2021.10.06
施策につなげる機械学習〜KPIの設計とOff-Policy Evaluation〜
こんにちは次世代システム研究室のT.I.です。
私はデータ・サイエンティストの端くれとして、データをビジネスを活用するために日々、試行錯誤を重ねております。しかしながら、現実では利用可能なデータは限定されていますし、質も必ずしも高くなく、ビジネス面からの要求とのすり合わせ、現実的に可能なアクション、関係各所との調整云々など、課題は山積みです。
そんな折、先日出版されました「施策デザインのための機械学習入門」という書籍を拝読いたしまして大変参考になりました。今回のブログでは、実際のデータから意思決定につなげる際に常に注意すべきデータのバイアスと観測構造、同書で紹介されました実践のためのフレームワーク、そして「過去に実施しなかった施策」をどうやって評価するか?というOff-Policy Evaluation について紹介します。
(本音を言うと、こんなブログを読むよりも、同書「施策デザインのための機械学習入門」(Kindle版もあります)をまずはご一読いただくことをおすすめします。)
観測データと意思決定
昨今、蓄積されたデータをビジネスにおいて活用することが重要視されています。大量に高精度のデータがあれば、それで十分なのでしょうか?
実はデータを取得する段階で、それには様々の偏り(バイアス)が紛れ込んでいます。そのために、どのようなプロセスで観測・集計されたデータであるのかを理解する必要があります。最初にデータに潜むバイアスに気づいて成功した例と、逆に気づかないまま判断を下し大惨事となった例を紹介します。
観測できたデータ
第二次世界大戦中に統計学者 Abraham Wald が、爆撃機の防御についての研究しました。以下の図は、帰還した機体の損傷箇所分布です。安全性のためには可能な限り、装甲を厚くしたいのですが、余分な装甲は飛行に支障を来しますので効率のよい配置が求められます。明らかに損傷が集中する箇所とそうでない箇所があります。損傷が多かった部位を集中して保護するというのが正解なのでしょうか?

By <a href=”//commons.wikimedia.org/wiki/User:SlvrKy” title=”User:SlvrKy”>Martin Grandjean</a> (vector), <a href=”//commons.wikimedia.org/wiki/User:McGeddon” class=”mw-redirect” title=”User:McGeddon”>McGeddon</a> (picture), Cameron Moll (concept) – <span class=”int-own-work” lang=”en”>Own work</span>, CC BY-SA 4.0, Link
実は、そもそものデータが「帰還できた」機体に限られており、撃墜された機体の情報が欠損していました。改めて結果を見ると、エンジンなど飛行に重要な箇所が不思議と損傷していません。この箇所に攻撃を受けた機体は、そのまま撃墜されたと考えることが自然です。
つまり、生存した(=帰還した)機体のデータというバイアスを理解することで、真の問題を理解し、有効な対策である「生還した機体が損傷を受けていない部位の補強」を提案できます。このケースでは生存バイアスを適切に理解して施策に繋げることができました。
しかし、しばしば生存者バイアスに気づかないまま成果を過剰評価してしまう恐れもあります。例えば、ヘッジファンドの過去実績が高いといっても、既に倒産したものが除かれたことによるバイアスであって、実際に全てを評価すると案外平凡な成績であることが指摘されています。
見落とされたデータ
1986年にスペースシャトル・チャレンジャーは打ち上げ直後に爆発事故を起こし7名の乗組員の命が失われました。この事故は、発進時に固体燃料補助ロケットの密閉用Oリングが破損したことが原因でした。
実は、事故以前から低温でのOリングの安全性に問題点が指摘されていました。加えて、それまでの打ち上げで、複数回の故障が発生していました。以下の図は、故障発生時の個数と気温ですが、両者の間には明確な相関は見られません。当日は氷点下まで気温が下がる見込みと不安要素はありましたが、最終的に打ち上げは決定され、爆発事故につながりました。
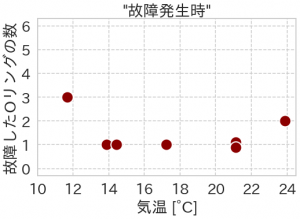
実は、先程のデータには「故障が発生しなかった」データが欠損していました。全てのデータを合わせると以下のようになります。気温と故障との相関は明確で、約18度以下の場合では確実に故障が発生しており、気温が下がるほど個数が増える傾向があります。更に、当日の予想気温はこれまでデータが取られていない非常に低温の環境下でどれほどの影響があるかは未知数です。
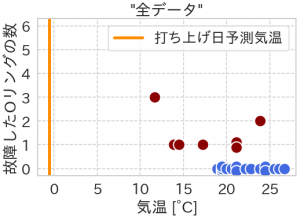
この例では、どのようなデータを観測しているか、そのバイアスに気づかないままに意思決定してしまった結果、悲劇につながってしまいました。問題が発生するとついそのデータばかりに着目してしまいますが、比較対象として正常な場合と比べることが原因追求には役に立つわけです。
機械学習とKPI・目的関数の設計
このように収集されたデータには様々なバイアスが潜みますので、その点に注意してビジネスの課題に望まないといけません。Garbage in, garbage out というように入力・前提が間違っていると、出力結果は無意味なものとなってしまいます。

では、出力である目的(KPI)をどのように設定すればよいでしょうか?
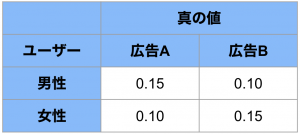
機械学習においてモデルの予測精度は一見わかりやすいKPIですが、それにも落とし穴があります。例えば、ユーザー属性に応じて出した広告のClick Through Ratio (CTR 広告の表示回数に対するクリック数の比率) 予測し、より高精度で予測できるモデルを作りたいとします。ここで、男性・女性に対して広告A, B を出した場合の真のCTRを以下の表の通りと仮定します。
ここで2つの予測モデルを作成しました。それぞれの予測CTRは以下の表の通りです。

2つの予測モデルを比較するとモデル1の予測誤差は MAE = 0.03、一方、モデル2の MAE = 0.0375。したがって、予測精度という観点では、モデル1が採用されます。
これで実際に運用すると、男性に対しては広告B、女性には広告Aが選択されます。結局、実際のCTRは最初の表から期待されるパフォーマンスはCTR = 0.10 です。
もし、モデル2を採用していたらどうなったでしょうか?この場合、モデル1とは逆の広告を提案することなります。そして最終的なCTR = 0.15 となり、モデル1を採用した場合よりも結果は良くなりました。
なぜこのようなことになってしまったのでしょうか?それは「機械学習モデルの精度」をKPIとしてしまい、本来必要なアクションである「意思決定」の観点が欠けていたためです。
モデル1のMAEは、0.03でモデル2のMAEは、0.0375 です、したがってモデル1を採用します。よりもむしろ、モデル1による期待CTRは、0.13、モデルIIでは期待CTRは、0.195 。このように精度の評価だけでは、意思決定の観点では結果的に性能の悪いモデルを投入する恐れがあるわけです。
上記の内容を式で表すと予測モデル![]() の精度として予測誤差
の精度として予測誤差
![]()
これを目的関数として最小化を図るのではなく、意思決定モデル![]() により得られる期待値
により得られる期待値
![]()
この最大化を図るべきでした。
自分自身が関わった過去のプロジェクトでもモデルの予測精度(的なもの?)を基準に設計仕様が決定されていて、結果的にパフォーマンス(売り上げ的なもの)が全く改善されず苦労したことがあります。今、振り返ってみると、精度とパフォーマンスをきちんと区別して施策に望むべきでした。
機械学習をビジネスに活用するためのフレームワーク
さて、「試作デザインのための機械学習入門」では、実践のためのフレームワークとして以下のステップが提唱されています。
(1) KPI設定
施策がうまくいっているのか、その性能評価のためには定量的な指標KPIを適切に設定することが必要です。ただし、単純に測定しやすい量を安易にKPIとするのは要注意です。CTRは判りやすい指標ではありますが、ユーザがクリックしても最終的にCV(conversion)に至らないと広告主の目的が達成できません。サービス・ビジネスの課題や収益構造を理解した上で適切に設定する必要があります。
(2) データ観測構造のモデル化
ネット広告配信でしたら、ユーザーに提示した広告に対するクリックの有無、そしてCVなどのデータが観測されます。その際は、配信先、ユーザーのUI、配信の形式などなど様々なバイアスがあります。また、当然ですが、別の広告を配信した場合の反応は得られません。このような観測できなかったデータを手元のデータからいかに推定するかが、今回紹介するOff-Policy Evaluation (OPE) のポイントとなります。
(3) 解くべき問題の特定
これは機械学習モデルの性能をどのように評価するか言い換えることができます。先のCTRの予測精度とパフォーマンスの例で紹介したように、モデルの予測精度はあくまで中間生産物にすぎません。結果としての意思決定の性能を改善するならば、CTRの最適化がより適切な課題といえます。
(4) 観測データのみを用いて問題を解く方法を考える
さて、(3)で最適化すべき目的関数![]() が決まりました。新しい意思決定モデルで目的関数を最適化したい訳ですが、現実では、サンプリングされた一部のデータしか観測できないため真の性能は評価できません。
が決まりました。新しい意思決定モデルで目的関数を最適化したい訳ですが、現実では、サンプリングされた一部のデータしか観測できないため真の性能は評価できません。
そこで、真の性能を観測データDから近似した推定量![]() を代わりに利用します。
を代わりに利用します。
簡単な例としては、過去の施策と新しいモデルの施策が一致した場合のデータのみで評価する経験性能という推定量があります。しかし、多くの場面でこの経験性能では、十分な真の性能評価ができません。詳細については、次の Off-Policy Evaluation の際に述べます。
(5) 機械学習モデルの学習
先のステップ(4) で導入した近似された目的関数![]() を最適化するようにパラメータを調整します。これは通常の機械学習モデルの学習と同様です。
を最適化するようにパラメータを調整します。これは通常の機械学習モデルの学習と同様です。
(6) 施策の導入
学習が完了し性能評価が終わりましたら、いよいよ施策を導入します。ここで、新たに導入したモデルが将来の学習データを生み出すことを忘れてはいけません。蓄積されるデータを活用するために、運用する機械学習モデルは後々に扱いやすい形で保存しておきましょう。
Off-Policy Evaluation (OPE)
さて、以上のような機械学習プロジェクトのフレームワークの中で限定された観測データから如何に問題を解決していくか、が重要なポイントであるとわかります。
データ観測構造のモデル
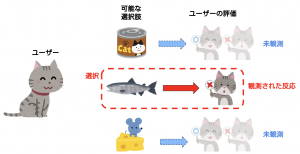
今、複数のアクションaが選択可能とします。選択したアクションに応じた目的変数(潜在目的変数) ![]() のみが結果的に観測されます。他のアクションを選択した場合の目的変数
のみが結果的に観測されます。他のアクションを選択した場合の目的変数![]() は観測不可能で、その選択が良かったのか悪かったのか判別できません。
は観測不可能で、その選択が良かったのか悪かったのか判別できません。
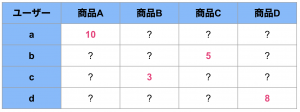
例えば、アイテムの推奨でしたら以下のように、ユーザー毎の過去の推奨とその結果のデータ(売上)が得られます。
さて、すでに蓄積されているデータは特徴量(context) x から古い意思決定 policy (behavior policyと呼ぶこともあります) ![]() により選択された結果、そして、そのアクションにより観測された潜在目的変数
により選択された結果、そして、そのアクションにより観測された潜在目的変数![]() となります。
となります。
ここで我々は新しい意思決定policy ![]() を使った場合の性能
を使った場合の性能
![]()
を評価することが問題となります。
一番簡単な方法はonlineで実際に新しいpolicyで運用してみれば、その性能を評価できますが、リスクもありますし予めofflineで性能を評価したいと思います。
単純なアプローチとしては、新旧の policy が一致したデータ
![]() のみを採用し、異なるアクションを選択した
のみを採用し、異なるアクションを選択した
![]()
の結果を無視した経験性能を利用します。
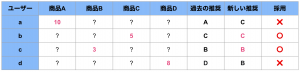
しかし、この方法では旧policyが選択に対してバイアスが掛かってしまいます。その対策として以下の3つの推定方法を紹介します。
Direct Method
まず、Direct Method と言われている方法です。この方法では新しいpolicyでの性能を以下のように推定します。
![]()
ここで、事前に観測されたデータを用いて潜在変数![]() を予測するモデル
を予測するモデル![]() を学習して利用します。
を学習して利用します。
![]()
この方法は予測モデル![]() に精度が依存するためバイアスが大きいのですが、全ての観測データを利用できるため分散は小さいという特徴があります。
に精度が依存するためバイアスが大きいのですが、全ての観測データを利用できるため分散は小さいという特徴があります。
Inverse Probability Weighting (IPW)
次に紹介するのは Inverse Probability Weighting (IPW) です。
これは新policyでの性能の評価に過去の意思決定モデルの確率(![]() )で重み付けて利用します。
)で重み付けて利用します。
![]()
ここで![]() は、
は、![]() のとき1、それ以外は0の値を取ります。これは不偏推定量であり、旧policyのバイアスを除去できるといる利点があります。しかし、旧policyとの乖離が大きい場合分散が大きくなるという問題があります。
のとき1、それ以外は0の値を取ります。これは不偏推定量であり、旧policyのバイアスを除去できるといる利点があります。しかし、旧policyとの乖離が大きい場合分散が大きくなるという問題があります。
Doubly Robust (DR)
DMとIPWを組み合わせた手法がDoubly Robust 推定です。この定義は以下の通りです。
![]()
IPWやDMの弱点を互いに補完することで分散・バイアスにより強い推定量となっています。
モデル学習の流れ
OPEを取り入れたモデル学習の流れは以下の通りとなります。
1. ログデータ収集
既存の意思決定モデル(behavior policy)を利用してデータを収集します。
2. Offline Policy Learning
収集したデータを訓練データ・検証データに分割し、offline policy evaluation の推定量を目的関数として新しいpolicyのparameterを最適化し学習します。
3. Offline Policy Evaluation
(2) で学習したモデルについて、検証データを利用して、その性能をDMやDRなどのOPE推定量から見積もります。
4. 実運用
最後に十分な検証が済んだ新しい意思決定モデルを実装運用します。
Open Bandit Pipelineによる実践
さて、OPEの紹介がすみましたし、実際に library を使って実践してみましょう。
ここでは、Open Bandit Pipeline (https://github.com/st-tech/zr-obp) を紹介します。これは、ZOZOにより開発されている python library です。ZOZOTOWNで収集されたデータセット(Open Bandit Daset)も利用できます。
インストール(!pip install obp)が完了したら、まずは必要なモジュールをimportします。
from sklearn.linear_model import LogisticRegression
from obp.dataset import SyntheticBanditDataset
from obp.policy import IPWLearner, Random
from obp.ope import (
OffPolicyEvaluation,
RegressionModel,
InverseProbabilityWeighting as IPW,
DirectMethod as DM,
DoublyRobust as DR,
)
次にデータセットを準備します。
dataset = SyntheticBanditDataset(n_actions=10, dim_context=1, reward_type='binary', random_state=42) training_data = dataset.obtain_batch_bandit_feedback(n_rounds=10_000) validation_data = dataset.obtain_batch_bandit_feedback(n_rounds=10_000)
ここで、training/validation data は訓練・検証用のデータで、その実態は python の dictionary であって、以下のようになっています。
print(training_data.keys()) >> dict_keys(['n_rounds', 'n_actions', 'context', 'action_context', 'action', 'position', 'reward', 'expected_reward', 'pscore'])
ここでcontext が特徴量、action がそれに対する選択、reward がそれにより得られた効果となります。pscore が旧policyでのactionの選択確率で、IPWやDRによるモデル推定・評価に必要となります。
最初に新しいpolicyで学習します(Offline-Policy Learning)。ここではIPWLearner つまり Inverse Probability Weighting の手法によりデータのバイアスを考慮して、分類器としてLogistic Regression による意思決定モデルを学習します。
eval_policy = IPWLearner(n_actions=dataset.n_actions, base_classifier=LogisticRegression())
eval_policy.fit(
context=training_data['context'],
action=training_data['action'],
reward=training_data['reward'],
pscore=training_data['pscore']
)
action_dist = eval_policy.predict(context=validation_data['context'])
学習・予測した結果(action_dist)が新しいpolicyでの選択結果となります。このpolicyの性能を各種のOPE推定量で評価します。
なお、比較のためにベースラインとしてランダムに選択するモデルも作成しておきます。
random_policy = Random(n_actions=dataset.n_actions)
action_dist_by_random = random_policy.compute_batch_action_dist(
n_rounds=validation_data['n_rounds']
)
DMやDRでは、回帰モデル(RegressionModel)の学習も必用なので、LogisticRegressionによる reward の予測モデルも作成しておきます。
regression_model = RegressionModel(
n_actions=dataset.n_actions,
base_model=LogisticRegression(C=0.01, random_state=42),
)
estimated_rewards_by_reg_model = regression_model.fit_predict(
context=validation_data["context"],
action=validation_data["action"],
reward=validation_data["reward"],
random
)
そして、IPW, DM, DR による OPE は以下で実行と可視化が完了します。
ope = OffPolicyEvaluation(
bandit_feedback=bandit_feedback_test,
ope_estimators=[IPW(), DM(), DR()]
)
ope.visualize_off_policy_estimates(
action_dist=action_dist,
estimated_rewards_by_reg_model=estimated_rewards_by_reg_model,
)
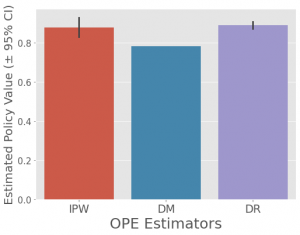
各OPE推定の性能は以下の通りです。解説したようにIPWでは分散(黒線)が大きく、DMでは回帰モデルのバイアスが大きいですが、両者を組み合わせた結果は, バイアスに強く、分散も縮小しています。
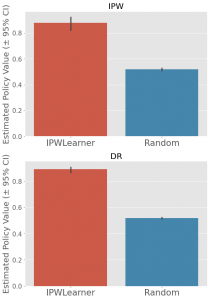
さて、ベースラインであるランダム選択モデルとの比較をしてみます。
ope = OffPolicyEvaluation(
bandit_feedback=validation_data,
ope_estimators=[IPW(), DR()]
)
ope.visualize_off_policy_estimates_of_multiple_policies(
policy_name_list=['IPWLearner', 'Random'],
action_dist_list=[
action_dist, action_dist_by_random,
],
estimated_rewards_by_reg_model=estimated_rewards_by_reg_model,
random_state=42,
)
最後にこれらの性能の推定値と真の性能を評価します。
policy_value_of_ipw_learner = ope.estimate_policy_values(
action_dist=action_dist,
estimated_rewards_by_reg_model=estimated_rewards_by_reg_model,
)
policy_value_of_random = ope.estimate_policy_values(
action_dist=action_dist_by_random,
estimated_rewards_by_reg_model=estimated_rewards_by_reg_model,
)
performance_of_ipw_learner = dataset.calc_ground_truth_policy_value(
expected_reward=validation_data['expected_reward'],
action_dist=action_dist
)
performance_of_random = dataset.calc_ground_truth_policy_value(
expected_reward=validation_data['expected_reward'],
action_dist=action_dist_by_random
)
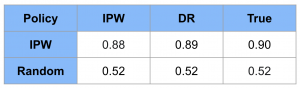
結果は以下の通りとなりました。IPWでの意思決定モデルの方が性能が高いことは明確ですが、さらにその性能推定ではDRの方がより真の性能と近い推定となっています。
まとめ
さて、今回はデータを施策に活かすために観測されたデータに潜むバイアスと、「施策デザインのための機械学習入門」で紹介されたフレームワーク、Offline-Policy Evaluation について解説しました。得られている限られたデータ(バイアス有り)から、有効な施策につなげるためにも、この種のフレームワークを身につけて実践していきたいものです。
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。
一緒に勉強しながら楽しく働きたい方のご応募をお待ちしております。
Reference
- 斉藤優太、安井翔太著「試作デザインのための機械学習入門」 (https://gihyo.jp/book/2021/978-4-297-12224-9)
- 上記のフレームワークの実践についてのわかりやすい解説としては「「試作デザインのための機械学習入門」を完全に理解したサトシくんがポケモン捕獲アルゴリズムを実装する話」(https://tepppei.hatenablog.com/entry/pokemon-ml-design)
- (最近読んで興味深かった)データのバイアスに関する書籍
- デイヴィッド・J・ハンド著「ダークデータ隠れたデータこそが最強の武器になる」
- ジョーダン・エレンバーグ著「データを正しく見るための数学的思考」
- Open Bandit Pipeline, https://github.com/st-tech/zr-obp
- 上記の解説記事「Off-Policy Evaluationの基礎とZOZOTOWN大規模公実験データおよびパッケージ紹介」(https://techblog.zozo.com/entry/openbanditproject)
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD