2024.04.08
Geminiを使ったマルチモーダルRAGのハンズオン
みなさんこんにちは、グループ研究開発本部 AI研究開発室のA.F(海外の出身)です。
LLM(大規模言語モデル)の生成した文章って、たまに事実と全然違う「幻覚」を見せちゃうこと、ありません? Retrieval-augmented generation (RAG)っていう技術は、まさにその対策なんです。RAGは、回答を生成する時にLLMが外部の情報を参照できるようにしてくれる技術で、最近はカスタムLLMモデルを構築する際の有力な手法になっています。
で、通常はテキスト形式の文書を情報源にするんですけど、画像、図表、その他のデータにも重要な情報って含まれているじゃないですか。ありがたいことに、最近はテキストだけでなく画像などの視覚情報も直接モデルに取り込めるようになってきてるんです!その方法の1つが、Gemini APIを使うことなんですよ。
今回のブログでは、マルチモーダルRAGモデルを構築する簡単な実験を通して、Gemini APIの使い勝手を体感してみましょう。テキストモダリティにはGemini 1.0 Pro、画像モダリティにはGemini 1.0 Pro Visionを使用します。
始める前に
- Google Cloudアカウント: 実験ではVertex AIプラットフォームを利用するので、Google Cloudのアカウントが必要です。新規ユーザの方には、お試しで$300分の無料クレジットが貰えますよ!
- Pythonと機械学習の基礎知識: このガイドでは、プログラミングと機械学習の基本的な概念を少し理解していることを前提としています。
Step-by-step ガイド
セットアップ
- Google Colabノートブックの新規作成: Google Colabで新しいノートブックを作ります。
- 必要なライブラリのインストール: 下記のコマンドを実行して、必要なツールを準備します。
!pip3 install --upgrade --user google-cloud-aiplatform pymupdf
- アカウント認証: 以下に表示されたコードを使って、自分のアカウントを認証します。
import sys # Additional authentication is required for Google Colab if "google.colab" in sys.modules: # Authenticate user to Google Cloud from google.colab import auth auth.authenticate_user() - Google Cloud Project IDの準備
- まずは、Google Cloud Projectを作成しておきましょう。こちらのURL: [URL]から作成できます。
- 作成したProject IDを、以下のコードの「YOUR_PROJECT_ID」の部分に貼り付けてください。
# Define project information import sys import vertexai PROJECT_ID = "YOUR_PROJECT_ID" LOCATION = "us-central1" # you can change the location # Initialize Vertex AI vertexai.init(project=PROJECT_ID, location=LOCATION) -
必要なライブラリのインポート
下記のコードで、必要なライブラリをインポートします。from IPython.display import Markdown, display from vertexai.generative_models import ( Content, GenerationConfig, GenerationResponse, GenerativeModel, HarmCategory, HarmBlockThreshold, Image, Part, ) -
Geminiモデルの読み込み
テキスト処理用の「Gemini 1.0 Pro」と、マルチモーダル処理用の「Gemini 1.0 Pro Vision」のモデルを読み込みます。text_model = GenerativeModel("gemini-1.0-pro") multimodal_model = GenerativeModel("gemini-1.0-pro-vision") -
ヘルパー関数のダウンロード
作業を簡単にするために、ここからintro_multimodal_rag_utils.pyというヘルパー関数をダウンロードしておきましょう。このファイルには、入力ドキュメントから情報を抽出するのに役立つ関数が含まれています。import os import urllib.request import sys if not os.path.exists("utils"): os.makedirs("utils") # download the helper scripts from utils folder url_prefix = "https://raw.githubusercontent.com/GoogleCloudPlatform/generative-ai/main/gemini/use-cases/retrieval-augmented-generation/utils/" files = ["intro_multimodal_rag_utils.py"] for fname in files: urllib.request.urlretrieve(f"{url_prefix}/{fname}", filename=f"utils/{fname}")
データ準備
情報ソースとして、テキスト文書と画像のどちらも使えます。ただ今回は、準備してあるヘルパー関数に合わせて、PDF形式のドキュメントを使ってみることにします。手元のPDFファイルをGoogle Colabのノートブックにアップロードしてください。
この実験では、Googleの財務情報や事業内容などが網羅された「Google-10K」データの改訂版を使用します。
- PDFファイルは
data/フォルダにアップロードしました。 - PDFから抽出した画像を保存しておく
images/フォルダも作成済みです。
あとは、以下のコードを実行すれば、PDFドキュメントから画像をimages/フォルダに抽出して、テキストと画像のメタデータをそれぞれ「DataFrame」形式で取得できますよ。
from utils.intro_multimodal_rag_utils import get_document_metadata
# PDFが入っているフォルダを指定
# pdf_folder_path = "/content/data/" # Google Colab環境で使う場合
pdf_folder_path = "data/" # Vertex AI Workbenchで使う場合
# 画像の説明文生成用のプロンプトを指定 (必要に応じて変更)
image_description_prompt = """Explain what is going on in the image.
If it's a table, extract all elements of the table.
If it's a graph, explain the findings in the graph.
Do not include any numbers that are not mentioned in the image.
"""
# PDFからテキストと画像のメタデータを抽出
text_metadata_df, image_metadata_df = get_document_metadata(
multimodal_model, # Gemini 1.0 Pro Visionモデルを使う
pdf_folder_path,
image_save_dir="images",
image_description_prompt=image_description_prompt,
embedding_size=1408,
# add_sleep_after_page = True, # API制限に引っかかる場合はコメント解除
# sleep_time_after_page = 5,
# generation_config = # 次のセル参照
# safety_settings = # 次のセル参照
)
print("\n\n --- 処理完了! ---")
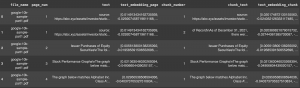
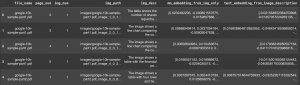
では、メタデータの中身を確認してみましょう。Pandasのデータ操作に慣れている方は、いつもの通りtext_metadata_df.head()やimage_metadata_df.head()コマンドでデータの先頭部分をご覧いただけます。
表示されるデータは以下のような感じになるはずです:
RAGの実装
まずは必要なヘルパー関数をインポートします。これらの関数は、クエリ(検索文)に合致したテキストや画像を見つけたり、Gemini API から応答を得たりするのに使います。
from utils.intro_multimodal_rag_utils import (
get_similar_text_from_query,
print_text_to_text_citation,
get_similar_image_from_query,
print_text_to_image_citation,
get_gemini_response,
display_images,
)
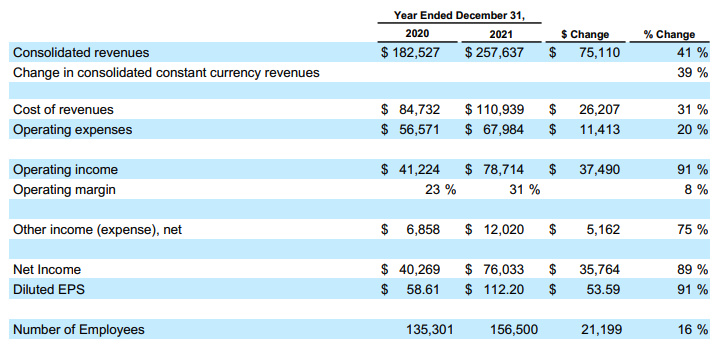
では、早速テキストクエリで検索を試してみましょう!まずはテキスト検索で情報を探してみます。以下はPDFからの1ページです、従業員数に関する質問を聞いてみましょう。
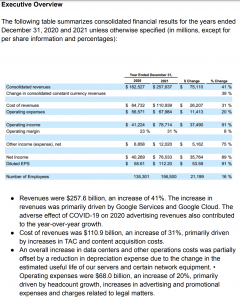
query = "2020と2021の社員数の差とそのパーセンテージを教えてください"
# ユーザーのテキストクエリと「chunk_embedding」をマッチングして、関連するチャンクを見つける
matching_results_text = get_similar_text_from_query(
query,
text_metadata_df,
column_name="text_embedding_chunk",
top_n=3,
chunk_text=True,
)
# マッチしたテキストの引用を表示する
print_text_to_text_citation(matching_results_text, print_top=False, chunk_text=True)
検索結果は以下になります。

複数の関連テキストが見つかって、それらを一つのコンテキストにまとめ、テキストモデル(Gemini 1.0 Pro)に質問を投げかけることで、より詳細な回答を得ることができます。
print("\n **** Result: ***** \n")
# All relevant text chunk found across documents based on user query
context = "\n".join(
[value["chunk_text"] for key, value in matching_results_text.items()]
)
instruction = f"""コンテキストに基づいて質問を回答してください。
質問: {query}
コンテキスト: {context}
回答:
"""
# Prepare the model input
model_input = instruction
# Generate Gemini response with streaming output
get_gemini_response(
text_model, # we are passing Gemini 1.0 Pro
model_input=model_input,
stream=True,
generation_config=GenerationConfig(temperature=0.2, max_output_tokens=2048),
)
**** Result: ***** このコンテキストには、社員数に関する情報が含まれていません。
テキスト検索からの情報だけでは、質問に答えるのに十分な判断ができなかったようですね。そこで、今度は画像を検索してみましょう!
matching_results_image = get_similar_image_from_query(
text_metadata_df,
image_metadata_df,
query=query,
column_name="text_embedding_from_image_description", # Use image description text embedding
image_emb=False, # Use text embedding instead of image embedding
top_n=3,
embedding_size=1408,
)
# Markdown(print_text_to_image_citation(matching_results_image, print_top=True))
print("\n **** Result: ***** \n")
print(len(matching_results_image))
# Display the top matching image
display(matching_results_image[1]["image_object"])
3つの画像を検索してみたところ、2番目の画像が良さそうですね!
では、早速画像を使って、答えを生成してみましょう!
print("\n **** Result: ***** \n")
# All relevant text chunk found across documents based on user query
context = f"""Image: {matching_results_image[1]['image_object']}
Description: {matching_results_image[1]['image_description']}
"""
# instruction = f"""Answer the question in JSON format with the given context of Image and its Description:
# Question: {query}
# Context: {context}
# Answer:
# """
instruction = f"""コンテクストのImageとそのDescriptionに基づいて質問に対してを回答しJSON化した回答を返してください:
質問: {query}
コンテキスト: {context}
回答:
"""
# Prepare the model input
model_input = instruction
# Generate Gemini response with streaming output
Markdown(
get_gemini_response(
multimodal_model, # we are passing Gemini 1.0 Pro Vision
model_input=model_input,
stream=True,
generation_config=GenerationConfig(temperature=0.2, max_output_tokens=2048),
)
)
結果は以下の通りです、良い感じと思います!
**** Result: *****
{
"answer": {
"employee_count_difference": 21199,
"employee_count_percentage_change": "16%"
}
}
テキストと画像の統合
それでは、テキストと画像のコンテキストを統合して、マルチモーダルRAGを実装してみましょう。
Step 1: クエリの準備
# クエリに基づいて関連するテキストチャンクを取得
matching_results_chunks_data = get_similar_text_from_query(
query,
text_metadata_df,
column_name="text_embedding_chunk",
top_n=10,
chunk_text=True,)
Step 2: 関連するテキストチャンクの取得
query = """質問: - 2020年から2021年にかけての従業員数の差とそのパーセンテージを教えてください。それは営業費用に影響を与えましたか? どのくらい? - 2021年の連結収益と売上原価の割合変化の要因は何ですか? Covidの影響はありましたか? - 2020年から2021年にかけて連結収益はどのくらい増加しましたか? 数値とパーセンテージを教えてください。 """
Step 3: 関連する画像の取得
# ユーザーのクエリに基づいて関連する画像をすべて取得
matching_results_image_fromdescription_data = get_similar_image_from_query(
text_metadata_df,
image_metadata_df,
query=query,
column_name="text_embedding_from_image_description",
image_emb=False,
top_n=10,
embedding_size=1408,)
Step 5: コンテキストをGeminiに渡す
prompt = f""" インストラクション:
画像とテキスト(コンテキスト)を比較して、複数の質問に答えてください。
回答前にはよく考え、どのように答えたかを説明できるように箇条書きで整理すること。
情報が不十分な場合は、「回答に必要なコンテキストが不足しています」と回答すること。
コンテキスト:
- テキスト:
{final_context_text}
- 画像:
{context_images}
{query}
回答:
"""
# Generate Gemini response with streaming output
Markdown(
get_gemini_response(
multimodal_model,
model_input=[prompt],
stream=True,
generation_config=GenerationConfig(temperature=0.2, max_output_tokens=2048),
)
)
それでは、以下の結果を確認してみましょう。
1. 従業員数の差とその営業費用への影響 従業員数の差:21,199人 パーセンテージ:16% 営業費用への影響:テキストには記載されていません。 2. 2021年の連結収益と売上原価の割合変化の要因とCovidの影響 連結収益の割合変化の要因: GoogleサービスとGoogleクラウドの成長 2020年の広告収入の悪影響からの回復 売上原価の割合変化の要因: TACとコンテンツ取得コストの増加 データセンターとその他の運用コストの増加 Covidの影響: 2020年の広告収入の減少 2020年後半の広告収入の回復 3. 2020年から2021年にかけての連結収益の増加 数値:$75,110百万 パーセンテージ:41%
全体的に見て、結果はかなり良いと言えるでしょう。Geminiはテキストと画像の両方から有用な情報を抽出することができました。また、質問に対する回答もかなり的確でした。
しかし、最初の質問に関しては、実際のページを見てみると(この画像を参照してください)、「従業員数の増加が営業費用に与える影響」に関する情報が少しだけ記載されています。ドキュメントと同じ言語でクエリを使用すると、より良い結果が得られるでしょう。
クエリとドキュメントが異なる言語であることを考えると、Geminiは非常に素晴らしい仕事をしていると言えます!
*** 英語でクエリ1を実行した場合の結果を次に示します。*** 1. Tell me the difference of employee number, and the percentage, from 2020 to 2021. Did it affect the operational expense? how much? The number of employees increased by 21,199 from 135,301 in 2020 to 156,500 in 2021, a 16% increase. Yes, the increase in employee count contributed to the increase in operating expenses. The text states that "Operating expenses were $68.0 billion, an increase of 20%, primarily driven by headcount growth, increases in advertising and promotional expenses and charges related to legal matters."
参考資料
このトピックについてさらに詳しく知りたい場合は、こちらのノートブックを参考にしてください(英語)。このノートブックは、本ブログ記事の主な参考資料です。
まとめ
今回は、Gemini APIのマルチモーダル機能を活用して、簡単なマルチモーダルRAGアプリケーションを構築する実験を行いました。Geminiがテキストと画像の両方から情報を抽出する能力をテストしただけでなく、クエリとは異なる言語のソースドキュメントをあえて使用してみました。
完璧ではありませんが、Geminiは良い仕事をしていると言えるでしょう。近い将来、Geminiは品質と能力をさらに向上させていくことが期待されます。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集要項一覧からご応募をお願いします。 一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD