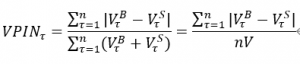2021.10.06
GCP VertexAI事始め(データ管理周り)
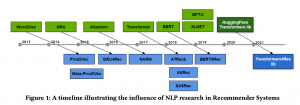
次世代システム研究室のT.Sです。皆様Google Cloud Platformが発表したVertexAIというサービスはご存知でしょうか?2021年5月のGoogle I/Oで発表されたサービスであり、これまでAI Platformとして提供されていた機械学習関連サービスより広範囲であり、データ準備から学習、特徴量作成、サービス提供、監視を一貫性を持って管理、実装、提供できる素晴らしいサービスです。VertexAIの日本語情報もまだまだ多くはないということで、超基礎部分ではありますが。VertexAIのデータ周りに特化して解説・紹介したいと思います。
VertexAIサービス概要
先述したとおりVertexAIは広範囲且つ一貫性を持った機械学習サービスです。そのためVertexAI配下に複数の役割を持った機能が属しています。以下がその概要の主だったところとなります。まさにデータから学習まで様々なものが存在していますね。
- データセット
- VertexAI内で利用するデータソース。CSVなどはここに取り込む事もできるし、BigQueryから直接利用することも可能
- 特徴量
- Feature Storeと呼ばれる特徴量管理のためのデータストア。指定時間における特徴量の抽出や再利用などに大きく役立つ
- ノートブック
- JupyterLab環境。特定のFramework/Versionを持った環境を素早く立ち上げることができる
- パイプライン
- 機械学習の一連の流れをパイプラインとして実装・実行する環境。Tensorflow ExtendedやKubeflowで記述
- トレーニング
- MLモデルを学習するための環境。AutoMLを利用して素早く実装することも可能であるし、Dockerコンテナベースであればあらゆるフレームワークにも対応できる
- モデル
- 学習済みモデル管理機能
- エンドポイント
- 学習済みモデルをServするAPIを作成する機能。GAEやCloudRunのようにスケーラブルな環境を実現可能
これ以外にもVertexAI Monitoringのような監視機能までそろっており、まさに機械学習モデルを提供するために必要な機能が一式そろったサービスであることがわかります。今回のPostではこの中からデータにまつわる「データセット」「特徴量」「監視」について概要を説明したいと思います。
データセット
データセットはその名の通り、学習に利用するデータセットを格納するサービスになります。いわゆるテーブルデータであればBigQueryという唯一無二のサービスがあるため、そちらに格納されていることも多いかともいますが、画像/テキスト/動画についてはGCSに置くしかなく、ちょっと取り扱いにくいなという印象を受けていた方も多いかもしれません。VertexAIではそのような非構造データでも対応できるよう工夫が加えられています。
特にアノテーションツールが充実しているため、これからデータセットを作るという時には心強い味方となります
画像
画像で取り扱いできるのは以下の4つになります
- 画像分類(単一ラベル)
- 画像分類(複数ラベル)
- 画像オブジェクト検出
- 画像セグメンテーション

試しにマルチラベルでの画像をデータセット取り込みしてみましょう。「画像分類(複数ラベル)」を選択すると以下の画面が表示されます。
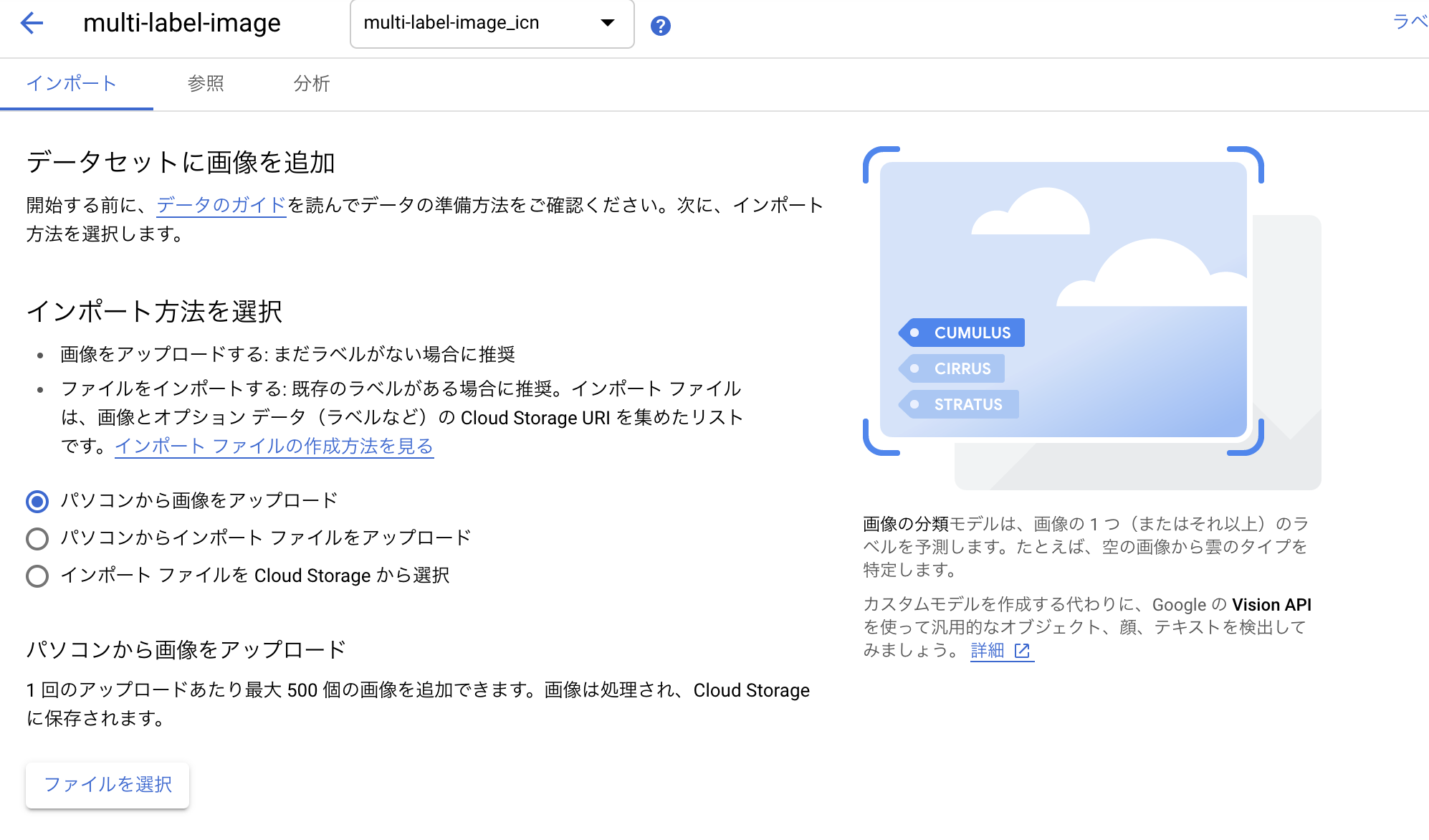
ここでは特に難しい設定は何もいりません。既存でラベリングされたものがあればインポートファイル形式でUploadされればひも付きますが、今回は簡単のために画像だけアップロードしたいと思います。
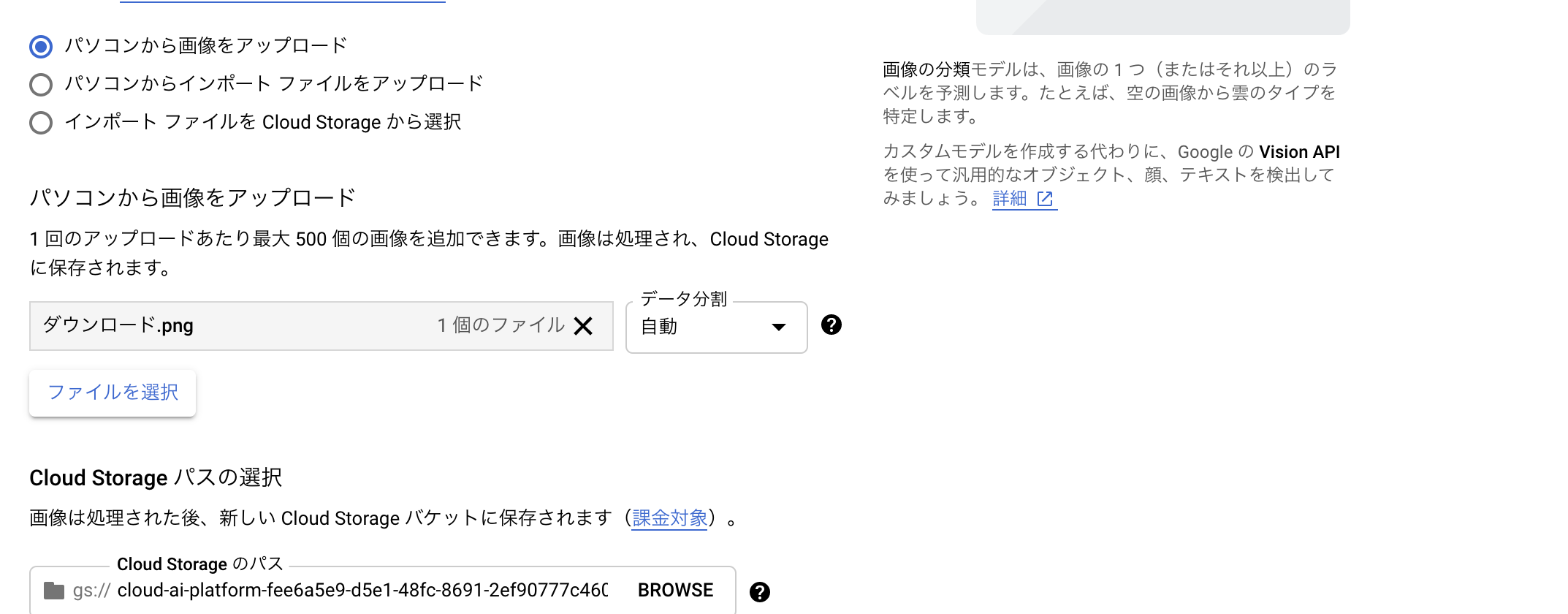
画像アップロードが完了すると、アノテーション画面に遷移します。ここがVertexAIの素晴らしいところで各種非構造データに対してアノテーションツールが存在します。これまでは様々なアノテーションツールを別途用意するひつようがありましたが、かなり便利になっています。またラベリングを外部の専門家に依頼することも、この画面から簡単にできるようになっています。アノテーションにかかる面倒な事前作業が一画面で終わるという素晴らしいUIですね。
表形式
テーブルデータは以下の2つになります。個人的にはテーブルデータはBigQueryから直接使うことが多いですね
- 回帰/分類
- 予測
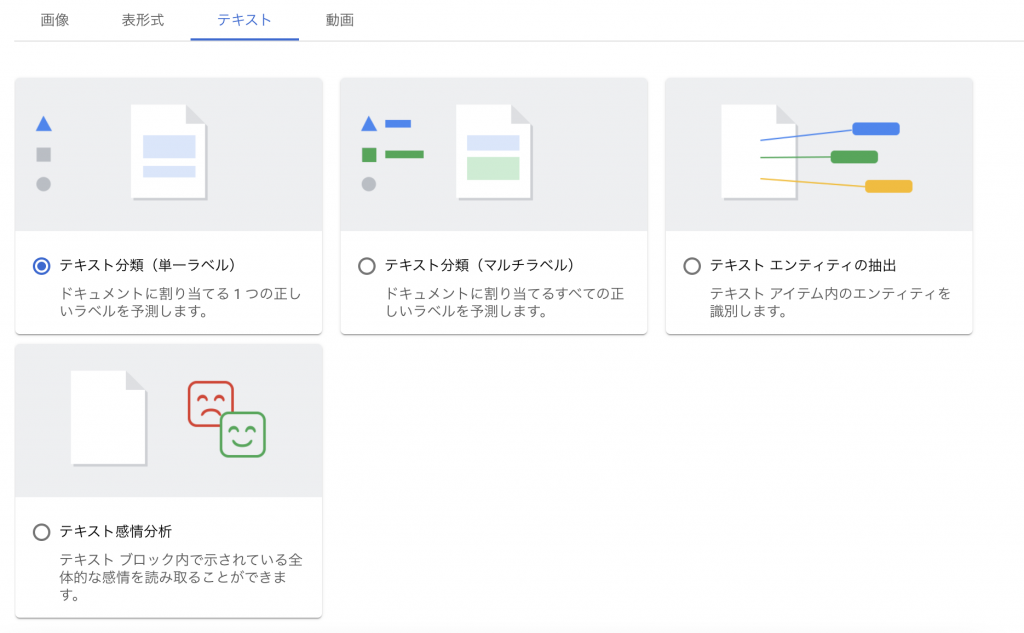
テキスト
テキストは画像と似た区分になっています。固有表現抽出があるのは嬉しいですね
- テキスト分類(単一ラベル)
- テキスト分類(複数ラベル)
- テキストエンティティの抽出
- テキスト感情分析
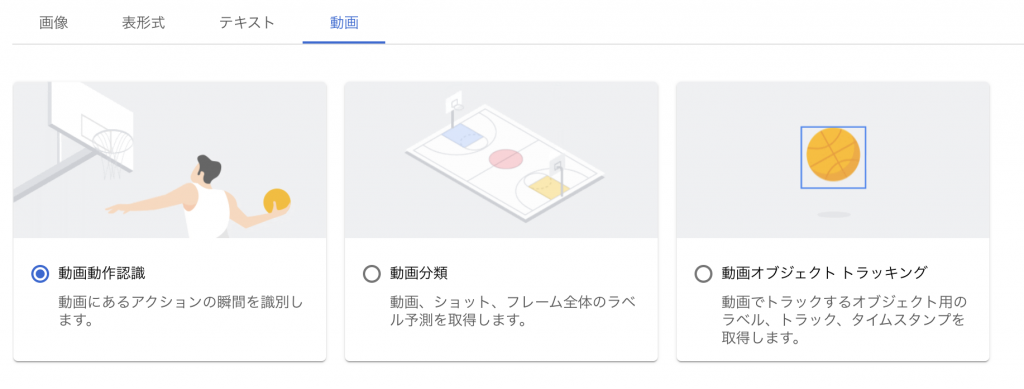
動画
最後は動画になります。私はあまり使う機会がないのですが、動画データセットを扱うための区分があるというのはかゆいところに手が届くという人も多いのかもしれません
- 動画動作認識
- 動画分類
- 動画オブジェクトトラッキング
以上がデータセットで扱える各種区分になります。アノテーションツールも備わっており、これだけでもかなり高機能であると感じ取れるサービスになっています。
特徴量
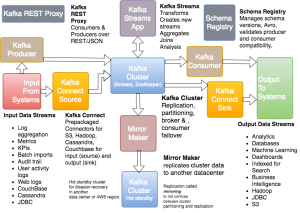
VertexAIでは、上記のように学習データをストアするだけでなく特徴量を管理するためのFeature Storeを設けています。「Feature Storeって?」と思う方もいらっしゃるかと思いますが、これは特徴量(fearture)を集中管理するためのレポジトリだと理解いただければとよいかと思います。例えば複数組織でMLモデルを利用している場合、それぞれがFeature Engineeringしてしまいことも多いかと思います。この場合せっかくのアイディアが共有されなかったり、また同じような特徴量を作るために計算資源を二重三重で使ってしまって無駄が発生しているということも多いかと。また、Training時に過って必要外のデータを利用してしまいLeakageを起こすなどといった学習時の問題点も発生します。こういったFeature周りでよく発生する問題を、管理レポジトリを用意することによって防ごうというのがFeature Storeの目的となります。
feastというOSSが存在しましたが、機能面ではこのfeastに非常に似通ったものになっているので、すでにfeastに慣れている方であれば非常にとっつきやすいものになっています。
今回はFeature Storeへのデータ格納・取り出しのみを簡単にコード例をお見せしますが、これを踏まえ実際に使っていただけるとその有用さがじわじわと実感できるものなのかなと感じています。
スキーマ定義
VertexAI Feature Storeでは「Feature Store」「Entity」「Feature」の3つの概念が存在します。
「Feature Store」はRDBでいうdatabaseにあたるものだと考えるのが一番近い気がします。「Entity」はRDBでいうTable、「Feature」はカラムだと考えるのが理解しやすい気がします。似て非なるものではありますが、階層構造になっており、最終的に「Feature」に値を投入します。
では実際に「Entity」「Feature」を作ってみましょう。コードから実行することもできますが、ここでは説明のため画面から作ってみようかと思います。
まず画面上部から「エンティティ タイプを作成」選択します。

押下後、Entityの情報を入力するダイアログが開きます。今回はおなじみのirisを使い、petal/sepalでEntityを分け登録してみたいと思います。通常はデータのグループ単位でここを分けることになりますので、例えばuser/media/adなどわかりやすい単位でグルーピングを定義することとになります。後続のデータ取得ではこのEntity単位で取得するため、一緒に抽出したいものをまとめると良いでしょう。
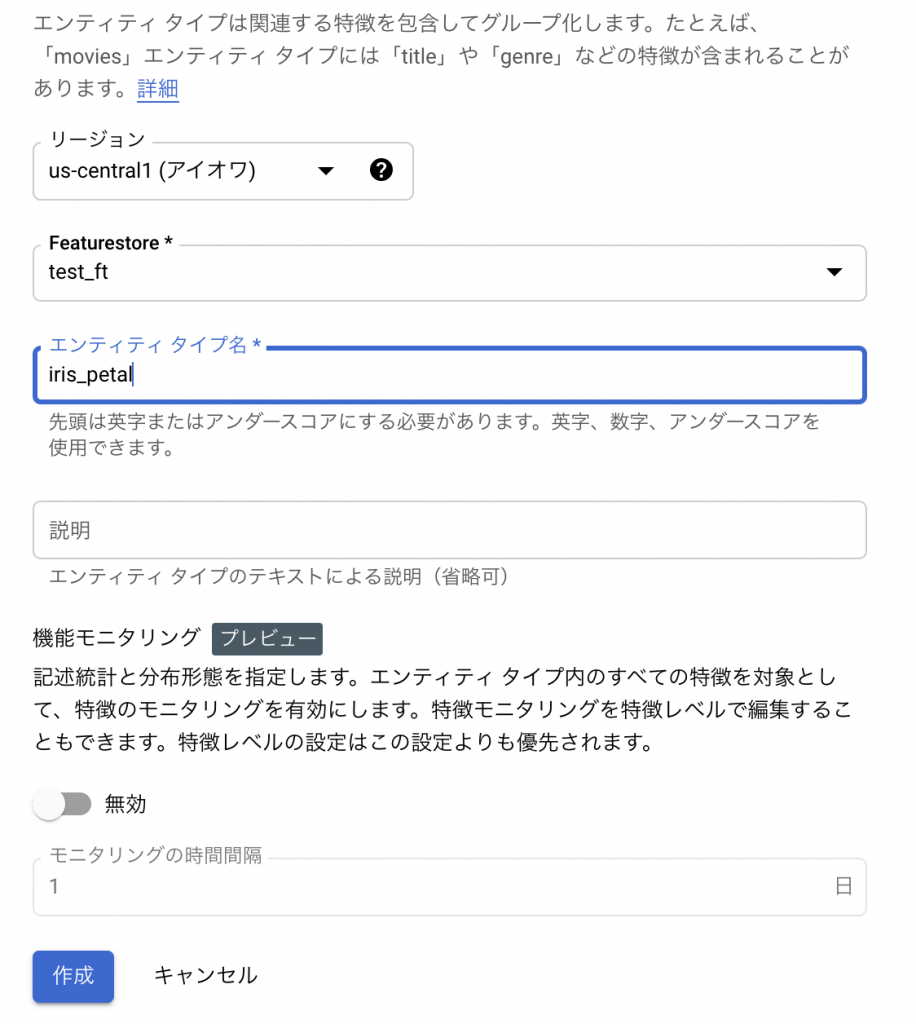
Entityが定義できたら、次は実際に値を格納するFeatureとなります。ここではirisに格納されているpetal-widthをそのまま登録・格納できるようにしていますが、特徴量エンジニアリングなどで必要な特徴があれば、その際に追加していく形になりますね。
ここで追加を選択して

開いたダイアログで適宜情報を入力していきます
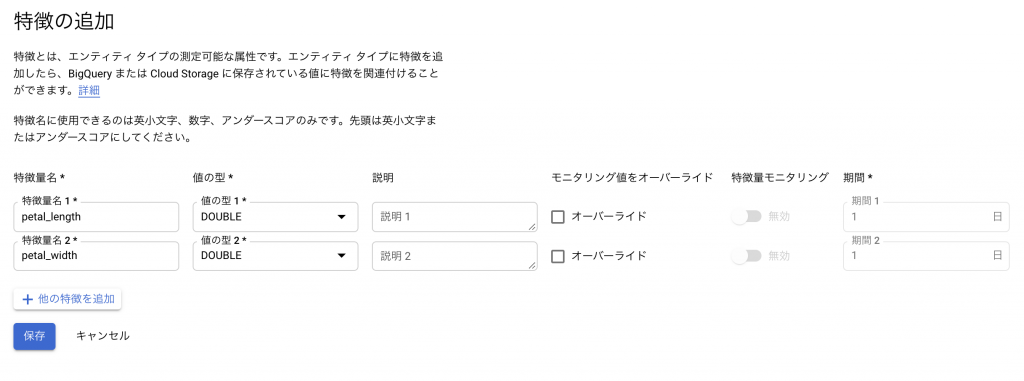
これで完成となります。用語がとっつきなれないですが、実際に操作してみると特に違和感もなく作成できたかと思います。
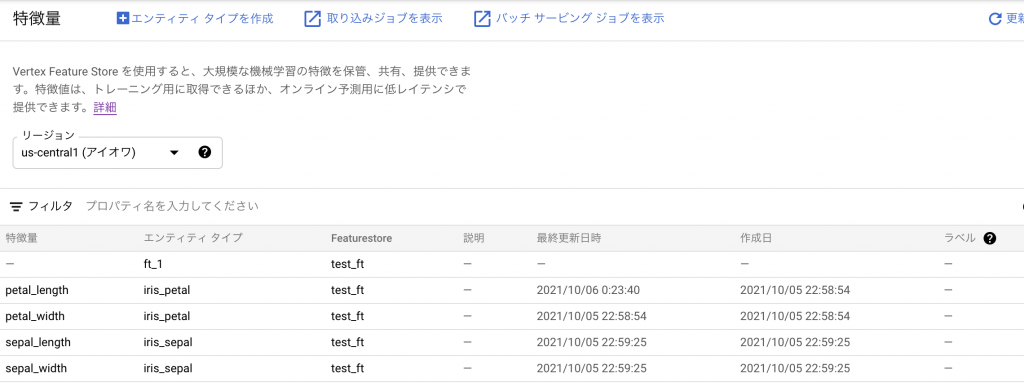
データ投入
さてスキーマが定義できたので、ここにデータを投入してみましょう。データ投入からはコードベースになります。VertexAI Notebookを使うと、いろいろな認証周りも省略できて便利なので、ぜひご活用ください。
下記がDataを一括でBigQueryからImportするコードです。
注目すべき箇所をいくつか後続でで見ていきましょう
FEATURESTORE_ID = "test_ft"
import_users_request = featurestore_service_pb2.ImportFeatureValuesRequest(
entity_type=admin_client.entity_type_path(PROJECT_ID, REGION, FEATURESTORE_ID, "iris_petal"),
bigquery_source=io_pb2.BigQuerySource(input_uri="bq://hogehoge.dataset.iris"),
entity_id_field="id",
feature_specs=[
featurestore_service_pb2.ImportFeatureValuesRequest.FeatureSpec(id="petal_length", source_field="petal_length"),
featurestore_service_pb2.ImportFeatureValuesRequest.FeatureSpec(id="petal_width", source_field="petal_width"),
],
feature_time_field="updated_at",
worker_count=1,
)
ingestion_lro = admin_client.import_feature_values(import_users_request)
ingestion_lro.result()
ImportするClassはいくつかありますがここではImportFeatureValuesRequestという一番一般的なものを使っています
データソースは以下でBigQueryを指定していますが、その他にもCSVを利用するCsvSourceやGcsSource、AvroSourceなどが存在するため利用用途に合わせて切り替えます
bigquery_source=io_pb2.BigQuerySource(input_uri="bq://hogehoge.dataset.iris")
引数の一つにentity_id_fieldというものがありますが、これをFeatureを一意に特定するIDとなります。無為連番でも構いませんし、UserIDなどのIDでも、その他Uniqueに特定できるKey情報を指定します。ただしDataTypeはStringとなるため数字連番の場合はStringで定義することをお忘れなく
entity_id_field="id"
また時間フィールドも必要となります。これは同一IDであっても時間経過で特徴量が変わる場合に、指定した時間の特徴量を掴むために必要になってきます。
feature_time_field="updated_at",
ここまで設定した後はclient.import_feature_valuesでimport実行します。この関数自体はすぐ返却されますが、実際のImportは終わっていませんのでご注意ください。本当に結果を知りたければresult関数で結果を取得してもらえれば、完了時に結果が表示されることとなります
ingestion_lro = admin_client.import_feature_values(import_users_request)
データ読み込み
データの読み込みも様々ありますが、ここではexampleでも一番最初に出てくる最も基本的なものを紹介します
data_client.read_feature_values(
featurestore_online_service_pb2.ReadFeatureValuesRequest(
entity_type=admin_client.entity_type_path(PROJECT_ID, REGION, FEATURESTORE_ID, "iris_petal"),
entity_id="4",
feature_selector=FeatureSelector(id_matcher=IdMatcher(ids=["petal_length"])),
)
)
entity_type_path関数でEntityを指定し、FeatureSelectorでFeature名を指定しています。sqlalchemyで考えると、FeatureSelectorがquery関数でカラムしている箇所だと思えばわかりやすいでしょうか?その後entity_idで対象IDを指定しています。sqlalchemyでいうところfilter関数ですね。もちろん複数指定して取得する方法も存在します。
entity_type=admin_client.entity_type_path(PROJECT_ID, REGION, FEATURESTORE_ID, "iris_petal") entity_id="4", FeatureSelector(id_matcher=IdMatcher(ids=["petal_length"]))
結果は以下のように表示されます。generate_time内に存在しているUnixTimeは取り込み時に指定したUpdated_atのようですね。ここを見ればどの時間に生成されたかがわかるようです
header {
entity_type: "projects/...."
feature_descriptors {
id: "petal_length"
}
}
entity_view {
entity_id: "4"
data {
value {
double_value: 1.5
metadata {
generate_time {
seconds: 1633443720
nanos: 383000000
}
}
}
}
}
特徴量監視
データに関するサービスについて、最後は特徴量の監視となります。特徴量の監視とはなんでしょうか?VertexAIでは、「学習時のデータ分布と、本番稼働後のデータ分布に大きな差異がないか」を監視する機能を提供しています。例えばDSチームが生成したモデルを本番適用するまでに一定期間が空く場合や、定期的なモデル学習の仕組みがない場合などは、学習時のデータ分布と比較して本番のデータ分布が異なることが発生します。こうなってしまうとモデル学習の前提が崩れてしまうため、モデル精度に大きな悪影響を及ぼしてしまいます。VertexAIでは、これを早期に検知するためVertexAI Monitoringというものが用意されています
監視できる項目
VertexAI Monitringが検出できる項目には「スキュー」と「ドリフト」の2種類が存在します。「スキュー」の場合のベースラインは、Training時のデータとなり、現在の本番データがトレーニングとどれだけ乖離しているかを検出します。それに対して「ドリフト」は直近に本番で確認されたデータが比較対象となります。時刻n と n+1を比較して時間で差異が発生してないかを検出するわけですね。
この差異は数値・カテゴリどちらでも利用できます。数値の場合はジェンセン・シャノンダイバージェンスを、カテゴリの場合はチェビシェフ距離を使って分布感の距離を計算し、設定した閾値以上の場合はAlertが来る仕組みとなっています。
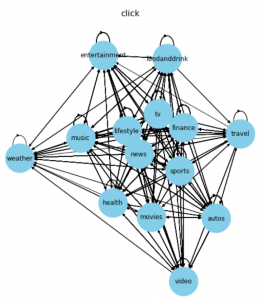
Alert発生時のデータ分布は以下のように確認できます。グラフィカルにでも確認できて直感的ですね。
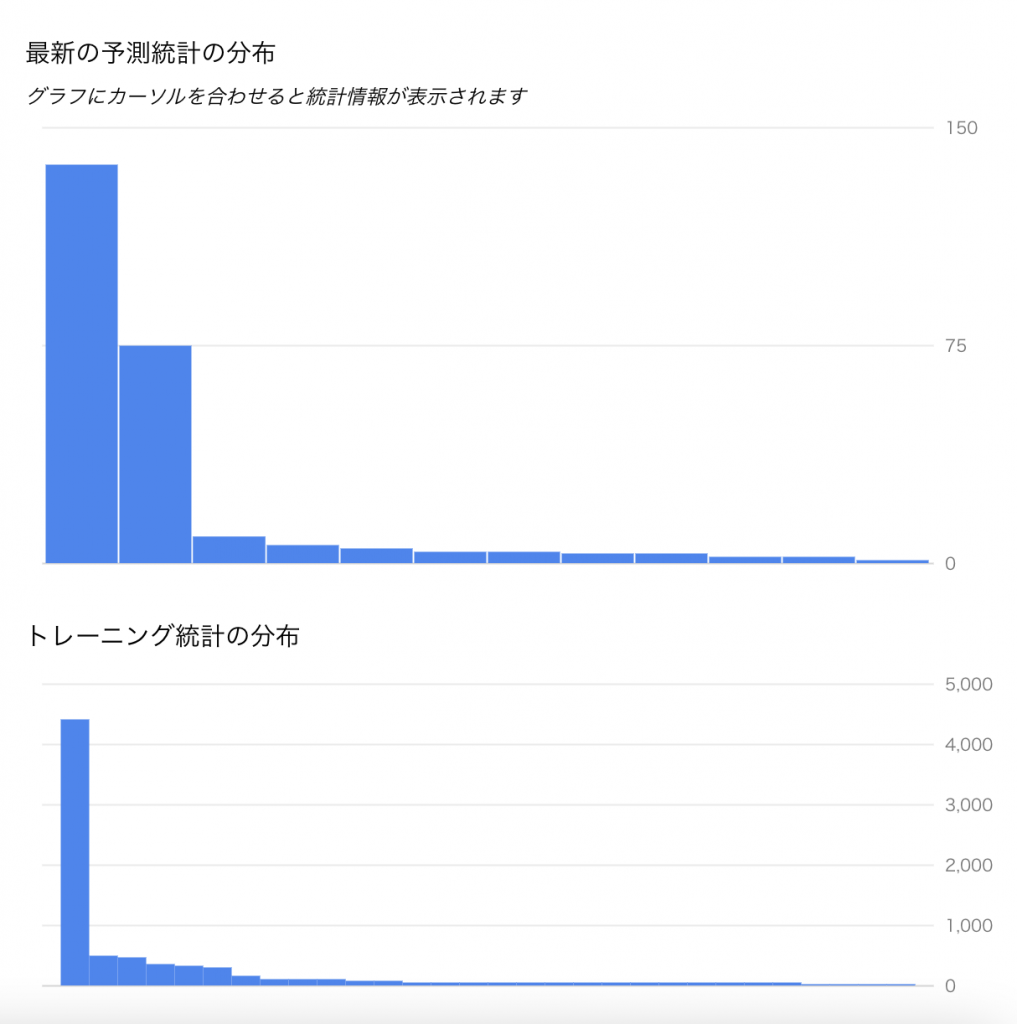
ただし一点だけ注意をしなくてはいけないのが、VertexAI MonitoringはVertexAIのEndpointを利用する場合のみ使うことができます。本番で受けたリクエストをサンプリングして監視するので当たり前といえば当たり前ですが、そこだけご注意ください。
おわりに
今回はVertexAIのはじめの一歩であるデータ周りのサービス概要を大まかに記載してみました。VertexAI自体は非常に広範囲であり、PipelineやTrainingなどを組み合わせてこそ本領を発揮します。今回は第一歩を書くだけにとどまりましたが、機会があれば他にも色々記載したいと思います。また
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD