2019.02.13
Doc2Vecをいい感じに評価したい
- 定性的評価: カテゴリを使わない場合(教師なしデータとして扱う)について、定性的に評価を行う。
- 定量的評価: カテゴリのある文章で、Doc2Vecのベクトルを教師あり学習に使うことで定量的な評価を行う。
ブログの構成
今回のブログの内容の詳細はGitHubにあります。このブログでは、このうち主な結果について説明します。概要は以下の3つに大きく分けられます。まずSection Aでは、パラメータなどは固定しておき、データ加工→トレーニング→評価までの一連のプロセスを説明します。次にSection Bでは、Aで説明した評価方法を用いて、前処理1のモデルについてハイパーパラメータのチューニングをして定量的な評価を行います。最後にSection Cで、A, Bとは異なる前処理(前処理2)を施したデータによるDoc2Vecモデルを作成して、前処理1の場合と(説明した評価方法を用いて)比較します。骨子は以下の通りです(各セクション毎にGitHubのリンクを貼っておきます)。 A デフォルトA-1 データの説明&データ加工(前処理1)の説明 (github link)
A-2 Doc2Vecのトレーニング (github link)
A-3 定性的評価 (github link)
A-4 定量的評価 (github link)
B ハイパーパラメータのチューニング
B-1 ハイパーパラメータの説明 (github link)
B-2 チューニング (github link)
B-3 評価 (github link)
B-4 考察 (github link)
C 前処理を変更して (前処理2)、前処理1のモデルと比較
C-1 前処理1とは異なるデータ加工(前処理2)の説明 (github link)
C-2 チューニング (github link)
C-3 評価 (github link)
C-4 考察 (github link)
A デフォルト
A-1 データの説明&データ加工(前処理1)の説明
定量的評価をする際に、カテゴリデータ(教師データ)が必要になります。そこで、livedoor news corpusというカテゴライズされたウェブ記事をデータとして使用します。しつこいようですが、Doc2Vecのトレーニングには教師データは不要です。定量的評価のために必要になります。 データの内容以下のlivedoor newsの以下の9カテゴリ毎の記事が、1記事=1ファイルの形でまとめられています。約800記事/カテゴリで、トータルで約7000記事あります。- topic-news: トピック(トレンド)
- sports-watch: スポーツ
- it-life-hack: IT系
- kaden-channel: 家電・PC
- movie-enter: 映画
- dokujo-tsushin: 女性(生活系)
- smax: スマホ
- livedoor-homme: 男性(生活系)
- peachy: 女性(美容系)
- 最低限の前処理を行い、
- 形態素解析で単語に分かち書きをする、
以下のように、データ加工されます。NTTドコモ、公式オンラインショップでも端末複数台購入で最大10,500円/台の割り引きが受けられる「家族セット割」を開始 NTTドコモは17日、公式オンラインショップ「ドコモオンラインショップ」において端末を複数台同時購入した場合に1台当たり最大10,500円を割り引く…
もう少し詳しい説明はGitHubにあります。[‘NTTドコモ’, ‘、’, ‘公式’, ‘オンラインショップ’, ‘で’, ‘も’, ‘端末’, ‘複数’, ‘台’, ‘購入’, ‘で’, ‘最大’, ’10’, ‘,’, ‘500円’, ‘/’, ‘台’, ‘の’, ‘割り引き’, ‘が’, ‘受け’, ‘られる’, ‘「’, ‘家族’, ‘セット’, ‘割’, ‘」’, ‘を’, ‘開始’, ‘NTTドコモ’, ‘は’, ’17日’, ‘、’, ‘公式’, ‘オンラインショップ’, ‘「’, ‘ドコモ’, ‘オンラインショップ’, ‘」’, ‘において’, ‘端末’, ‘を’, ‘複数’, ‘台’, ‘同時’, ‘購入’, ‘し’, ‘た’, ‘場合’, ‘に’, ‘1’, ‘台’, ‘当たり’, ‘最大’, ’10’, ‘,’, ‘500円’, ‘を’, ‘割り引く’, …]
A-2 Doc2Vecのトレーニング
A-1で加工したしたデータをインプットとしてDoc2Vecを学習します。Doc2Vecはgensimのライブラリを使います。トレーニング方法は簡単で、単純に公式document通りにすればよいだけです。一応、GitHubにもトレーニングのコードを書いておきました。A-3 定性的評価
A-2でトレーニングしたDoc2Vecモデルが適切に学習できたかを、まずはカテゴリデータを用いずに(= 教師なしデータとして扱い)評価する方法を考えます。定量的(数値を基準)な評価ではなく、「だいたい合ってそう」など人の感覚を基準に評価しています。A-3-1 評価方法
「学習したベクトルのcosine類似度」と「文章の類似度」に相関があるか、人が見て判断 具体的には以下のようなプロセスになります。- ある記事ベクトルを任意に選び(記事a)、さらにランダムに複数記事(記事b-1,記事b-2, …)を選ぶ。
- 記事aとb-1, b-2…の間のベクトルのcosine類似度を計算する。
- 上記の記事の内容を表示して、文章の類似度を人が判断する。
- Doc2Vecが適切に学習できていれば、cosine類似度の値が高い記事→(人が判断した)文章の類似度も高く、cosine類似度の値が低い記事→(人が判断した)文章の類似度も低く、なるはず。
A-3-2 結果
一例を上げると、以下のようになります。他の記事の例については、GitHubを参照。文章aの記事は「サッカー」の話題。記事a ([‘「’, ‘広島’, ‘の’, ‘せい’, ‘に’, ‘する’, ‘な’, ‘」’, ‘浦和’, ‘・’, ‘槙野智章’, ‘の’, ‘インタビュー’, ‘が’, ‘ひんしゅく’, ‘\u3000’, ‘「’, ‘週プレ’, ‘NEWS’, ‘」’, ‘が’, ‘掲載’, ‘し’, ‘た’, ‘浦和レッズ’, ‘の’, ‘日本代表’, ‘DF’, ‘槙野智章’, …) 記事b-1: cos類似度=0.93 ([‘【’, ‘Sports’, ‘Watch’, ‘】’, ‘戦線離脱’, ‘の’, ‘香川’, ‘が’, ‘コメント’, ’30日’, ‘放送’, ‘、’, ‘TBS’, ‘「’, ‘情熱大陸’, ‘」’, ‘で’, ‘は’, ‘、’, ‘ドイツ’, ‘・’, ‘ブンデスリーガ’, ‘の’, ‘ボルシア・ドルトムント’, ‘で’, ‘活躍’, ‘する’, ‘日本代表’, ‘・’, ‘香川真司’, …) 記事b-2: cos類似度=0.91 ([‘大人’, ‘女子’, ‘が’, ‘スカート’, ‘の’, ‘下’, ‘に’, ‘秘める’, ‘べき’, ‘もの’, ‘と’, ‘は’, ‘?’, ‘「’, ‘ナマ’, ‘足’, ‘」’, ‘という’, ‘言葉’, ‘など’, ‘ない’, ‘頃’, ‘は’, ‘、’, ‘大人’, ‘の’, ‘女’, ‘が’, ‘スカート’, ‘の’, ‘下’, ‘に’, ‘ストッキング’, ‘を’, ‘履く’,…) 記事b-3: cos類似度=0.89 ([‘落合’, ‘氏’, ‘、’, ‘大いに’, ‘語る’, ‘「’, ‘来年’, ‘ユニフォーム’, ‘着る’, ‘って’, ‘なっ’, ‘たら’, ‘、’, ‘ここ’, ‘まで’, ‘は’, ‘喋ら’, ‘ない’, ‘」’, ’17日’, ‘深夜放送’, ‘、’, ‘日本テレビ’, ‘「’, ‘Going!’, ‘Sports’, ‘&’, ‘News’, ‘」’, ‘で’, ‘は’, ‘、’, ‘今季’, ‘をもって’, …) 記事b-4: cos類似度=0.77 ([‘【’, ‘ニュース’, ‘】’, ‘KDDI’, ‘音楽’, ‘配信サービス’, ‘配信’, ‘「’, ‘LISMO’, ‘Music’, ‘Store’, ‘」’, ‘を’, ‘年内’, ‘終了’, ‘へ’, ‘KDDI’, ‘は’, ‘、’, ‘2011年’, ’12月8日’, ‘を’, ‘もっ’, ‘て’, ‘、’, ‘着うたフル’, ‘や’, ‘ビデオクリップ’, ‘の’, ‘PC’, ‘向け’, …) 記事b-5: cos類似度=0.60 ([‘イー・アクセス’, ‘、’, ‘8月’, ‘発売予定’, ‘の’, ‘クアッドコア’, ‘CPU’, ‘と’, ’16’, ‘コア’, ‘GPU’, ‘を’, ‘搭載’, ‘し’, ‘た’, ‘ハイエンド’, ‘タブレット’, ‘「’, ‘GT’, ’01’, ‘」’, ‘の’, ‘発売’, ‘を’, ‘延期’, ‘!’, ‘発売’, ‘時期’, ‘は’, ‘未定’, ‘ファーウェイ’, …)
- 文書bのうち、最も近い類似度=0.93を出しているのはサッカーの話題。
- 類似度=0.88と高い記事も野球の話題で、スポーツ系の記事。
- 唯一おかしいのは「女性のナマ足」の記事で、なぜか0.91と類似度が高い。「足」つながり?
- 残りの記事は類似度が低く、実際に内容もサッカーと異なるので良い感じ。
A-3-3 考察
(完璧ではないものの)良い感じで評価できているのがわかります。今回の実験では、ベクトルと文章の内容の類似度が完璧に一致しているわけではないことは確認できるので、doc2vecをトレーニングのtuningをして、この一致度が上がればより良いモデルになったと評価できるでしょう。 ただし「どのくらい良いか」の判断は定性的評価なので難しいですね。また上記ではわかるのは明らかに精度が改善・改悪された場合だけで、微妙な精度の違いを評価するのは難しいでしょう。A-4 定量的評価
A-2でトレーニングしたDoc2Vecモデルが適切に学習できたかを、カテゴリデータ(= 教師データ)を用いて評価を行います。A-3の定性的評価と異なり、”正解”がわかっているので定量的な評価が可能になります。A-4-1 評価方法
- Doc2Vecモデル学習したDocベクトルをfeature、カテゴリを教師データとして教師あり学習をする。
- 教師あり学習の正解率(accuracy)を評価基準にする。
- doc2vecが適切に学習できていれば、正解率が高くなるはず。
A-4-2 結果
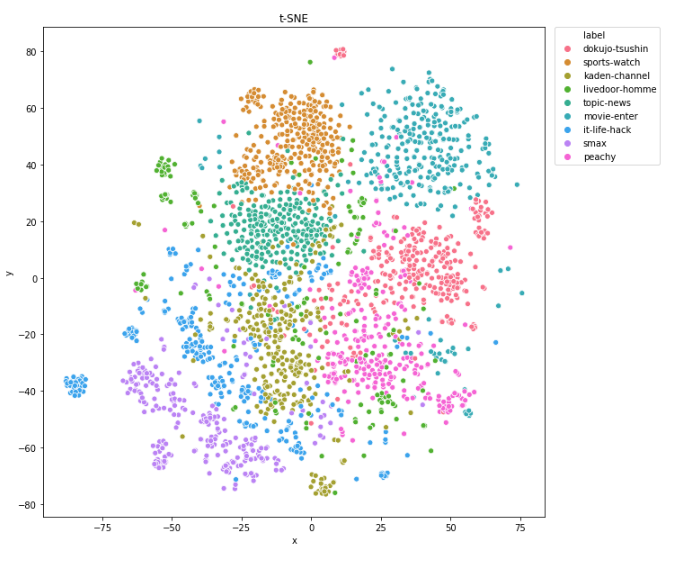
A-4-1の教師ありの学習の結果、テストデータの正解率(accuracy)は79%でした。悪くはない精度ですが、間違いもまだまだあるという値ですね。これは教師なしの評価の感覚ともconsistentです。この評価方法は、doc2vecのモデル精度(= vector情報)を適切に評価できている、と言ってよさそうですね。 9つのカテゴリ毎にも評価値を算出しました。「smax, movie-enterは精度が良く、livedoor-hommeは低い」などの傾向がわかります。 [table id=38 /] このことは、t-SNE(次元圧縮の手法)で2次元plot(下図)してみても直感的にわかりますね。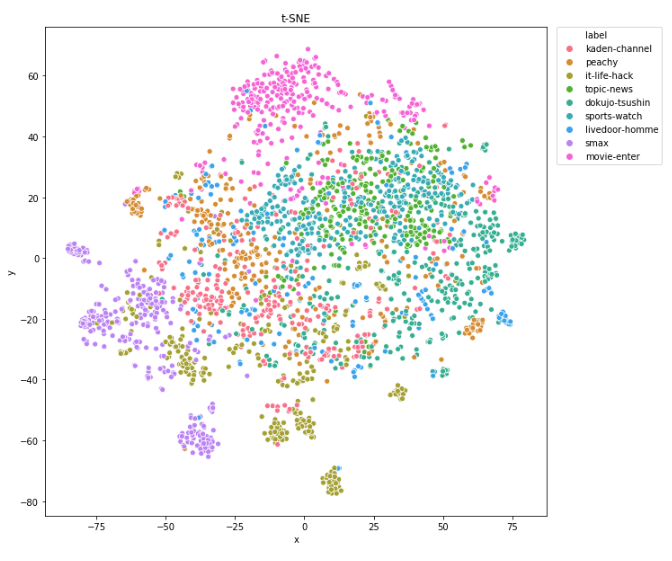
pred_cat: movie-enter real_cat: movie-enter words:[‘【’, ‘2012年’, ‘先取り’, ‘映画’, ‘vol.5’, ‘】’, ‘名’, ‘も’, ‘なき’, ‘メイド’, ‘たち’, ‘の’, ‘声’, ‘を’, ‘集め’, ‘、’, ‘時代’, ‘を’, ‘変え’, ‘た’, ‘一’, ‘冊’, ‘の’, ‘「’, ‘ストーリー’, ‘」’, ‘\u3000’, ‘2012年’, ‘に’, ‘公開’, ‘を’, ‘控える’, ‘新作映画’, ‘の’, ‘中’, ‘で’, ‘、’, ‘MOVIE’, ‘ENTER’, ‘編集部’, ‘オススメ’, ‘の’, ‘作品’, ‘を’, ‘紹介’, ‘する’, ‘「’, ‘2012年’, ‘先取り’, ‘映画’, ‘」’, ‘。’, ‘“’, ‘映画’, ‘は’, ‘芸術’, ‘ハラ’, ‘”…] pred_cat: livedoor-homme real_cat: livedoor-homme words:[‘プロ’, ‘に’, ‘聞く’, ‘“’, ‘合コン’, ‘の’, ‘極意’, ‘”’, ‘(’, ‘前編’, ‘)’, ‘\u3000’, ‘合コン’, ‘アナリスト’, ‘水’, ‘谷麻’, ‘衣’, ‘に’, ‘聞く’, ‘、’, ‘合コン’, ‘の’, ‘勝ち’, ‘パターン’, ‘と’, ‘は’, ‘\u3000″‘, ‘合コン’, ‘総研’, ‘アナリスト’, ‘”‘, ‘の’, ‘水谷’, ‘麻衣’, ‘さん’,…]「該当カテゴリらしい」記事内容を適切に予測できているのがわかります。movie-enterは「映画の話」で”映画”という単語もあるし、正解しやすそうですね。livedoor-homme(男性生活)も「合コンの話」なので、「該当カテゴリらしい」といえそうです。このことからも、doc2vecがある程度うまく学習できていることがわかりますね。 間違いのケース 間違いは大きく2種類に分けられます。
- doc2vecが適切に学習できていないケース
- 記事内容から、カテゴリ分けするのが難しいケース(教師カテゴリと記事内容が適切にマッチしていない, etc)
最初の記事は1の例です。予測は女性生活系ですが実際は男性生活系のカテゴリでした。どちらも生活系なので、大きく外したわけではないですが、記事には”サラリーマン”、’’お小遣い”などの単語があり、Docベクトルが十分な情報量を持っていれば正解したと考えられます。まだまだDoc2Vecの学習精度が悪い、という事がわかる例ですね。 2番目の記事は2の例です。ゲームイベント紹介の記事で、家電・PC系と予測していますが、実際は男性生活系のカテゴリでした。内容的には、カテゴリ分けが難しいケースと言えますね。pred_cat: dokujo-tsushin(女性生活系) real_cat: livedoor-homme(男性生活系) words:[‘サラリーマン’, ‘格差社会’, ‘の’, ‘現実’, ‘、’, ‘借金’, ‘or’, ‘貯蓄’, ‘1’, ‘,’, ‘000’, ‘万’, ‘円’, ‘に’, ‘二極化’, ‘6月28日’, ‘、’, ‘livedoor’, ‘HOMME’, ‘にて’, ‘、’, ‘オトナ’, ‘の’, ‘お小遣い’, ‘事情’, ‘に関する’, ‘緊急’, ‘アンケート’, ‘を’, ‘実施’, ‘し’, ‘た’, ‘。’, ‘短い’, ‘時間’, ‘ながら’, ‘累計’, ‘8’, ‘,’, ‘416’, ‘(’, ’29日’, ’10時’, ’30分’, ‘現在’, ‘)’, ‘も’, ‘の’, ‘非常’, ‘に’, ‘多く’, ‘の’, ‘方々’, ‘に’, ‘ご’, ‘協力’, ‘いただい’, ‘た’, ‘。’, ‘この’, ‘場’, ‘を’, ‘お’, ‘借り’, ‘し’, ‘て’, ‘お礼’, ‘申し上げ’, ‘たい’, ‘。’, ‘さて’, ‘、’, ‘この’, ‘緊急’, ‘アンケート’, ‘で’, ‘は’, ‘、’, ‘驚く’, ‘べき’, ‘結果’, ‘が’, ‘明らか’, ‘に’, ‘なっ’, ‘た’, ‘。’, ‘今回’, ‘は’, ‘アンケート’, ‘結果’, ‘を’, ‘もと’, ‘に’, ‘、’, ‘僕ら’, ‘現代’, ‘サラリーマン’, ‘の’, ‘貯蓄’, ‘事情’,…] pred_cat: kaden-channel(家電・PC) real_cat: livedoor-homme(男性生活系) words:[‘ハンゲーム’, ‘が’, ’10周年’, ‘、’, ’30万人’, ‘の’, ‘大規模’, ‘リアルタイム’, ‘・’, ‘オンライン’, ‘イベント’, ‘開催’, ‘!!’, ‘国内’, ‘最大級’, ‘の’, ‘インターネットゲームポータルサイト’, ‘「’, ‘ハンゲーム’, ‘」’, ‘が’, ‘、’, ’11月1日’, ‘に’, ‘サービス開始’, ’10周年’, ‘を’, ‘迎える’, ‘。’, ‘これ’, ‘を’, ‘記念’, ‘し’, ‘て’, ‘、’, ‘ハンゲーム’, ‘を’, ‘運営’, ‘する’, ‘NHN Japan’, ‘で’, ‘は’, ‘、’, ‘ハンゲーム’, ‘ユーザ’, ‘と共に’, ‘、’, ‘グループ’, ‘スタッフ’,…]
A-4-3 考察
評価方法が(ある程度)適切に定量的評価ができていることがわかりました。注意点としては、「教師カテゴリと記事内容が適切にマッチしていない」ケースもあるので、「doc2vecの評価を目的とする場合、正解率100%を目指すことは適切ではない」ことを忘れないこと。むしろ(このデータセットの場合)正解率100%近くなったらoverfit(記事内容ではなく、特定の単語やURLで”正解”を学習している,etc)を疑った方がよさげですね。 この評価方法は、parameter tuningするとき正解率を相対的に比較する事で評価に用いる、などが適切な使い方といえるでしょう。また数値だけでなく、文章を表示したりベクトルを2次元plotするなど多角的・定性的にも理解した方が安心ですね。B ハイパーパラメータのチューニング
Aで説明した評価手法を用いて、Doc2Vecのhyper parameterをTuningします。Doc2Vecの学習で用いるfeatureは前処理1のデータ(A-1で作成したデータ)です。B-1 ハイパーパラメータの説明
Doc2Vecのトレーニングに使われるハイパーパラメータの意味は、以下のようになっています。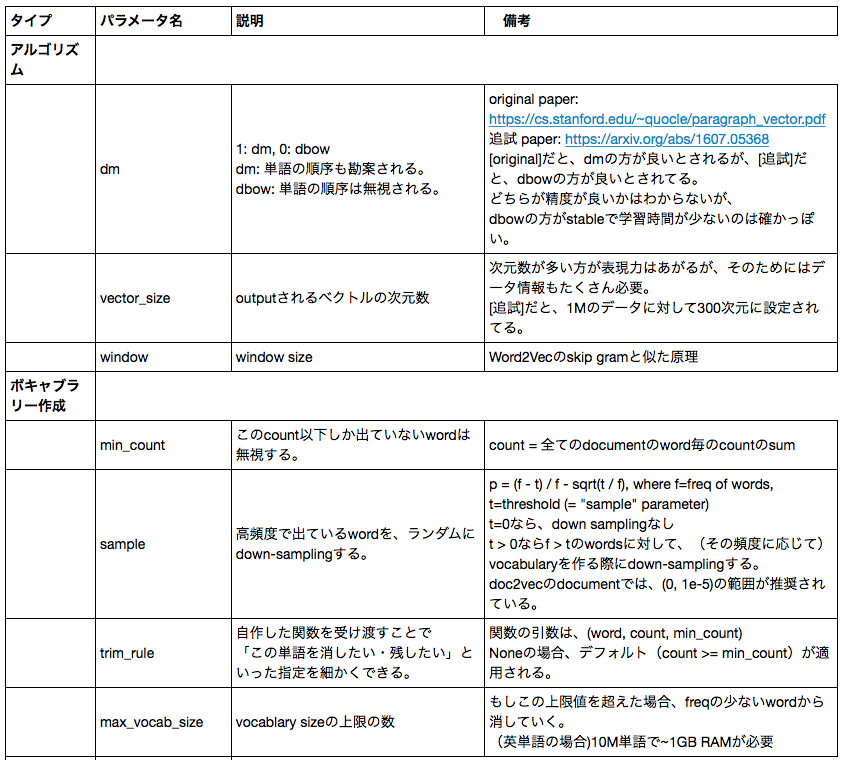
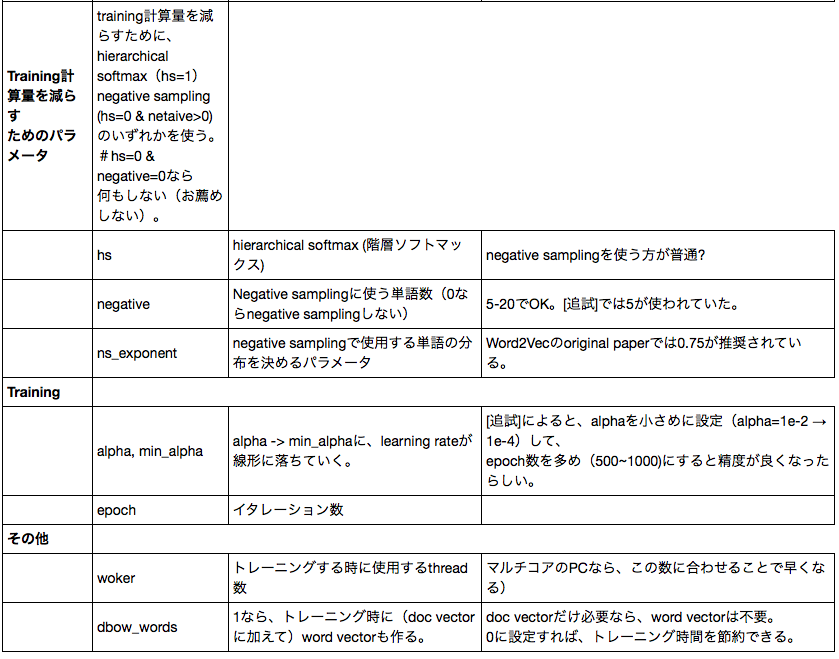
B-2 チューニング
Tuningの方法は以下のようにしました。- tuningするhyper parameterを一つ決める。
- 該当するhyper paramterをある値に設定する。
- doc2vecをトレーニングする。
- A-4で説明したカテゴリ予測の教師あり学習で(カテゴリ予測の)モデル精度を測定する(モデル精度が高ければ、input data (= doc2vecのvector)の情報量が高い、と推定できる)。
- 上記2~4を色々な値で試して、モデル精度の高いhyper parameterを採用する。
- epochs: 5 → 30
- min_alpha: 1e-4 → 1e-4
- sample: 1e-3 → 1e-3
- min_count: 1 → 5
- window: 15 → 15
- vector_size: 50 → 100
B-3 評価
上記のA, BのパラメータセットをA-4の方法で定量的に評価すると、- A(最適化前): 正解率=79%
- B(最適化後): 正解率=91%
B-4 考察
上記のことから、hyper parameter tuningが重要なのがわかります。また今回のデータセットでは、以下のようなことがわかりました。- 一番大きな影響があったのはepoch。今回のデータセットでは文章量が少なかったため、epochを大きく設定すると精度が上がる。
- min_count, vector_size, sampleも適切に設定することが大事。これらはデータに依存するので、都度tuningする必要あり。
- min_alpha, window_sizeは、だいたい常識的な範囲に設定すれば精度に大きな影響はない。
C 前処理を変更して (前処理2)、前処理1のモデルと比較
A, Bで用いたデータセット(前処理1で加工)とは別の加工方法(前処理2)を用いて準備したデータセットでDoc2Vecモデルを学習させます。BとCの場合の比較を(上記の評価方法で)行い、前処理の相違がモデルにどのような影響を与えるかを評価します。C-1 前処理1とは異なるデータ加工(前処理2)の説明
前処理1(A-1参照)は非常に簡素にデータ加工をしました。ここでは、もう少し多くの処理を入れ込んだ前処理(前処理2)を行ってみます。前処理2では、以下のような処理を追加しました。- 不要と思われる品詞の除去
- 品詞を原形に変換
- stop wordの除去
- 数字を全て0に変換
- 全角→半角変換
前処理2 [‘nttドコモ’, ‘公式’, ‘オンラインショップ’, ‘端末’, ‘複数’, ‘購入’, ‘最大’, ’00’, ‘000円’, ‘台’, ‘割り引き’, ‘受ける’, ‘家族’, ‘セット’, ‘割’, ‘開始’, ‘nttドコモ’, ’00日’, ‘公式’, ‘オンラインショップ’, ‘ドコモ’, ‘オンラインショップ’, ‘端末’, ‘複数’, ‘同時’, ‘購入’, ‘する’, ‘場合’, ‘0’, ‘当たり’, ‘最大’, ’00’, ‘000円’, ‘割り引く’,…] 前処理1 [‘NTTドコモ’, ‘、’, ‘公式’, ‘オンラインショップ’, ‘で’, ‘も’, ‘端末’, ‘複数’, ‘台’, ‘購入’, ‘で’, ‘最大’, ’10’, ‘,’, ‘500円’, ‘/’, ‘台’, ‘の’, ‘割り引き’, ‘が’, ‘受け’, ‘られる’, ‘「’, ‘家族’, ‘セット’, ‘割’, ‘」’, ‘を’, ‘開始’, ‘NTTドコモ’, ‘は’, ’17日’, ‘、’, ‘公式’, ‘オンラインショップ’, ‘「’, ‘ドコモ’, ‘オンラインショップ’, ‘」’, ‘において’, ‘端末’, ‘を’, ‘複数’, ‘台’, ‘同時’, ‘購入’, ‘し’, ‘た’, ‘場合’, ‘に’, ‘1’, ‘台’, ‘当たり’, ‘最大’, ’10’, ‘,’, ‘500円’, ‘を’, ‘割り引く’,…]
C-2 チューニング
B-2と同様に、Doc2Vecのハイパーパラメータのtuningをしました。tuningした結果、B-2で最適化したパラメータと同じ値で、ほぼ最適の結果が得らることがわかりました。(少くとも、このデータセットに関しては、)前処理を変更しても、最適化したパラメータセットはほぼそのまま使える、ことがわかりました。C-3 評価
上記C-2で作成した前処理2の最適化モデルを、A-4の方法で定量的に評価してみた。その結果、正解率による評価では- C(前処理2): 正解率=87%
- B(前処理1): 正解率=91%
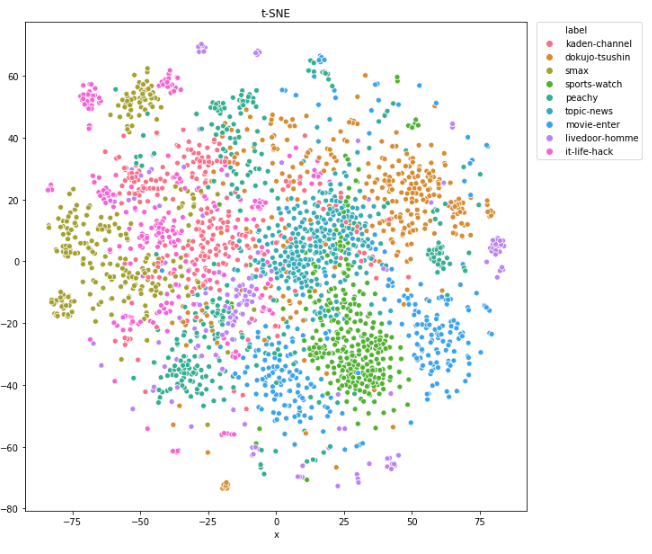
C-4 考察
前処理1はほぼ生データを分かち書きしてるだけなのに対して、前処理2はデータをcleaningする作業などを入れています。そのため、より多くの処理を入れた前処理2の方が良い結果になると期待していましたが、そうではありませんでした。 →定量的に評価することで、前処理2が不適切な処理(情報量を削除しすぎた?)である可能性が高いことが分かりました。 またこのことから、前処理を実装するとき、(闇雲に入れずに)定量的に評価しながら適切な処理を入れていくことが大事であることもわかりました。その際にも、上記の評価方法が役立ちますね。まとめ
Doc2Vecのモデル精度の評価を、教師ありのデータセットを用いることで定性的・定量的に行いました。評価方法の結果を多角的に見ることで、上記評価方法で(ある程度)モデルを適切に定量的評価ができていることを確認しました。この評価方法を用いて、Doc2Vecのトレーニング時のハイパーパラメータや前処理を変更したデータセットなど、異なるセットアップで学習したDoc2Vecを比較しました。その結果、(当たり前ですが)ハイパーパラメータの調整がモデル精度に大きく影響する場合があること、クリーニング処理は闇雲に入れるべきではないこと、などがわかりました。 注意点としては、今回の定量的評価が絶対的に正しいわけではないことを念頭に入れておくことでしょうか。Doc2Vecのfeature化から教師ありモデルの評価までに、不確定な要素はたくさんあるので、「教師あり学習の正解率が高いこと」は「Doc2Vecモデルの精度が良いこと」と高い相関はあるものの、必ずしもイコールではないです。なのでこの評価方法は、parameter tuningするとき正解率を相対的に比較する事で評価に用いる、などが適切な使い方といえるでしょう。前処理によるデータセットの大きな変更の場合、数値だけでなく文章を表示したりベクトルを2次元plotするなど多角的・定性的にも理解した方が安心ですね。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。ご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD