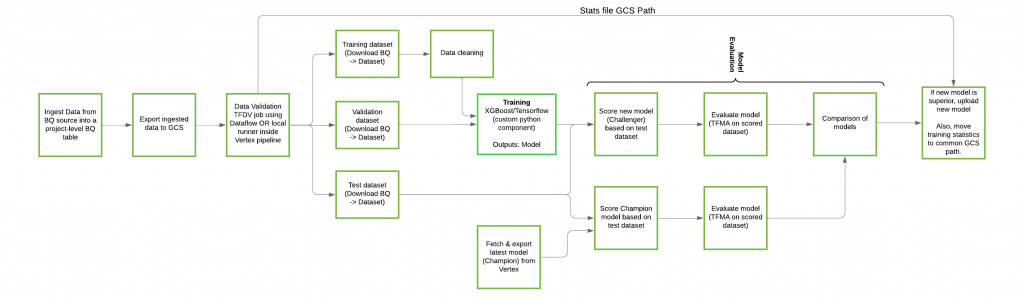
公式リポジトリより
predictionパイプライン
Predictionパイプラインの構成は以下の通りです。Trainingパイプラインで作成されたモデルを使って、バッチ予測を行います。
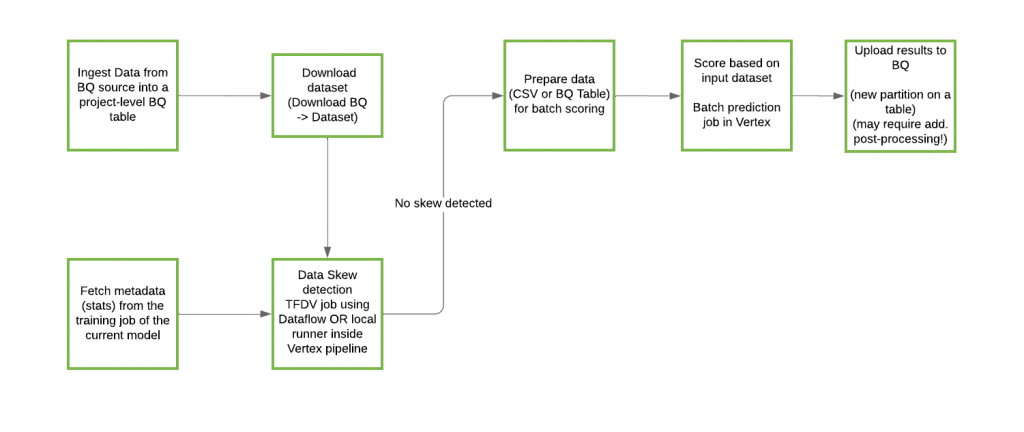
公式リポジトリより
3.セットアップ
実際にGCP上に機械学習プロダクトを構築してみます。今回は、各環境(test/prod/cicd)用のプロジェクトは分けず、単一プロジェクト内でそれぞれの環境用のGCSバケットを作ることで環境を分けています。
3-1.GCP側
Cloud Storageのバケット作成
上述の通り、各環境(test/prod/cicd)用のバケットを作成します。
Cloud Buildのトリガーを作成
mainブランチに対する各タイミングでキックされるトリガーを作成し、cloudbuildディレクトリの構成ファイルを割り当てます。この中のregionで作られたtriggerでないと動かないので注意が必要です。
トリガーに設定する変数含め、詳細は公式リポジトリに載っています。
pull request作成時
- 事前チェック用のtrigger
- pr-checks.yml
- pre-commitによるチェック
- 各kfpモジュールの単体テスト
- パイプラインのコンパイル
- pr-checks.yml
- End-to-End用のtrigger
- e2e-test.yml
- test環境で、training/predictionパイプラインをVertexAI Pipelineにデプロイする。
- コメント制御推奨(
/gcbrunとコメントされた場合にのみ起動)
- e2e-test.yml
- test環境でのteraform plan用のtrigger
- terraform-plan.yml
terraform planを実行。
- terraform-plan.yml
- prod環境でのteraform plan用のtrigger
- terraform-plan.yml
terraform plan
- terraform-plan.yml
release tag作成時
- リリース用のtrigger
- release.yml
- cicd環境にtraining/predictionパイプライン定義を設置する。
- release.yml
PR merge時
- test環境でのterraform apply用のtrigger
- terraform-apply.yml
terraform apply
- terraform-apply.yml
- prod環境でのterraform apply用のtrigger
- terraform-apply.yml
terraform applyを実行。
- terraform-apply.yml
Local
- リポジトリをcloneしてくる。
- pipenvをインストールし、
pipenv install --devで環境を作る。 env.sh.exampleをenv.shにコピーし、Cloud Storageバケット等の環境変数を適宜アップデートする。.gitignoreからenv.shを除外する。
4.動かしてみる
予め準備されているxgboostのパイプラインで、デプロイまでのフローを試してみます。手順は公式リポジトリに載っています。
ちなみに新しいパイプラインを作る場合はpipelines以下に作成し、unit testやEnd-to-End testを適宜作成します。
4-1.パイプライン変更
featurebranchを作成。pipelines/xgboost/(training|prediction)/payloads/(test.json|prod.json)make pre-commitでpre-commitを実行。フォーマットエラー等はここで修正されます- Commit & Push
- mainブランチに対してPRを作成。コメントには
/gcbrunと記載。
PRを作成すると、pre-commitチェック、End-to-Endテスト、terraform palnのtriggerが実行されます。githubのUIから確認できます。
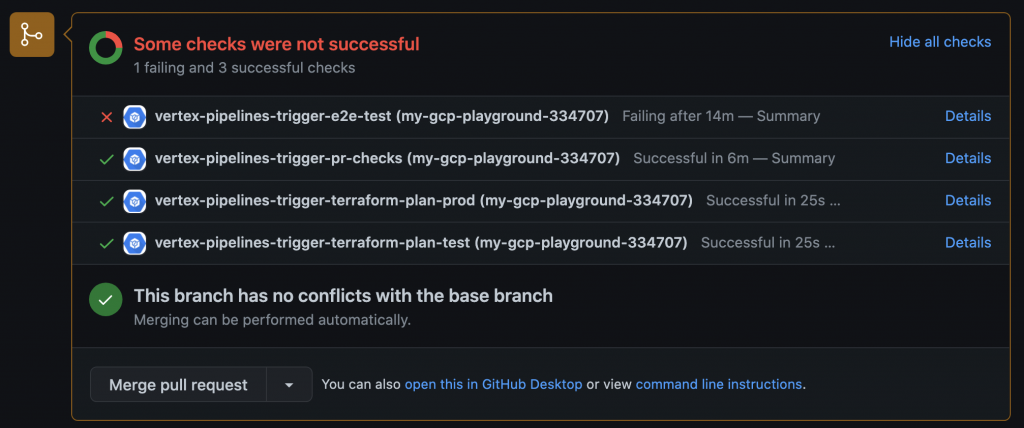
上記ではe2d-testが失敗していますが、上手くいくとVertexAI Pipelinesでパイプラインジョブを確認できます。これはtrainingパイプラインです。この規模のパイプラインをほぼテンプレートのままでデプロイできるのは非常に便利ですね。
![]()
全てのtriggerが成功したらPRをmergeしましょう。mergeするとterraform applyのtriggerが実行されますが、terraform構成についてはまだ更新していないので、特に何も変更はなく実行は成功します。
4-2.リリース
v1.1のタグをmainブランチに作成します。
releaseのtriggerが実行され、cicd環境のGCSにv1.1のディレクトリが作成されます。training.jsonとprediction.jsonが保存されていることを確認しましょう。
4-3.テスト環境にデプロイ
test-env-schedulingenvs/test/main.tfを編集- backendを設定。backendはterraformのstateファイルを保存する場所のことで、ここではtest環境のGCSバケットを指定します。
- 必要なterraformコンポーネントを追記。
- Commit & Push
- mainブランチに対してPRを作成。
- pre-commitチェック、End-to-Endテスト、terraform palnのtriggerが実行されます。(
/gcbrun
- pre-commitチェック、End-to-Endテスト、terraform palnのtriggerが実行されます。(
- PRをmerge
- terraform applyのtriggerが実行されます。GCPコンソールから各サービスが期待通りにデプロイされていることを確認します。
4-4.本番環境にデプロイ
prod-env-schedulingenvs/prod/main.tf- 以下、テスト環境の時と同様。
ここまで終えると、最初に示したCI/CDアーキテクチャがGCP上に構築されていると思います。
公式リポジトリより
5.まとめ
今回は公式テンプレートに則り、GCP上での機械学習プロダクトの運用を実践しました。
筆者はCI/CDや構成管理の知識が乏しかったですが、豊富なドキュメントのおかげで実装されるプロダクトの全体像が把握しやすく、このテンプレートを使った本番運用の手順を再現することができました。
このプロジェクトは現在も活発に改修が行われていますが、大きい軸の部分に関しては、機械学習プロダクトテンプレートとしての一つの完成形に近いモノを感じています。
特に、環境の使い分けやディレクトリ構成は非常に参考になります。このあたりの構成については、GCPでやるなら基本的にどんなプロジェクトでもこのテンプレートそのままで良いのではないでしょうか。
kfpによるパイプラインのテンプレートも、必要なコンポーネントが網羅されていて実践仕様のクオリティです。各プロジェクト毎にtuningが必要な部分としては、データロード、モデル定義、モデルデプロイ(VertexAI Endpointにデプロイするとか)くらいだと思います。
上述の通りこのプロジェクトは頻繁に手が入っていて、特にconfig周りをもっとシンプルかつスマートにしようという意思を感じます。このテンプレートがさらに使いやすくなるのが楽しみですね。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD