2022.04.08
Strimziによるストリームデータ処理基盤を構築してみた-第1回
こんにちは。次世代システム研究室のT.D.Qです。
近年の急激な技術革新により、証券取引所、銀行、保険などの支払いや金融取引データが多様なシステムから大量のデータが継続的に出力されるようになり、金融企業は大量のデータを貯めておき、定期的に処理をするバッチデータ処理エンジンの見直しを迫られています。大量のデータを低レイテンシ(リアルタイム)に継続的に処理するストリーム処理エンジンを導入することで大量データをリアルタイムで分析・処理し、結果を企業内の既存システムにリアルタイムで連携することもできるため、それらのデータから最大限の価値を引き出すことができます。ストリーム処置プラットフォームの構築に様々な技術を利用する必要があるので、自前で構築することは困難でしたが、近年Kafkaといった分散メッセージングシステム、Cloud Native技術、Kubernetesの発展のおかげで、ストリームデータ処理プラットフォームの構築が以前よりしやすくなってきました。今回の記事でStrimziを使ってGCP上にストリームデータ処理基盤のKafka on Kubernetesクラスターの構築を紹介したいと思います。また、検証内容が長いので、複数記事に分割して投稿する予定です。
今回やりたいこと
- Kafkaのストリーム処理の技術について説明
- ストリーム処理エンジンのアーキテクチャの説明
- なぜKafka on Kubernetesなのか説明
- Strimziの紹介
- StrimziによるKafkaクラスターを構築したい
Kafkaのストリーム処理
Kafkaのおさらい
Apache Kafka は、1日当たり数兆件のイベントに対応可能なコミュニティ/分散型イベントストリーミングプラットフォームです。抽象化された分散型コミットログであるKafkaは、当初はメッセージキューとして捉えられていました。2011年にLinkedInでオープンソースベースで開発されて以降、メッセージキューから本格的なイベントストリーミングプラットフォームへと急速に進化を遂げてきました。
ご存知の方が多いと思いますが、Kafkaの主なコンポネントはtopics, producers, consumers, consumer groups, clusters, brokers, partitions, replicas, leaders, and followersとなっており、各コンポネントの関係は以下の図のように構成されています。

Kafka Streams
Kafka Streams は、入出力データをApache Kafka®クラスターに格納するアプリケーションやマイクロサービスを構築するためのクライアントライブラリです。
Kafka Streams では、Apache Kafka® のプロデューサーAPIとコンシューマーAPIを基盤とし、Kafkaのネイティブ機能を利用してデータの並列性、分散協調、フォールトトレランス、操作の簡易性が提供されるため、アプリケーション開発が簡素化されます。
ちなみに、ストリームデータは常に発生し続け、リアルタイムにデータ処理エンジンに処理される大規模データで、時間とともに記録されるのと変更されないという特徴を持っているため、ストリームデータに対する操作は作成と閲覧だけ考えれば良いです。ストリームとは、Kafka Streamsが提供する最も重要な抽象概念であり、継続的に更新される境界のないデータセットを表します。境界がないとは、”サイズが未知または無制限”であることを意味します。Kafka のトピックと同様に、Kafka Streams APIのストリームは、1つ以上のストリームパーティションで構成されます。ストリームパーティションは、再生可能でフォールトトレラントな、不変のデータレコードの順序付きシーケンスです。データレコード はキーと値のペアから成ります。
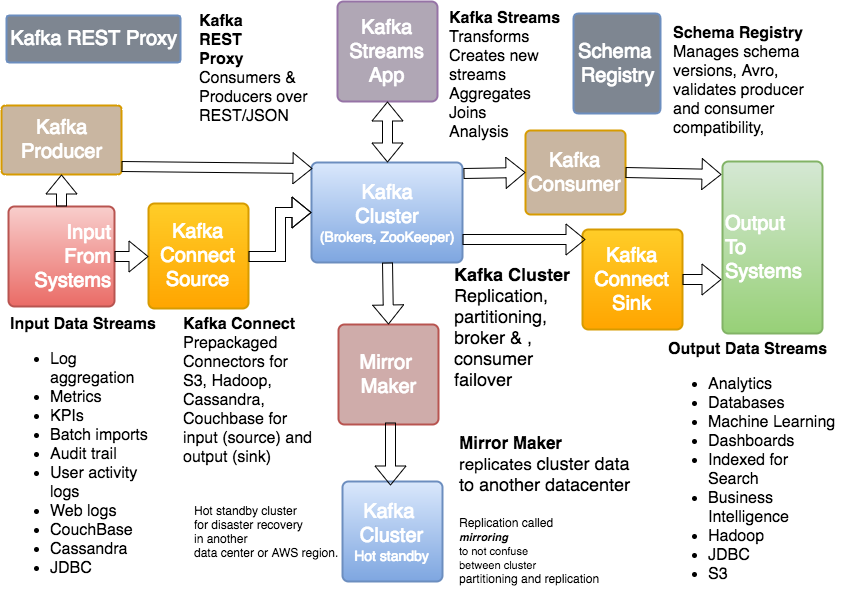
次の図は、Kafka Streams API を使用するアプリケーションの構造を示しています。これは、複数のストリームスレッドを含む Kafka Streams アプリケーションの論理ビューです。各ストリームスレッドには複数のストリームタスクが含まれています。
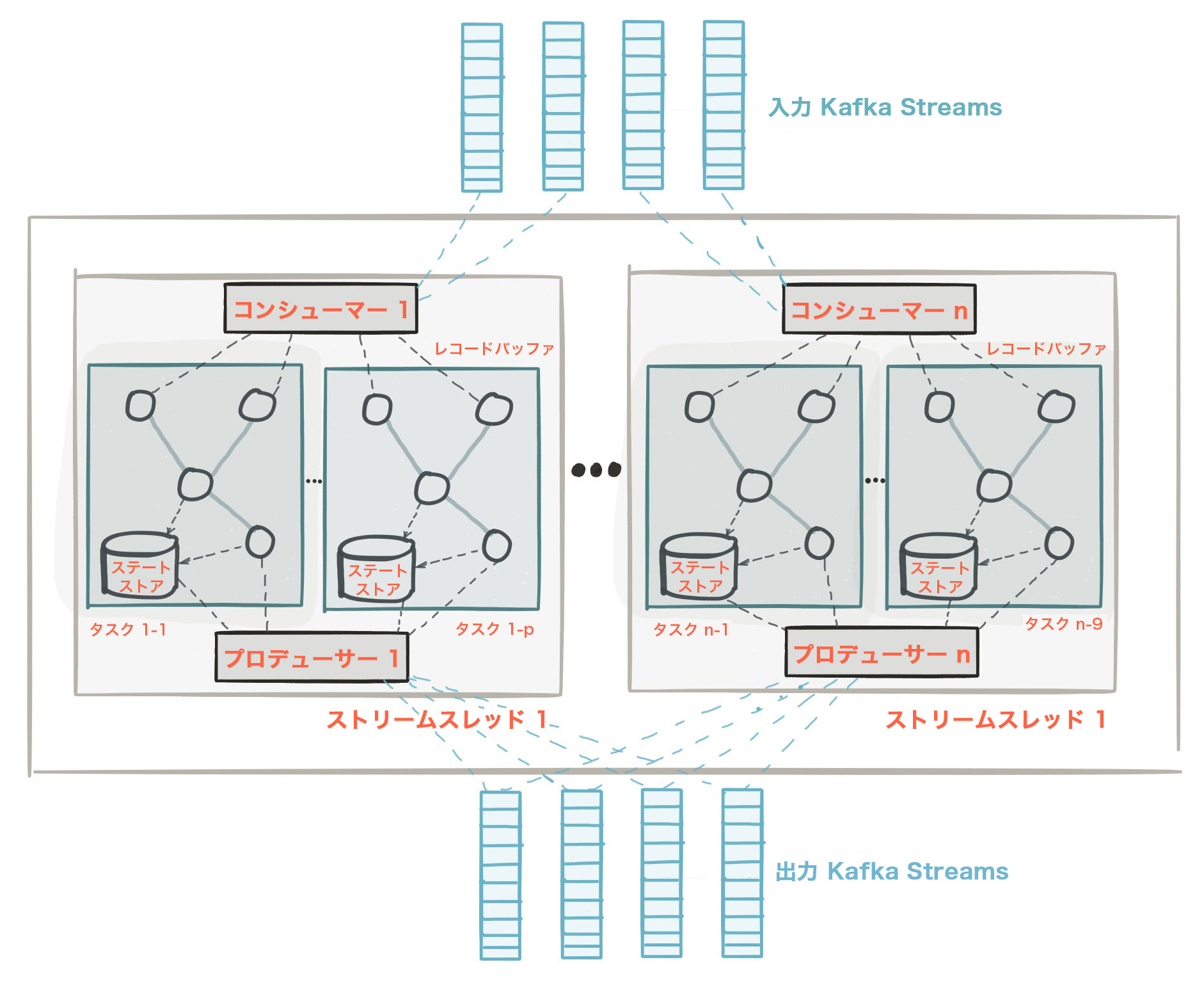
ストリーム処理エンジンのプロセッサートポロジー
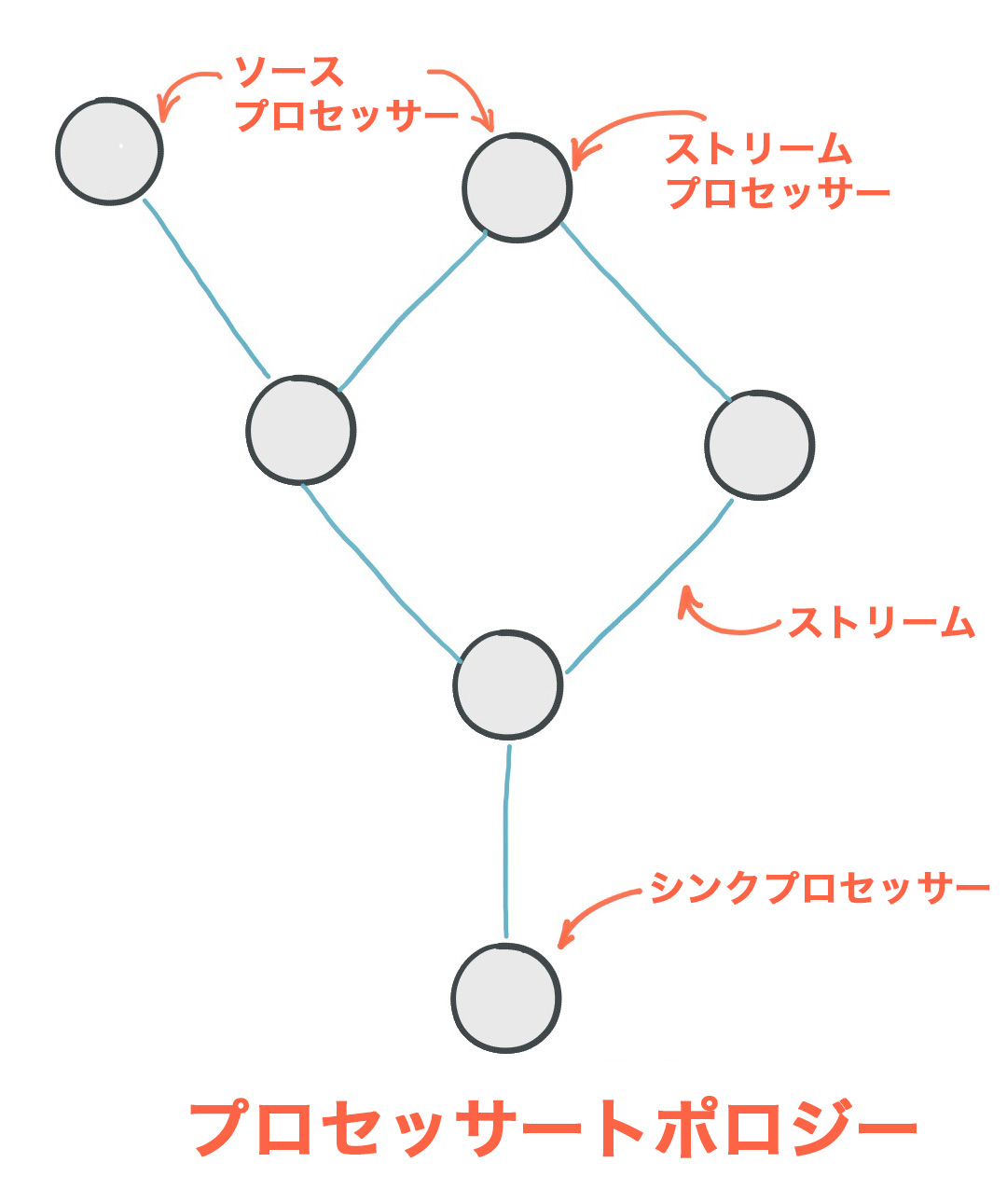
プロセッサートポロジー、または単に トポロジー とは、アプリケーションのストリーム処理の計算ロジックを定義するものです。つまり、入力データがどのように出力データに変換されるかを表します。トポロジーは、ストリーム (エッジ)または共有 ステートストア によって接続された ストリームプロセッサー (ノード)を図示するものです。トポロジーには、次の 2 つの特殊なプロセッサーが含まれています。
ソースプロセッサー: ソースプロセッサーは、アップストリームプロセッサーを持たない特殊な種類の ストリームプロセッサー です。1 つ以上の Kafka トピックからレコードを消費し、ダウンストリームプロセッサーに転送することで、トピックからトポロジーへの入力ストリームを生成します。
シンクプロセッサー: シンクプロセッサーは、ダウンストリームを持たない特殊な種類のストリームプロセッサーです。アップストリーム プロセッサーから受信したレコードを、指定された Kafka トピックに送信します。
以下の図のように、Apache Kafka Streamsのプロセッサートポロジーです。
ストリーム処理エンジンのアーキテクチャ
Lambdaアーキテクチャ
Lambdaアーキテクチャとは膨大なデータ「ビッグデータ」を処理するアプローチです。ハイブリッドアプローチを使用してバッチ処理やストリーム処理メソッドへのアクセスを提供し、任意の関数を計算する問題を解決するために使用されます。ラムダアーキテクチャは3つのレイヤーから構成されています。
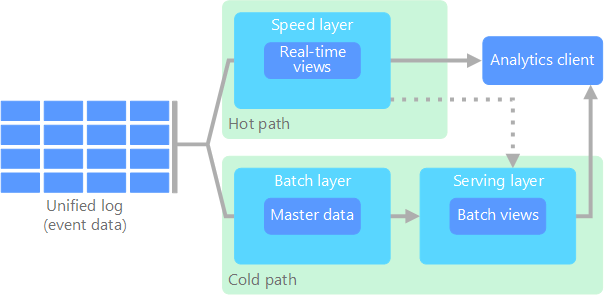
バッチレイヤー
新しいデータは、データシステムへのフィードとして継続的に提供されます。データはバッチレイヤーとスピードレイヤーに同時に供給されます。全てのデータを一度に調べ、最終的にストリームレイヤー内のデータを修正します。
サービングレイヤー
バッチビューの形式のバッチレイヤーからの出力と、ほぼリアルタイムビューの形でスピードレイヤーから出力されるデータは、このサービングレイヤーに転送されます。このレイヤーはバッチビューのインデックスを作成し、アドホックベースで低待機時間でクエリを実行できるようにします。
スピードレイヤー(ストリームレイヤー)
このレイヤーは、バッチレイヤーのレイテンシで処理できずバッチビューでまだ配信されていないデータを処理します。また、リアルタイムビューを作成して、ユーザーにデータの完全なビューを提供するために、最新のデータのみを扱います。
バッチ処理はスループットが非常に高いというメリットを持つものの、レイテンシが非常に遅くなってしまうというデメリットがありました。そのためバッチ処理とストリーム処理を組み合わせることで、このデメリットに対抗しようとしたのがLambda Architectureになります。一方で「バッチ処理とストリーム処理の2つのシステムを維持しないといけない」というデメリットもあります。
Kappaアーキテクチャ
Kappaアーキテクチャは、「そもそもストリーム処理だけで全て計算できるのではないか」という点でLambdaアーキテクチャの代替として提案されました。Lambdaアーキテクチャと基本的な目標は同じですが、ストリーム処理システムを使用して、すべてのデータが単一のパスを経由する、という重要な違いがあります。以下の図のように、Kappaアーキテクチャの基本概念です。

Kappaアーキテクチャは、重複する計算ロジックとアーキテクチャ管理の複雑さを取り除きます。ただし、ユースケースが当てはまる場合を除いて、KappaアーキテクチャはLambdaアーキテクチャの代わりにはならないことに注意することが重要です。
ストリームデータ分析基盤
なぜKafka on Kubernetesなのか
Kafka Streamsは、Kafka イベントのシンプルで強力なストリーム処理を可能にします。分散ストリーミング、リアルタイム処理、高いスケーラビリティといったコアなイベント駆動型機能はすべて、Apache Kafka によって可能になります。
KubernetesはApache Kafkaにとって理想的なプラットフォームです。開発者にはKafkaアプリケーションをホストするスケーラブルなプラットフォームが必要で、その回答がKubernetesです。Googleのクラウドサービスを支えるテクノロジーであるKubernetesは、コンテナ化アプリケーションを管理するオープンソース・システムであり、これを使うことで、コンテナに関連する手動プロセスの多くが不要になります。Apache KafkaをKubernetesで使用すると、Apache Kafkaのデプロイ、構成、管理、使用が最適化されます。
KafkaとKubernetesを組み合わせると、Kafka のすべてのメリットに加えて、Kubernetesの特長であるスケーラビリティ、高可用性、移植性、デプロイの容易性も活用できます。このため、Apache KafkaはKubernetesのコンテナ管理システムに頻繁にデプロイされます。
また、GKEはオープンソースのコンテナオーケストレーションツール「Kubernetes」をGCPがマネージドサービスとして提供するので、GKEを使ってKafkaクラスターを展開することがさらに便利になります。
Strimziとは
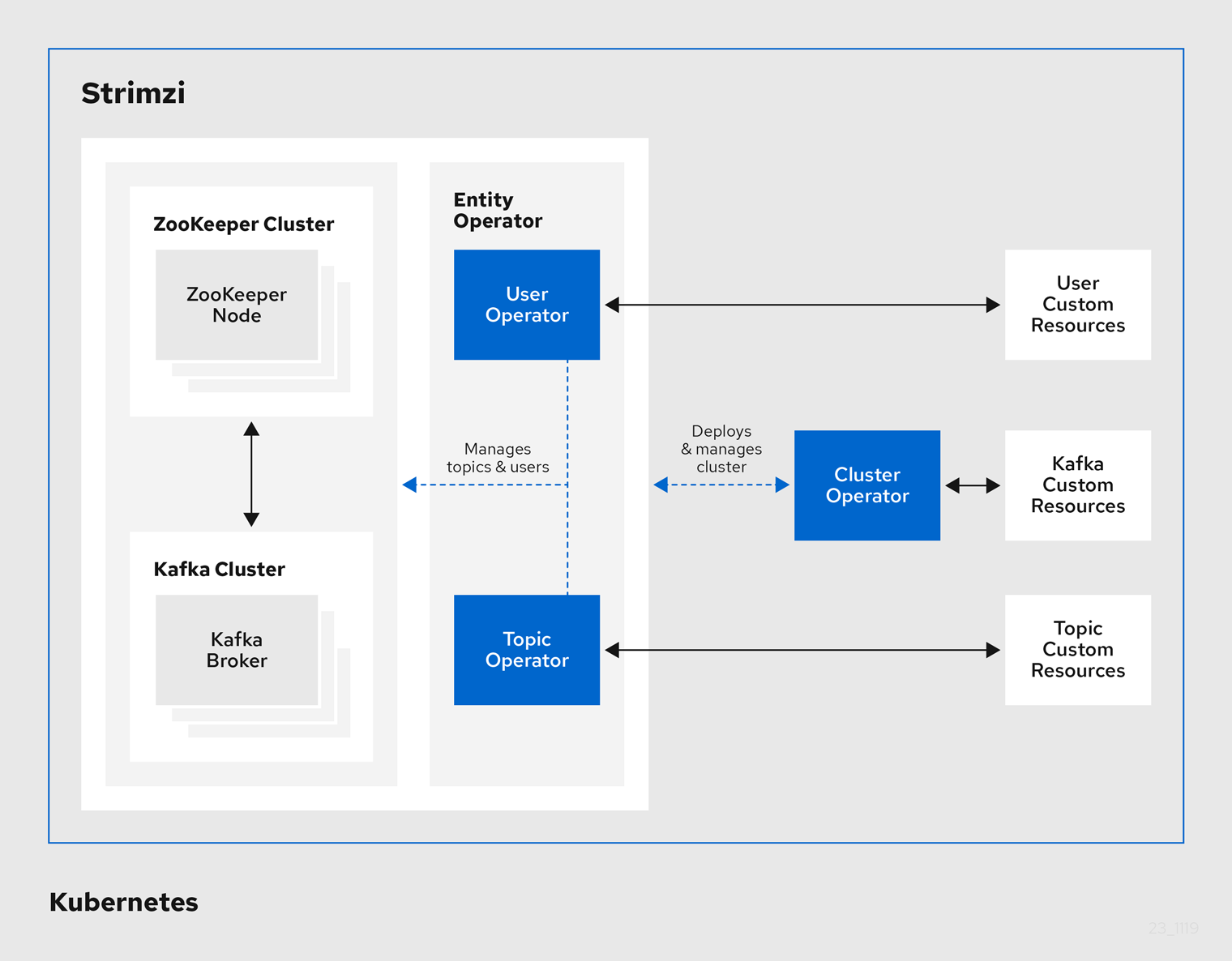
一言言うとStrimziがKubernetesでApache Kafkaを機能させるKubernetes Operatorです。
Kubernetes上にApache Kafkaの手動運用は、多くのコンポーネントの過剰な構成を必要とする複雑な作業です。この複雑さを解決するものとして登場するのが、Strimziです。StrimziはKubernetes オペレーターを使用して、Apache Kafkaの構成をスムーズかつシームレスにデプロイできます。オペレーターは、Kubernetesでアプリケーションをデプロイおよび管理するための最先端の機能で、インフラストラクチャレベルで抽象化し、開発者がインフラストラクチャに関する多くの情報を持たなくてもアプリケーションをデプロイできることから、開発に柔軟性をもたらします。
ストリームデータ処理基盤の構築
前回のブログに構築したデータ解析基盤のKubernetesクラスター上にKafkaクラスターを構築したいと思います。
Namspaceを作成
KafkaのNamespaceで他のサービスと区別するため作成しておきましょう。
tdq@cloudshell:~ (evident-time-336603)$ kubectl get namespaces NAME STATUS AGE default Active 67d jhub Active 57d kube-node-lease Active 67d kube-public Active 67d kube-system Active 67d spark Active 65d spark-operator Active 57d tdq@cloudshell:~ (evident-time-336603)$ kubectl create namespace kafka namespace/kafka created tdq@cloudshell:~ (evident-time-336603)$ kubectl get namespaces NAME STATUS AGE default Active 67d jhub Active 57d kafka Active 5s kube-node-lease Active 67d kube-public Active 67d kube-system Active 67d spark Active 65d spark-operator Active 57d tdq@cloudshell:~ (evident-time-336603)$
Strimziをインストール
次にstrimzi kafka operatorのデプロイしましょう。Namespaceは作成したkafkaを指定します。
tdq@cloudshell:~ (evident-time-336603)$ kubectl create -f 'https://strimzi.io/install/latest?namespace=kafka' -n kafka rolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator-entity-operator-delegation created customresourcedefinition.apiextensions.k8s.io/strimzipodsets.core.strimzi.io created clusterrole.rbac.authorization.k8s.io/strimzi-kafka-client created customresourcedefinition.apiextensions.k8s.io/kafkausers.kafka.strimzi.io created clusterrolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator-kafka-broker-delegation created configmap/strimzi-cluster-operator created customresourcedefinition.apiextensions.k8s.io/kafkas.kafka.strimzi.io created clusterrole.rbac.authorization.k8s.io/strimzi-cluster-operator-namespaced created customresourcedefinition.apiextensions.k8s.io/kafkatopics.kafka.strimzi.io created customresourcedefinition.apiextensions.k8s.io/kafkaconnects.kafka.strimzi.io created customresourcedefinition.apiextensions.k8s.io/kafkabridges.kafka.strimzi.io created customresourcedefinition.apiextensions.k8s.io/kafkaconnectors.kafka.strimzi.io created clusterrole.rbac.authorization.k8s.io/strimzi-entity-operator created clusterrole.rbac.authorization.k8s.io/strimzi-cluster-operator-global created clusterrolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator-kafka-client-delegation created customresourcedefinition.apiextensions.k8s.io/kafkamirrormakers.kafka.strimzi.io created clusterrole.rbac.authorization.k8s.io/strimzi-kafka-broker created customresourcedefinition.apiextensions.k8s.io/kafkamirrormaker2s.kafka.strimzi.io created customresourcedefinition.apiextensions.k8s.io/kafkarebalances.kafka.strimzi.io created serviceaccount/strimzi-cluster-operator created deployment.apps/strimzi-cluster-operator created clusterrolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator created rolebinding.rbac.authorization.k8s.io/strimzi-cluster-operator created tdq@cloudshell:~ (evident-time-336603)$
Kafkaクラスターを作成
KafkaのBrokerが3ノード、Replication係数が3で、Zookeeperの3ノードのクラスターを作りたいので、以下の設定内容でYAMLファイルを作りました。
また、デモのためKafka BrokerノードのStorageが10Giで設定しておきます。
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 3.1.0
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
default.replication.factor: 3
min.insync.replicas: 2
inter.broker.protocol.version: "3.1"
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 10Gi
deleteClaim: false
zookeeper:
replicas: 3
storage:
type: persistent-claim
size: 5Gi
deleteClaim: false
entityOperator:
topicOperator: {}
userOperator: {}
上記の設定でクラスターを作成しましょう。
tdq@cloudshell:~ (evident-time-336603)$ vi kafka/kafka-cluster.yaml tdq@cloudshell:~ (evident-time-336603)$ kubectl apply -f kafka/kafka-cluster.yaml -n kafka kafka.kafka.strimzi.io/my-cluster created tdq@cloudshell:~ (evident-time-336603)$ kubectl wait kafka/my-cluster --for=condition=Ready --timeout=300s -n kafka kafka.kafka.strimzi.io/my-cluster condition met tdq@cloudshell:~ (evident-time-336603)$ kubectl get pods -n kafka NAME READY STATUS RESTARTS AGE my-cluster-entity-operator-6d5ff97f6-8s5rn 3/3 Running 0 47s my-cluster-kafka-0 1/1 Running 0 97s my-cluster-kafka-1 1/1 Running 0 97s my-cluster-kafka-2 1/1 Running 0 97s my-cluster-zookeeper-0 1/1 Running 0 2m46s my-cluster-zookeeper-1 1/1 Running 0 2m46s my-cluster-zookeeper-2 1/1 Running 0 2m46s strimzi-cluster-operator-587cb79468-c96sh 1/1 Running 0 19m tdq@cloudshell:~ (evident-time-336603)$
無事にKafkaクラスターが作成されました。
Kafkaクラスターの動作確認
早速構築したKafkaクラスターの動作確認をしたいと思います。
動作確認するため、まずKafkaプロデューサーをデプロイし、プロデューサーが稼働しているコンソールに任意メッセージを入力します。Enterを押してメッセージを送信します。
tdq@cloudshell:~ (evident-time-336603)$ kubectl -n kafka run kafka-producer -ti --image=quay.io/strimzi/kafka:0.28.0-kafka-3.1.0 --rm=true --restart=Never -- bin/kafka-console-producer.sh --broker-list my-cluster-kafka-bootstrap:9092 --topic my-topic If you don't see a command prompt, try pressing enter. >This >is >test >messages >from kafka producer >hello >
次に、Kafkaコンシューマーをデプロイし、コンシューマーコンソールに受信メッセージが表示されることを確認しましょう。
tdq@cloudshell:~ (evident-time-336603)$ kubectl -n kafka run kafka-consumer -ti --image=quay.io/strimzi/kafka:0.28.0-kafka-3.1.0 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server my-cluster-kafka-bootstrap:9092 --topic my-topic --from-beginning If you don't see a command prompt, try pressing enter. This is test messages from kafka producer hello
無事にメッセージを送受信できることを確認しました。ここで、Kafkaクラスターの準備ができました。
次にクラスターに外部サービスからForexデータをKafkaクラスターに継続的にImportし、Kafka Streamsでストリームデータ処理したいと思いますが、この検証内容は次回の記事にしたいと思います。
まとめ
今回の記事はApache Kafka及びKafka Streamsの特徴、ストリーム処理エンジンのアーキテクチャを説明いたしました。KafkaとKubernetesを組み合わせると、両方の強いところをもっと強くできるので、ストリーム処理基盤の運用に最適なオプションだと思われます。また、ストリーム処理基盤を構築するときにStrimziを使うことでクラスターの構築・運用作業が非常に楽になりました。ストリーム処理の検証は次回継続しますが、今回の記事に紹介した技術を是非体感していただければと思います。
最後に
次世代システム研究室では、ビッグデータ解析プラットホームの設計・開発を行うアーキテクトとデータサイエンティストを募集しています。次世代システム研究室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD