現在の MLOps に関わる課題とその解決法を考える
ご覧頂きありがとうございます。グループ研究開発本部 AI 研究開発室の N.M.と申します。
昨年のブログから前回にわたって、MLOps 周りのブログを執筆し続けていました。ブログの中で一連の処理の流れをパイプラインとして実装していましたが、もちろんパイプラインの整備をすることが MLOps ということではありません。MLOps を適用させるベストプラクティスは、プロダクトの性質や求められるシステム構成、使用すべきなツールなどによって大きく変化し、多くの議論が交わされています。そこで今回は、 改めて MLOps の現状を踏まえた上でそこにある技術的な課題・それを解決できるサービスやツール群について調査してみます。特に、現状のクラウド ML プラットフォームの中でも注目度の高い GCP の Vertex AI 、AWS の SageMaker の二つのマネージドサービスとそれを補完できる OSS との比較などを少し意識しています。最後までお読みいただけると幸いです。
TL;DR
- MLOps は乱立するツールの中で「どのツールを」「どのように使いこなすか」ということを考え、各企業がベストプラクティスを追求し続けるフェーズにあると考えられる。
- Vertex AI, SageMaker はエコシステムが極めて多い。MLOps をマネージドサービスで行うからにはまずデータ加工 → モデル構築 → デプロイの一連の流れを実装したパイプラインを軸に、必要なサービスを取捨選択しながら使っていきたい。
- MLOps の界隈では前提として Kubernetes は強い。Vertex AI, SageMaker などフルマネージドなプラットフォームは使わずとも GKE, EKS に乗せて運用するパターンは一考の余地がある。
目次
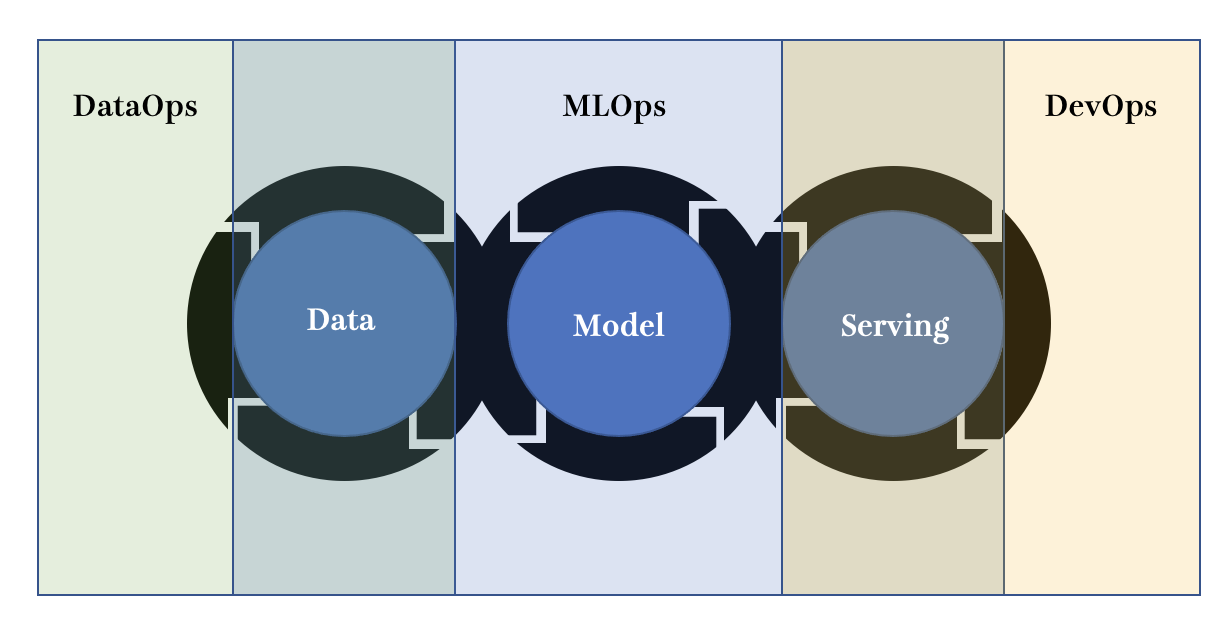
MLOps が解決すべき課題
そもそも MLOps は機械学習プロダクトが抱える課題・負債を解決するための取り組みです。おそらくこのブログをご覧になっておられる方であれば Google の論文の機械学習プロダクトには様々な負債が生じるという図は見たことがある方が多いかと思います。さまざまな課題の種類がありますが、今回は以下の 3 つに分類してみます。- データ観察・収集・加工などのデータ周りの課題
- 機械学習による実験・構築・チューニングなどのモデル周りの課題
- デプロイ・モニタリングなどのサービング周りの課題
ケース A: データに関する課題
“Garbage In, Garbage Out”という言葉もあるとおり、使えないデータをいかに加工し知見を得ようとも難しいものがあります。機械学習プロダクトにとってデータは何よりも重要なものであり、そのデータを扱う上で負債とならないように考慮しなければいけない課題には以下のようなものがあります。予測に使われたデータや予測結果のデータを取得できない
機械学習サービスを開発する際に真っ先に考えなければならないのは予測結果を取得することです。予測モデルをサービングしっぱなしでログを全く取らないということは、機械学習プロダクトを開発する場合にはまず考えられないかと思います。しかしながら、ETL のように データ → モデル → サービング → データ or モデルと上手く繋ぐ仕組みを導入することができなければ機械学習プロダクトに発展はありません。データの前処理に一貫性がない
後述のモデルに関する課題に対しても言えることですが、データサイエンティストが作成した本番実装を前提としていないアドホックな notebook を使い続けることで、ロジックの再利用が面倒になります。車輪の再発明になりうるという問題もありますが、前処理をnotebookで行うことによってキャスト漏れのような問題が発生する可能性が高まります。ケース B: モデルに関する課題
正しく、素早く、綺麗なデータを得ることで ML エンジニアやデータサイエンティストが実験を繰り返し、プロダクトに合致した機械学習モデルを構築します。実験を行いモデルを構築する際に考慮しなければいけない課題には以下のようなものがあります。実験の結果を再現できない
世のデータサイエンティストが一度は悩むであろう課題ですが、自身の行ったモデルの学習といった実験がどのパラメータで行ったものなのかわからなくなったり、逆に結果がわからなくなったりといった問題です。個人でも悩むレベルの課題であればサービスレベルになれば当然生じます。一個人の実行回数はそこまで多くならなければ地道に実験のパラメータを管理しても間に合うかもしれませんが、サービスレベルになると不可能です。モデル開発と運用とのギャップが生じる
モデルの構築を行う人はデータサイエンティストや ML エンジニアが大半なのに対して、構築された予測モデルをデプロイしたりモニタリングしたりといったことを行うのは、必要とされる技術スタックがかなり異なるためどちらかといえば DevOps エンジニアの側面が強い人が行うことは多々あるかと思います。もちろん人力で行うのであれば、どちらの知識スタックも知っている人が行うことが望ましいですが、そのような都合の良い人材が多数いるとも限りません。可能であれば一度ワークフローを作成してシステムに任せてしまいたいです。モデルの「公平性」が崩れる
少し視点が高くなりますが、現在の機械学習においては公平性が重要視されています。機械学習による意思決定が一般的になってきた昨今、データの偏りなどによる影響で差別的な判断などの倫理観のない意思決定が実行される場合があります。サービスのユーザに対して「データの偏りによってたまたまこのような機械学習による意思決定が…」など説明したとしても、理解してもらえるとは限りません。CI のような形で公平性が失われる事態を未然に避けなければいけません。ケース C: サービングに関する課題
ひとりのデータサイエンティストがアドホックにデータ分析をしたいという場合は notebook で完結するかもしれませんが、機械学習プロダクトの場合はそうはいきません。サービスとして利用できるようにモデルをサービングする必要があります。その際に考慮しなければいけない課題には以下のようなものがあります。本番環境にスケールできない
開発時はローカル環境で実装して動けばそれで良いということもあるかもしれませんが、本番環境になるとパフォーマンスやセキュリティといった様々な面で障壁が生まれます。特に PoC 期間でスピード感を意識するあまり本番環境のことを全く考えずに ML 基盤を構築してしまい、一から構築しなおすという可能性も出てきます。もちろん PoC のタイミングから本番環境のことを考えずともプレ本番、及び本番も同じ条件で考えられるようにサービングサービスを選択できれば非常に効率的に本番レベルにスケールできます。急なデータの変化時にモデルを差し替えできない
いわゆるドリフト・スキューと言った開発環境と本番環境のデータの分布の差、あるいは本番環境のデータの分布自体の変化などによって入力されるデータが大幅に変わる可能性があります。そのまま放置しておくと予測精度がどんどん下がっていき、サービスのクオリティに対して影響が大いに発生します。この際にスムーズにサービングできるような仕組みを構築してない場合、モデルの差し替えを行うことは容易ではありません。フィードバックループによる悪影響が発生する可能性がある
フィードバックループは入力されたデータによってモデルを再学習させて修正する働きであり、これは Continuous Training の視点から悪いことではありません。ただし、サービングやモニタリングの体制が整っていなければ、データからモデルを再修正をかけることができる機構を含んでいることが原因となり、上記のようなデータの急激な変化によって精度がより悪化してしまう可能性も考えられます。ケース ?: MLOps を導入するための課題
上記の課題群に関しては、機械学習をプロダクトに導入するための障壁であり、機械学習をプロダクトレベルに昇華できる確率をあげるために MLOps を導入して解消すべき課題になります。ただし、前提としてそもそも MLOps の導入に対しても課題が生じるということも考慮に入れなければいけません。例えば下記のような課題が考えられます。コストがかかる
当然ですがシステムの構成がより大きくならざるを得ないため、その基盤環境分のコストが必要になります。DevOps はある程度ベストプラクティスが固まりつつあり、技術スタックとしても少しづつ一般的になりつつありますが、機械学習プロダクトに対して MLOps を導入する場合、目に見えてランニングコストが発生してしまうため、費用対効果が薄いとビジネスサイドに捉えられてしまうとも考えられます。技術選定に幅がありすぎる
DevOps における CI/CD ツールは長い年月を経て淘汰され、いくつかの代表的なツールに絞られてきています。しかしながら、MLOps を取り巻くツールは CI ツール/CD ツールという括りには収まらず、かつデータの前処理やデプロイなどのそれぞれのカテゴリごとに数多くのツールが存在します。MLOps は未だ過渡期ということもあり、どのツールを使うのかという点は決めるのが難しいです。MLOps を導入するための課題に関しては、技術的な負債だけでは解消できません。効果的・効率的な MLOps のノウハウであったり、コストパフォーマンスの高い技術選定であったり、一つ視座をあげて考える必要が出てきます。この「どのツールがベストなのか」という議論はまだまだ答えは出なさそうです(大前提サービスの種類によっても異なるとは思いますが…)
MLOps にまつわるツール別課題解決の一例
機械学習プロダクトには上記のような課題をはじめとして上手くサイクルを回すためには様々な障壁があります。しかし、上記のような多岐に渡る技術・知識を活用して機械学習を中心としたサービス基盤を構築するためには、インフラ・ネットワークからデータサイエンスまで幅広い技術スタックを持った極めて優秀なエンジニア(あるいはチーム)でもいない限り 0 から作るのは困難を極めることは想像に難くありません。機械学習を用いない一般的なウェブサービスにおいてもオンプレミスではなくクラウドネイティブで柔軟なスケーリングや運用管理を実現する流れはありますが、ご存知の通り MLOps にもその流れがあります。このセクションでは 上記に挙げた課題 に対して、Vertex AI, SageMaker であればどのようなサービスが利用できるのか、またその機能を補完できる OSS にはどのようなものがあるかを整理してきます。課題 1: データの前処理に一貫性がない => 前処理パイプラインの構築
まずはデータ面の課題から、データ加工のパイプライン構築の方法をまとめていきます。Vertex AI の場合
Vertex AI の場合は Vertex AI Pipeline で上記のデータ加工のパイプラインを実行することができます。こちらに関しては前回・及び前々回のブログでも紹介しているように kubeflow pipelines をベースに構築するか、Tensorflow Extended をベースに構築するかを選択して実装していきます。また、前述のブログでも述べている Google Cloud Pipeline Component には Dataflow(マネージド Apache BEAM)を呼び出すコンポーネントも存在します。使い方によっては嵌まる GCPC ですが、GCP 上のサービスに閉じて正しく使うことを意識すれば一度書いたパイプラインの管理は非常に楽になります。SageMaker の場合
SageMaker にも Pipeline は当然存在します。Vertex AI のように kubeflow pipelines, tensorflow extended のように OSS の様式をそのままに使う Vertex AI Pipeline とは対照的に、独自の API を用意している部分は AWS らしさがあります。また、SageMaker には SageMaker Data Wrangler というサービスがあります。Data Wrangler を使うと GUI 上でクレンジングしたデータを可視化できるだけでなく、そのままシームレスに SageMaker Pipelines で実行できる形にエクスポートできるようです。さらに、Data Wrangler でクレンジングしたデータを SageMaker Feature Store に格納して再利用できるようにするなど、SageMaker のエコシステム内での連携を考えられた作りになっています。
OSS の場合
パイプライン構築のライブラリは上記のようなデータの前処理やモデルの訓練以外にも処理の依存関係を明確化させるべき箇所であれば MLOps 以外でも当然使用されます。有名なものであれば Airflow や Kedro といったものや、Vertex AI の裏側で回っている kubeflow pipelines, tensorflow extended も OSS ではありますが、今回は Prefect を少し紹介します。Prefect は 処理の単位である task と それらをつなげた flow によって ワークフローを構築します。下記のような Python のコードの記述で DAG を表現可能です。
from prefect import task, Flow
@task
def say_hello():
print("Hello, World!")
with Flow("My First Flow") as flow:
say_hello()
flow.run() # "Hello, world!"
いくつかの大きな利点として、以下のようなものが挙げられます。- Airflow と比較してローカルデバッグがしやすい
- Prefect Cloud という本番環境向けのクラウド環境がある(ハイプリッドモデルと呼ばれセキュリティ対策もできる)
課題 2: 実験の結果を再現できない => 実験管理
次にモデル面の課題から、実験管理の方法をまとめていきます。Vertex AI の場合
Vertex AI Training を介して AutoML あるいはカスタムトレーニングを使用すれば、トレーニングによって生成されたモデルは Vertex AI Model Registry に登録されて一元でアウトプットすることが可能です。また、一つのモデルに対して、ML metadata として以下のようなアーティファクトを取得することもできます。- モデルの作成に使用されたデータ
- モデルのトレーニング中に使用されたハイパーパラメータ
- モデルのトレーニングに使用されたコード
- トレーニングと評価プロセスで記録されたメタデータ(モデルの精度など)
- このモデルから派生したアーティファクト(バッチ予測の結果など)
SageMaker の場合
SageMaker の場合は、Amazon SageMaker Experiments という実験管理用のサービスが明示的に存在します。Vertex AI のようにアーティファクトをクエリで取得しなくても、SageMaker の Console 上の UI で可視化してくれます。OSS の場合
実験管理を OSS で実現しようとすると必ず候補に上がってくるのが MLflow です。MLflow は以下の 4 つのコンポーネントで構成される実験管理に特化したライブラリです。- MLflow Tracking: データ・コード・パラメータを追跡して可視化
- MLflow Projects: 使用したコードをパッケージ化
- MLflow Models: デプロイしやすいようにモデルをパッケージ化
- MLflow Model Registry: 上記モデルのストアを提供してバージョン管理
課題 3: 急なデータの変化時にモデルを差し替えできない=> サービングプラットフォーム
最後にサービング面の課題から、サービングプラットフォームをまとめていきます。Vertex AI の場合
まさに前回のブログにて検証してみた内容になりますが、GCP の Console(GUI)上からはもちろん、Vertex AI Pipeline からもトラフィックをコントロールしながら一つのエンドポイントに対して複数のモデルをデプロイすることが可能になります。これを使いつつ上手くモニタリングすることで A/B テスト等にも応用できるかもしれません。SageMaker の場合
上記の Vertex AI と同様にマルチモデルエンドポイントへのデプロイ機能によって同様のことを実装できます。このブログ記事のように A/B テストのソリューション案もあり、問題なく稼働できそうです。OSS の場合
サービングプラットフォームにも KServe, Seldon Core といった OSS は存在します。しかしながら基本的には Kubernetes 上で動かすことを前提としたサービングプラットフォームが多いです。GCPのGKE, AWSのEKSなど、マネージドKubernetes上で動かすことを考えれば若干ハードルは下がりますが、依然として導入のハードルは高く感じます。そんな中、bentoML は Yatai と呼ばれる kubernetes 上で動かすライブラリもサポートしつつ、 Docker image をエクスポートすることもできるため、小規模の間はエクスポートしたDocker imageを使って、規模が大きくなってスケールする必要が出てきたらYataiに乗り換えるということもできるかと思います。まとめ
今回のブログでは現状の MLOps にまつわる課題やそれを解決するプラクティスやツールについて整理してみました。なお、本ブログは MLOps と全く関わりのない業務をしている人間が書いたものですので、情報に誤りがある可能性があるかもしれません.このブログの内容によって生じた損害に対しては一切の責任を負いかねますことをご承知おきください。ML プロダクトの抱える課題は実運用をしていくと上記以上のものが発生する可能性は十分にあります。パイプラインを整備することで確実に回避できるような課題もあれば、公平性のようにより緻密にロジックを確認する必要のある課題まであり、さらに改善の余地はあるように感じます。また、プロダクトに対して機械学習を適用させることと同じように、プロダクトに対して MLOps を適用させること自体に対するハードルも確かに存在します。マネージドや OSS 関わらず様々なツール群があるなかで、どのような基準でツールを選べば良いのかという観点でさらに MLOps と向き合ってみたいと思いました。
今回のブログのために改めて調べていましたが、マネージドMLプラットフォームであるのVertex AI, SageMakerのエコシステムは極めて多く、かつドキュメントが綺麗にまとまっていないため、マイナーなサービスは導入のハードルが高いと感じました。基本的には両者ともPipelineを軸にデプロイ周りはマネージドに助けてもらうという構成が現状のイメージになります。OSSのサービングについては何故かKubernetes前提のものが多く存在しました。MLOps界隈でデファクトスタンダードになっている雰囲気があり、今後MLOpsを勉強する上で欠かせない技術になっていくかもしれません(Vertex AI, SageMakerのようなマネージドクラウドMLプラットフォームが主流になるのとどちらが早いかという話ですが…)。
今回は課題の列挙と極めて簡単な解決策の整理に留まりますが、今後はどのようなシステム構成・ツールを選定すればより手軽にかつ効果的に MLOps を導入することができるのかについても考えていきたいです。最後までご覧いただきありがとうございました。
最後に
グループ研究開発本部 AI 研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務など AI 研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。参考
- Hidden Technical Debt in Machine Learning Systems
- Rules of Machine Learning: Best Practices for ML Engineering
- Practitioners guide to MLOps: A framework for continuous delivery and automation of machine learning.
- MLOps: Continuous Delivery for Machine Learning on AWS
- EthicalML/awesome-production-machine-learning