2022.04.08
MLOps on GCP 入門 ② 〜デプロイ編〜
ご覧いただきありがとうございます。次世代システム研究室の N.M.と申します。
前回のブログでは、Vertex AI Pipeline を使ってデータの前処理 => モデル構築 => デプロイまで一通り行ってみましたが、初の Vertex AI Pipeline (及び Kubeflow Pipeline)に中々に手こずらされました。今回は、前回の内容を踏襲しつつデプロイ周りに関してもう少しパイプラインの構築及び構築したパイプラインの活用を考えてみようと思います。最後までお読みいただけると幸いです。
要約
- 単一のエンドポイントに対して複数のモデルをデプロイしてみる
- Cloud Function & Cloud Scheduler を使って作成したパイプラインを定期実行する
- python function-based component と workbench との相性が非常に良い。
改めて Vertex AI Pipeline
今回も Vertex AI を触っていく上で前回のブログで試しきれなかったいくつかの機能のうち、単一エンドポイントへの複数モデルデプロイと Cloud Function & Cloud Scheduler による パイプラインの定期実行の 2 つを試してみたいと思います。
Vertex AI による複数モデルデプロイ
Vertex AI では実際に予測を行うモデルの概念とそれをサービングするエンドポイントの概念が明示的に分けられています。エンドポイントを作成すると、sklearnやTensorflowなどの環境が既に整っているビルド済のコンテナやその他の指定したカスタムコンテナが動いている新しいVMインスタンスが立ち上がるというイメージで、Vertex AI の言う「モデルのデプロイ」はこのエンドポイントに対してモデルを割り当てることを指します。モデルのメタデータと予測用のインスタンスを分けていることから、デプロイに関しては非常に柔軟性があり、かつ上述のsklearnやTensorflowで作られた一般的な機械学習モデルであればGUI上からスムーズにデプロイすることができます。例えば、こちらのページには以下のような 2 つのデプロイ戦略が書かれています。
- 同じエンドポイントに複数のモデルをデプロイ
- 複数のエンドポイントにモデルをデプロイ
同じエンドポイントに複数のモデルをデプロイすることができるため、同一の URL でありながら異なるモデルを使った予測が可能になります。その際のトラフィック分割もサポートされており、「基本的には安定稼働のモデル A を使いたいが、新しく作ったモデル B の精度を検証したい」などであればモデル A へのトラフィックを 90%、モデル B へのトラフィックを 10%としてデプロイしたり、「モデル C とモデル D でどちらが良いか検証したい」などであればお互いに 50%のトラフィックにして A/B テストのようなことも考えられるかもしれません。また、複数のエンドポイントにモデルをデプロイすることができるため、作成したモデルを STG 環境と本番環境の両方に異なるスペックのエンドポイントのリソースを用意して紐付けるなどのことができます。
今回は、「現状動いているMLプロダクトに対して、アプリケーション側への影響・負担が少なく、かつスムーズに別の機械学習モデルをデプロイする」というシナリオを想定し、同じエンドポイントに複数のモデルをデプロイすることに着目したいと思います。
パイプラインの定期実行
上述の通り、GUI上からモデルをデプロイすることは非常にスムーズにできます。ただし、これらは検証やPoCレベルであれば歓迎するべき点ですが、運用を考えるといちいちモデルを選択してデプロイのボタンを押すのはヒューマンエラーの可能性もありますし何より面倒です。そのため、今回も前回のブログ同様にVertex AI Pipelineを使って一連の処理をパイプラインにして自動化します。
その際にもう一つ考えたいのは、例えば「1週間に一度、新しいデータを考慮したモデルをデプロイする」といったパイプラインの定期実行です。これを実装することによって、MLOpsにおけるCT(継続的トレーニング)を実現することができます。では実装は難しいか…と考えるとそうでもなく、GCP上の他サービスを利用することでパイプラインをスケジュール実行することが可能です。イメージとしてはコンパイルしたパイプラインのjsonをプロジェクトのGoogle Cloud Storage上に保存しておき、Cloud Functionsでそれを呼び出すメソッドを定義し、Cloud Schedulerでそれを定期実行するように定義する…と言った流れです。こちらもパイプラインと異なり一度定義してしまえば以降勝手に実行されるので、GUI上で一度作成してしまえば問題ありません。
今回の実装方針
前回のブログで、パイプラインのコンポーネント(データの前処理、モデル作成など実際の処理の部分)をどのように実装するかと言う話で、以下の 3 つの実装方針があると書きました。
- パイプラインのソースコードに関数ベースで書く
- Google Cloud パイプライン コンポーネントを使う
- GCR に push されている docker image を使う
今回は前回使わなかった GCR に push されている docker image を使う方法(下記関数、前回ブログ参照)をとってみようと思っていました。
from google_cloud_pipeline_components
import aiplatform as gcpc_aip
training_op = gcpc_aip.CustomContainerTrainingJobRunOp(
container_uri=container_uri,
dataset=dataset_create_op.outputs[“dataset”],
training_fraction_split=0.8, ...
)
しかしながら、このGoogle Cloud パイプラインコンポーネント(以下GCPC)と自作のコンポーネント(精度のチェックや今回のようなカスタマイズされたデプロイなど)との相性が非常に悪く、提供されている機能が限定的な Google Cloud パイプライン コンポーネントを使用するのは、現状複雑なパイプラインになると対応しづらいです。(例えばこの issue のように既存の endpoint に対してデプロイするということも難しい)
そのため、今回もPython function-based componentの形式で作成していきます。また、Vertex AI のサービスの一つである workbench 上で都度パイプラインをコンパイルして json を生成することができることから、notebook のセル単位でコンポーネントを作成していくことで見通しがつきやすく実装できるので個人的に気に入っています。今回もこちらの方法で実装していきます。
複数モデルデプロイの実装
今回は以下の前提からスタートし、新しく作ったモデルをトラフィック 10%でデプロイすることをゴールにします。
- 既にエンドポイントが作成されている
- そのエンドポイントに一つモデルが作成されている
- 最小1種類、最大2種類のモデルがデプロイされている状態になっている
- 新しく作られたモデルは、パイプラインを実行するごとに入れ替える
また、今回も前回同様以下のコンポーネントの構成です。
- データの前処理
- モデルトレーニング
- 品質のチェック(同一コンポーネントのため割愛)
- モデルのデプロイ

データの前処理
今回は scikit-learn のToy Datasetsのうち、linnerudを使って体重・胸囲・心拍数から懸垂・腹筋・ジャンプの回数を推定するモデルを作っていきます。今回はこのlinnerud データセットを上手い具合に件数に増やし(ここはスコープにしていないので割愛)、前回とは異なりBigQuery に保存した状態からデータセットを作っていきます。ライブラリの使用上URLを若干いじる必要がありますが、基本的にはBigQueryのClientを呼び出してpandas.DataFrameの形に変換します。
@component(
base_image="gcr.io/deeplearning-platform-release/sklearn-cpu:latest",
packages_to_install = ["google-cloud-storage", "google-cloud-bigquery", "pandas"]
)
def create_dataset(
bq_table_uri: str,
dataset: OutputPath("Dataset")
):
import pandas
from google.cloud import bigquery
from google.cloud import storage
bqclient = bigquery.Client()
storage_client = storage.Client()
prefix = "bq://"
if bq_table_uri.startswith(prefix):
bq_table_uri = bq_table_uri[len(prefix):]
table = bigquery.TableReference.from_string(bq_table_uri)
rows = bqclient.list_rows(table)
df = rows.to_dataframe(create_bqstorage_client=False)
df.to_csv(dataset)
トレーニング
sklearn の MLPRegressor でモデルを作っていきます。今回も metrics に score を入れて閾値未満であればデプロイしない機構を入れています。詳細は前回のブログをご覧いただけると幸いです。
@component(
base_image="gcr.io/deeplearning-platform-release/sklearn-cpu:latest",
packages_to_install = ["sklearn", "pandas", "joblib"]
)
def create_model_with_tuning(
dataset: Input[Dataset],
metrics: Output[Metrics],
model: Output[Model],
):
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import r2_score
from joblib import dump
import pandas as pd
df = pd.read_csv(dataset.path)
train_df, test_df = train_test_split(df,test_size=0.2,random_state=0)
x_train = train_df.iloc[:, 3:6]
x_test = test_df.iloc[:, 3:6]
y_train = train_df.iloc[:, 0:3]
y_test = test_df.iloc[:, 0:3]
param_grid = {
'max_iter': [10000],
'activation': ['tanh', 'relu'],
'alpha': [0.0001, 0.05],
}
skmodel = GridSearchCV(MLPRegressor(), param_grid, cv=4)
skmodel.fit(x_train, y_train)
best = skmodel.best_estimator_
pred = best.predict(x_test)
score = r2_score(y_test, pred)
print('score is:',score)
dump(best, model.path + ".joblib")
metrics.log_metric("score",(score * 100.0))
モデルのデプロイ
今回のブログのメインになります。前述の通り google cloud pipeline component は使用せずに、Vertex AI の前身である aiplatform のライブラリを使ってデプロイしていきます。
aiplatform.EndopointでエンドポイントのIDによって取得した後、endpoint.list_models()でデプロイされているModelのIDやdisplay_name(GUI上で表示されている名前)などの一覧を引くことができます。このIDを使ってやることでシンプルに既存のものと入れることができます。エンドポイントから既存のモデルをundeployするタイミングでtrafficを100%にしていますが、これはundeployのタイミングでtrafficを指定しなければいけないためです。deployするタイミングでtraffic_percentageを指定することで簡易的にtrafficを指定していますが、もちろん全てのdeployされたmodelのIDは取得できるのでtraffic_splitを直接指定することもできます。
@component(
packages_to_install=["google-cloud-aiplatform"],
base_image="python:3.9",
)
def deploy_model(
model: Input[Model],
project: str,
location: str,
endpoint_name: str,
deployed_endpoint: Output[Artifact],
deployed_model: Output[Model],
):
from datetime import datetime
from google.cloud import aiplatform
aiplatform.init(project=project,location=location)
target_model = aiplatform.Model.upload(
display_name="linnerud-challenger-model-{0}".format(datetime.now().strftime("%Y%m%d%H%M%S")),
artifact_uri = model.uri.replace("/model", "/"),
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/sklearn-cpu.0-24:latest"
)
target_endpoint = aiplatform.Endpoint(endpoint_name=endpoint_name)
deployed_models = target_endpoint.list_models()
# モデルは最大でも2つしかデプロイされていないとする(かなりの力技)
champion_id = ""
for i in range(len(deployed_models)):
if (deployed_models[i].display_name == "linnerud-champion-model"):
champion_id = deployed_models[i].id
for i in range(len(deployed_models)):
if (deployed_models[i].display_name != "linnerud-champion-model"):
target_endpoint.undeploy(
deployed_model_id = deployed_models[i].id,
traffic_split = {champion_id: 100},
)
target_endpoint.deploy(
model=target_model,
deployed_model_display_name="linnerud-challenger-model",
min_replica_count=1,
max_replica_count=1,
traffic_percentage=10,
machine_type='n1-standard-4',
)
deployed_endpoint.uri = target_endpoint.resource_name
deployed_model.uri = target_model.resource_name
以上でパイプラインの構築は完了です。コンパイルしてGUIやworkbench上でjob.submit()などをしてパイプラインを実行することで下記のような状態を維持できます。
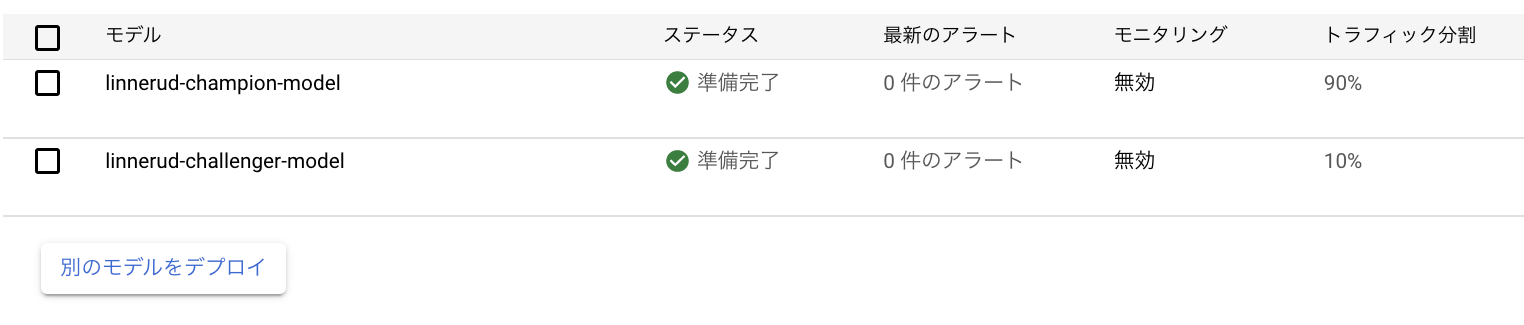
パイプラインの定期実行 + 予測取得
上記のパイプラインによって一つのエンドポイントに複数のモデルをデプロイすることができました。
パイプラインの定期実行
上記のパイプラインの定期実行を行なっていきます。こちらは GCP Console 上で構築していきます。流れとしては以下のようになります。
- 実行するパイプラインのコンパイルした json を Google Cloud Storage に保存
- 上記のパイプラインを実行する Cloud Functions を定義してデプロイ
- 上記 Cloud Functions を定期実行する Cloud Scheduler を定義して実行
本当にこれだけしかやっていないです。さらに、懇切丁寧に記載されたこのガイドに沿って実装していけば完了できます。検証の際は1時間ごとに実行するようにスケジューリングしていました。下記のようにちゃんと実行されており、Pipeline構築の苦労と比べるととても簡単に実装することができました。
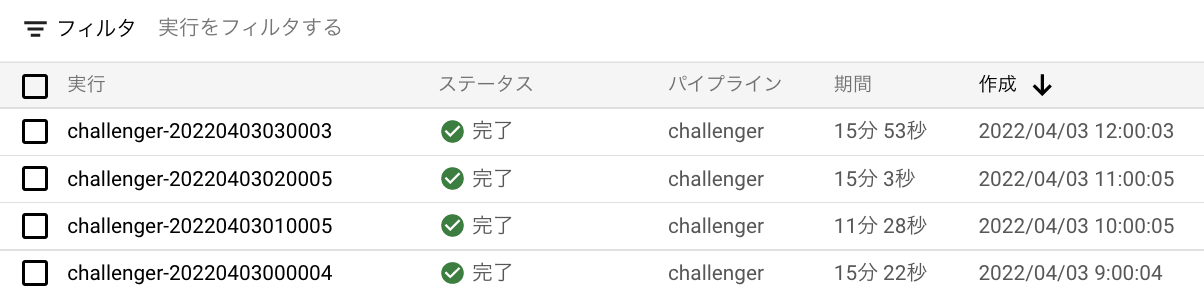
予測の取得
おまけになりますが、せっかくなので試しにオンライン予測を取得してみます。このガイドにも記載がある通り、gcloud auth application-default print-access-tokenの記述がある通りアクセストークンが必要にはなりますが、普通に curl で取得できます。今回は{ "instances": [[86.6, 91.4, 50]] } のような json(下記コマンドの testdata.json)をリクエストしてみます。
% curl -X POST \
-H "Authorization: Bearer [token]" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/[project]/locations/[region]/endpoints/[endpoint]:predict \
-d @testdata.json
--------------- ここからレスポンス ---------------
{
"predictions": [
[
7.228936398190295,
126.4570810077021,
50.357917036718561
]
],
"deployedModelId": "[model]",
"model": "projects/[project]/locations/[region]/models/[model]",
"modelDisplayName": "linnerud-champion-model"
}
それらしい予測結果が返ってきていそうです。ML の予測を REST API でサッと使えるのは、入力するスキーマが同一であればアプリケーション側を変更する負担が増えるわけではないと思うので導入がしやすいかと思います。また、前述のようにエンドポイントに複数のモデルをデプロイしておけば、URL の変更なしでモデルを切り替えることも可能な点もアプリケーションへの影響を抑えることができる点になります。
まとめ
今回は単一エンドポイントに複数モデルをデプロイするパイプラインの構築を中心に、Cloud Functions, Cloud Scheduler との連携など具体例も混ぜつつ行ってみました。モデルのデプロイの柔軟性は様々な利用価値があるとは思いますが、複数モデルのデプロイの最大の意義は安定稼働をさせながらもどのように機械学習モデルを入れ替えることができるという点にあるかと個人的には思いました。
Cloud Functions, Cloud Scheduler との連携に関しては GUI 上でサクサクできるため問題はありませんでしたが、やはり肝心のパイプライン構築に関しては躓く点も多かったです。基本的には workbench 上で component を notebook 上で書き、それをコンパイルしてそのまま実行できる python function-based component の自由度が非常に高い分、google cloud component pipeline はやはり自由度が低く使いこなすのが難しく感じました。
まだまだ ML パイプラインのできることは数多くあるかと思うので、今後も MLOps のプラクティスについては注目していきたいと思います。最後までご覧いただきありがとうございました。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティスト、及びグループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD