GPT-4Vに色々な書類の読み取りをさせてみる
はじめに
こんにちは、グループ研究開発本部 AI研究開発室のS.Sです。最近ではGPT-4Vのような画像を処理できる生成AIが登場し、さらに複雑なタスクも解けるようになってきました。
そこで今回の記事では、GPT-4Vにビジネス応用を意識した画像処理タスクをいくつか解かせてみることにより、今後の応用可能性について感覚をつかみたいと思います。
記事の構成
具体的には業務で取り扱う可能性のある下記のフォーマットの書類について、GPT-4Vで内容を認識し、いくつかの基本的な質問に正しく答えられるかどうかを確認するという流れで見ていきたいと思います。- 身分証明書
- 免許証
- マイナンバーカード
- 書類
- 領収書
- 通帳
- 請求書
- 議事録
身分証明書の読み取り
本人確認のために免許証やマイナンバーカードを読み取って、顔写真や住所を確認するというようなシチュエーションはありそうなので、まずはこのケースから検証してみたいと思います。もちろん実務での利用に当たっては入力した個人情報が学習に使われないなど、よりビジネスでの利用に適した要件を満たすLLMを使う必要があります。
ChatGPTに免許証のデータを与えて、名前と住所を尋ねるとプライバシー保護とセキュリティの観点から答えることはできないといわれます。(画像引用元: https://www.npa.go.jp/policies/application/license_renewal/index.html )

マイナンバーカードの場合も同様の回答をしてきます。(画像引用元: https://www.city.kiyose.lg.jp/kurashi/todoke_shoumei/mynumber/1005849.html )

このような処理を行わせるには、データが保護されている環境で、個人情報の読み取りができるようにチューニングされたLLMを動かし、フォーム等で入力された情報と照合するといった工夫が必要になるでしょう。
書類の読み取り
領収書
次はコンビニの領収書から精算金額合計を答えさせてみます。以下の例ではプリペイドの預かり金額を誤って抽出してしまっています。
レシートの最後のほうにある金額が合計金額であることが多く、見る部分としてはそんなに間違っていないのですが、フォーマットが微妙に異なるケースなどはひっかかってしまうこともあるようです。(画像引用元: https://www.sanikleen.co.jp/kajiraku/blog/821 )


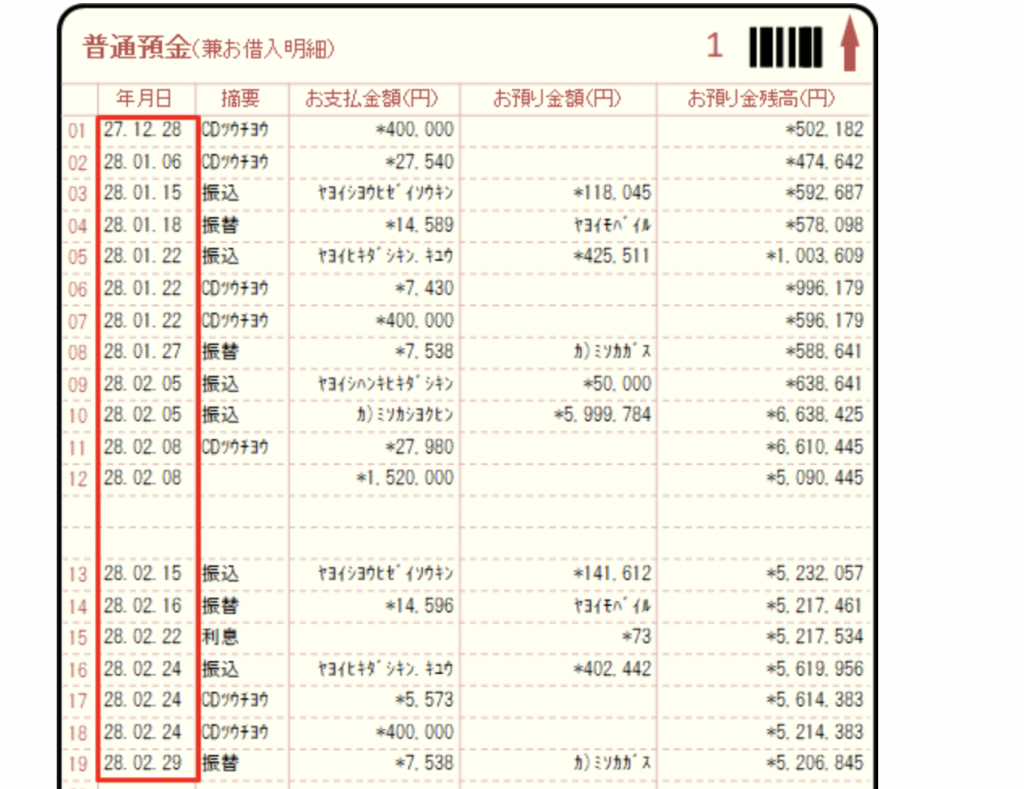
通帳
次は通帳の入出金から直近の振り込みに該当するレコードを抽出してもらい、さらに特定の企業からの振り込みがあるかどうかをチェックしてもらいます。一部間違いもありますが、ATMでの入金と思われるレコードを抽出してくれています。
ミソカショクヒンへの振り込みがあるかどうか(10行目を参照)を尋ねると、該当するものはないという回答になります。
日本語の書類の場合は日本語OCRの精度も影響してくるので、そもそも正確に書類を読み取れていないのか・読み取れた上で質問に答えることができていないのかどちらの原因でうまく答えられないのかは切り分けがしづらくなっています。(画像引用元: https://support.yayoi-kk.co.jp/subcontents.html?page_id=26843&grade_id=AE )



請求書
どの業種に属する会社の請求書なのかを尋ねると、品目を読み取って飲食業であると回答してくれます。(画像引用元: https://www.fastaccounting.jp/blog/20230410/11224 )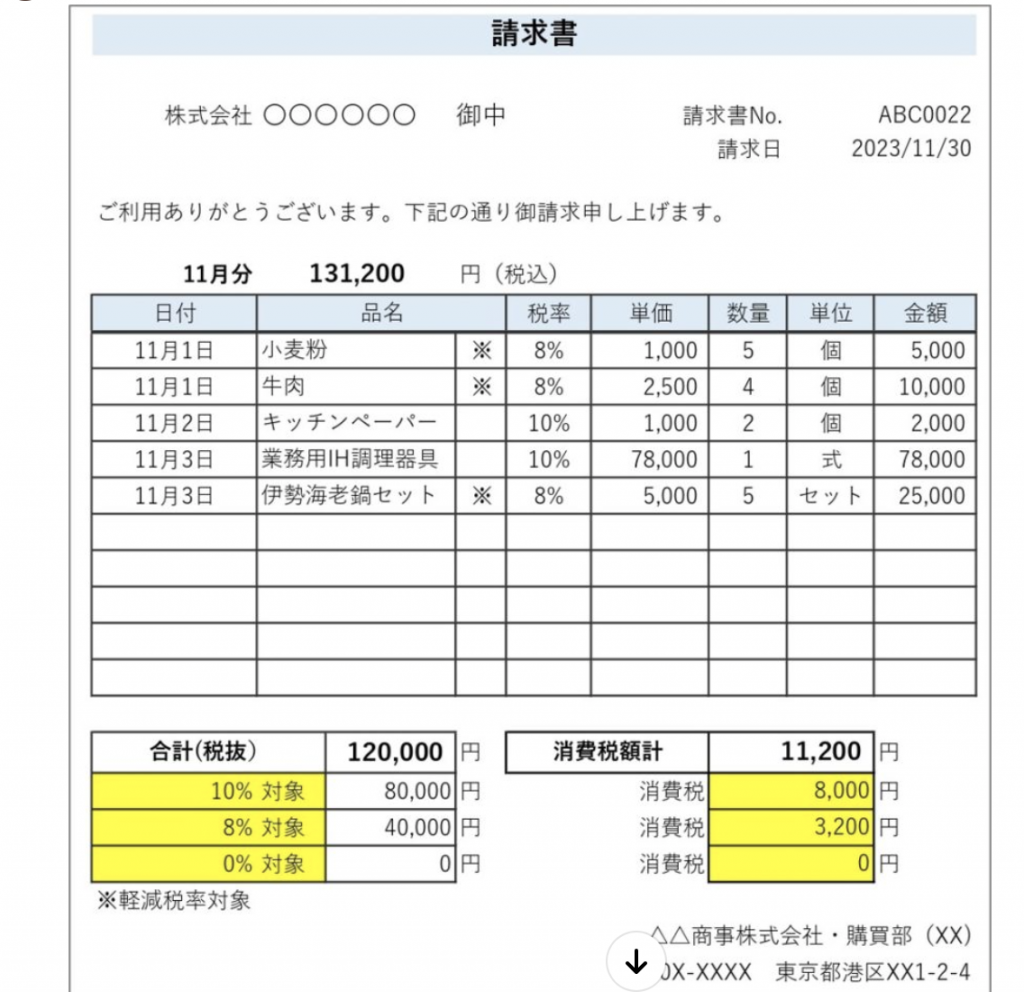

請求書の発行元・請求先の会社を尋ねてみると、会社名がふせられていることは認識します。
〇〇御中だけから請求先の会社であることを読み取るには、書類のフォーマットなどを事前に教えた上で画像をインプットしないといけなさそうです。

議事録
次は会議の議事録から必要な情報を読み取り、質問に答えてもらいます。ここでは日銀の金融政策決定会合の10/30~10/31開催分の議事録を題材にしてみます。
それではまずこの会合で金融緩和政策に変更があったかどうかを尋ねてみます。
金融緩和のスタンスに変更はないという回答がかえってきます。

今度はもう少しフォーカスして、イールドカーブコントロールに関する言及はあったかどうかを尋ねます。
この会合では、長期金利の事実上の上限1%を超えることを容認するという趣旨のことが、遠回しな言い方で書かれているのですが、その微妙なニュアンスを汲み取って回答する必要があるこの質問はやはり難しいようです。
以下議事要旨からの引用: 執行部の説明に対し、大方の委員は、イールドカーブ・コントロー ルの運用のさらなる柔軟化およびその具体的な運用について、執行部 の示した対応案は適当であるとの見解を共有した。何人かの委員は、 長期金利の上限の引き上げは、市場参加者の金利目線を引き上げてし まう可能性があるため適当ではなく、むしろ1%を上限の「目途」と したうえで、上限に近づけば機動的に買入れを増やしていく運用が適 切であると述べた。そのうえで、委員は、1%の上限の目途のもとで、 長期金利が1%を大幅に上回って推移することは想定されないとの 認識を共有した。


各国の金融政策に関する議事要旨を読み込ませて、今後が引き締めが続くかどうかを判断させる試みもいくつかなされており、もっと明確な政策の変更がある場合には、うまく判定してくれるかもしれません。
まとめ
今回の記事では、様々なフォーマットの書類をGPT-4Vに読み込ませてタスクを解かせてみました。この手のものは、書類のフォーマットにうまく適応する追加のロジックを作って大量の書類を処理するのが一般的ですが、フォーマットに関して特別な工夫を凝らすことなく部分的には質問に答えられるようです。
実際の応用にあたっては、データのプライバシーの問題や日本語OCRの精度、各種フォーマットに応じた事前知識のインプットなど、乗り越えなければいけない壁は多いですが、今後の発展次第では日常のビジネス書類を読ませて1次処理を行わせるといった可能性も出てくるかもしれません。