2017.10.05
Word2VecとAR技術で趣味を自動で可視化!趣味が見える名刺作成ツールShumiel
はじめに
こんにちは。次世代システム研究室の新入社員のY.Kです。
弊社では我々新入社員のエンジニア・クリエイター向けにGMOテクノロジーブートキャンプという研修カリキュラムが存在します。この研修ではIT関連の技術・知識の習得を目的とし、その集大成として二日間のハッカソン合宿を行います。今回は私のグループが作成したユーザーの趣味を自動で判別し、可視化出来るサービス「Shumiel」の紹介をさせていただこうと思います。
概要
我々が解決したかった課題としては、「初対面での話題の提供」というものがあります。
初対面の人とすることと言えば、SNSアカウントの交換などもありますが、プロフィールを入力するのが面倒だったり、入力されている情報が古い可能性もあります。
我々は初対面の人とすることの一つである「名刺交換」に着目し、最近の趣味を自動で判別し、ARで可視化出来る名刺を作成出来るサービスを作成しました。
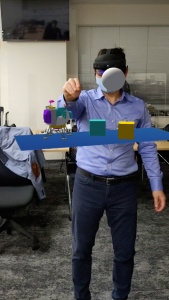
作れる名刺はこんな感じです。裏側のQLコードを読み取ってサイトにアクセスし、カメラでマーカーを写すと趣味を表す3Dモデルが表示されます。


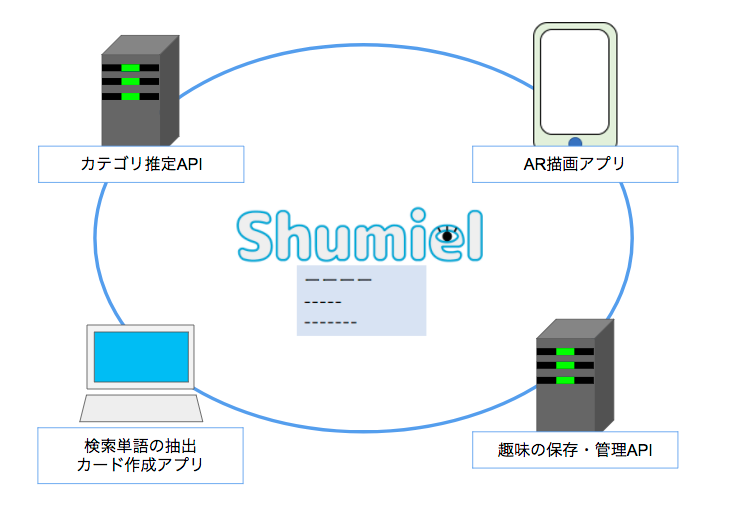
システム構成図は以下となります。
各システムの要素技術と問題点、改善点を説明していきます。
趣味データの収集 ~Chrome Extension~
最近の趣味を自動で判定するということで、今回は日常的に行われる検索に着目しました。
要するに、「よく調べてる単語は趣味を表すよね」ってことです。
実現するために用いたのはChromeの拡張機能です。
拡張機能は特定のURLを閲覧しているときのみ処理を行う設定が可能です。
今回は「https://www.google.co.jp/search?****」にいる場合にURLのパラメーターから検索語を取得し、以下の処理を行います。
- 趣味を判定するカテゴリ推定APIに検索語を投げる
- 検索語を形態素解析し、名詞を抽出する(カテゴリ推定API)
- 名詞から趣味を判定する(カテゴリ推定API)
- 返却された趣味データをDBに登録する
この拡張機能によって、ググるたびに自分の趣味を表すデータが自動で蓄積されていきます。
今回はGoogleのみをターゲットにしましたが、Yahoo!やBingなどを追加してすべての検索エンジンを網羅することも可能です。
ちなみにGoogleのURLの中で検索語はここにあります。
![]()
趣味の判別 ~Word2Vec・Flask~
今回のアプリの肝とも言える単語から趣味カテゴリを判別するAPIですが、至極単純な仕組みです。
カテゴリの尤もらしさを表す数値はズバリ、
「検索語に含まれる名詞とカテゴリを表す名詞のコサイン類似度」!!!!!そうです。ただのベクトル空間上の距離の近い単語をそのカテゴリとして返しているだけです。
「カテゴリ推定でも何でもないじゃないか!」と思われるかもしれませんが、Bag of WordsとSVMによるカテゴリ推定だって言ってしまえば分散表現の距離による分類です。
このコサイン類似度を測るベクトル空間には機械学習ツールWord2Vecを用いて、Wikipedia全文をベクトル化したものを利用しています。形態素解析器はMeCabを利用し、辞書は出来る限り新しい単語にも対応したいのでmecab-ipadic-NEologdを用いました。
API化するために用いたのはFlaskというフレームワークです。
採用した理由は
- 1つの機能しか作らないので、単純なフレームワークであるということ
- Word2VecのライブラリがあるPythonである
の2点です。
モジュールにFlask-RESTfulというものが存在しますが、こちらは利用せずともFlask単体でRESTful APIは作れます。(むしろ、Flask-RESTfulを使ったほうがややこしい印象を受けました。)
クロスオリジンアクセスを許可したAPIを作るのは以下だけでできます。他に必要なものはなく、たった1ファイルでAPIが動きます。今回のような簡単なAPIを作成するときには手軽で良いですね。
注意点としてはWord2Vecのベクトルデータはグローバルで読み込んでおくことです。
Wikipedia全文ともなるとバイナリ化してもとても容量が大きいので、リクエストのたびに読み込んでいたら確実にタイムアウトします。
from flask import Flask, request, jsonify, url_for, Response
from flask_cors import CORS, cross_origin
from gensim.models.word2vec import Word2Vec as w
# グローバルに定義して起動時に読み込む
model = w.load_word2vec_format('/path/to/vec_model', binary=True, unicode_errors='ignore')
model.init_sims(replace=True)
app = Flask("app")
cors = CORS(app) # クロスオリジン許可
@app.route('/category', methods=['POST'])
@cross_origin()
def create():
query = request.json['query']
return_dic = category(query); #queryとカテゴリの類似度を返却する
return jsonify(return_dic), 200
if __name__ == "__main__":
app.run()
単純な仕組みの割に直感的に正解と言える結果が返ってきますが、1位のカテゴリと他のカテゴリとの数値の差が単語によってまちまちです。結果の例を載せておきます。
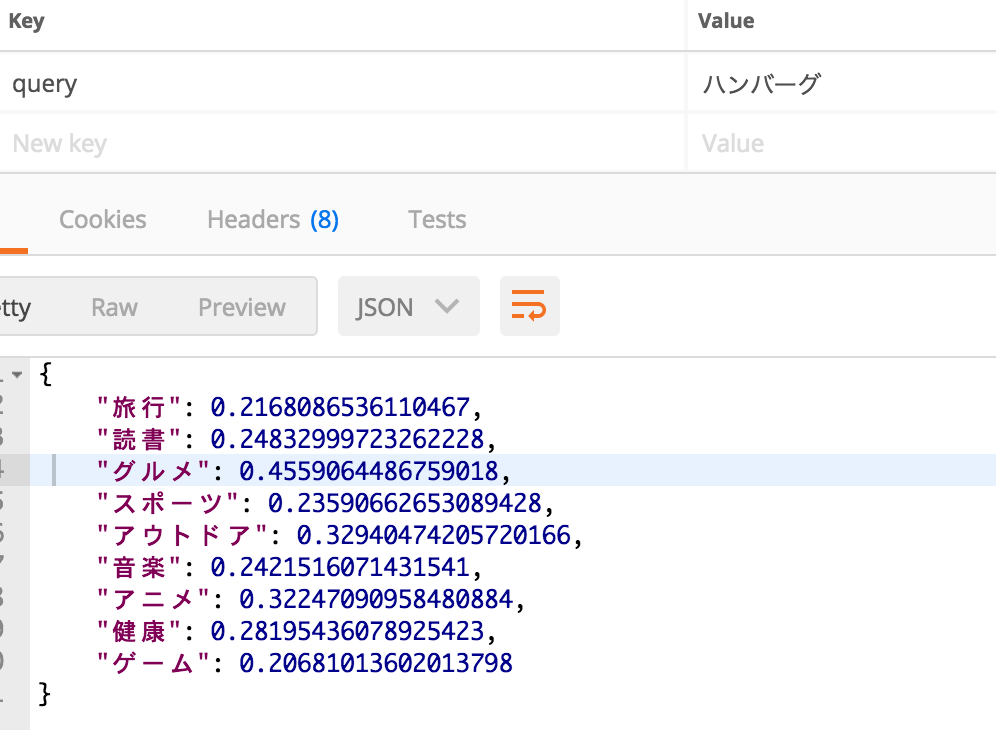
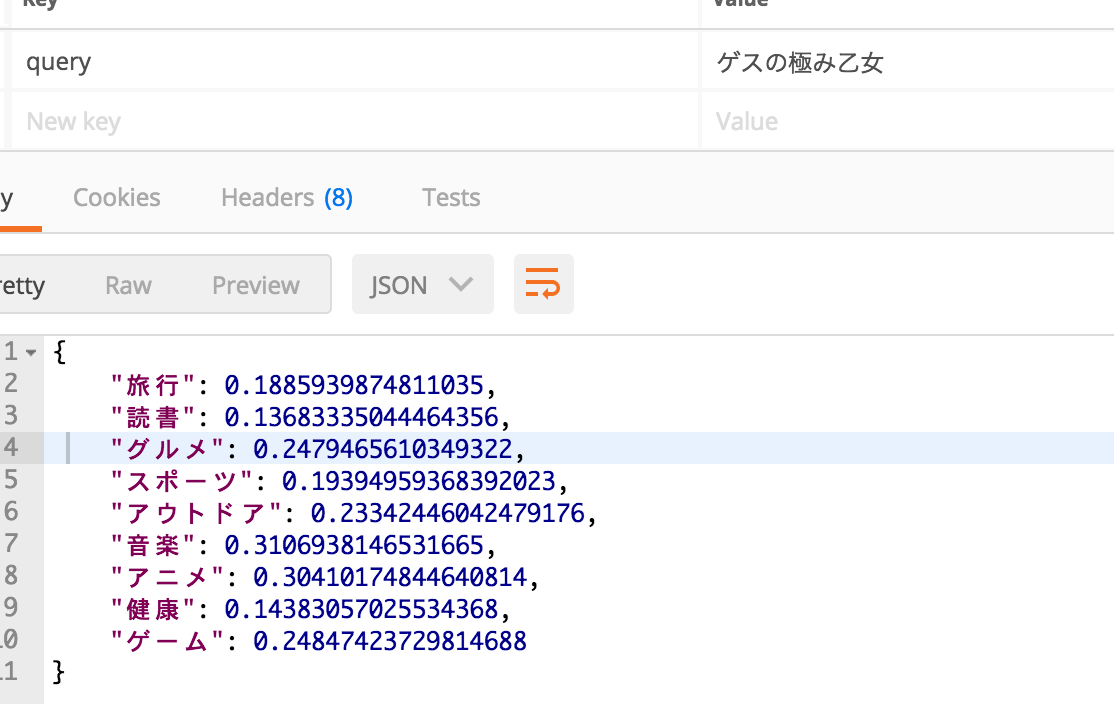
今回はそもそも各カテゴリを表す各単語自体の距離が等しくなかったため各カテゴリに有利不利があると考えられます。
単語の曖昧性を考慮してWord2Vecのベクトルをそのまま用いるか、各カテゴリの単語の距離や近傍単語の数などによって重みをつけるのか、議論の余地はありそうです。
認証 ~Json Web Token~
今回のアプリの認証の要件は、
- 趣味データの取得は誰にでも許可されなけれはならず、登録は本人にのみ許可されなければならない
- 誰でも取得出来ると言っても名刺であるため、渡した相手にのみ取得させたい(user_idなどの他のユーザーのものが推測されやすいパラメータを使うのは好ましくない。)
とし、取得用のトークンと登録用のトークンを発行して認証を行うようにしました。
一般的なトークン認証でこの要件を満たそうとすると、
- トークン用のテーブルを作成
- ランダムに作成したトークンとuser_idと取得用・登録用を判別するトークンタイプを保存
- 送られて来たトークンと一致するレコードが存在するか否かで認証を行う
結構めんどうくさいです。
もっと楽にできないかと検討し、今回利用したのはJSON Web Token(以下JWT)と呼ばれる”xxxxx.yyyyy.zzzzz”のような形式のトークンです。
これは[署名アルゴリズムなどの情報を含むJSONをBase64化した文字列].[利用するユーザー情報などを含めたJSONをBase64化した文字列].[前者2つから作成される署名]となっていて
- JSONは前述の通りBase64で複合可能なので中身を見ることができる
- 3つ目の署名はサーバーしか知り得ないキーによってそのBase64文字列から生成されるので、改竄が検知できる
といった特徴を有します。
これならば本来DBアクセスによって行う認証が不要で、ターゲットとなるuser_idやトークンタイプをすぐに取得できます。
今回は以下のようにuser_idとトークンタイプの2つの情報をJSONに持たせてJWTを発行しました。
{
"user_id": 123,
"token_type": 'register' or 'get'
}
拡張機能からログインした時点で取得用と登録用のトークンを発行します。
趣味カテゴリデータを登録する際は登録用トークンを利用、名刺のQRコードには取得用トークンを含めたURLを記載という風に利用しています。
今回のような複数の役割を持つトークン認証が必要な場合には便利なのでは無いでしょうか?
気になることと言えば、DBアクセスのオーバーヘッドと署名の計算コストにそこまで大きな差があるのかという点とJWTは有効期限が切れる以外に失効することが無いので万が一にでも漏洩した場合のリスクが高いのではないかという点ですかね。
名刺の作成 ~canvas~
名詞のレイアウト作成もブラウザから行えます。
今回はCanvasを用いて以下の機能を実装しました。利用したライブラリはjCanvasです。
- 背景の選択、追加
- 文言の追加
- サイズ・フォント・文字色の変更
- 画像ファイルとして保存
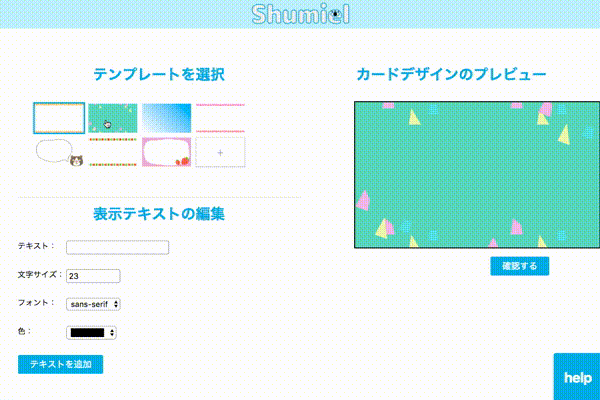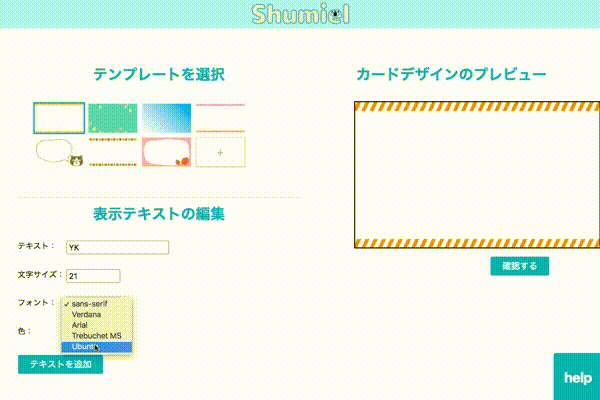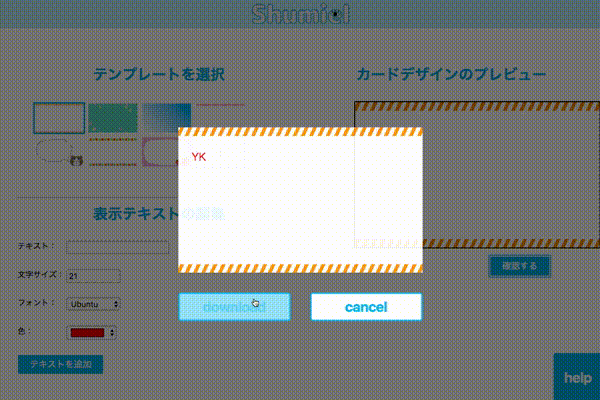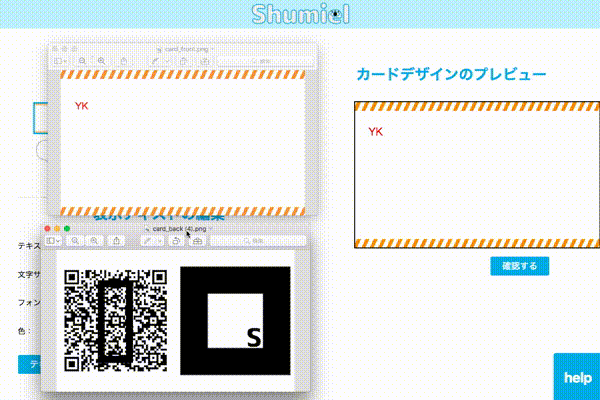
今回は画像で保存するところまでJSで完結できました。Canvasで作成した画像をそのまま印刷するところまでやりたかったですが、可能なAPIが見つからず断念。。。
画像を作成してDOMにhiddenで追加、DOMを印刷するAPIを叩くとかで実現できるのではないかと思っております。
趣味の可視化 ~AR.js~
趣味データの可視化にはAR.jsを用いています。
URLに記載されたJWTによってサーバーにアクセスし、JWTのJSONに含まれるuser_idのユーザーの趣味に対応する3Dモデルを表示します。
HTMLタグに属性を追加するだけでも簡単にARアプリが作成できることを謳っているAR.jsですが、もちろんJSで細かいアニメーションをつけたり、動的に表示するモデルを変化させたり等のカスタマイズもできます。
今回はアニメーションをつける時間はなかったのですが、表示されるモデルごとに異なるアニメーションを作成できればもっと洗練されたアプリが作れたかなと思います。
ここにサンプルも有るので興味のある方は色々試してみてはいかがでしょう?



苦労した点
今回一番苦労した点は、SSL問題でした。
GoogleがHTTPSであるため検索単語をAPIに投げるときにHTTPSでないとChromeによって弾かれます。なので本番でもSSL化しなくてはなりませんし、ローカルでは動きません。。。
更に、AR.jsによるウェブカメラへのアクセスもHTTPSでないと動きません。
結局自分が持っていたドメインでLet’s EncryptによってSSL対応をすることにしました。
Let’s Encryptさまさまですね。持っててよかった独自ドメイン!!!
その他苦労したことと言えば、初めて使うFlaskの本番デプロイに手間取ったり、3Dモデルの調整が大変だったり等ですね。
3Dモデルは無料のものがたくさんあるのですが、webで使うには容量が大きいものが多かったので容量削減(メッシュを極限まで減らすなど)の謎のチューニングをしていたことですかね。3Dモデル初心者には用語がわからなさすぎて辛かったです。少なくともハッカソンでやるものではなかった。。。
まとめ
まだまだ、改善できるところは多いですが、楽しく研修を終えることができました。
ARなどのライブラリが洗練されてきた影響で誰でも簡単にWebARプロダクトを作成できるようになってきました。
今回のように動的に表示するものを変化させることが出来るのは大変おもしろく、このような技術を用いることでエンターテイメントの幅が広がっていくのではないかとワクワクしております。
次世代システム研究室では、アプリケーション開発や設計を行うアーキテクトを募集しています。アプリケーション開発者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD