2021.07.07
GNNを使ってビットコインWalletを分類して可視化してみた
目次
こんにちは。次世代システム研究室のC.W.です。
暗号資産って最近流行っていますね。今年の年始からビットコイン(BTC)の価格がジェットコースターの様に動いているのは皆さんご存知かと思います。その後ろにインフルエンサー達がSNSで暗号資産の良し悪しについて発信して価格を動かしたり、BTCの資産家が膨大なBTCを買い売りしていることが存在しています。
BTCの一つの特性は全ての取引(Transactions)が公開資料です。ですけど、前記のインフルエンサーや資産家の様なことが存在しているのは分かっていますが、そうの様は容易に捉えることができません。その根本的な原因は複雑なTransactionsのネットワークと個人が複数のWalletを所有しているのだと思います。その謎を少しでもときたいため、今回は機械学習のGraph Neural Network(GNN)を使ってTransaction Networkを取り組み複数のWalletを一つのクラスタリングをして捕らえることを試してみました。
TL;DR
- BTC balance Top 10,000 walletsのTransaction Networkを無向グラフとして扱う
- AttentionWalkでNode Embeddingを行う
- K-meansでEmbeddingの特徴量をクラスタリングすると有意義のクラスタリングが得られる
1. ビットコインのおさらい
まずは軽くビットコインのWallet (以下Walletと略す) の特徴について紹介させていただきます。
- Walletは資産を保管するものの総称。文字列(Address)でWalletの特定ができて、入金を受け取ることや他のWalletへ出金することができる。番号で銀行の口座を特定できて入出金できると似た様な概念です。
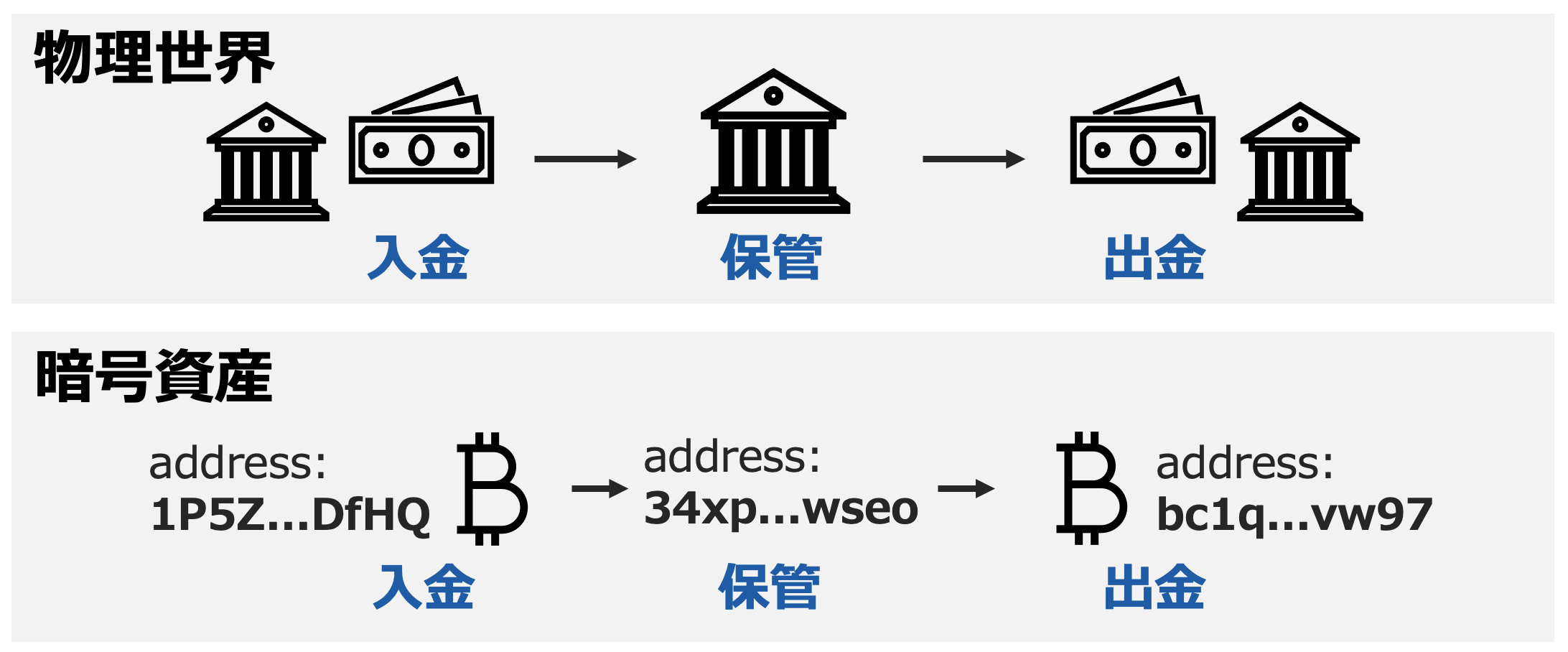
- Walletはワンクリックで生成できるもの。個人資料の登録や審査など一切必要ないので、複数Walletを作ることが極めて容易になっている。一般の銀行ではそういうことができません。
- Wallet Addressさえ分かれば該当Walletの全ての取引記録(Transaction)を見ることができる。銀行口座などとは異なり、資産のプライバシーは高くないです。

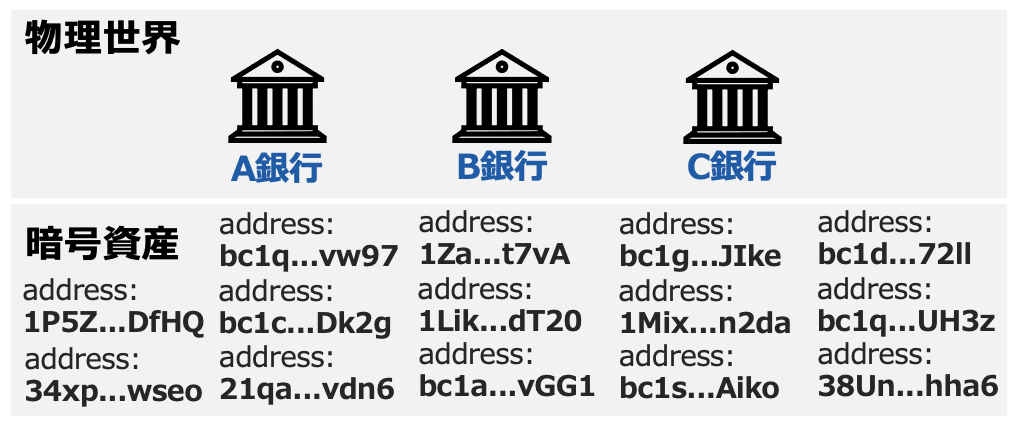
単一walletだと何処かにwallet addressがリークしたら資産のプライバシーは台無しになるので、目的別に複数walletを作って運用するのが一般的になっています。ですけど、複数walletを使ったマネーロンダリングなどの不正行為も続出しているのも現実です。
問題点
一般的にマネーロンダリングは不正の資金源を追跡できなくさせるため違う取引でお金を綺麗にしているので、その取引を遡れば不正の資金源にたどり着くことができます。しかし、BTCのtransactionでは普通の1出金先と1入金先の1対1の関係ではなくN出金先対N入金先の複数対複数の関係が存在しています。さらにCoinJoinの様なサービスがあって意図的にtransactionを複雑にしています。

さらに、個人で複数のwalletを所有しているtransaction networkを考えると、単純に遡りを通じて資金源を追跡することはほぼ不可能になってきます。
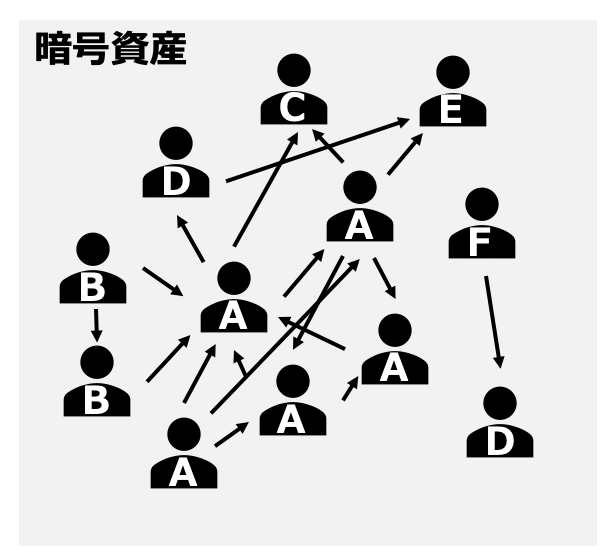
仮にその中で前記の様な不正が発生しても、transaction networkと複数walletの複雑な構造を解いて不正を摘発するには難度が高いです。
なので、問題を2ステップに分けて、
- 匿名の複数Walletを個人個人のグループとして集める
- 不正があるかないかの判断
が必要になってきます。そこで1のタスクで匿名walletを集める課題の解決を試してみました。
2. Graph Neural Network
2-1. Graph構造
Graph構造はNode(節点・頂点)の集合とEdge(枝・辺)の集合で構成される数学的構造。対象される点の一部が相互に何らかの脈絡で「関係している」ようなものをいう。
Transaction networkも似た様な構造で、Node (wallet)とEdge (transaction)が絡み合っている構造で、今回はGraph構造を使ってtransaction networkをを叙述した。
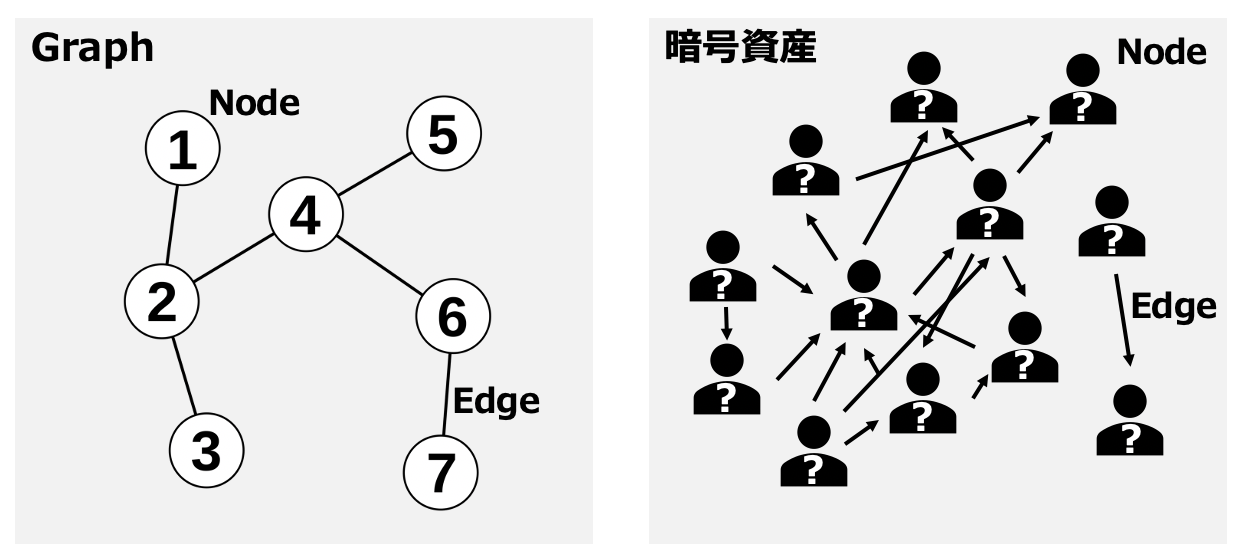
2-2. Graph Neural Network
機械学習の1分野で、Graph Neural Network(以下GNNで略す)はGraph構造を持っているデータをNeural Networkで解決する様なことを指しています。Graph構造のNode, Edge, Graph(大Graph内のSubgraphも含む)などを対象に、以下の様なGNNのタスクが挙げられます。
- Link Prediction:NodeとNodeの間にEdgeが存在している確率を予測
- Node Embedding:Graphの中のNodeごとをN次元の特徴量で叙述する
- Graph Embedding:Graph自体をN次元の特徴量で叙述する
- Node Classification:Nodeを隣接の情報(Edge, 他のNode等)によって分類する
- Graph Classification:Graph自体を分類する
2-3. AttentionWalk
今回使うのはNode EmbeddingタスクのAttentionWalkモデルです。自然言語処理分野のSelf-attention layerと同じ年で同じくGoogle AIから発表されたモデルで、NodeとNodeの間の関係性をAttentionの仕組みで捉える様なことをしています。さらにグラフ構造の全体感を出すためにはRandomWalkを使っています。
RandomWalk
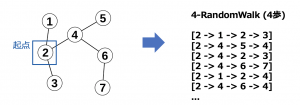
RandomWalkはGNNでトップレベルで大事な手法DeepWalkの定石です。ざっくりいうとGraph構造の様な非構造化データを構造化データで叙述する方法です。
概念としては、あるNodeからRandomでN歩移動すると、そのN歩のうち経由したN個のNodeの系列データをRandomWalkのデータとして扱います。NodeからNodeに移動するときはEdgeを経由するので、各NodeからランダムでN歩移動する系列データは数が多ければ全体のGraphを叙述することができます。
Attention
Attentionは学習する重みそのもので、各NodeごとにN個の数値で表示されます。このN個の数字が学習が終えた時に各NodeごとのN次元の特徴量となります。
AttentionWalkではN個のAttention weightをさらにN/2個のLeftとN/2個のRightと設定し、LeftとRightの積でスコアの計算をしています。(Self-Attention Layerに馴染みのある方にとって、つまりLeftはKeyでRightはQueryの様な状況です)
AttentionWalkの流れ
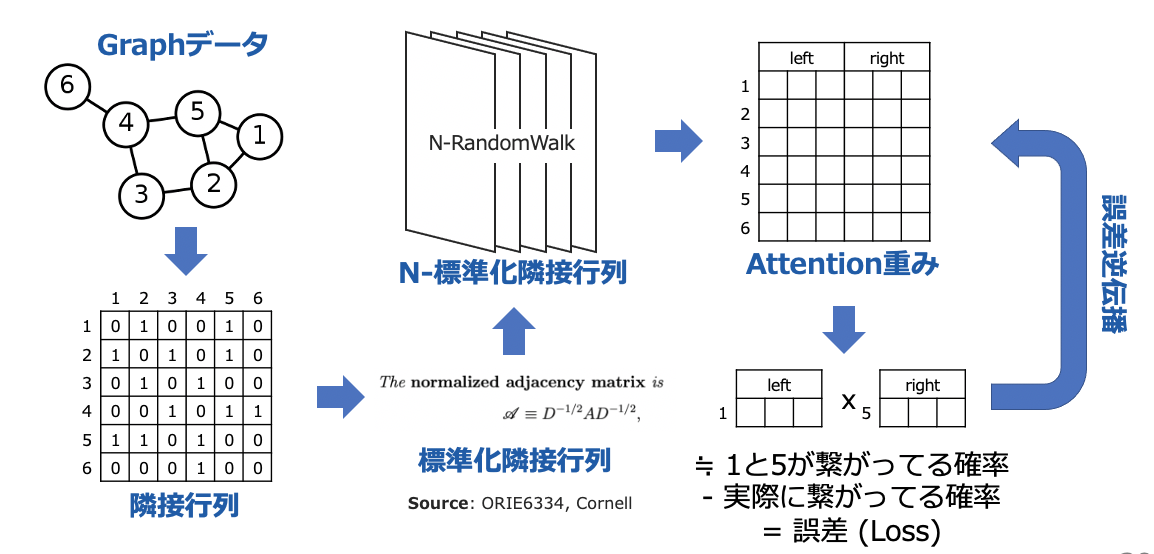
- Graph構造をAdjacent Matrixに行列化する
- Adjacent Matrixを標準化する
- 標準化Adjacent MatrixをRandomWalkで各歩にたどり着くNodeの確率分布を計算する
- Attention weightをLeftとRightに分けて、Node AのLeftとNode BのRightをMatmulで出力値を計算する
- 上記4の出力をNode AからNode Bに移動する確率と見なし、RandomWalkの実確率との誤差を逆伝播する
詳細はこちらの論文と実装Githubを参照してください。
3. 実装
3-1. データソース
今回使うデータwalletデータとwalletに関与するtransactionデータです。
Walletデータは収集に少しハードルがあって、片っ端からblock内のものを収集すると意味のない使われていないwalletが大量に入ってきて結果的に意味のない出力にMisleadされるので、今回はbitinfocharts.comからBTC balanceのTop 10,000 walletを持ってきました。
TransactionデータはBTC.COMのAPIを使って集計しています。期間としては2020/01/01から2021/06/01の17カ月間の中のTop 10,000 walletsが関与したtransactionを全て持ってきています。
3-2. 学習パラメータ
- Epoch: 20,000
- RandomWalk: 5 steps
- Dimension: 8 dimensions
4. 結果
4-1. GNN結果
上記のデータをAttentionWalkで学習した結果(8次元)をtSNEで2次元に落とした結果はこうなります。
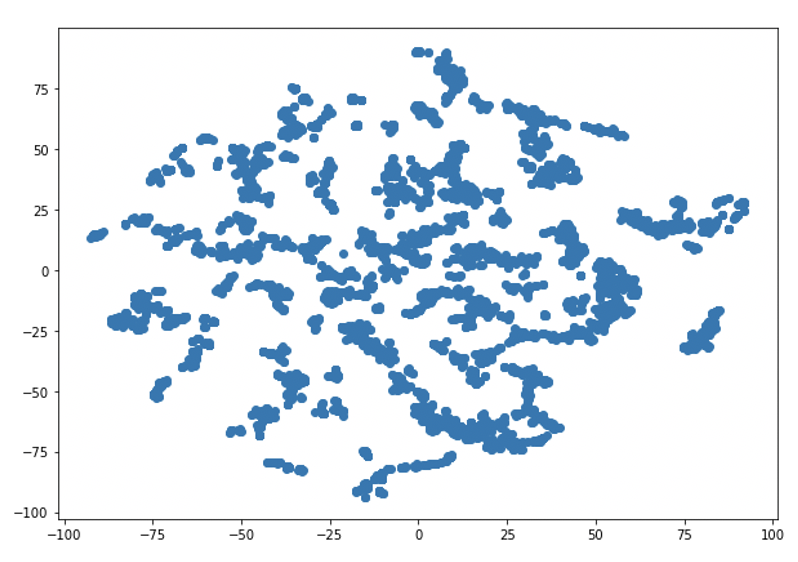
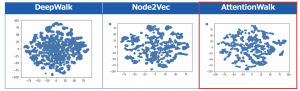
特徴点の群れの間には距離がおいてあり、特徴が分かれていることが画像から見とることができる。他にもDeepWalkとNode2Vecを同じデータとパラメータで学習しましたが、結果は下記の様になって全体的にAttentionWalkの特徴量が一番分かれていることがわかります。
4-2. クラスタリング
K-meansを使ってk=13にするとこの様にクラスタリングすることができます。
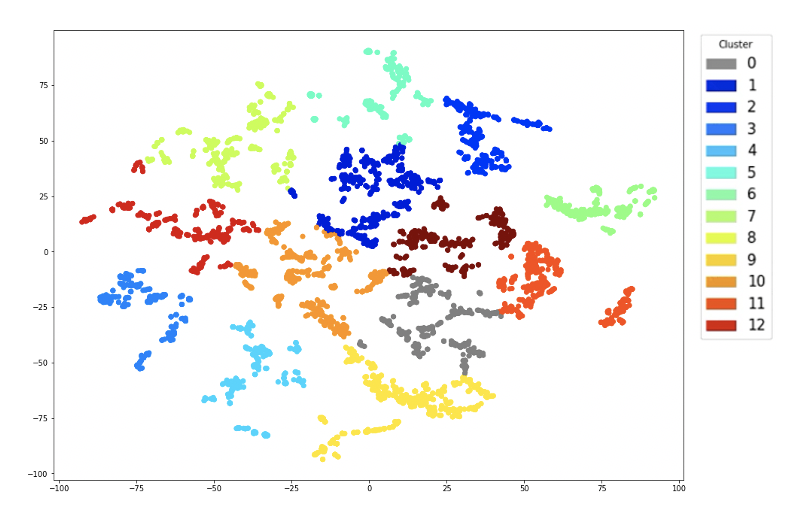
微妙に距離ある群れを一つのクラスターにしているところがわかりますよね。それはK-meansのアルゴリズム問題で、球状クラスタリングしていてそもそも距離からクラスタリングしているのではないところで、結果的には懸念はあると思います。ですけど今回は如何にうまくクラスタリングするのが目的ではないので、とりあえずKーmeansでざっくりいきます。
4-3. 意義性の検証
Walletラベルの地域性
Bitinfocharts.comではwallet address以外にも、一部のwalletに取引所のラベルなどが付いていたので、まずはクラスタリングする前の2次元特徴量画像から異なる取引所はどう分布しているのかを見てみましょう。
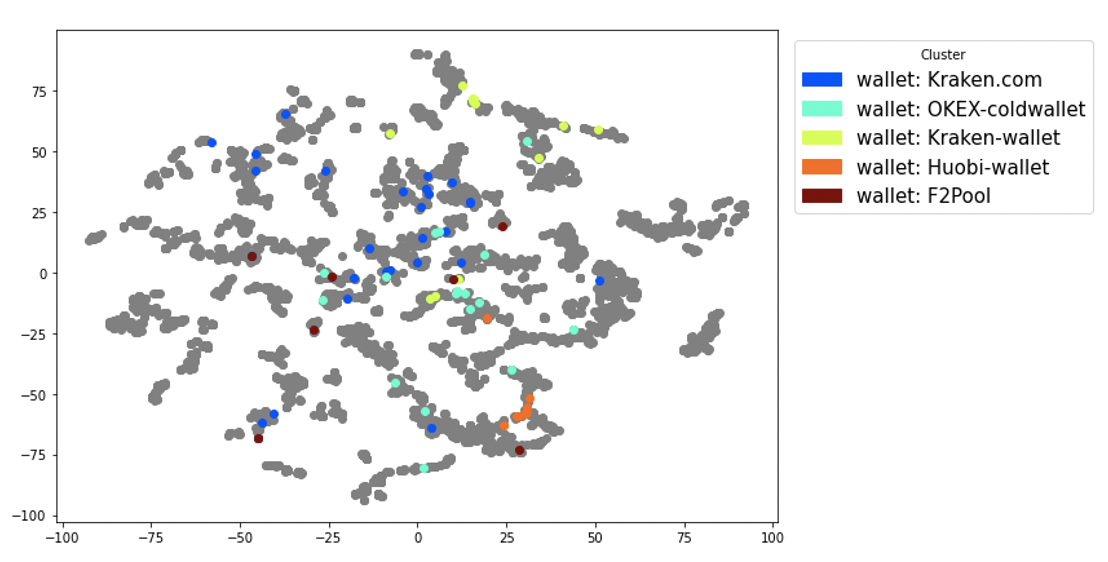
全体的に言うと、Kraken(欧米系)は左上に偏る傾向が見えてOKEx, Huobi(中国系)は右下に偏る傾向が見えますよね。この地域性は事前に入力した情報からは全く見えなく、AttentionWalkがtransaction netoworkを解読している時に自然にたどり着いた結論です。個人的にはすごい思いますが、まだざっくりなので意義があるとは断言はできません。
Walletラベルのクラスター分布
次に見たのが同じラベルの複数walletがどうクラスタリングされているか、ランダムでクラスタリングされているのかを見てみました。
5個以上walletが存在しているラベルを使ってクラスターの分布を見てみました。こちらのheatmapが該当ラベルの付いているwalletの内、何割のwalletがどのクラスターに分布されているかを示したheatmapです。
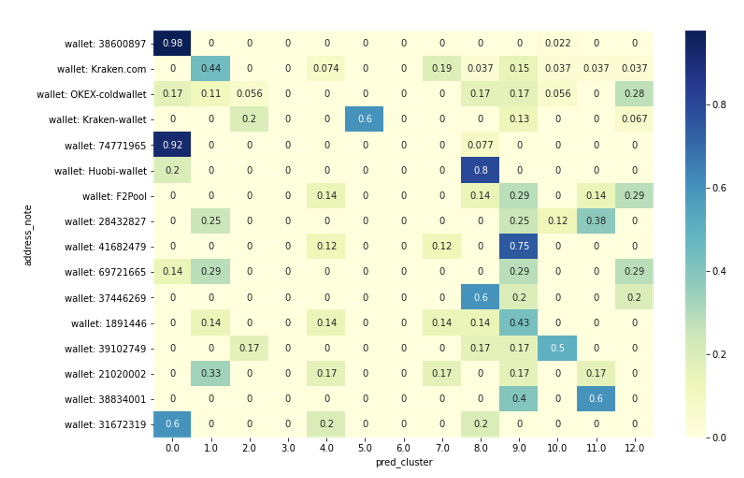
結論から言うとこの特徴量とクラスタリングはランダムではありません。パッと見れば同じラベルのWalletは同じクラスターにクラスタリングされることが多いのがわかり、統計視点から見てもMultinominal分布のPDFから見てもこの様になる確率はほぼゼロに近い状況です。
5.インタラクティブ可視化
クラスタリングはできたが、ここで解釈性がないと言う高い壁に遭遇しました。その理由は主に二つあります。
- Neural Network(NN)
NNの解釈性が低いのは皆さんご存知だと思います。それを解決するためにExplainable AIという専門分野もあります。ですが、NNの強みは複雑なロジックで問題を解決することであり、その複雑なロジックが人間が解釈できないのが解釈性が低い原因の一つなので、これはいつになっても正解のない問題です。
さらに、今回は無教師学習のNode Embeddingを使ってただ特徴量の抽出しかしていないので、この段階で出た特徴量が既に解釈性を失っています。 - クラスタリング
クラスタリングはまた一つ有名な無教師学習の方法です。クラスタリングでは数値が近いものや関係性のあるものを一つのクラスターに集めていて、実際に何かを基づいてクラスターにしているのではありません。
AttentionWalk(無教師学習)で出した解釈性の低い特徴量をK-means(無教師学習)でクラスターにすると、もう何がなんだかわからない状態になってきます。
なので結果がランダムではないことは確信した上でどの様に解釈するかは個々のケーススタディで意味を出す必要があります。そこで、このtransaction networkのブラックボックスを開けるためにリアルタイムで知りたい情報が見れるインタラクティブのアプリが必要だと思って、以下の様なものを作りました。

5-1. 可視化ツール
PythonでNetworkx, PlotlyとDashを使って作成しました。
- Networkx
Graph構造を扱う方便なライブラリで、そのdraw関数(circular_layout, spring_layout等)を使いました。 - Plotly
インタラクティブな画像を作れるライブラリで、色んなインタラクティブなところが設定できてそこの応用しています - Dash
Plotlyのモジュールで、flaskを使ってPlotlyをApplication化することができます。
5-2.画像出力コード
ざっくりこの様な感じで画像を出力しています。
import networkx as nx
import plotly.graph_objs as go
def networker(sample_size, selected_clusters, minimum_btc_balance, layout_type, ego_node):
random.seed(1)
selected_clusters = sorted(selected_clusters)
if sample_size<10000:
cluster_sample = df_address_meta.groupby('pred_cluster').apply(lambda x: sample(x['id'].astype(int).tolist(), sample_size)).to_dict()
else:
cluster_sample = df_address_meta.groupby('pred_cluster').apply(lambda x: x['id'].astype(int).tolist()).to_dict()
[cluster_sample.pop(key) for key in range(13) if key not in selected_clusters]
sampled_nodes = [x for y in list(cluster_sample.values()) for x in y]
cluster_mapping = {cluster: i for i, cluster in enumerate(selected_clusters)}
G = graph.subgraph(sampled_nodes)
G = nx.Graph(G)
too_low_list = df_address_meta.loc[df_address_meta['balance_btc'] < minimum_btc_balance*1000, 'id'].astype(int).tolist() G.remove_nodes_from(too_low_list) ### Layout Style if layout_type=='Circular': pos = nx.circular_layout(G) angs = np.linspace(0, 2*np.pi, len(selected_clusters)+1) repos = [] rad = 7.5 # radius of circle for ea in angs: if ea > 0:
repos.append(np.array([rad*np.cos(ea), rad*np.sin(ea)]))
for node in pos.keys():
cluster = sample_mapping[node]
cluster_index = cluster_mapping[cluster]
pos[node] += repos[cluster_index]
elif layout_type=='Spring':
pos = nx.spring_layout(G, k=2, seed=1)
elif layout_type=='Ego':
try:
ego_id = int(df_address_meta.loc[df_address_meta['address']==ego_node, 'id'].values[0])
print(f"""
Egomode:
wallet:{ego_node}
id:{ego_id}
""")
G = nx.generators.ego.ego_graph(graph, ego_id, radius=1, center=True, undirected=True, distance=None)
pos = nx.spring_layout(G, k=1, seed=1)
except IndexError:
print('wallet address wrong')
pos = nx.spring_layout(G, k=2, seed=1)
for n, p in pos.items():
G.nodes[n]['pos'] = p
edge_x = []
edge_y = []
for edge in G.edges():
x0, y0 = G.nodes[edge[0]]['pos']
x1, y1 = G.nodes[edge[1]]['pos']
edge_x.append(x0)
edge_x.append(x1)
edge_x.append(None)
edge_y.append(y0)
edge_y.append(y1)
edge_y.append(None)
import plotly.graph_objs as go
edge_trace = go.Scatter(
x=edge_x, y=edge_y,
line=dict(width=0.5, color='#888'),
hoverinfo='none',
mode='lines')
node_x = []
node_y = []
for node in G.nodes():
x, y = G.nodes[node]['pos']
node_x.append(x)
node_y.append(y)
import plotly.graph_objs as go
node_trace = go.Scatter(
x=node_x, y=node_y,
mode='markers',
hoverinfo='text',
marker=dict(
showscale=True,
colorscale='bluyl',
reversescale=True,
color=[],
colorbar=dict(
thickness=15,
title='Transaction count',
xanchor='center',
titleside='right'
),
line=dict(
width=1.5,
color='black'
)
)
)
node_degree = []
node_text = []
node_symbol = []
node_size = []
for node, degree in G.degree():
cluster_num = sample_mapping[node]
address = df_address_meta.loc[df_address_meta['id']==node, 'address'].values[0]
balance = df_address_meta.loc[df_address_meta['id']==node, 'balance_btc'].values[0]
address_note = str(df_address_meta.loc[df_address_meta['id']==node, 'address_note'].values[0])
node_degree.append(degree)
node_symbol.append(0 if address_note=='nan' else 17)
node_size.append(30 if ((layout_type=='Ego')&(address==ego_node)) else 10)
node_text.append(
f'{address}'+
'
Cluster: {}'.format(str(int(cluster_num)))+
'
# of transactions: {}'.format(str(degree))+
f'
BTC balance: {balance}'+
f'
Note: "{address_note}"'
)
node_trace.marker.color = node_degree
node_trace.marker.symbol = node_symbol
node_trace.marker.size = node_size
node_trace.text = node_text
fig = {
'data':[edge_trace, node_trace],
'layout':go.Layout(
titlefont_size=16,
showlegend=False,
hovermode='closest',
margin=dict(b=20,l=5,r=5,t=40),
annotations=[ dict(
text=f"(sampled {sample_size} wallets per cluster)",
showarrow=False,
xref="paper", yref="paper",
x=0.005, y=-0.002 ) ],
hoverlabel=dict(
font_size=16
),
xaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
yaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
height= 800
)
}
return fig
5-3. インタラクティブ
この様なFlaskの書き方で各パートから引数を持ってきて、画像生成の関数に入力しています。
@app.callback(
dash.dependencies.Output('my-graph', 'figure'),
[dash.dependencies.Input('samplesize-slider', 'value'),
dash.dependencies.Input('full-samplesize-check', 'value'),
dash.dependencies.Input('btcbalance-slider', 'value'),
dash.dependencies.Input('my-multi-dynamic-dropdown', 'value'),
dash.dependencies.Input('layout_style_radioitem', 'value'),
dash.dependencies.Input('input_egowallet', 'value')])
def update_output(samplesize_value, full_sample, btcbalance_value, clusters, layout_style, egowallet):
SAMPLE_SIZE = samplesize_value if not full_sample else 99999
MIN_BTC_BALANCE = btcbalance_value
SELECTED_CLUSTERS = clusters
LAYOUT = layout_style
return networker(SAMPLE_SIZE, SELECTED_CLUSTERS, MIN_BTC_BALANCE, LAYOUT, egowallet)
Webフロントの部分はdashのcore componentとhtml componentで簡単に作ることができます。ここでcomponentを制作する時にidとかを設定すれば、上記のflaskに引数を持っていくことができます。
import dash
import dash_core_components as dcc
import dash_html_components as html
app.layout = html.Div([dcc.xxx,
html.Div(dcc.xxx, html.Div(dcc.xxx, ...))
])
正直Webフロントは基礎知識しかわからなかったが、このツールは使い勝手がよく簡単に作ることができますので、お勧めします。
6.最後に
今回はGNNを使ってBTC walletのクラスタリングを試してみました。ランダムでクラスタリングしていない検証もできましたが、意味の解釈がきつかったです。そこでPlotlyとDashを使ってインタラクティブのアプリを作ってここのケーススタディをよりスムーズに行うことができて、コツコツクラスターごとの意味を発掘していきたいです!
面白いものが見つかったら今度共有します。では、また来期!
次世システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。 一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD




