2019.01.11
Kaggleのコンペティションに参加してランキング入りしたお話
イントロダクション
みなさま、こんにちは(or こんばんは)
次世代システム研究室のY.Tです。
冬の寒さもいよいよクライマックスを迎えようとしていますが、みなさまはいかがお過ごしでしょうか?
私は、葛根湯や麻黄湯(まおうとう)といった漢方薬を懐にしのばせながら、インフルエンザや風邪の流行に対して臨戦態勢ですごしております。
とにもかくにも体を冷やさぬようにすごしたいところです。
さて今回は、世界的なデータサイエンティストのコンペティションサイト「Kaggle」に参加したお話をしたいと思います。
分かりやすく言うと、「データサイエンティスト界の天下一武道大会」に参加して見聞き、経験したことをみなさまと共有できればと思います。
Kaggleとは
Kaggleは、データサイエンティストの天下一武道大会と申しました。
どのような形でコンペティションが開催されるかと申しますと、コンペティションを主催するスポンサー企業(と言って良いかと思いますが)が、Kaggleにデータを提供し、そのデータに対して世界中のデータサイエンティストが知恵と経験値を駆使して、予測モデルの性能を競い合うという形となっています。
ランキングはLeader Boardと呼ばれており(略:LB)、成績が良い順に「In the money」「Gold Medals」「Silver Medals」「Bronze Medals」の称号を手にすることができます。
In the money は上位数名で、この数名には賞金が支払われることが多いため本当に激戦区です。
賞金も総額1000万円とか数百万円など、本格的な規模感です。
「Gold Medals」「Silver Medals」「Bronze Medals」を手にするための順位の閾値は、参加人数によって変化します。
例えば、参加チームが1000チーム以上のコンペティションでは、「Bronze Medals」を手に入れるには上位10%以内にランクインすることが条件で、
「Silver Medals」は上位5%以内、「Gold Medals」は上位10位 + 0.2%の順位にいることが条件となります。
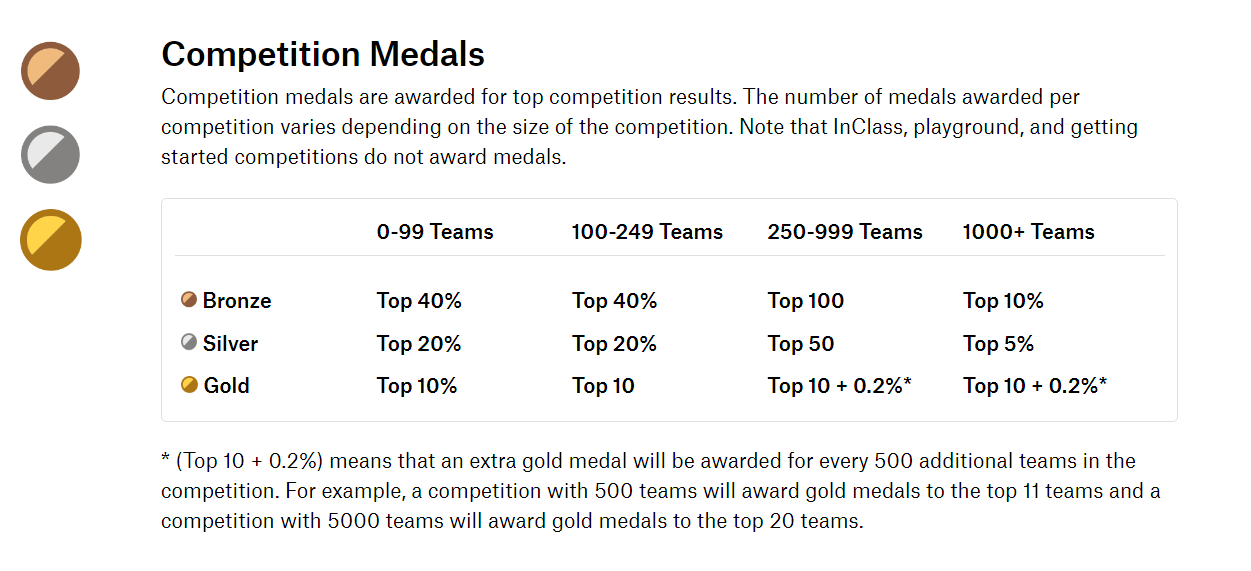
コンペティションで獲得できる Medals 以外に、Kernel(Jupyter Notebook を公開したもの)やDiscussionの分野でもメダルを取ることができます。
コンペティションの順位だけでなく、知見の共有や、コミュニティにおける議論の活性化に貢献することでも評価が得られるという、バランスよく考えられた仕組みになっています。
Kaggleは盛り上がるべくして盛り上がっていると言えるのではないかと思います。
なお、Kaggleのコミュニケーションは英語です。
コンペティションの説明画面も、ディスカッションのページも、サポート文書も全て英語です。
オンライン辞書やGoogle翻訳を駆使しながら、コンテンツを噛み砕いて理解すると、英語のトレーニングにもなるでしょう。
LBにランキングされている参加者の出身地を見ると、本当に世界中からコンペティションに参加していることが分かります。
欧米先進国は当然ながら、東南アジア、東欧、中東と世界の幅広い地域から参加しています。
最近は、東アジアでの参加者の増加が勢いづいているようです(特に中国)
日本でも近年認知度が上昇しており、Kaggleの日本コミュニティも活気付いています。
企業のデータサイエンティストや、大学生、大学院生など様々なバックグラウンドの参加者がいます。
Kaggleに参加するには、GoogleアカウントやFacebookアカウントがあれば、簡単に申し込むことができます。
このエントリにアクセスしたのをキッカケに、あなたもKaggleの世界にJoinしてはどうでしょうか?
今回参加したコンペティション
今回私が参加したコンペティションは、「Two Sigma: Using News to Predict Stock Movements」というものです。
コンペティションを主催するスポンサーは、世界的に有名なヘッジファンド「Two Sigma」です。
定量的なアプローチでファンドを運用し、目覚しい発展を遂げているヘッジファンドの一つです。
今回のコンペティションでは、米国株式市場の日足の取引データと、ロイターが提供する金融・経済ニュースのデータを
駆使して、将来の株価(=10日先の株価)のリターンを予測して競い合います。
具体的には各株の10日先における残差リターンを予測します。
残差リターンとは、ざっくりと説明すると市場の全体における相対的リターンの大きさと考えてください。
どの株も上昇している日では、株価は上昇しているだけでは駄目で、市場全体を見渡しても平均以上の上昇幅を見せなければ残差リターンはプラスにはなりません。
一方、どの株も下落する日では、株価がほとんど動かないだけでも、相対的なリターンは大きくなります。
ということで、単純な株価の上下ではなく、市場全体における相対的なポジションを予測するという手ごわい予測対象になります。
評価の仕方
評価基準となるスコアは、各営業日ごとのポートフォリオの合計残差リターンのシャープレシオです。
シャープレシオは、「平均値÷標準偏差」であり、値のばらつきが大きいと数値が悪化します。
よって、平均値が高いだけではなく、なるべくばらつきの小さい、高位安定となるように予測しなければなりません。
各営業日ごとに、評価対称となる株の銘柄が指定されています。
u_ti が1の銘柄が評価対象になります。
モデルの予測値 y^ は、-1.0から+1.0の値の範囲を取ります。
対象株の残差リターンが大きいと考えるほど、+1.0に近づき、残差リターンが小さいと考えるほど -1.0に近づきます。
残差リターンがプラスで、予測値 y^ がプラスであれば、スコアは加算されます。
また、実際の残差リターンがマイナスでも、予測値 y^ がマイナスであれば、スコアは加算されます。
(この計算処理は、株の空売りに相当します)
そして、各営業日におけるポートフォリオの残差リターンと予測の符号付加重の和を求め、その期間横断の平均値・標準偏差を計算し、シャープレシオを導出します。

このシャープレシオで本コンペティションのランキングを競い合います。
コンペティションへの参加方法
今回のTwo Sigmaのコンペティションは、Kernel を提出するタイプのものです。
Kernelは、Kaggleにログインした後、コンペティションの「Kernel」のページで、画面右上にある「New Kernel」をクリックすることで新規作成します。
コンペティションのデータセットに関連付けられたKernelが立ち上がります。
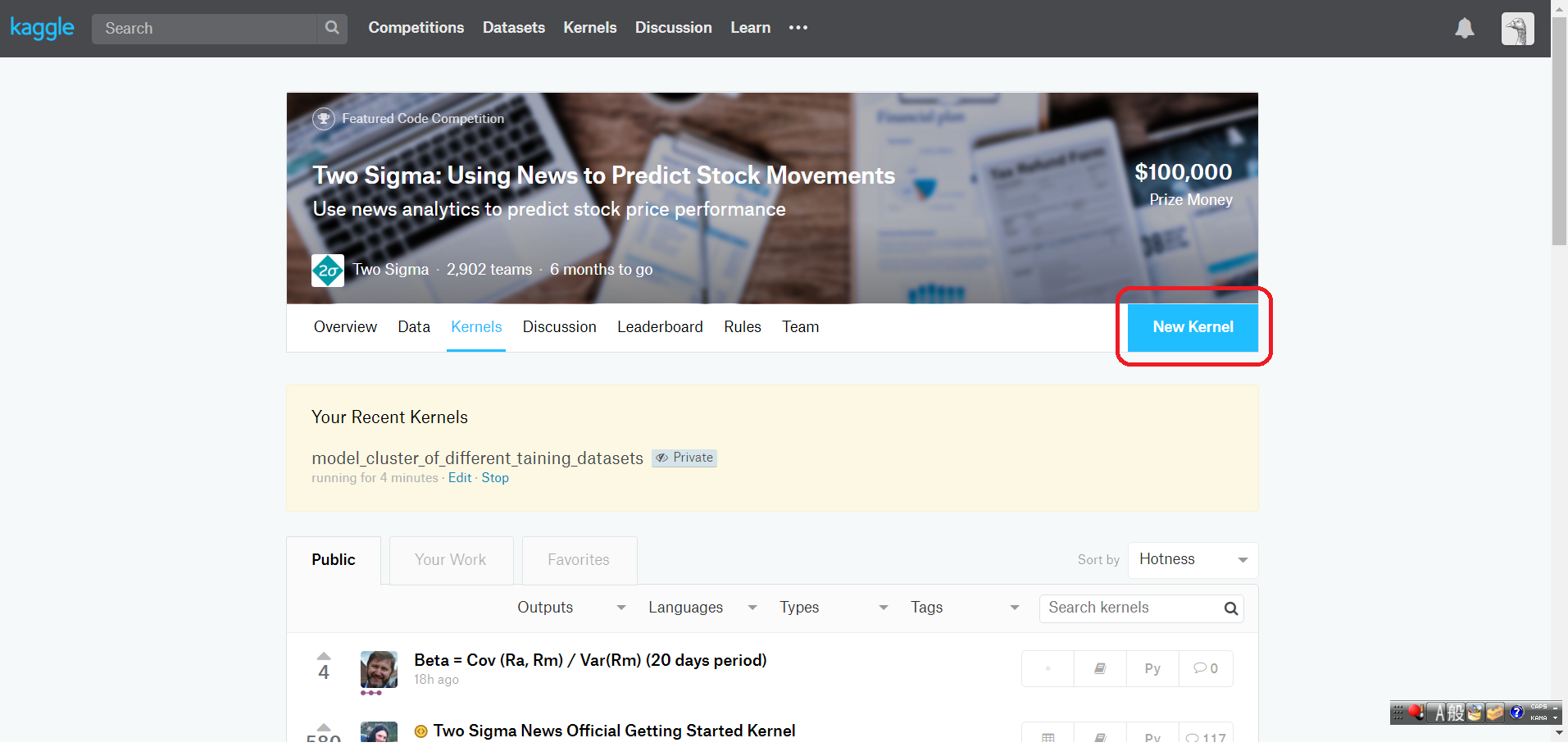
すると以下の画面のように、Jupyter Notebook に非常に近いインターフェースを持つ編集画面が起動します。
AWSやGCPでお馴染みの仮想マシンが起動しています。
メモリは約17GBにCPUは4つと、なかなか役に立つスペックを持っています。
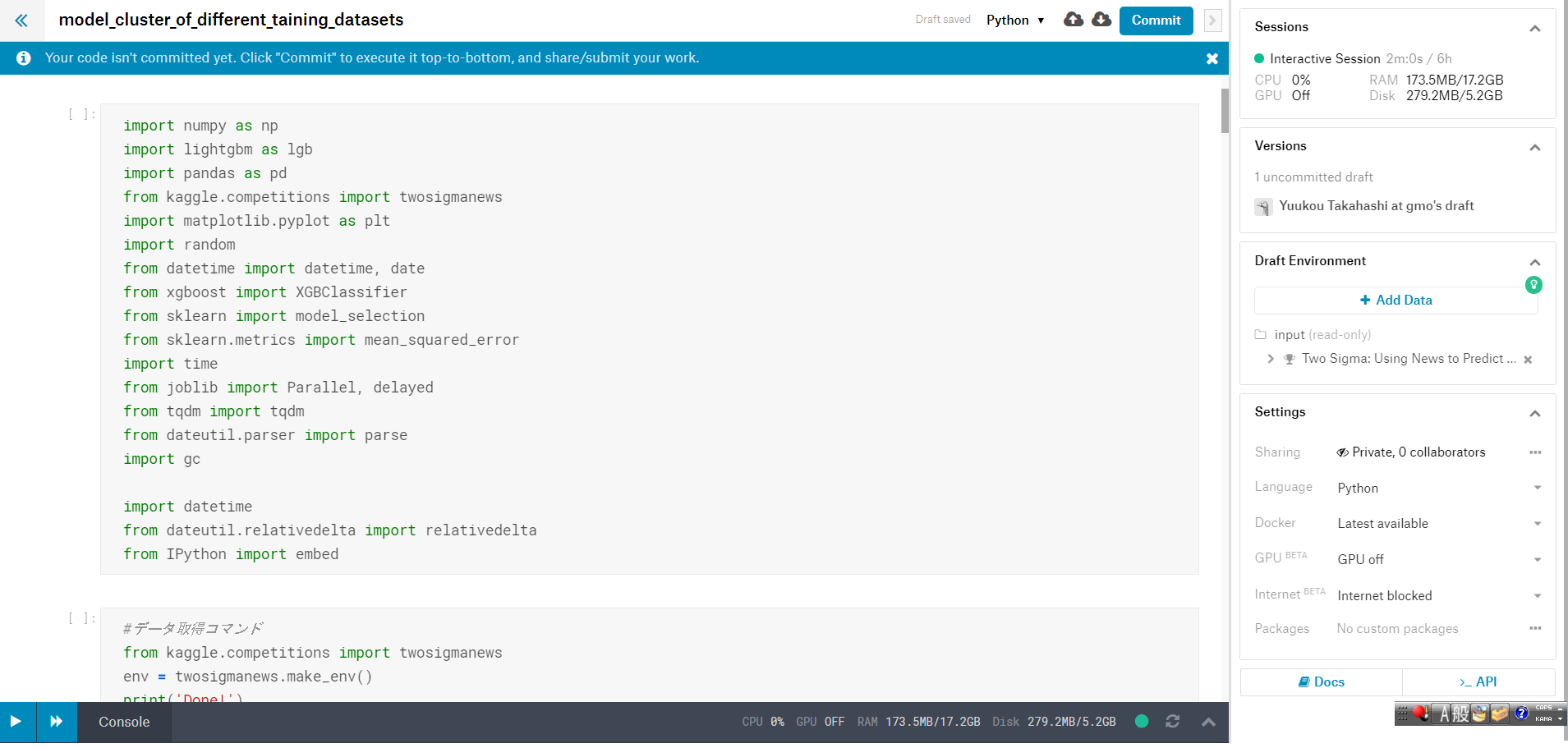
今回のコンペティションでは、この仮想マシンのスペックの制約の元でモデルを構築し、予測を出力するところまでPythonで実装します。
他のデータサイエンティストのKernelを見て学ぶ
Kaggleでは、世界中のデータサイエンティストがKernelを公開しています。
各コンペティションのKernelのページには、公開されているKernelの一覧がズラリと並んでいます。
他の人のソースコードを読むことで、たくさん学ぶことができます。
データサイエンスの手法を見に付け、発想にヒントを得る上で、非常に有益です。
今回のコンペティションで使われているモデルの種類とアプローチ
あくまで公開されているKernelに目を通した範囲の見解ですが、用いられているモデルの種類は大きく分けると以下の3つの模様です。
- lightGBM
- xgboost
- LSTM
株価の日足を学習データとするので、深層学習のLSTMは時系列が得意分野なので納得感のあるモデルの選択となりますね。
一方、xgboostとlightGBMですが、これらは特に時系列に特化したモデルではないのですが、Kaggleでは特に人気があるモデルです。
いずれも木構造を基本とするモデルで、ブースティング機能を搭載しており、精度面やスピード面で他のモデル(非深層学習モデル)より優れていると見られています。
LSTMを使う場合は、Keras(深層学習モデルの開発を容易にしてくれるフレームワーク)を用いて、ネットワーク構造を記述し、
株価の時系列データを入力して予測するというパターンが基本となります。
xgboost・lightGBMを使う場合、そのままでは時系列に対応していないので、移動平均などウィンドウ処理をして求めた統計量を特徴量として使う必要があります。
今回のコンペティションで苦労した点
そろそろ私のコンペティションにおける取り組みについて触れたいと思います。
実際に参加したのは、昨年の12月の下旬で、締め切りまで2週間ほどのタイミングでした。
まず、時間が圧倒的に足りないという点で苦労しました。
どこかでハマったら最後です。限られた時間内に、良い発想にたどり着けるかどうかの勝負であったように思います。
次に、スペック的な制約との格闘が重要なポイントであり、苦労した点でした。
●トレーニングデータが非常に大きいため、メモリの使い方を意識しないでデータ処理をしようものなら、あっという間に仮想マシンのメモリを枯渇させてしまいます。
●また、学習から予測結果の出力まで、トータルで9時間以内に収めなければなりません。
重たい計算処理を放置していると、散々待った挙句に仮想マシンが強制的にシャットダウンされて、結果ファイルを出力できずに終わってしまいます。
そのため、パフォーマンスチューニングの観点は、非常に重要でした。
私が取った方針は以下の通りでした。
(1)データ型は、必要最低限の精度にする。
pandas を使う際、数値型のカラムは64ビット float型 or int型がデフォルトです。これを 32ビットや可能であれば16ビットまで落とすことで、メモリ消費量をだいぶ抑えることができます。
(2)並列処理をする
前処理を行う際、並列処理が出来るところでは、並列処理を実施するわけです。
特に、各株式ごとの特徴量を計算する際には、並列処理が必須と言って良いと思います。並列処理をしないと、簡単に制限時間オーバーになってしまいます。
この2点に取り組むことで、モデル開発作業上の懸念が大きく解消されました。 しかし、苦労した点はこれだけではありませんでした。
モデル開発のPDCAサイクルを順調に回せるようになったは良いものの、肝心なのはモデルの予測精度です。
どんぐりの背比べのように、メダル獲得可能な順位の前でクラスターが出来ていました。 具体的には、スコア0.69の壁です。
この壁を突破できるかどうかで、メダル獲得射程圏内に入れるかどうかが決まります。
ランキング上では、上位の10%~15%の範囲にいる参加者が、スコア0.69付近に密集しています。
0.70台を達成すれば、一気に見える景色が変わり、メダル獲得射程圏が視界に入ってきます。 基本に忠実なアプローチは大事ではあるのですが、そこに拘泥すると壁を突破するのは難しいように思えました。
複数のモデルを構築してアンサンブル(xgboostやlightGBMは、既にアンサンブル学習モデルですが…)しても、決定打にはならず。
学習データの大部分を使ってモデルを構築していたのですが、うまくいきませんでした。 学習データの範囲によっては、予測に裏目に出る「ノイズ的な範囲」があるのではないか?
予測に貢献する「シグナル」を含む範囲が存在するのではないか? と考え、学習データをなるべくたくさんモデルに入力させるべしという考えから離れ、柔軟に試行錯誤を繰り返すことにしました。 結果的には、この発想が大きく予測精度改善に貢献しました。
範囲は狭くても、広い検証期間で良好な予測精度を発揮する学習期間が存在することが分かったのです。 後は、ひたすら良いシグナルが集中していると目される学習期間の探索に専念し、精度の良いモデルの数を20個ほど構築することができました。
そして、それらのモデルのアンサンブルを構築し、予測を出力することができました。
果たして結果は…
私個人のKaggleアカウントで獲得したベストスコアは0.71445となりました。
2019年1月15日時点でのランキングは124位、シルバーメダル圏内にランクインしています。
※今後、実際の株価のデータを追加しながらランキングの更新が行われます。
最終的には2019年7月15日までの株価データで予測を行い、ランキングが決定されます。
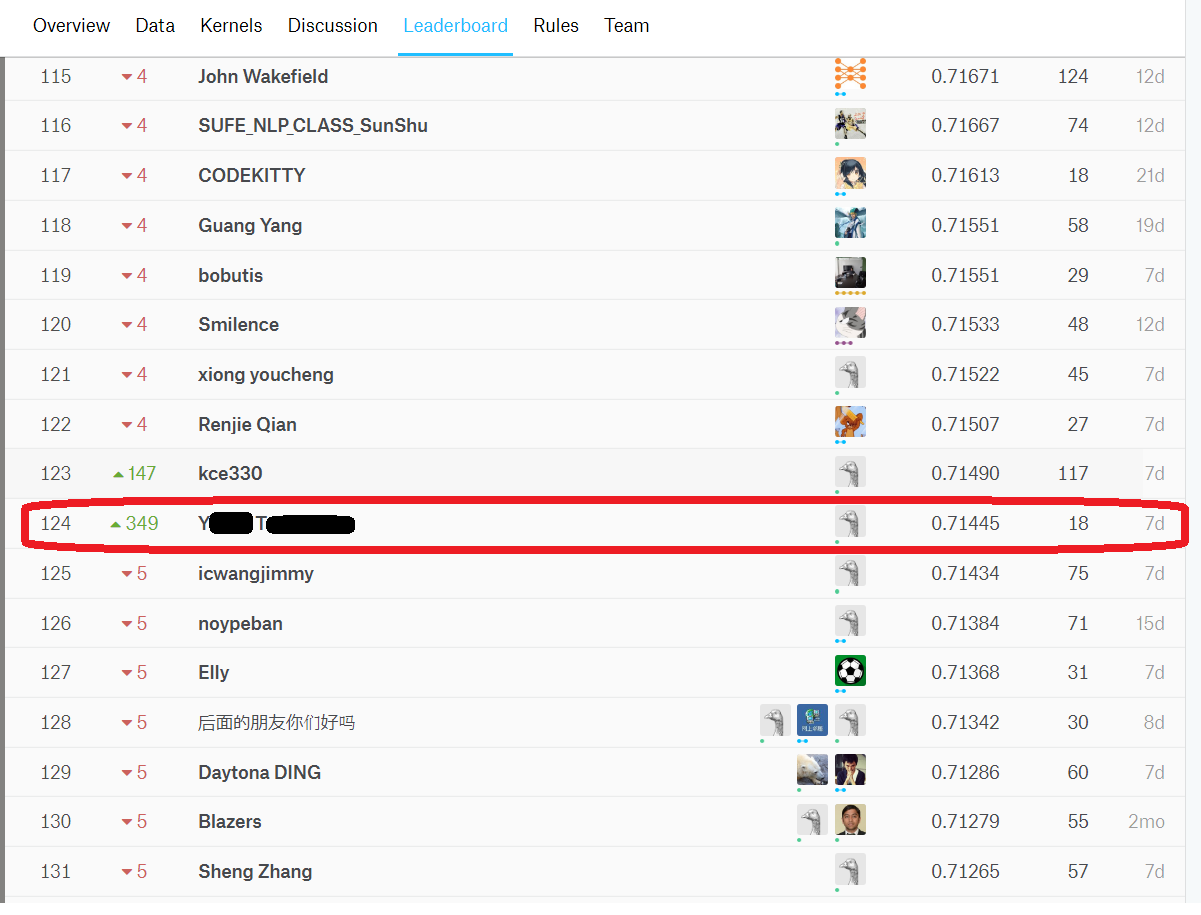
始めて参加したコンペティションでしたが、今のところは結果が出ているようです。(あと半年、予断を許さない状況が続きます…)
まとめ
今回は、最新の理論やテクノロジーではなく、体験談という形のエントリとさせていただきました。
こうしたコンペティションに参加することで、モチベーションも刺激され、切磋琢磨する環境に身を投じることができます。
データサイエンスの力を伸ばす上で、絶好のアプローチであると感じました。
また、固定観念にとらわれずに、あの手この手でアイディアを試すことの重要さを痛感したコンペティションでした。
(学習データをなるべく多くをモデルに食べさせるべし、という考えがひっくり返りました。もちろんこれは、データの種類にもよるとは思いますが…)
今後も様々なコンペティションに参加して、実戦さながらのデータと課題に取り組んでデータサイエンティストとしての力を鍛えて行きたいと思います。
最後に
次世代システム研究室では、機械学習や統計処理に関心を持つ開発者、アーキテクト、データサイエンティストを求めています。
次世代システム研究室にご興味を持たれたらすぐに 募集職種一覧 からご応募してください。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD