2018.04.03
Capsule network(新 neural network)で毒キノコ画像を判別してみた
お世話になっております。次世代システム研究室のK.S.(女性、外国人)です。
今回のブログはディープラーニングの世界でゴッドファーザーと呼ばれたGeoffrey Hintonを中心に提案された新しいニューラルネットワーク (Capsule Network:CapsNet)を紹介し、CapsNetを使った毒キノコ画像解析の実験レポートをお伝えしたいと思います。
まず、Capsule Network (CapsNet)とはなにか、なぜこの技術を紹介するのか、を説明したいと思います。それから、CapsNetはどう使うのものなのか、実際に動くコードを見ながら、実装方法を説明したいと思います。今回実験で用いた実装コードサンプルではキノコの画像を学習し、入力した画像が毒キノコかどうかを予測するものです。
このブログの構成は、以下のとおりです。
① Capsule Network(CapsNet)
最近のテレビで人工知能(AI)に様々な情報を学習させれば、適切な答えを導き出せる可能性が広がっている、という話をよく聞いたりしませんか? 例えば、「犬」と「猫」の写真を学習(記憶)しておけば、AIが写真を区別することが可能になってきました。その学習するためのテクノロジーは「機械学習」と呼ばれています。さらに、従来の機械学習を発展させたテクノロジー(従来のニューラルネットワークをベースとしたもの)はディープラーニング(深層学習)と呼ばれています。
ディープラーニングはコンピューターにデータを学習させるため、人間の神経を真似て作ったニューラルネットワークの階層を深めたアルゴリズムです。ディープラーニングのアルゴリズムは様々なタスクに応用されており、その中でも有名なものは画像学習に関するアルゴリズムです。また、画像学習のアルゴリズムの中で一番有名なものは畳み込みネットワーク(Convolutional Neural Network、以降 ConvNetと略)です。
ConvNetはかなり素晴らしい技術であり、ディープラーニングが有名になった理由の一つだと考えられています。しかし、どんなよいものでも、欠点があります。2014年にGeoffrey Hinton先生が「Convolutional Neural Networkで使用されるpooling操作は大きな間違いであり、それがうまく機能するという事実は完全な失敗である」とコメントしました。この問題を解決するために、去年の10月にGeoffrey Hinton先生と彼のチームがCapsulesという新たなニューラルネットワークを誕生させました。このCapsulesアイデアについてディープラーニング界にはかなり大きいニュースでした。出版された論文は完全に新しいアイデアが書かれていて、色々な応用につながる事が予想できます。そもそも、ConvNet の欠点はなにか、Capsule Network(CapsNet)とはなにか、なぜConvNetよりCapsNetの方がよいのか、を説明したいと思います。
まず、CapsNetの話を理解するため、現在ディープラーニングで使われているConvolutional Neural Network(ConvNet)を少しおさらいします。次に、CapsNetを説明します。ちなみに、文字を読むのが苦手な方はこのビデオの説明は結構わかりやすいです。私もHinton先生の論文とこのビデオから勉強しましたので、ご参考になればと思います。
1.1. ConvNetの概要と欠点
Convolutional Neural Network(ConvNet)はニューラルネットワークの一つであり、画像認識や分類でよく使われています。ConvNetのアーキテクチャは図1のようになります。
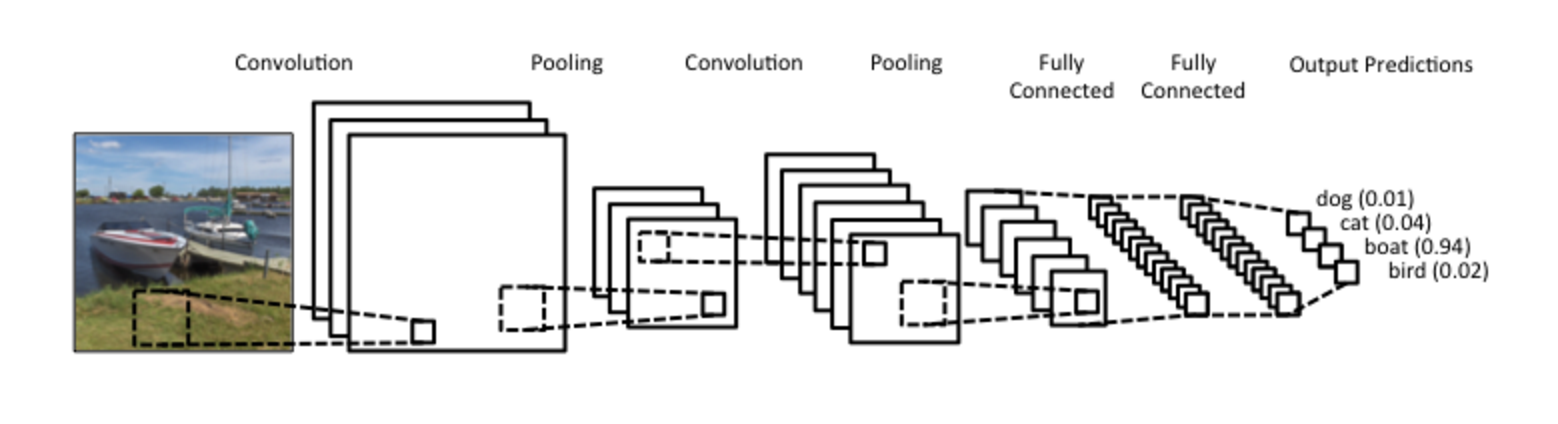
まず、画像が入力され、畳み込み(Convolution)ステップが始まり、ネットワークが作られます。ネットワークの中に、大きな画像は分別され、様々な特徴がneuronとして作られます。それらの特徴はpooling層(max poolingなど)やactivation層(ReLUなど)を通して、設定した層数までに、どんどん転送されていきます。学習するときに、back propagationという理論を利用し、画像認識は本物に近づくように計算されます。最後にsoftmax式を使って出力を確率に変換し、画像を予測することが可能になります。
ここまでのところ、ConvNetの処理の流れには特に問題は無さそうに思えますが、一体どんな欠点があるのでしょうか。一見するとConvNetは普通に画像を分別することができるように見えます。ところが実際には、入力する画像が回転すると、ConvNetの性能が落ちたり、poolingする(図1)ときに、空間的位置関係が無視されるという問題があるのです。図2のように、ConvNetは特徴をpoolingするので、その特徴(目、鼻、口)の位置を考えずに、人の顔を認識してしまいます。これは写真の向きや位置が違う大量なデータを用意し、学習すれば解決可能ですが、この欠点に対応するためには大量のデータやコストの高い計算が必要となります。
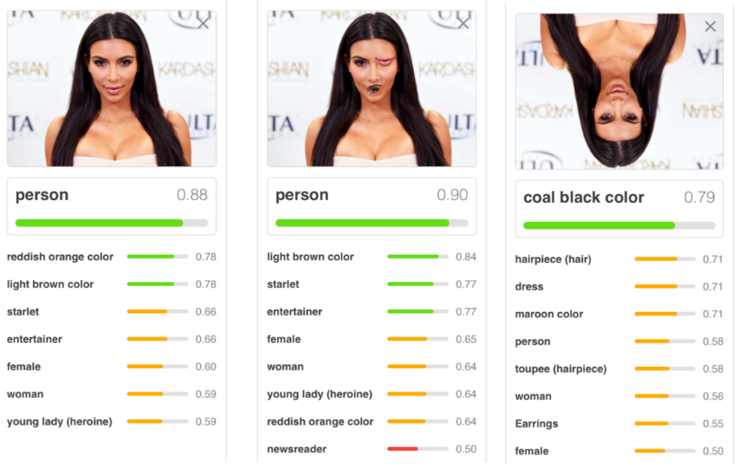
ちなみに、この問題は専門的な記事では、よくInvariance(不変性)とEquivariance(同等性)という専門用語を用いて解説されています。poolingの処理については、空間変化がInvariance(不変性)になっており、Equivariance(同等性)ではないという説明がされることが多いようです。
1.2. CapsNet
Capsule Network(CapsNet)は、上下が逆になったり、回転した入力画像に対処するために発明された新たしいニューラルネットワークです。上記で述べたように、ConvNetの欠点はpooling時に特徴的な空間関係を失うことにあります。その問題に対してCapsNetは解決方法をもたらすのですCapsNetと従来のConvNetはなにが違うのか、そしてどうやって失われた情報に対処できるのか、見ていきましょう。
図1に見せたように、層から層へ画像の特徴(i.e., 口の画)を部分的に転送するのがneuronで、そのneuronを改良したcapsuleを使うものがCapsNetです。具体的な変更は図3でのまとめがあります。

画像情報を移すときに、従来neuronは3ステップあり、capsuleはもう一つステップが追加され、計算ステップの中にも変更があります。従来neuronとcapsuleを比較します。
- 1.入力と出力の形:neuronはスカラー(大きさ)であり、capsuleはベクトル(大きさと向き)になります。
- 2.Affine変更:capsuleで使ったAffine変換は位置関係を表すために、線形式で平行移動と回転を用いたものです。このステップはneuronにないですが、capsuleはこのステップが加わります。
- 3.重み付け:neuronは入力スカラーの和、カプセルも入力ベクトルの和ですが、バイアス(b)はなくなります。
- 4.非線形変換:カプセルは新たなsquash関数が提案されます。
上記の説明はUnderstanding Hinton’s Capsuleを参考にしました。また、capsulesの具体的な作り方は実装のセクションでコードを見ながら説明します。
② CapsNetで毒キノコ画像解析
ここから、CapsNetを利用し、画像認識を実装します。せっかくなので、実験に用いるサンプル画像は、一般的に広く機械学習でよく使われるMNIST(手書き文字の認識のためのデータセット)ではなく、自分の趣味に合わせて、生物の画像を認識させたいと思います。
ちなみに、みなさん、山に行ったりキャンプをしたことがありませんか? 自然が豊かな場所に行くと、たくさんキノコを見つけることができます。そのときに、見つけたキノコが食べられるかどうか分かると便利ではありませんか? もし、スマホで撮った写真から、キノコが毒かどうかわかればいいなあと私は思ったことがあります。というきっかけで、今回の例は食用キノコと毒キノコの画像を認識し、区別してみました。一緒に、コードを見ながら結果を検討しましょう。間違いやコメントがあれば、ご指摘下さい。コード全体はMNISTデータセットを利用した例を修正したものです。修正した今回の実装コードは github にも入れましたので、ご参考や検討になればと思います。また、CapsNetの実装はTensorflow(googleが開発した機械学習ライブラリ)を利用しました。Tensorflowについての参考は ここです。
それでは実装を始めましょう!
まず、実装環境を準備します。それから、キノコの画像を用意します。最後はCapsNetを利用しキノコ画像を学習と予測してみます。
2.1. 実装環境
実装環境は GMOアプリクラウドを利用しました。
マシンスペック
-
タイプ:L
仮想CPU:10
ディスク容量:800GB
メモリ容量:60GB
OS: Centos7.0
言語環境
-
python 3.6
tensorflow 1.5.0
keras 2.1.5
numpy 1.14.2
matplotlib 2.2.2
2.2. キノコ画像データ準備
学習するため、たくさんのキノコ写真が必要です。そのため今回のキノコ画像データ準備は3つのステップで分けます。まず、キノコ画像データを取得します。それから、取ってきたデータセットを読み込みます。最後は、読み込んだ画像データをさらに拡張します。
キノコ画像データ取得
今回はお試しなので、簡単にgoogle画像からの写真を使いたいと思います。大量のダウンロードをするため、google-images-downloadを使わせていただきました。Git hubからcloneし、下記のコマンドで毒キノコと食用キノコの写真をダウンロードしました。毒キノコの例はテングタケ(英名:fly amanita)とドクツルタケ(英名:destroy angel)、食用のキノコはシイタケとエノキです。
python google-images-download_edit.py --keywords "fly amanita" --limit 100 python google-images-download_edit.py --keywords "destroy angel" --limit 100 python google-images-download_edit.py --keywords "shiitake" --limit 100 python google-images-download_edit.py --keywords "enoki" --limit 100
これで、キノコ画像データ取得は完了です。
取得データの読み込み
ここまでで、画像データ取得ができましたが、まだ未加工の状態です。機械に画像を入力させるためには、画像を数字の列に変更することが必要です。具体的に、今回はtensorflowを使うので、図をtensorflow object にし、numpy array(数字の配列)に変更することが必要です。
手順は

def input_image(csv_name, num_batch_size):
# キノコのデータをロードする
fname_queue = tf.train.string_input_producer([csv_name])
reader = tf.TextLineReader()
key, val = reader.read(fname_queue)
fname, label = tf.decode_csv(val, [["aa"], [1]])
# 画像をdecodeとresizeする
jpeg_r = tf.read_file(fname)
image = tf.image.decode_jpeg(jpeg_r, channels=colour_mode) # channels=1 for grayscale, channels=3 for RGB
image = tf.cast(image, tf.float32)
resized_image = tf.image.resize_images(image, [set_size,set_size]) # 今回のサイズは 28 x 28 (set_size = 28)
# 学習ためのバッチを作成する
image_batch, label_batch = tf.train.batch([resized_image, label], batch_size=num_batch_size)
return image_batch, label_batch
これで、キノコ画像からtensorflow形への変更は完了です。
大量の学習データがあるとき、ここまでを使って学習することも可能ですが、今回はダウンロードしてきたデータは少ないため、このデータを使って、さらにデータを拡張してから学習します。
注意点
画像データ拡張
みなさんもご存知かと思いますが、機械学習を行うためには、多くの学習データが必要です。ダウンロードしてきた画像だけでは足りないので、学習しながら、自動的に画像データを拡張します。Keras(PythonでTensorFlow上で実行可能な高水準のニューラルネットワークライブラリ)によって画像データを拡張します。Kerasの中にあるImageDataGeneratorクラスを使って、画像を回転、拡大、縮小、位置移動、などをしながら、画像を増やします。Kerasのドキュメントを参考し、使ったコードは下記になります。
def image_augmentation(x_train, y_train, num_batch_size):
train_datagen_augmented = ImageDataGenerator(
rotation_range=10.,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.,
zoom_range=.1,
horizontal_flip=True,
vertical_flip=True)
train_datagen_augmented.fit(x_train)
x_train = train_datagen_augmented.flow(x_train, y_train, batch_size=num_batch_size)
return x_train, y_train
この関数をデータtrainingに入れれば、同じデータセットから、様々な形に変更し、自動的にデータ拡張ができます(図4)。関数の呼び方は以下の学習(Training)のところに説明します。

2.3 実装
いよいよ、実装です。
まず、Capsule Networkを作成します。それから、そのネットワークを使って、学習し、学習したモデルも検証します。モデルを構築したら、そのモデルを使って、実際にキノコ画像を分類してみたいと思います。
Capsule Network作成
CapsNet アルゴリズムの作成手順(図5)を一個ずつ簡単に説明します。
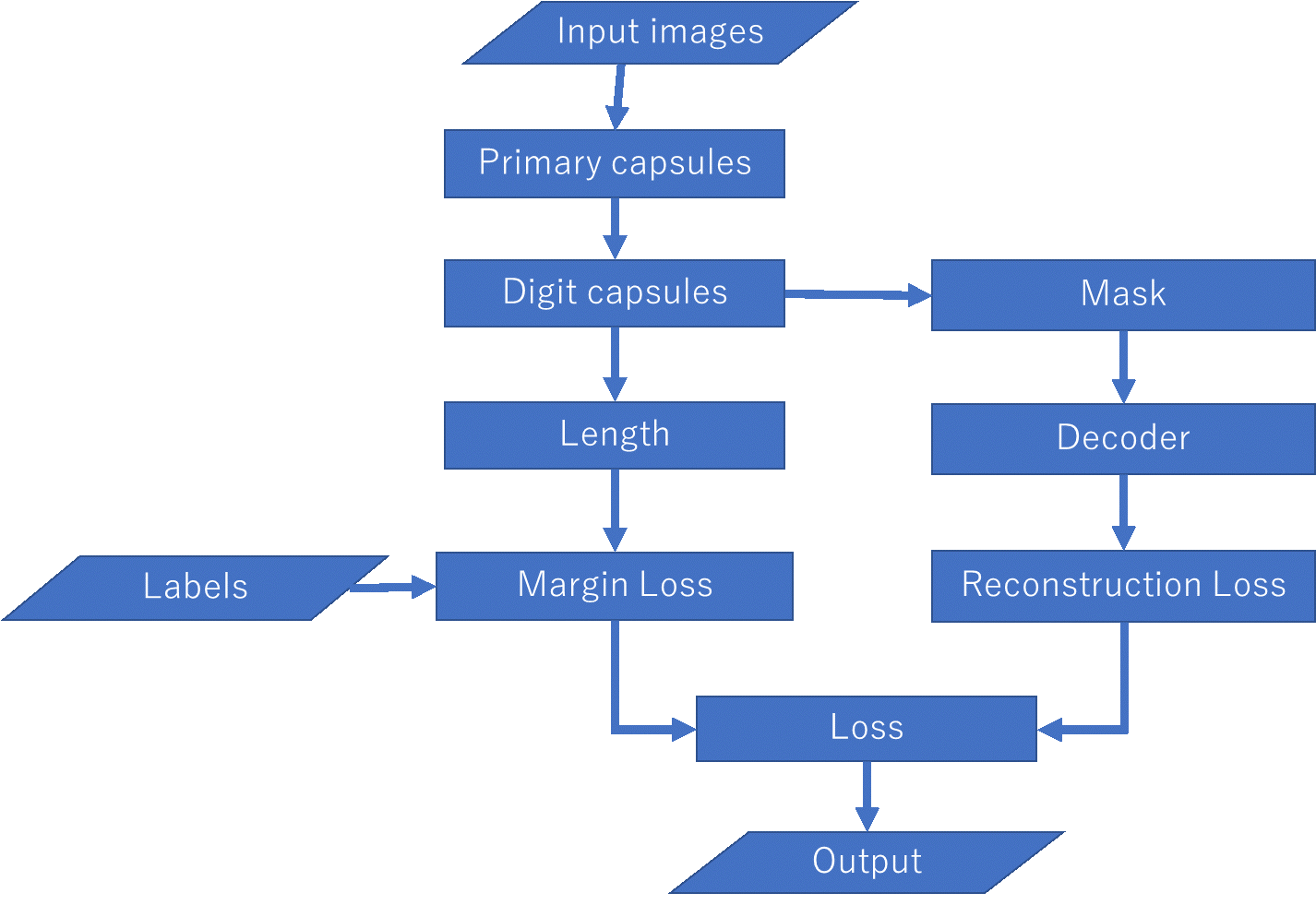
「2.2 キノコ画像データ準備」で行ったことはInput imagesとLabelsになります。Tensorflowで学習するため、その画像の情報(サイズや色モード)をプログラムに教える必要があります。それはプレースホルダー(placeholder)と呼ばれます。プレースホルダーは実際の画像情報を後から挿入できるように、仮の場所を確保するものです。今回は、入力画像とラベルのプレースホルダーを作成します。
ここで画像のサイズと色モードを設定します。
X = tf.placeholder(shape=[None, set_size, set_size, colour_mode], dtype=tf.float32, name="X") y = tf.placeholder(shape=[None], dtype=tf.int64, name="y")
Noneは実行するときに決定することを表します。set_sizeは学習したい画像サイズで今回は 28を設定します。colour_modeは画像モードで、今回は RGB画像を使うので、3になります。
Capsules(図3)を使って、層を作ります。論文で紹介されたsquash関数も使います。最初の層は 32 maps の6*6 capsulesを設定します。各capsuleは8次元(8D)のactivation vectorを出力します。
caps1_n_maps = 32
caps1_n_caps = caps1_n_maps * 6 * 6 # 1152 primary capsules
caps1_n_dims = 8
# 2 convolutional layersを作成
conv1_params = {
"filters": 256,
"kernel_size": set_kernel_size,
"strides": 1,
"padding": "valid",
"activation": tf.nn.relu,
}
conv2_params = {
"filters": caps1_n_maps * caps1_n_dims, # 256 convolutional filters
"kernel_size": set_kernel_size,
"strides": 2,
"padding": "valid",
"activation": tf.nn.relu
}
conv1 = tf.layers.conv2d(X, name="conv1", **conv1_params)
conv2 = tf.layers.conv2d(conv1, name="conv2", **conv2_params)
# 8D vectors を作成するため、(_batch size_, 6, 6, 256) を (_batch size_, 6*6*32, 8) にreshapeします。
caps1_raw = tf.reshape(conv2, [-1, caps1_n_caps, caps1_n_dims], name="caps1_raw")
# これらのベクトルをsquash(論文で紹介された新しい関数)にする必要があります。
def squash(s, axis=-1, epsilon=1e-7, name=None):
with tf.name_scope(name, default_name="squash"):
squared_norm = tf.reduce_sum(tf.square(s), axis=axis, keep_dims=True)
safe_norm = tf.sqrt(squared_norm + epsilon)
squash_factor = squared_norm / (1. + squared_norm)
unit_vector = s / safe_norm
return squash_factor * unit_vector
# outputはsquash関数の計算です
caps1_output = squash(caps1_raw, name="caps1_output")
Digit CapsulesはPrimary Capsulesの次であり、最後の層になります。ここは一つdigit classは一つ16Dcapsulesを含まれています。
caps2_n_caps = num_label
caps2_n_dims = 16
init_sigma = 0.01
W_init = tf.random_normal(
shape=(1, caps1_n_caps, caps2_n_caps, caps2_n_dims, caps1_n_dims),
stddev=init_sigma, dtype=tf.float32, name="W_init")
W = tf.Variable(W_init, name="W")
# create the first array by repeating `W` once per instance
batch_size = tf.shape(X)[0]
W_tiled = tf.tile(W, [batch_size, 1, 1, 1, 1], name="W_tiled")
# ここのinputは一層のcapsuleのoutputになっています。
caps1_output_expanded = tf.expand_dims(caps1_output, -1, name="caps1_output_expanded")
caps1_output_tile = tf.expand_dims(caps1_output_expanded, 2, name="caps1_output_tile")
caps1_output_tiled = tf.tile(caps1_output_tile, [1, 1, caps2_n_caps, 1, 1], name="caps1_output_tiled")
caps2_predicted = tf.matmul(W_tiled, caps1_output_tiled, name="caps2_predicted")
# Routing by agreement
raw_weights = tf.zeros([batch_size, caps1_n_caps, caps2_n_caps, 1, 1], dtype=np.float32, name="raw_weights")
# Round 1 - softmaxを使い、最後はsquash関数を利用
routing_weights = tf.nn.softmax(raw_weights, dim=2, name="routing_weights")
weighted_predictions = tf.multiply(routing_weights, caps2_predicted, name="weighted_predictions")
weighted_sum = tf.reduce_sum(weighted_predictions, axis=1, keep_dims=True, name="weighted_sum")
caps2_output_round_1 = squash(weighted_sum, axis=-2, name="caps2_output_round_1")
# Round 2 も行いますが、Round 1 と同じように行います。全体コードはgithubに参考してください。
出力ベクトルの長さはクラス確率を表します。
def safe_norm(s, axis=-1, epsilon=1e-7, keep_dims=False, name=None):
with tf.name_scope(name, default_name="safe_norm"):
squared_norm = tf.reduce_sum(tf.square(s), axis=axis, keep_dims=keep_dims)
return tf.sqrt(squared_norm + epsilon)
y_proba = safe_norm(caps2_output, axis=-2, name="y_proba")
y_proba_argmax = tf.argmax(y_proba, axis=2, name="y_proba")
y_pred = tf.squeeze(y_proba_argmax, axis=[1,2], name="y_pred")
複数なdigit capsuleを適応するため、margin lossを分けることになります。
m_plus = 0.9
m_minus = 0.1
lambda_ = 0.5
T = tf.one_hot(y, depth=caps2_n_caps, name="T")
caps2_output_norm = safe_norm(caps2_output, axis=-2, keep_dims=True,
name="caps2_output_norm")
present_error_raw = tf.square(tf.maximum(0., m_plus - caps2_output_norm),
name="present_error_raw")
present_error = tf.reshape(present_error_raw, shape=(-1, num_label), name="present_error")
absent_error_raw = tf.square(tf.maximum(0., caps2_output_norm - m_minus),
name="absent_error_raw")
absent_error = tf.reshape(absent_error_raw, shape=(-1, num_label), name="absent_error")
L = tf.add(T * present_error, lambda_ * (1.0 - T) * absent_error, name="L")
margin_loss = tf.reduce_mean(tf.reduce_sum(L, axis=1), name="margin_loss")
画像をdecodeするため、digit capsuleのoutputを変形する必要があります。
mask_with_labels = tf.placeholder_with_default(False, shape=(), name="mask_with_labels")
reconstruction_targets = tf.cond(mask_with_labels, # condition
lambda: y, # if True
lambda: y_pred, # if False
name="reconstruction_targets")
reconstruction_mask = tf.one_hot(reconstruction_targets, depth=caps2_n_caps, name="reconstruction_mask")
reconstruction_mask_reshaped = tf.reshape(reconstruction_mask, [-1, 1, caps2_n_caps, 1, 1], name="reconstruction_mask_reshaped")
# mark作成
caps2_output_masked = tf.multiply(caps2_output, reconstruction_mask_reshaped, name="caps2_output_masked")
Decoderは 二つdense ReLU 層のあとに、dense output sigmoid 層が続いたものです。
n_hidden1 = 512 * colour_mode
n_hidden2 = 1024 * colour_mode
n_output = set_size * set_size * colour_mode
# decoderのinput
decoder_input = tf.reshape(caps2_output_masked, [-1, caps2_n_caps * caps2_n_dims], name="decoder_input")
with tf.name_scope("decoder"):
hidden1 = tf.layers.dense(decoder_input, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
decoder_output = tf.layers.dense(hidden2, n_output, activation=tf.nn.sigmoid, name="decoder_output")
Reconstruction Lossは入力した画像(X_flat)と作成された画像(decoder_output)の差分二乗です。
X_flat = tf.reshape(X, [-1, n_output], name="X_flat") squared_difference = tf.square(X_flat - decoder_output, name="squared_difference") reconstruction_loss = tf.reduce_mean(squared_difference, name="reconstruction_loss")
図5のように、最終的なLossはmargin lossとreconstruction lossの組み合わせです。そこで、両方を合計した値を評価に用います。また、モデル評価するため、比較するものが正しいかどうかaccuracy(精度)で判断します。Accuracyはy(ラベル)とy_pred(予測ラベル)はどのくらい一致したのか確率を求めたものです。
# loss alpha = 0.0005 loss = tf.add(margin_loss, alpha * reconstruction_loss, name="loss") # accuracy correct = tf.equal(y, y_pred, name="correct") accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
これでcapsnet作成は完了です。
学習(Training)
Capsnetを使ってキノコ画像を学習します。
Training operationはAdam Optimizerを使い、Lossをなるべく小さくするように最適化します。今回の学習では、Adam Optimizer のdefault learning rateについて変更を行いました。CapsNet論文にはdefault learning rate (0.001)が使われていました。最初はこの値を使ってみましたが、学習後のモデルの精度はなかなか上がりませんでした。そこで、今回のキノコ画像の学習ではlearning rate=0.0001にしました。
optimizer = tf.train.AdamOptimizer(0.0001) training_op = optimizer.minimize(loss, name="training_op")
学習条件は下記になります。
Epoch(一つの訓練データセットの学習回数)の中には、4枚の画像から、2000枚に拡張されたサンプルを学習しました。2000サンプルには画像バッチサイズ4枚で500回繰り返し学習しました。また、Epochごとに学習が終わったら、検証します。検証するときに、違う4枚の画像データセットを利用し、1000サンプルに拡張しました。画像バッチサイズ4枚で250回繰り返し検証しました。
# 設定
n_iterations_per_epoch = num_train_samples // num_batch_size
n_iterations_validation = num_validate_samples // num_batch_size
best_loss_val = np.infty
checkpoint_path = "./my_capsule_network"
train_image_batch, train_label_batch = input_image('downloads/picture_name_train.csv', num_batch_size)
validate_image_batch, validate_label_batch = input_image('downloads/picture_name_validate.csv', num_batch_size)
with tf.Session() as sess:
if restore_checkpoint and tf.train.checkpoint_exists(checkpoint_path):
saver.restore(sess, checkpoint_path)
else:
init.run()
# 初期化
init = tf.global_variables_initializer()
sess.run(init)
tf.train.start_queue_runners(sess)
# training and validating loop
for epoch in range(n_epochs):
for iteration in range(1, n_iterations_per_epoch + 1):
# training operationを設定
X_batch = train_image_batch.eval()
y_batch = train_label_batch.eval()
# 各iterationで自動的に画像を拡張する。
X_batch, y_batch = image_augmentation(X_batch, y_batch, num_batch_size)
X_batch = next(X_batch)
X_batch = X_batch[0]
# 実行
_, loss_train = sess.run([training_op, loss],
feed_dict={X: X_batch.reshape([-1, set_size, set_size, colour_mode]), y: y_batch})
# 各epochの最後に、validation loss と accuracy を評価する
loss_vals = []
acc_vals = []
for iteration in range(1, n_iterations_validation + 1):
X_batch = validate_image_batch.eval()
y_batch = validate_label_batch.eval()
# iterationごとに自動的に画像を拡張する。
X_batch, y_batch = image_augmentation(X_batch, y_batch, num_batch_size)
X_batch = next(X_batch)
X_batch = X_batch[0]
# 実行
loss_val, acc_val = sess.run([loss, accuracy],
feed_dict={X: X_batch.reshape([-1, set_size, set_size, colour_mode]),
y: y_batch})
loss_vals.append(loss_val)
acc_vals.append(acc_val)
print("\rEvaluating the model: {}/{} ({:.1f}%)".format(
iteration, n_iterations_validation,
iteration * 100 / n_iterations_validation),
end=" " * 10)
loss_val = np.mean(loss_vals)
acc_val = np.mean(acc_vals)
# モデルがよくなったら、保存
if loss_val < best_loss_val:
save_path = saver.save(sess, checkpoint_path)
best_loss_val = loss_val
これで学習完了です。学習結果は図6になります。
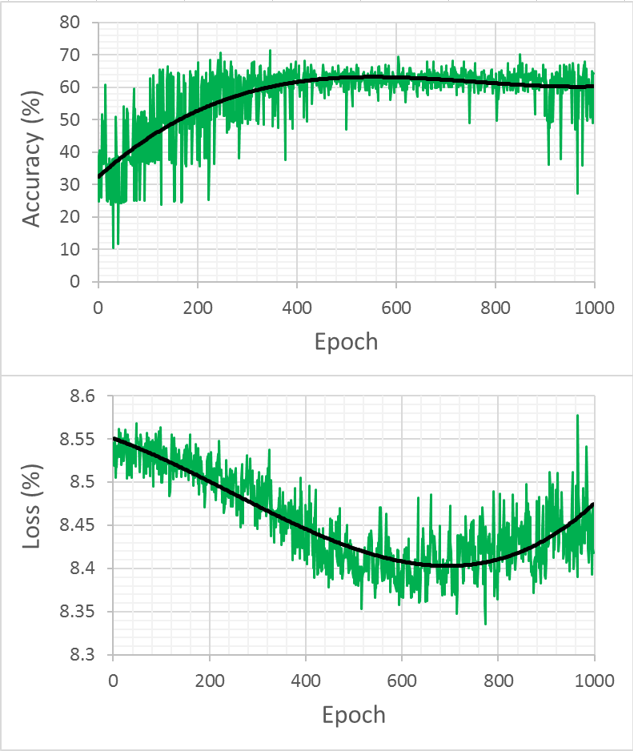
図6に示すように、学習回数を増やすと、精度 (accuracy)も上がっていきます。今回の学習結果による、精度は71.59%(loss=8.49)まで上がりました。capsules論文のMNISTサンプルの学習精度(99.23%)に比較すると、まだ不十分な結果だと考えられます。しかしながら、実用のサンプルでのテストとして、適応性は十分見られたのではないかと思います。今回はほぼ論文の条件をそのまま使いましたが、今後画像処理やパラメータチューニングなどを改良すれば、もっとよいモデルを構築できることが期待できます。特にlossの結果を見てみると途中からloss値が反転して上昇してきたので、ひょっとすると今回の原因はlearning rate値に関連するものかもしれません。上記に述べたように、capsnet論文を参考にlearning rate値を下げて学習を行いましたが、まだ大きすぎたのではないかと考えられます。また、適当にダウンロードしてきたキノコ画像に対する加工処理を工夫することで、学習効率がよくなる可能性が高いのではないかと思います。
テスト(Testing)
学習したモデルが正しいかどうかをテストします。テストの実装プログラムに関しては
学習の実装と似ています。テストと学習の違いはデータセットとサンプル量だけです。また、学習したモデルを利用するため、Epochは必要ありません。
テスト条件は下記になります。
テスト結果による、予測の精度 (accuracy)は65.00%(loss=8.40)でした。予測の精度65%はそんなに高くないですが、学習時の精度71% (学習(Training)セクションで述べた結果)に比較すると、妥当な結果だと考えられます。個人的には学習処理のパフォーマンスの改良と共に、予測精度についてはまだ改善余地があると思います。
まとめと考察
今回のブログではCapsNetを紹介し、一緒にコードを見ながら、毒キノコと食用キノコ画像を学習しました。画像からキノコが毒かどうかをある程度判定できましたが、実用に耐えるレベルに到達するためには、まだ多くの技術的な改良が必要だと考え、下記のように検討してみました。
- 計算時間
- 今回はCPUを使って実装しましたので、計算時間は二日程度かかりました。GPUを使えばもっと速くなるでしょう。
- 精度
- 画像の解像度:今回の学習では低い解像度画像を使いました。将来解像度を向上させると、学習精度はよくなる可能性があります。そのため、学習時間とメモリを増やさなければなりません。
- 拡張データ:今回、画像を処理せず、生データからデータ拡張を使って学習しました。本番だと、データ前処理や、サンプル個数(生データも拡張データも)も増やしたほうがよいと思いました。
- パラメータチューニング:今回使ったパラメータはMNISTサンプルのパラメータでした。今後、さらにパラメータチューニングすれば、学習効率は高まると期待します。
- アンサンブル:CapsNet論文にはCIFAR10サンプル(キノコ画像のようなRGB例)を使った学習例もありました。その学習は7モデルをアンサンブルしたものです。キノコ画像モデルはまだアンサンブルしていませんが、やってみる価値があるのではないと考えています。
今回の紹介はまだ完璧にCapsNetの潜在能力を引き出しきれてはいませんが、この新しい技術(CapsNet)は可能性を秘めた有望なテクノロジーであることをお伝えできると幸いです。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD