2021.10.06
異常検知の基本的なモデルを試してみる
こんにちは。次世代システム研究室のS.S.です。
今回はfraud detectionのタスクを解くことを念頭に、さまざまな異常検知のモデルを紹介し、大まかに性能を比較してみたいと思います。
異常検知とそのバリエーション
異常検知とは大多数のデータからはずれたアイテム(outlier)などを識別するタスクで、決済の不正利用検知や機械の故障検知などに応用されます。
このような応用では不正利用率もしくは故障率は低く、positiveのデータをたくさん集めるのは難しい場合が多いです。
outlierを含むデータでトレーニングしてoutlierを検出する場合はoutlier detection、outlierを含まないデータでトレーニングしてoutlierを検出する場合はnovelty detectionと呼んで区別することもあります。
novelty detectionの場合はoutlierが密になっている領域があっても、トレーニングデータではデータがほとんど観測されてない領域であればそのアイテムをoutlierとして検出できるという違いがあります。
異常検知手法の紹介
Local Outlier Factor
LOFは対象のデータ点のlocal densityを近傍のデータ点のlocal densityと比べて、対象のデータ点のlocal densityが低ければはずれ値とします。
local densityというのはk-distanceとreachability-distanceをもとに定義されます。
k-distanceはデータ点の近傍のk番目の点への距離です。
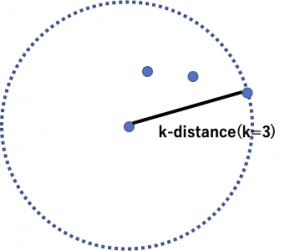
BからAへのreachability distanceはk-distance(B)とA, Bの距離のmaxで定義されます。
![]()
reachability distanceは引数に関して対称でないので、厳密には距離ではないことになります。
Aのlocal reachability density(lrd)は近傍からのreachability distanceの平均をもとに計算します。

最後にはずれ値かどうかの目安であるAのlocal outlier factorは、Aのlocal reachability densityを近傍の点で計算したlrdの平均と比べて極端に低くないかどうかを計算します。
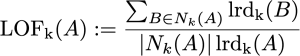
LOFが1より大きければoutlierであり、小さければinlierであることを示しています。
Isolation Forest
Isolation Forestはランダムにfeatureと閾値を選んで分割を繰り返し、木をつくるというところはRandom Forestと同じですが、そのような木をつくったときにはずれ値をそれ以外の値とわけるのは通常の値と比べると簡単であるという性質を利用します。
木を辿って1点だけ分離できるノードまでのパスの長さが短ければ、その程度には分けるのが簡単ということになります。
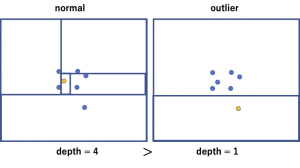
下の図の左は通常のデータ点のケースを示しています。
この点は密度が比較的高い場所に存在するので、ランダムに選んだfeatureと閾値で1点だけに分離するには、何度も分割を繰り返す必要があります。
一方右のほうはoutlierのケースを示しています。
点は密度の低い場所に存在するので、少ない回数の分割で1点だけに分離することができます。
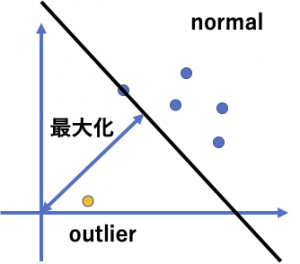
One-class SVM
One-class SVMでは通常のSVMと同様にデータを特徴空間にマップした上で、トレーニングデータの全てのデータ点を原点から分離するような超平面を用意し、その原点からの距離を最大化します。
新たな入力データについては超平面をもとにoutlierかどうかを判断できます。
実験
IEEE-CIS Fraud Detectionのタスクとデータセットを使います。こちらのタスクではEコマースの取引履歴のデータをもとにfraudかどうかを分類するのが目的です。
https://www.kaggle.com/c/ieee-fraud-detection/overview
もともとのデータは約60万件の取引履歴を含んでいますが、アルゴリズムの計算時間の都合があるのでそのうち50000件をランダムにサンプルして以降の実験では用います。
今回は簡単のためにfeatureとしてC1~C14のカラムのみを使うことにします。
不正であればisFraud=1となります。
比較する手法は次の通りです。
モデルにはハイパーパラメータがいくつか存在しますが、今回は大まかな感覚をつかむことが目的なので、チューニングは行わずにデフォルトの値を使います。
- outlier detection : unlabeledデータ
- Local Outlier Factor
- Isolation Forest
- One-class SVM
- novelty detection : negativeデータのみ
- Local Outlier Factor(LOF)
- Isolation Forest
- One-class SVM
- classification : ラベルありデータ
- k-nearest neighbor(k-NN)
- SVM(SVC)
- Random Forest(RF)
分類性能については時間方向のsliding window CVを用いてAUROCを比較します。
今回のデータセットにはTransactionDTに時刻の情報が含まれていますのでこちらを元に分割します。
import pandas as pd
from sklearn.model_selection import TimeSeriesSplit
from sklearn.neighbors import LocalOutlierFactor, KNeighborsClassifier
from sklearn.metrics import roc_auc_score
from sklearn.svm import OneClassSVM, SVC
from sklearn.ensemble import IsolationForest, RandomForestClassifier
df_tr = pd.read_csv("data/ieee-fraud-detection/train_transaction.csv")
df_te = pd.read_csv("data/ieee-fraud-detection/test_transaction.csv")
# 50000件をサンプル
df_tr_smp = df_tr.sample(50000, random_state=0).sort_values(["TransactionDT"])
positive rate確認
まずそれぞれのfoldにどのくらいの割合でisFraud=1が含まれているか確認してみます。
for i_tr, i_te in TimeSeriesSplit(n_splits=5).split(df_tr_smp):
z_tr = df_tr_smp.iloc[i_tr]
z_te = df_tr_smp.iloc[i_te]
print("pos rate(tr, te):", z_tr["isFraud"].mean(), z_te["isFraud"].mean())
pos rate(tr, te): 0.0250749850029994 0.03456138245529821 pos rate(tr, te): 0.029817614590832733 0.03972158886355454 pos rate(tr, te): 0.03311867525298988 0.0358814352574103 pos rate(tr, te): 0.03380932381352373 0.03600144005760231 pos rate(tr, te): 0.03424772601819186 0.030961238449537982
outlier detection
ではここから異常検知の手法を試していきます。
はじめはラベルの情報を使わずに異常検知を行うoutlier detectionです。
for i_tr, i_te in TimeSeriesSplit(n_splits=5).split(df_tr_smp): z_tr = df_tr_smp.iloc[i_tr] z_te = df_tr_smp.iloc[i_te] mdl = LocalOutlierFactor(n_neighbors=20, contamination=z_tr["isFraud"].mean(), novelty=True) mdl.fit(z_tr.filter(regex="^C.+")) print(roc_auc_score(z_te["isFraud"], -mdl.score_samples(z_te.filter(regex="^C.+"))))
0.6982231026862786 0.6726819050524379 0.6230327129765387 0.6397111913357401 0.6355818753449973
for i_tr, i_te in TimeSeriesSplit(n_splits=5).split(df_tr_smp): z_tr = df_tr_smp.iloc[i_tr] z_te = df_tr_smp.iloc[i_te] mdl = OneClassSVM(gamma='auto') mdl.fit(z_tr.filter(regex="^C.+")) print(roc_auc_score(z_te["isFraud"], -mdl.score_samples(z_te.filter(regex="^C.+"))))
0.6219211812029556 0.6337867949930946 0.616162246905501 0.6099363044109715 0.6250317997456021
for i_tr, i_te in TimeSeriesSplit(n_splits=5).split(df_tr_smp): z_tr = df_tr_smp.iloc[i_tr] z_te = df_tr_smp.iloc[i_te] mdl = IsolationForest(contamination=z_tr["isFraud"].mean()) mdl.fit(z_tr.filter(regex="^C.+")) print(roc_auc_score(z_te["isFraud"], -mdl.score_samples(z_te.filter(regex="^C.+"))))
0.681133467992542 0.6816005590747328 0.662104325845924 0.6611629113241213 0.6924415004679964
novelty detection
次はnegativeのデータだけでモデルを作るnovelty detectionを試します。
for i_tr, i_te in TimeSeriesSplit(n_splits=5).split(df_tr_smp): z_tr = df_tr_smp.iloc[i_tr] z_te = df_tr_smp.iloc[i_te] mdl = LocalOutlierFactor(n_neighbors=20, novelty=True) mdl.fit(z_tr.loc[lambda x: x["isFraud"]==0].filter(regex="^C.+")) print(roc_auc_score(z_te["isFraud"], -mdl.score_samples(z_te.filter(regex="^C.+"))))
0.7103275412609629 0.6966028507978745 0.6556705489961976 0.6790713307606125 0.69124967000264
for i_tr, i_te in TimeSeriesSplit(n_splits=5).split(df_tr_smp): z_tr = df_tr_smp.iloc[i_tr] z_te = df_tr_smp.iloc[i_te] mdl = OneClassSVM(gamma='auto') mdl.fit(z_tr.loc[lambda x: x["isFraud"]==0].filter(regex="^C.+")) print(roc_auc_score(z_te["isFraud"], -mdl.score_samples(z_te.filter(regex="^C.+"))))
0.6241857865478903 0.6387725198609713 0.6212414129581386 0.6152755301049837 0.6316351069191446
for i_tr, i_te in TimeSeriesSplit(n_splits=5).split(df_tr_smp): z_tr = df_tr_smp.iloc[i_tr] z_te = df_tr_smp.iloc[i_te] mdl = IsolationForest() mdl.fit(z_tr.loc[lambda x: x["isFraud"]==0].filter(regex="^C.+")) print(roc_auc_score(z_te["isFraud"], -mdl.score_samples(z_te.filter(regex="^C.+"))))
0.6715636005800704 0.709682662415967 0.6792759118229131 0.6597524793559899 0.7026603787169703
classification
次はラベルの情報を使って通常の教師あり学習で分類器をトレーニングします。
for i_tr, i_te in TimeSeriesSplit(n_splits=5).split(df_tr_smp): z_tr = df_tr_smp.iloc[i_tr] z_te = df_tr_smp.iloc[i_te] mdl = KNeighborsClassifier(n_neighbors=20) mdl.fit(z_tr.filter(regex="^C.+"), z_tr["isFraud"]) print(roc_auc_score(z_te["isFraud"], mdl.predict_proba(z_te.filter(regex="^C.+"))[:, -1]))
0.7088247099647813 0.7349507034117604 0.7587816578870902 0.7490549400390059 0.7468778649770801
for i_tr, i_te in TimeSeriesSplit(n_splits=5).split(df_tr_smp): z_tr = df_tr_smp.iloc[i_tr] z_te = df_tr_smp.iloc[i_te] mdl = SVC() mdl.fit(z_tr.filter(regex="^C.+"), z_tr["isFraud"]) print(roc_auc_score(z_te["isFraud"], mdl.decision_function(z_te.filter(regex="^C.+"))))
0.7402503711760238 0.7618014303070757 0.7798657544899061 0.7558243080625753 0.7698377612979097
for i_tr, i_te in TimeSeriesSplit(n_splits=5).split(df_tr_smp): z_tr = df_tr_smp.iloc[i_tr] z_te = df_tr_smp.iloc[i_te] mdl = RandomForestClassifier() mdl.fit(z_tr.filter(regex="^C.+"), z_tr["isFraud"]) print(roc_auc_score(z_te["isFraud"], mdl.predict_proba(z_te.filter(regex="^C.+"))[:, -1]))
0.7391726659070507 0.7794486423711294 0.8008776246104556 0.7875467861737001 0.8069201046391629
結果
5 split平均のAUROCの結果は以下になります。
- outlier detection
- LOF : 0.6538461574791985
- one-class SVM : 0.6213676654516249
- Isolation Forest : 0.6756885529410633
- novelty detection
- LOF : 0.6865843883636575
- one-class SVM : 0.6262220712782257
- Isolation Forest : 0.6845870065783822
- classification
- k-NN : 0.7396979752559436
- SVC : 0.7615159250666981
- RF : 0.7827931647402998
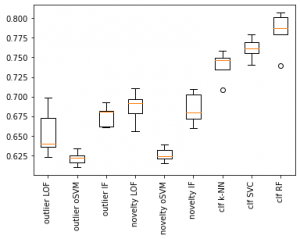
fraud detectionに関しては不正な取引は通常の取引と異なるパターンになることから、ラベルなしもしくはnegativeだけのデータを用いるoutlier detection/novelty detectionである程度分類できていることがわかります。
またpositiveのデータが含まれていないnovelty detectionのほうがoutlier detectionよりもはずれ値を検出できていることがわかります。
さらに比較のためにラベルの情報を用いて分類器をトレーニングした場合の結果をclassificationで示しました。
十分にラベル付きのデータがあれば異常検知の手法でこのラインを超えることは難しいと思います。
まとめ
この記事では不正検知への応用を視野に入れた上で、異常検知の3つの手法(Local Outlier Factor, One-class SVM, Isolation Forest)を紹介しました。
positiveのデータを集めるのが大変な不正検知のタスクでは、異常検知によるアプローチもある程度有効であることがわかりました。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。興味を持って頂ける方がいらっしゃいましたら、ぜひ募集職種一覧からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD