2021.10.07
ちっちゃいMLOpsやってみた(手書き文字認識アプリ+kedro)
ご覧いただきありがとうございます。次世代システム研究室、新卒の N.M と申します。
前回のブログ記事は GMO インターネットグループの新卒技術研修(GMO Technology Bootcamp)での成果物に関する紹介でしたので、実質今回が初投稿となります。仕事に活かせるような実用的な先端技術の研究してきたわけではなく題材選びに苦労しましたが、今回は個人的に勉強してみたいと思っていた MLOps を触ってみようというテーマで書かせていただきたいと思います。ご覧いただけると幸いです。
今回行ったこと
- ブラウザ上で手書き文字を認識するアプリを作ってみる
- そのアプリで用いている機械学習まわりのコードに kedro を導入してみる
ちゃっちいちっちゃい MLOps を体験して勉強した気分になる
背景
私は入社する以前から業務や事業の効率化に興味がありました。(面倒臭がりなので)
非エンジニアレベルでの RPA を用いた業務効率化や、DevOps による開発・運用の効率化など気になっていましたが、その中で DevOps からインスパイアされた機械学習に関わる開発・実験・運用を整備する MLOps という手法があると知りました。
普段機械学習(その他様々なシミュレーションも含む)を使う上では当然パフォーマンスが最重要であり、データや処理の流れといったパイプラインの整備まで目をむける余裕がないということもありますが、一度実際に手を動かして触ってみたいということで機械学習パイプラインツールである kedro を使ってみます。
今回の実装の焦点
MLOps で検索した際よく目にする図に Google さんが出しているドキュメントに描かれた以下の図があります。
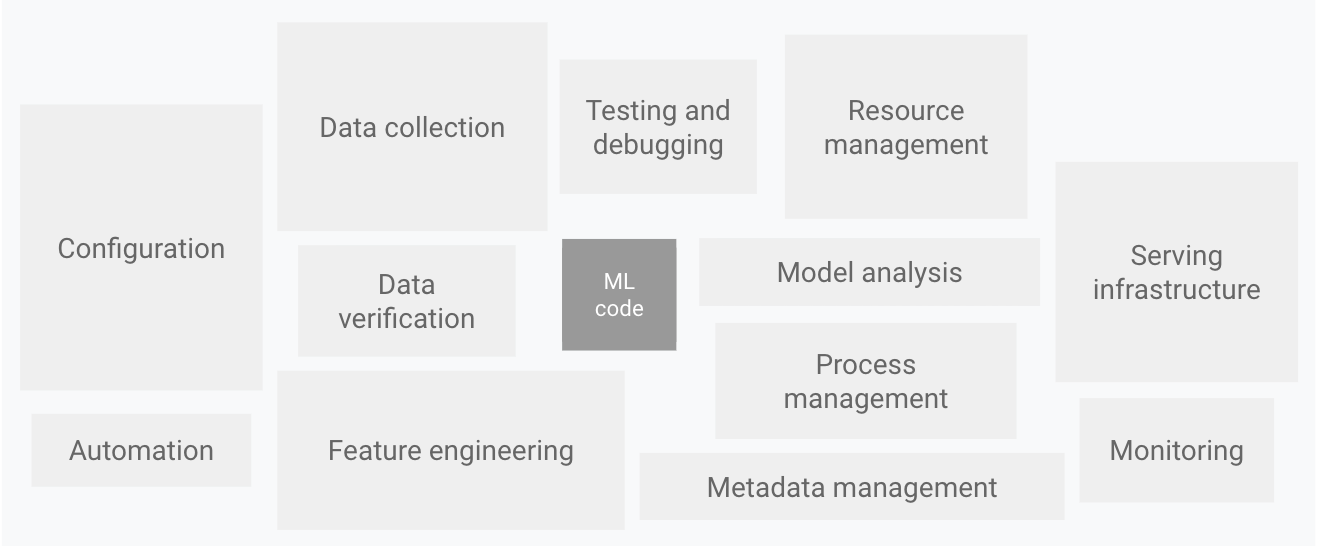
主たるメッセージとしては「機械学習システムの中でモデルに用いられるコードはほんの一部分でしかなく、データ収集やモデルの解析といったことだけでなく、自動化や監視まで複雑な要素が絡んでいる」ということだと思いますが、これに付随して「MLOps はこれらの複雑な技術的負債を解決するための取り組みであり、どの部分を解決するためのものかによって性質がかなり異なる」ということも言えるかと思います。メタデータの管理やテストなどの実験に関わる部分を効率化することも、機械学習システムへの訓練済みモデルのデプロイを自動化させることも、データや処理の流れを整備することも全て MLOps の指し示す領域です。
基本的にはデータサイエンティストの方が MLOps を駆動させたいと思う動機として「実験時のモデルのメタデータや結果が煩雑で整理できていないなぁ…」といったことから実験管理ツール(MLFlow など)に手を出すことが多いかと思いますが、今回はあえて実験管理の部分ではなく、データがどこからどこに流れ、どのような処理をするかという機械学習パイプライン構築の部分に焦点を当てたいと思います。実験管理については偉大な先輩の書かれたこちらのブログをご覧ください。勉強させていただきました。
アプリ制作
せっかく機械学習パイプラインを構築するので、データがどんどん増えていくようなシステムに適用させたいと考えました。そこで今回はブラウザ上で文字を書き、書いた文字に対応した数字を押すことで、文字を識別するという手書き文字認識アプリを作りました。アプリケーションの構成は以下の通りです。
- フロントエンド:JavaScript
- バックエンド:Flask
- 機械学習ライブラリ:Keras
図に起こす必要もないくらいに非常に簡素な構成です。アプリケーション+機械学習という題材において、MNIST という有名なデータセットがあるということや、データ(手書き文字の画像)がわかりやすいという意味でもちょっとやってみたいという分には手書き文字認識が最適かもしれません。
今回は外部リソースは使用せず、全てローカルの PC 内で実装しています。また、ボタンを押すことでサーバ側に画像データと正解ラベルが POST されるのですが、そのデータの保存に関しては DB を使わずにそのまま MNIST のデータと同じ形式の pickle ファイルとして追加していくというとても原始的な方法で実装しています。DB からデータを抽出 → そのデータを使って訓練・検証 → そのモデルを本番環境にデプロイという流れを構築できたらよかったのですが、それぞれの処理で本腰を入れると相応重たいので今回は真ん中の「データを使って訓練・検証 」の部分に焦点を当てます。
kedroの導入
上記のアプリケーションに対して、今回はパイプラインツールである kedro を使います。このツールを使ったパイプラインの入門として偉大な先輩の書かれたこちらのブログがありますので、合わせてご覧ください。勉強させていただきました。(500 字ぶり 2 度目)
まずお決まりのライブラリのインストールです。kedro を pip でインストールした後、プロジェクトを作っていきます。
$ pip install kedro $ kedro --version kedro, version 0.17.5 $ kedro new
この後、いくつか情報を入力することによって勝手に出来上がるディレクトリ群も含めて、個人的に重要だと思ったファイルを抜粋すると以下のようになります。
.
├── ...
├── conf
│ └── base
│ ├── ...
│ ├── catalog.yml # データの登録
│ └── parameters.yml # パラメータの登録
├── data
│ ├── ...
│ ├── 03_primary
│ │ ├── app.pkl # アプリからのデータ
│ │ └── mnist.pkl # MNISTのデータ
│ ├── ...
│ ├── 06_models
│ │ ├── model # アプリ用モデル
│ │ ├── pre_model # 訓練後のモデル
│ │ └── tune_model # チューニング後のモデル
│ └── ...
└── src
├── ...
└── tegaki
├── ...
├── pipeline_registry.py # 全体のパイプライン定義
└── pipelines
├── data_engineering
│ ├── __init__.py
│ ├── nodes.py # 前処理を記述
│ └── pipeline.py # 前処理のパイプライン定義
├── data_science
│ ├── __init__.py
│ ├── nodes.py # 訓練・テストの処理を記述
│ └── pipeline.py # 訓練・テストのパイプライン定義
└── fine_tuning
├── __init__.py
├── nodes.py # チューニングの処理を記述
└── pipeline.py # チューニングのパイプライン定義
大枠としては、conf/base ディレクトリ内のファイルでパラメータとデータの形式を記述し、そのデータの形式通りに data ディレクトリ以下から読み込み(あるいは書き込み)が行われます。上記のパラメータとデータを使って、src 以下のディレクトリで実際にパイプラインを記述していくというイメージです。
ここからはいくつかファイルを抜粋して記述していきます。
conf/base ディレクトリと data ディレクトリ
conf/base ディレクトリの中の二つはデータの形の登録やパラメータの登録を行います。
(catalog.yamlの内容) mnist_data: type: pickle.PickleDataSet filepath: data/03_primary/mnist.pkl backend: pickle app_data: type: pickle.PickleDataSet filepath: data/03_primary/app.pkl backend: pickle pre_model: type: tensorflow.TensorFlowModelDataset filepath: data/06_models/pre_model tune_model: type: tensorflow.TensorFlowModelDataset filepath: data/06_models/tune_model # # アプリで参照するモデル 今回は手動でコピーしています # model: # type: tensorflow.TensorFlowModelDataset # filepath: data/06_models/model
(parameters.ymlの内容) num_classes: 10 img_rows: 28 img_cols: 28 batch_size: 128 ...
parameters.yml はその名の通りです。catalog.yml には data ディレクトリの中にどのような形式のデータを入れるかということを記述します。csv や pickle はもちろんのこと、今回使う Keras のモデルを丸ごと保存できるタイプなんかもあります。うまく扱うことで様々な形のデータを対象として I/O の管理ができます。
今回は MNIST のデータを pkl として事前保存しておき前処理の際に読み込み、アプリ側から POST されたデータも同様の形式でアプリ側から書き込み、MNIST のデータ同様前処理のタイミングで読み込みます。MNIST のデータを使って訓練したモデルを pre_model として保存し、作成された pre_model をチューニングしたモデルを tune_model として保存します。また、生成されたモデルを model という名称でコピーしてアプリ側から使用します。このあたりは極めて原始的なデプロイなので検討の必要があります。
src ディレクトリ
src ディレクトリでは実際にパイプラインの記述を行っていきます。パイプラインの流れとしては、スタンダードに MNIST のデータを訓練データ、バリデーションデータ、テストデータに分けた上で訓練してテストするという流れのほか、アプリから pickle 形式に追加されていくデータを使って特定の層のみ学習させるファインチューニングを MNIST のデータで訓練済のモデルに適用してさらに新しいモデルを作る、といったパイプラインを作っていこうと思います。
イメージとしてはディレクトリを「うまい具合に」分けて、node.py に処理を関数の形で記述して、それを pipeline.py で呼び出し、各ディレクトリで作られた pipeline.py を pipeline_registry.py に登録して使用するといったイメージです。
ディレクトリの分割パターンとしては前処理を行う data_enginering のパイプラインと訓練やテストを行う data_science のパイプラインに分割することが多いようです。今回はそのパイプラインにファインチューニング用のパイプラインを用意しました。
まずは node.py の例です。
(data_science内のnode.pyの一部)
def train(x_train, y_train, x_valid, y_valid, parameters):
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',\
input_shape=(parameters["img_rows"],parameters["img_cols"],1)))
model.add(Conv2D(64, (3, 3), activation='relu'))
...(中略)...
model.add(Dense(parameters["num_classes"], activation='softmax'))
model.compile(loss='categorical_crossentropy',\
optimizer=RMSprop(),metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=parameters["batch_size"], \
epochs=parameters["epochs"], verbose=1, validation_data=(x_valid, y_valid))
return model
def report(model, x, y):
score = model.evaluate(x, y, verbose=0)
print("****************************")
print('Test loss:', score[0])
print('Test accuracy:', score[1])
print("****************************")
(fine_tuning内のnode.pyの一部)
def tuning(model, x_app, y_app, parameters):
for i in range(len(model.layers)):
if i != parameters["tuning_layer"]:
model.layers[i].trainable == False
model.compile(loss='categorical_crossentropy',\
optimizer=RMSprop(),metrics=['accuracy'])
model.fit(x_app, y_app, batch_size=parameters["tuning_batch_size"], \
epochs=parameters["tuning_epochs"], verbose=1)
return model
一般的な Python の関数です。node.py に記述するのは前処理や訓練、評価といった機械学習システムを組む上で必ず必要な処理の部分なので、既に用意している関数を特に問題なく使用することができます。
いくつかの関数に parameters という引数があると思います。これは次に記述する pipeline.py で前述の parameters,yml に書かれたパラメータ群を引数としてあたえています。
(fine_tuning内のpipeline.py)
from kedro.pipeline import Pipeline, node
from .nodes import tuning
from ..data_science.nodes import report
def create_pipeline(**kwargs):
return Pipeline(
[
node(
func=tuning, # node.pyに記述した関数名
inputs=[ # パイプラインの前の関数からのインプット
"pre_model", # catalog.ymlに書いた"pre_model"
"app_x", # 前のパイプラインから得た画像データのArray
"app_y", # 前のパイプラインから得た正解ラベル
"parameters" # parameters.ymlに記述したパラメータ
],
outputs="tune_model", # チューニングしたモデルを次に渡す
name="tuning",
),
node(
func=report, # node.pyに記述した関数名
inputs=[
"tune_model", # チューニングしたモデルを受け取る
"mnist_test_x", # 前のパイプラインから得たMNISTのテストデータセット
"mnist_test_y", # 前のパイプラインから得たMNISTのテストデータセット
],
outputs=None,
name="report"
)
]
)
今回はスペースの都合上省略していますが、この前に呼び出す前処理のパイプラインで app_data を app_x と app_y に分割しています。そのデータに加えて、catalog.yml で指定した”pre_model”を読み込んで先ほど記述した tuning 関数に引数としてあたえています。使ってみるとわかるかと思いますが、特にimportしている訳でもない変数っぽいものが自然と使えることがどこか不思議な気分でした。(それを裏でやってくれるのがパイプラインツールなのですが。)
最後にこのさらに上の階層で先ほど記述した各パイプラインを統合します。
from kedro.pipeline import Pipeline
from tegaki.pipelines import data_engineering as de
from tegaki.pipelines import data_science as ds
from tegaki.pipelines import fine_tuning as ft
def register_pipelines() -> Dict[str, Pipeline]:
...(中略)...
tegaki_de_pipeline = de.create_pipeline()
tegaki_ds_pipeline = ds.create_pipeline()
tegaki_ft_pipeline = ft.create_pipeline()
return {
"de": tegaki_de_pipeline,
"ds": tegaki_ds_pipeline,
"ft": tegaki_ft_pipeline,
"__default__": tegaki_de_pipeline + tegaki_ds_pipeline,
"tuning": tegaki_de_pipeline + tegaki_ft_pipeline
}
それぞれの pipeline を呼び出して、上述のように書くことで実行できるようになります。今回の場合、kedro runを実行するとデータを前処理して訓練してテストして結果を出力、kedro run --pipeline tuningを実行するとデータを前処理してモデルを読み込んでファインチューニングしてテストして結果を出すという一連の流れをやってくれます。このようにしてパイプラインを構築していきます。
長々とコードを転記しましたが、スペースの都合上一部のみの抜粋のため全体像を掴みにくかったかと思います。申し訳ないです。ありがたいことに、kedro には kedro-viz という可視化ツールがあります。
pip kedro-vizでインストールした後、kedro vizと実行すると先ほどのパイプラインやcatalog.ymlが正しく書けてさえいれば下のようにブラウザ上で可視化してくれます。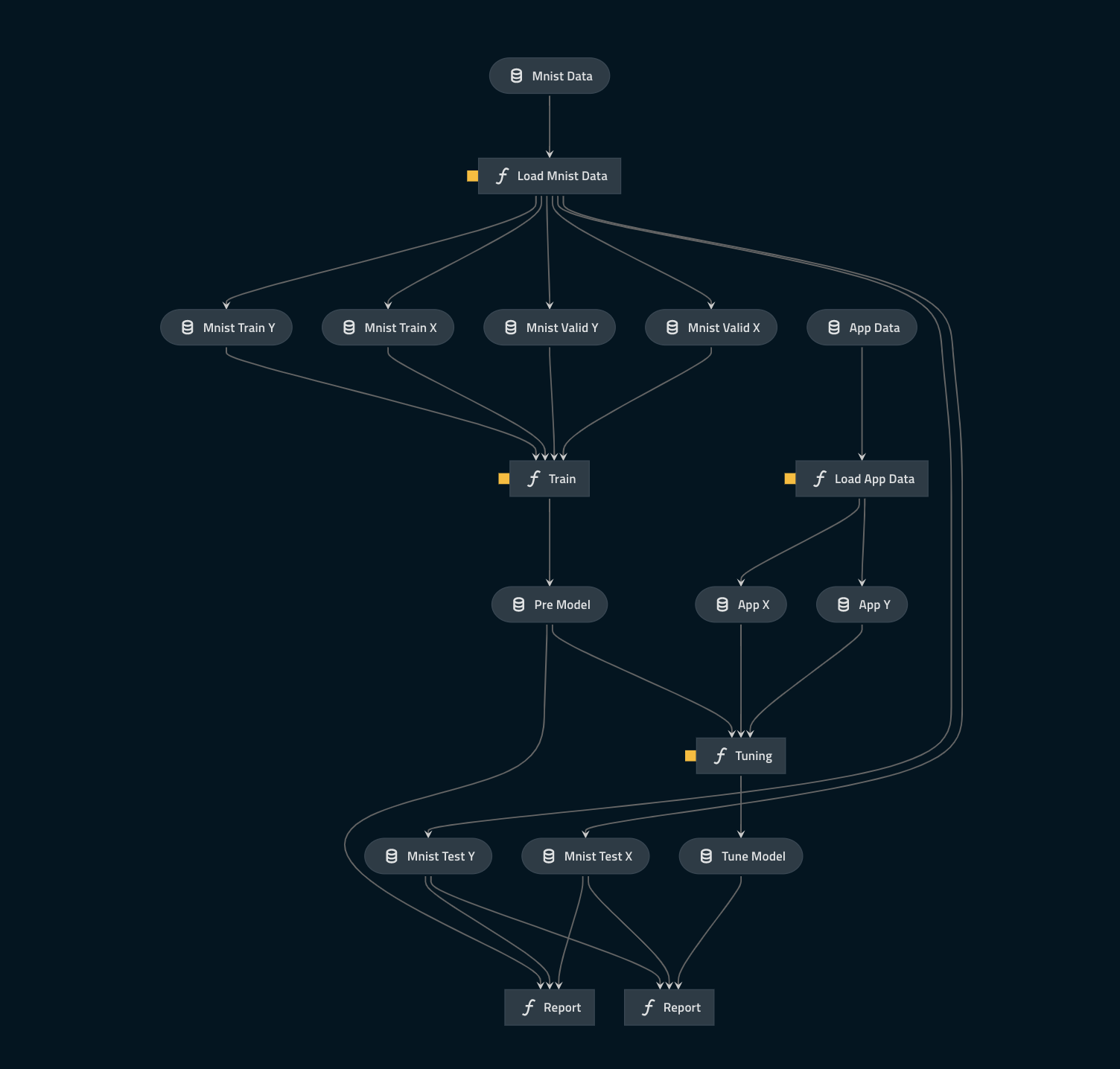
表示するノードやデータを変更することもでき、非常に好感触でした。(今回はシンプルなシステムだったからかもしれません。)
まとめと所感
今回は手書き文字を認識するアプリを作成し、そのアプリに kedro を導入した上で、新たなデータ入手 → そのデータでモデルを再テストの流れを整備できるよう実装してみました。細かい実験管理やデプロイの自動化、データの保存方法など改善点はまだまだあると思いますので、引き続き勉強していきたいと思います。
本記事を書くに当たって感じたこととして 2 点、プロダクションレベルでの MLOps の規模感の想像が社会人未経験の新卒にとってはなかなか難しいということと、前述の通りそもそも MLOps の指し示す領域が相当広いということがあります。
前者については今回は割り切ってかなり小規模かつ手探りで実装を行いましたので、数年後にはこの記事が自分にとって黒歴史になっているかと思います。後者に関しては MLOps を学ぶ上で非常に重要な点かつハードルが高い要因だと個人的には思います。
凄まじいスピードで進化し続ける機械学習界隈において、同様のスピードでそれらが生み出す課題を上手く解消できるように効率良く開発・実験・運用していくことはとても重要な要素だと考えています。実プロジェクトレベルではどのような規模・技術で機械学習パイプラインで運用しているのか、またどうすればさらに効率良く開発ができるようになるのかなどを意識しつつ仕事をしていきたいと思います。ご覧いただきありがとうございました。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティスト、及びグループ全体のインテグレーションを支援してくれるアーキテクトを募集しています。インフラ設計、構築経験者の方、次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD