2019.04.04
InstaGANでポケモンを移動してみました
こんにちは。次世代システム研究室のK.S.(女性、外国人)です。
最近、駅の周りや有名なスポットなどに行くと、沢山の人たちが集まり、指でスマホをスライドしている姿を見かけたりしていませんか? 街がすごいことになり、なにが起こっているのだろうと思ったりしませんでしょうか? 私は「なに?なに?なに?」と思いました。こっそり見てみたら、間違いなく、みんながポケモンGOでポケモンを捕まえていました。日本だけではなく世界中でポケモンを知らない人はほぼいないと思います。ポケモンGOというスマホゲームも聞いたことがあるかと思いますが、そもそも具体的に大ブームになったポケモンGOとはどんなゲームでしょうか。ポケモンGOはポケモンが現実の世界を舞台にしたスマホゲームです。アプリを立ち上げるとマップが開き、GPSによって自分の居場所が表示されます。自分がゲームのキャラになり、プレイヤーとして自分が歩けば、キャラも歩きます。自分の足で現実の世界を歩き回り、ポケモンを捕獲します。場所の特徴によってポケモンの種類も変わっていきます。例えば、川に行くと、魚ポケモンが多く見られ、山に行くと、キノコポケモンが沢山出てきます。散歩やコレクションアプリとして、子供からお年寄りまでが一緒に楽しめるアプリです。私も最近ポケモンGOにはまっています(笑)。そこで、牛ポケモンが欲しくて、2月の寒い中仲間と頑張って東京から千葉のマザー牧場まで牛ポケモンを捕まえに行きました。しかし、牧場に着いても、牛ポケモンはあまりいませんでした。たくさん撮りたかったけど、少ししかいなかったのが残念でした。たまらなく、悔しくて、悲しくて、色々なところからたくさん牛ポケモンを牧場に連れて帰りたい!!と思いました。
そこで、ポケモンちゃんを移動するため、技術論文を調査しました。結果、InstaGANという最近のGAN(Generative Adversarial Networks)論文を発見しました。InstaGANの技術だったら、牛ポケモンを牧場に連れて帰られるだろうと期待しています。ということで、今回のブログでは、InstaGANを使って、ポケモンを移動させてみたいと思います。
せっかくですので、まず、簡単にGANをおさらいし、InstaGAN論文を紹介します。それから、技術面を理解した上で、一緒にポケモンの居場所を移動することを遊んでみたいと思います。このブログの構成は、以下のとおりです。
① GANと関連技術のおさらい
GANs (Generative Adversarial Networks; 敵対的生成ネットワーク) は2014年に、Deep Learning(深層学習)の世界では有名なIan Goodfellowが考案された画像を生成するためのモデリング手法です。GANという技術はかなり有名ですので、日本語でも英語でも検索したら、たくさんわかりやすくGANを紹介する記事が出てきますので、ここでは簡単なおさらいと今回紹介するInstaGANに関係があるポイントだけを紹介させて頂きます。
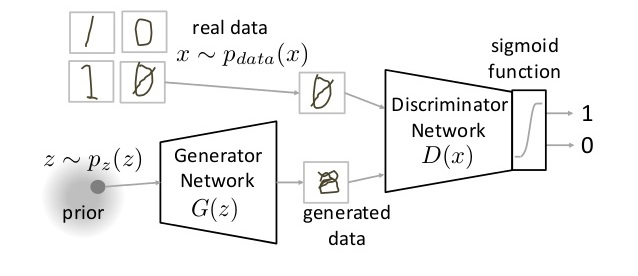
さて、GANは人間の創造性に挑戦するための機械学習技術の一つです。人間は創造力を持ち、ポケモンの絵を描いたり、ポケモン漫画を書いたりすることができます。しかし、機械は自分で考えて作ることはまだ難しいです。そこで、GANが生まれました。もう少し簡単に技術的な説明をすると、GANはneural network(ニューラルネットワーク)の生成モデルの一つの種類です。訓練データを学習し、それらのデータと似たような新しいデータを生成するモデルです。データを生成するため、GANではgeneratorとdiscriminatorという二つのネットワークを利用します。Generatorは本当のデータと同じような偽データを生成するものです。Discriminatorは本当のデータとgeneratorからの偽データを識別するものです(図1)。最初generatorが適当な偽データを作成しますが、学習による、discriminatorの識別で偽データがどんどん本当のデータに似ているようになっていきます。最後に、generatorが本物と似ているような絵や漫画を作成することができるようになることが期待できます。
ただし、実はGANが生成した結果(画像クオリティなど)はまだ不十分であり、特定の領域の変換をすることが出来ませんでした。例えば、ファッションアプリで、服を変えてみたいときに、GANで自然にズボンをスカートに変換することは難しいです。そこで、画像内の形状を変更するために、2017年に機械学習アルゴリズムとして CycleGAN という技術が提案されました。CycleGANを使うことで、2つのデータソース間を1対1で変換(スタイル変換)することが可能になりました。ただ、CycleGANのアルゴリズムはまだ不十分なところがあり、たまに画像をまるごと変化させて、画像内で特定したい部分が多ければ、ある部分が変換されない場合もありました(図2)。これらの問題を解決するため、2018年12月にCycleGANの改良版InstaGANが考案されました。それでは、InstaGANはなにができるのか、どうやってポケモンの居場所移動につなげられるのか、次のセクションになります。

② InstaGAN論文の紹介
InstaGAN (Instance-aware GAN)はGANを基にし、画像内の特定領域の形状を自然に変換させるものです。ここでは簡単に主なポイントだけを説明し、詳細はInstaGAN論文を参考にして頂ければと思います。
説明前に、少しこの論文の用語をおさらいさせて頂きます。画像内の特定領域はinstance、その領域の形状はsegmentation mark、像領域(画像ドメイン)はimage domainと使われています。また、mapping(マッピング)はある情報を一対一の別の情報に対応させることです。
さて、二つの画像ドメイン(image domain X, Y)を考えると、画像間変換の問題は元のコンテクスト(文脈)を維持しながら、異なる画像ドメイン(GXY:X→Y or/and GYX:Y→X)、すなわち変換ターゲットにわたるマッピングを学習することです(図3a)。ここはもし、二つの画像である部分が同じであれば、条件付け「p(y|x) or/and p(x|y)」での生成的モデリングタスクで解決できます。しかし、対になっていない二つの画像ドメインをマッピングするのは難しいです。この困難に対応できるようにするためのアルゴリズム提案はInstaGAN論文の強い独創性だと思います。
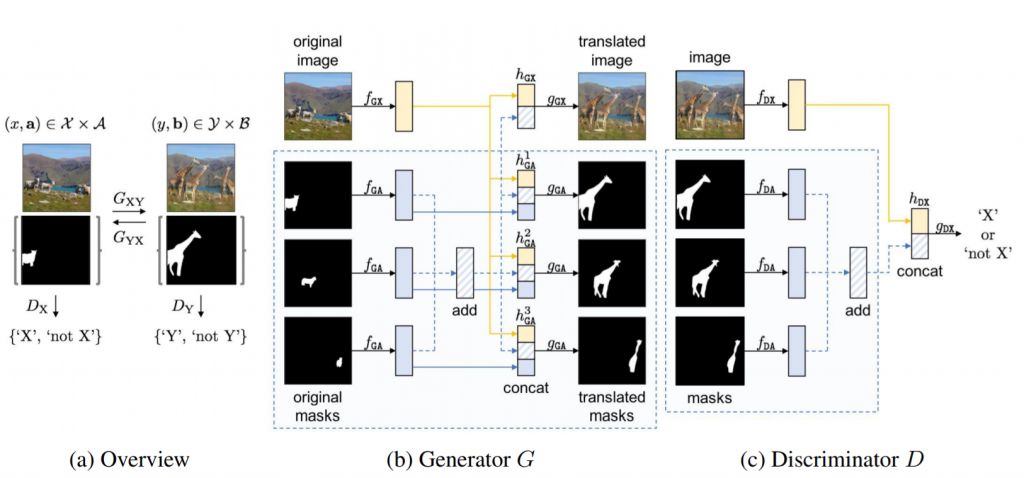
InstaGAN論文の主なユニークアイデアは追加のインスタンス情報を組み込むことです。すなわち、画像から画像への変換効率を高めるため、一組のインスタンス属性Aの空間を元の画像空間Xに拡大します。そして、この論文のアプローチは属性増大空間間のジョイントマッピング(X×AとX×B)の学習として説明することができます。これにより、画像内の様々なインスタンスが解きほぐされ、GANのgeneratorが正確で詳細な変換を作成することができるようになります。
また、独創性の詳細は3つあります。
- An instance-augmented neural architecture
- A context preserving loss
- A sequential mini-batch inference/training technique
この三つの日本語での数式的な説明はすでに他のブログで書かれていますので、追加の参考情報としてこれらを参考にして頂ければと思います。
③ ポケモンの居場所の移動
InstaGANなどの説明が長くなりました。それでは、いよいよ、ポケモンの居場所の移動を実装してみたいと思います。
やりたいこと
前述しましたが、今回やりたいことはポケモンを牧場に戻すことです。やり方としては、マザー牧場で取ったメリープ(羊ポケモン)写真を使って、メリープの代わりに、都会にいるミルタンク(牛ポケモン)を牧場に移動します。このため、二種類のポケモン(メリープとミルタンク)が写った写真を使って、ポケモンの形(segmentation)を学習します(train)。それから、ミルタンクがメリープに入れ替われるか試します(test)。
実装環境
マシンスペックはGPU : NVIDIA GeForce GTX 1070を使いました。言語環境はPython 3.5です。また、主なプログラムはInstaGANパッケージをgithubからダウンロードをしました。InstaGANに必要なパッケージもダウンロードすることが必要です。インストール方法はInstaGANのREADME.mdを参考にして頂ければと思います。
ポケモン画像データ準備
まず、当たり前ですが、メリープとミルタンクの写真が必要です。スマホ携帯でポケモンGOのアプリから、色々な場所でどきどきしながら楽しくメリープちゃんとミルタンクちゃんの写真を5枚ずつ撮影しました。取って来た写真はそのまま使えないため、少し処理しました。まず、学習やテストするため、写真からミルタンクとメリープのsegmentationを作成する必要があります。今回は画像枚数が少ないし、簡単に処理したいので、GIMPを利用しました。基本的にはbackgroundを黒にし、メリープとミルタンクのsegmentationを白にしました(図4)。そして、学習とテストデータを準備しました。InstaGAN論文で使われたズボンとスカートの変換のデータセット作成ファイルを少し修正し、ポケモンデータセット作成ファイルを作りました。興味がある方は下記のコードを参考にして下さい。

データ処理のコード
import argparse
import cv2
import math
import numpy as np
import scipy.io as sio
from pathlib import Path
from tqdm import tqdm
from PIL import Image
import torch
import torchvision.transforms as T
def main():
parser = create_argument_parser()
args = parser.parse_args()
generate_pokenmon_dataset(args)
def create_argument_parser():
parser = argparse.ArgumentParser()
parser.add_argument('--data_root', type=str, default='datasets/pokemon')
parser.add_argument('--save_root', type=str, default='datasets/pokemon_save')
parser.add_argument('--cat1', type=str, default='sheep', help='category 1')
parser.add_argument('--cat2', type=str, default='cow', help='category 2')
parser.add_argument('--size_h', type=float, default=450, help='height')
parser.add_argument('--size_w', type=float, default=300, help='width')
parser.add_argument('--no_skip_horizontal', action='store_true', help='do *not* skip horizontal images')
return parser
def generate_pokenmon_dataset(args):
"""Generate POKEMON dataset (train/val, A/B)"""
args.data_root = Path(args.data_root)
args.img_root = args.data_root / 'images'
args.ann_root = args.data_root / 'annotations'
args.save_root = Path(args.save_root)
args.save_root.mkdir()
generate_pokemon_dataset_sub(args, 'train', 'A', get_cat_id(args.cat1))
generate_pokemon_dataset_sub(args, 'train', 'B', get_cat_id(args.cat2))
generate_pokemon_dataset_sub(args, 'test', 'A', get_cat_id(args.cat1))
generate_pokemon_dataset_sub(args, 'test', 'B', get_cat_id(args.cat2))
def generate_pokemon_dataset_sub(args, phase, domain, cat):
img_path = args.save_root / '{}{}'.format(phase, domain)
seg_path = args.save_root / '{}{}_seg'.format(phase, domain)
img_path.mkdir()
seg_path.mkdir()
idx_path = args.data_root / '{}_list.txt'.format(phase)
f = idx_path.open()
idxs = f.readlines()
print ("idxs",idxs)
pb = tqdm(total=len(idxs))
pb.set_description('{}{}'.format(phase, domain))
if domain == 'A':
select_cat = args.cat1
elif domain == 'B':
select_cat = args.cat2
for idx in idxs:
count = 0 # number of instances
id = idx.split('.')[0] # before extension
for ann_path in args.ann_root.iterdir():
if ann_path.name.split('_')[0] == id:
ann = cv2.imread(str(ann_path))
if not args.no_skip_horizontal:
if ann.shape[1] > ann.shape[0]:
continue # skip horizontal image
if (np.isin(ann, cat).sum() > 0) and (select_cat in str(ann_path.name.split('_')[0])):
print (select_cat, "np",np.isin(ann, cat).sum())
seg = Image.fromarray(ann)
seg = resize_and_crop(seg, [args.size_w, args.size_h]) # resize and
if np.sum(np.asarray(seg)) > 0:
seg.save(seg_path / '{}_{}.png'.format(id, count))
count += 1
print ("count",count)
if count > 0:
img = cv2.imread(str(args.img_root / '{}.jpg'.format(id)))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = Image.fromarray(img)
img = resize_and_crop(img, [args.size_w, args.size_h])
img.save(img_path / '{}.png'.format(id))
pb.update(1)
pb.close()
def get_cat_id(cat):
return {
'penguin': 0,
'sheep': 1,
'cow': 2,
'honey': 3,
'pikachu': 4,
}[cat]
def resize_and_crop(img, size):
src_w, src_h = img.size
tgt_w, tgt_h = size
ceil_w = math.ceil((src_w / src_h) * tgt_h)
return T.Compose([
T.Resize([tgt_h, ceil_w]),
T.CenterCrop([tgt_h, tgt_w]),
])(img)
if __name__ == '__main__':
main()
データ処理の実行コマンド
python ./datasets/generate_pokemon_dataset.py --save_root ./datasets/pokemon_save --cat1 sheep --cat2 cow
実装
今回の実装はInstaGANのお試しつもりですので、学習パラメータはほぼdefaultの設定を適用しました。また、今回利用したGPUメモリが少なかったため、少し画像サイズを減らしました。
学習
nohup python train.py --dataroot ./datasets/pokemon_save --model insta_gan --name pokemon_instagan --loadSizeH 300 --loadSizeW 200 --fineSizeH 200 --fineSizeW 200 --niter 2000 --save_epoch_freq 1000 > log.out 2>&1 &
テスト
# 1000 epochs テスト python test.py --dataroot ./datasets/pokemon_save --model insta_gan --name pokemon_instagan --loadSizeH 300 --loadSizeW 200 --fineSizeH 200 --fineSizeW 200 --ins_per 2 --ins_max 20 --epoch 1000 # 2000 epochs テスト python test.py --dataroot ./datasets/pokemon_save --model insta_gan --name pokemon_instagan --loadSizeH 300 --loadSizeW 200 --fineSizeH 200 --fineSizeW 200 --ins_per 2 --ins_max 20 --epoch 1000
結果
学習回数は2,000 epochs(学習において訓練データをすべて使い切ったときの回数)でした。学習時間ははっきり測っていませんでしたが、3時間くらいかかりました。学習イメージを捕まえるため、学習のときの画像を載せます(図5)。図5を見ると、学習回数が多くなると、ポケモン移動は少しずつよくなっていくことがわかります。学習400Epochsのとき、InstaGANで生成したミルタンク画像も、メリープ画像も、ミルタンクとメリープの絵が重なっているのが明らかに見えます。学習2000Epochsまで行くと、生成した画像がある程度許容範囲になってきました。

次に、学習が終わると、学習モデルを使って、ポケモンを移動してみました。結果は図6になります。メリープはミルタンクの代わりに都会に遊びに行くことができましたが、残念ながら、ミルタンクは完璧に牧場に戻れませんでした。ミルタンクとメリープが結合してしまいました。今回の学習はまだ不十分でしたが、期待ができるのではないかと思います。

おまけ
だめ元だと思いますが、せっかく、花見の季節ですので、それに合わせて、最後までこのブログを読んで頂いている方におまけとしてポケモンと桜を贈りたいと思います。妄想ストーリーでは、渋谷に遊びに来たミツハニー(蜜蜂)と公園で桜の木と遊んでいるピカチュウを入れ替えてみました。データはメリープとミルタンクと同じように5枚ずつの写真を用意し、1000Epochsでの学習モデルを作りました。そのモデルを使って、別の1枚ずつ写真(図7に載せた写真)をテストしました。結果は図7になります。なんとなくの雰囲気が出せただけですが、InstaGANで生成した桜とミツハニーの写真を楽しんで頂ければ幸いです。いかがでしょうか?

④ まとめと考察
今回はInstaGANを紹介し、InstaGANを使ってポケモンを移動しました。結果はまだ完全に移動できませんでしたが、ある程度移動の可能性が見えてきました。今回は正面からの画像だけを使い、学習のパラメータチューニングなども行いませんでした。次の機会には、画像の枚数を増やしたり、モデルをチューニングしたり、様々な角度からも試してみたいと思います。また、ご参考まで、この画像をいつも絵を描いたり画像を処理したりしているデザイナーさんの友達に見せて、意見を頂きました。答えは「1時間あれば、もっときれいに画像処理ができますよ」と言われました(恥)。それはたしかですが、いつか機械学習の性能が向上し、1時間で何百枚何千枚の画像処理できるようになるのを期待しております。手間がかかる画像処理作業が機械に任せられるようになれば、私たちが牧場や公園に行く時間が増えるだろうと思っています。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD