マーケットのミクロストラクチャーの紹介~information tradeの評価へ
はじめに
こんにちは。次世代システム研究室のC.Z.です。マーケットを理解・分析するための各機械学習手法を行う際に、どのようなML特徴量を使うべきか・使ったほうがいいかは一番難しい課題だろうと思います。
O’Hara(1995)は、マーケットのミクロストラクチャーを、「明確なトレーディングルールの下で、アセットを交換するプロセスと結果」を研究する分野と定義しました。ミクロストラクチャー的なデータセットは取引プロセスに関する色々な重要情報を含めます。例えば、取引約定状況、order book、queues、aggressive(or passive) side orderなどがあります。これらの情報がマーケット参加者の意図を研究・解釈する可能性が与えられました。それゆえ、ML予測モデルを立てる際に、ミクロストラクチャー的なデータはもっとも重要な特徴量の一つになっています。
本記事において、筆者はマーケットのミクロストラクチャー的な特徴量についての代表的な研究とモデルを紹介したいと思います。
概要
マーケットのミクロストラクチャーに関する研究と理論は、アクセス可能なデータの量・質・種類の増加につれて、進化し続けています。それらの研究と理論は、大雑把に、三つの世代のモデルに分けられます。最初に、第一世代のモデルはプライス情報のみを利用しています。そのなか、二つの基礎的なモデルとして、トレード classificationモデルとRoll モデルがあります。
その後、Volume関連情報のアクセス可能につれて、第二世代のモデルは誕生しました。この第二世代のモデルは、volumeがpriceに与えるインパクトの研究に注力しました。例として、KyleモデルとAmihudモデルがあげられます。
第三世代のモデルは、Easley(1996)が提出した「probability of informed trading」、即ちPIN理論をはじめ、画期的な進化が生まれました。なぜかと言いますと、本理論によると、spreadをmarket makerとinformed traderの一連戦略の結果と見られ、PINはそのプロセスを解釈することになるからです。それが、本質上においてはmarket makerがinformed traderに逆選択されている商品を売って、ask-bid spreadはその期待損失をカバーするためのプレミアムになります。その後、PINの拡張版として、Easleyはまたhigh-frequency取引を扱えるVPINモデルをも提出しました。
上記の諸研究のまとめとして、low-frequencyとhigh-frequencyのモデルらはそれぞれHasbrouck(2007)とEasley(2013)によりよく整理さられました。
第一世代モデル:プライス順序
第一世代のミクロストラクチャーモデルは、アクセス可能な情報が限られたため、トレードプロセスの構成や戦略などが考慮されていません。プライス情報のみを用いて、spreadとvolatilityを推定します。Tick test rule
Double auction bookにおいて、quote(askとbid)がそれぞれマーケットに挙げられています。Buyerがあるaskにマッチするまたはsellerがあるbidにマッチするなら、取引が発生します。当然、すべての取引にはbuyerとsellerがあります。但し、取引の発動者はbuyerかsellerのどちらだけになります。取引の発動方をaggressor、もう一方をpassiveと定義しています。
その故、aggressorのトレード方向を決定するため、classificationモデルが必要となります。Lee and Readyはtick testモデルを提出しました。
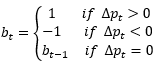
ここでは、1をbuyer発動取引、-1をseller発動取引とラベルしています。
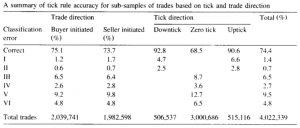
モデルはシンプルですが、Aitken(1996)によりtick testの精度が実は高いようで、Δp不変のケースを除くと、オーストラリアのstock市場をテスト対象に、90%以上の精度が得られました。
さらに、系列bの変形によって、複数の特徴量が作成できます。例えば、bのentropyはマーケット効率性の評価に使うことが可能です。
Roll model
Rollモデルは「有効」なspreadを解釈しようとしているモデルです。mid_price(m)がrandom walkに従うと仮定し、trade price(p)は
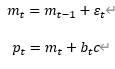
ここでは、bは前セッションのaggressorの売買方向ラベル、cはspreadの半分になります。
Rollモデルはトレードのbuyとsellの発生率が同じ且つ時系列独立と仮定し、ask-bid spreadと真なprice noiseが導かれます(証明略)。
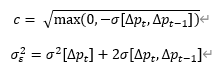
まとめると、spreadはprice変化の自己共分散の関数であり、誤差(真のnoise)は観測可能のnoise(ミクロストラクチャー noiseを含む)とプライス変化の自己共分散の関数になっています。
まとめると、spreadはprice変化の自己共分散の関数であり、誤差(真のnoise)は観測可能のnoise(ミクロストラクチャー noiseを含む)とプライス変化の自己共分散の関数になっています。
ここから、一つ当たり前の質問が上がるだろうと思います。それは、ask-bid情報がアクセス可能な今、Roll modelがまだ必要ですか?答えはyesです。一つのメインな理由は、商品がほぼ取引されていないまたはプライスが提供されても実際は取引されたくないプライスに対して、つまり信頼性が低いquoteに対して、Roll modelが比較的に直接で「有効」なspreadを推定することが可能だということです。
High-Lowボラティリティとspreadモデル
一番伝統的なclose-to-closeボラティリティモデルと比べ、high-low volatilityモデルをはじめ、複数なvolatilityモデルが次々と提出され、もっとロバストな推定量が得られるといわれています(証明略)。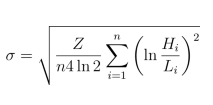
https://www.rdocumentation.org/packages/TTR/versions/0.24.2/topics/volatility
上記のhigh-lowプライスよりボラティリティを推定するように、Corwin and Schultzもhigh lowプライスを使って、spreadを推定しました。このモデルは二つの仮設があります:①high priceが常にbuy発動取引、low priceが常にsell発動取引②volatility原因のhigh-to-low ratioは時間につれ増加
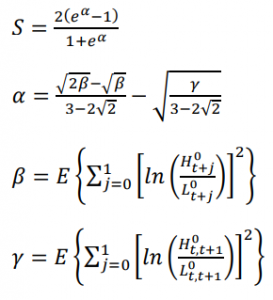
彼らの論文によると、このモデルの推定spreadが真のspreadと0.9以上の相関性が見られました。
Corwin and Schultzモデルを使う理由は、Rollと似ていた「有効」spread且つ流動性(volatility)の推定以外で、情報不均衡性を測定するには、close-to-close spreadよりもっと効率的な結果が得られたようです。
第二世代モデル:戦略取引モデル
第二世代のモデルは主にマーケット流動性の解釈と測定に注力しました。これらのモデルは、取引をinformed traderとuninformed traderの戦略相合作用として解釈しましたので、第一世代のモデルよりもっと強い理論基礎を持っています。この目的を達成するため、volumeやorder imbalanceに注視することになりました。まず、マーケットの流動性は何ですか?場合によって、意味が違いますが、我々よく耳に入っているマーケットインパクトと高い相関性を持っています。Market impactを一言で簡単に解釈すれば、buy(sell)取引が発生するとpriceが上がる(下がる)ということです。本質上からいうと、このインパクトはorder imbalanceから生じたもので、マーケットの流動性に左右されています。
Kyle’s Lambda
Kyleは以下の取引環境を仮定しました。- 商品はvの価値がある
- 二人のトレーダーがある
- Uninformed traderが真の価値vを知らず、数量uを取引しよう
- Informed traderが真の価値vを知り、数量xを取引しよう
- Market makerはuninformedとinformed traderを区別できず、ただ数量(x+u)のorder flowが観測でき、そのorder flowに応じプライスpを設定する
このpriceのインパクト度合を評価する特徴量として、マーケットの非流動性(流動性の逆)指標であるlambdaが提出されました。
(証明略)lambdaとinfromed traderの期待収益が以下の式に書くことができます。
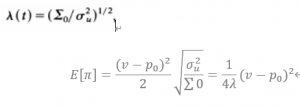
非流動性lambda式の分母は真価格の分散、分子はnoiseの分散になります。
収益の期待値(pi)の式からわかるように、informed traderは三つの収益源があります。
- 商品のmispricing
- Uninformed traderのorder flowの分散(noiseが高いほど、informed traderが自分の意図をもっと隠すことができる)
- 商品の真価値の分散(このボラティリティが低いほど、informed traderがもっとmispricingを利用することができる)
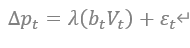
ここでは、bは前にも紹介したaggressorのflag、Vは取引のボリュームになります。
次のlambdaモデル
Amihud(2002)のlambdaはreturnの絶対値と非流動性の正相関を表示しています。モデルはシンプルですが、daily有効spreadと高い相関を持つことが見られました。Hasbrouck(2009)のlambdaはKyleとAmihudの研究の上、trade-and-quote(TAQ)データを用いて、priceインパクトを推定しました。Hasbrouckのlambdaは取引有効コスト(market impact)の概算には、使える特徴量となります。
第三世代モデル:PINとVPIN
上記Kyleのモデルからわかるように、第二世代の戦略取引モデルは、一人のinformed traderが複数のタイミングで取引できる環境を設定しました。第二世代と違って、第三世代のモデルは、randomで選択されたtradersが順次にマーケットに入る環境をモデリングしました。
このモデルが流行っている原因は、market makerが直面しないといけない不確実性を解釈しようとするわけです。この不確実性は、情報あるイベントの発生率、このイベントがよい(悪い)イベントの比率、uninformed traderの到達率、informed traderの到達率を含めます。これらの変数によって、market makerはダイナミック的にquoteを更新し、positionなどを管理します。
PIN(Probability of Information-based trading)
PINは商品のinformation-based取引の確率を測定する特徴量です。つまり、PINが大きいほど、traders間の情報非対称程度と高いと解釈できます。このミクロストラクチャーモデルは、取引をmarket makerとtakerの間に複数の期間に繰り返し発生したゲームと見なします。
取引プロセスの構造は以下のようになります。
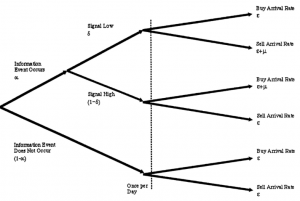
商品現在のプライスをS0とします。もし新しいイベントが発生したら、このイベントの情報はプライスにも反映されることにします。良いイベントが発生した場合、プライスはSgとなり、逆に悪いイベントが発生した場合、プライスはSbになります。
上記のモデル環境より、商品のプライス期待値は以下の式になります。
Market makerは損失を回避するため、ask-bid spreadを以下のように設定する必要があります(証明略)。
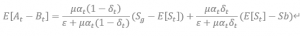
さらに、良いイベントと悪いイベントの発生率が同じであると仮定すると、上記の式は以下のように変形できます。
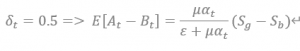
つまり、spread(market maker提供する流動性)を決めるための決定的な要素は上記の式の係数になります。この係数はPINです。
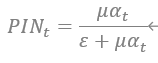
PINを決めるには、上記の式のパラメータらを推定する必要があります。
取引のプロセスから、buyとsellの分布をPoisson分布にして、最大尤度法からパラメータの推定が可能になります。
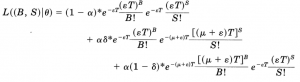
High-frequency向けのPIN:VPIN(volume-synchronized PIN)
詳細は略しますが、VPINは単純なtime clockを使うことではなく、volume clockを使うことがメインな手法になります。Volume clockの利用により、データのsamplingがマーケットの活動と同期することができます。PINと違って取引単位での売買分類ではなく、各volume barのbulk classificationにより、bulkごとの売買分類を行います。次は、任意サイズのbulkをさらに集計し、VPIN推定するためのvolume bucketを作ります。
Easley(2008)はPINを提出した論文で、既に下記の関係式が証明しました(略)
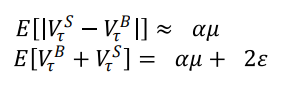
ここで、Vはvolume bucketのことです。
それでは、リアルタイムのhigh-frequencyデータのPINが以下のように計算することが可能になります。
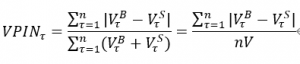
式より示されたように、VPINはパラメータの推定は不要です。
ボラティリティ自体の予測featureではなさそうですが、複数の研究においてVPINはマーケット急変の予兆を捉える特徴量として、予測能力があると証明しました。
最後に
以上紹介したミクロストラクチャーモデルらについて、一番の懸念点はこれらのモデルは全部線形回帰の上に作成され、現代のもっと複雑になりつつある非線形マーケットにうまく解釈できるかのことでしょう。なお、上記ミクロストラクチャーの特徴量以外、マーケット参加者の挙動と意図を内包するほかの特徴量にも注意したほうがいいでしょう。例えば、order sizeの分布はプライスの安定性情報を含める特徴量が作られます。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。