2018.01.10
深層学習を利用した自動プログラミング技術/ニューラルチューリングマシン
イントロダクション
みなさまお疲れ様です、次世代システム研究室のY.Tです。
Pythonを駆使して金融ビッグデータと格闘する日々をすごしています。
最近はめっきり気温が下がって、さすがに冬らしくなってきましたが、皆様はいかがお過ごしですか?
私の方ですが年末は、帰宅後に正月飾りのデプロイや、もち米を炊いてお餅のビルドに忙しく取り組んでいました。
特にお餅は、もち米を炊くときの水加減がうまく行ったみたいでして、正月中予定のクオリティチェックやクロスレビューが楽しみです。
(追記:2018/01/09) お餅おいしかったです。ホームベーカリーを使っても、おいしいお餅が作れることを確認できました。
さて、今回のブログエントリーのテーマは、なんと「AIによる自動プログラミング」です。
昨今はどこのメディアでも、AIが人間の仕事をどんどん出来るようになると盛んに記事が掲載されています。
コンピュータが人の代わりに働く時代がすぐそこに来ていると、夢と希望と不安と絶望の絶妙なハイブリッド感を禁じえません。
そんな時代の風が吹く中、「さすがにIT系の仕事は大丈夫だろう」と安堵している方は少なくないと思いますが、なんと、その専門のど真ん中、プログラミングをAIが自動化してしまうというテクノロジーがあるのをご存知でしょうか?
今回は、深層学習の技術を応用した「ニューラルチューリングマシン」と呼ばれる、プログラミングの自動化テクノロジーの論文とサンプルコードをご紹介したいと思います。
ニューラルチューリングマシンとは
チューリングマシンとは、著名なイギリスの数学者アラン・チューリングが提唱した計算機を数学的に表現するためのコンセプトです。
ずばり言ってしまうと、私たちが普段使っているコンピュータは、チューリングマシンを実現化したものの一つです。
半導体ではなく、物理的な機械仕掛けの実装も立派なチューリングマシンです。
ニューラルチューリングマシンは、ニューラルネットワークを利用して、このチューリングマシンを実装したものです。
コンピュータを使って、コンピュータの振る舞いを実装するという一見するとリソースの無駄と見えるかもしれませんが、このニューラルチューリングマシンがすごいのは、入力データとそれに対して望まれる出力結果を与えることで、プログラミングというプロセスをスキップして、機能を実装できてしまうところにあります。
オンラインドキュメントや書籍を首っ引きで参照しながらコーディングしなくても、「こんなデータを入れたら、こーんな感じで結果を返してね」とデータを与えるだけで仕様を実装できてしまうわけです。
ニューラルチューリングマシンの実装方法にもいくつかありますが、今回はGoogle Deep Mind社(あのアルファ碁を作った会社)が発表した論文のものを紹介します。
Neural Turing Machines/Google DeepMind, London, UK Alex Graves,Greg Wayne,Ivo Danihelka
https://arxiv.org/pdf/1410.5401.pdf
ニューラルチューリングマシンの特徴
ニューラルチューリングマシンは、ニューラルネットワークでコンピュータもどきを作ったものです。
ニューラルネットワークで出来ているということは、微分可能であり(=differentiable)、勾配降下法の各種アルゴリズムを使って振る舞いを最適化することができます。
つまり、誤差伝播法(バックプロパゲーション)で、望む振る舞いを学習させることができるわけです。
我々が使っているコンピュータは、半導体回路などハードウェアの設計図を人間が書き上げ、それに基づいて工場で製造されて出来上がります。
そして、プログラムのコードを記述し、ソフトウェアを実装して初めて、コンピュータとしての役割を果たします。
ところがニューラルチューリングマシンは、ハードウェアの設計図もプログラミングも不要で、振る舞いを定義する入出力のデータを流し込むだけで出来上がります。
ここで、機械学習についてご存知の方ならば、現在の機械学習で同じことができるのではないか?と感じられたことでしょう。
ニューラルチューリングマシンと、現在普及している機械学習とは何が違うのでしょうか?
それは、振る舞いの汎用性です。
学習プロセスで経験したことがない大きなデータ、長いパターンに対して、現在普及している機械学習では対応できません。
著しく性能が落ちてしまうのです。
学習したパターンに類似したものには対処できますが、そもそもデータのサイズが違う、長さが違うといった構造的な変化に対しては無力なのです。
(それは、LSTMを筆頭とする再帰的ニューラルネットワークも同様です)
しかしニューラルチューリングマシンは、入力されるデータの構造的な変化に対して頑健な性能を発揮します。
つまり、学習したときに経験したときより、サイズが大きいデータ、より長いパターンがやってきても、性能を維持する力が、再帰的ニューラルネットワークを含む従来の機械学習よりずっと強いのです。
ニューラルチューリングマシーンは、入力のパターンを覚えているのではなく、入力に対する「振る舞い方」や「操作手順・ロジック」を学習しているからです。それはまさに自動プログラミングと言っても差し支えないでしょう。
やり方を学んでいれば、今までより大きいデータや長いパターンが来ても、することは同じなので対処できるというわけです。
基本的な仕組み
ニューラルチューリングマシンは、コントローラーと呼ばれる要素が入出力のインターフェースとなり、その裏側で外部メモリ(External Memory)という要素にアクセスをする構造になっています。
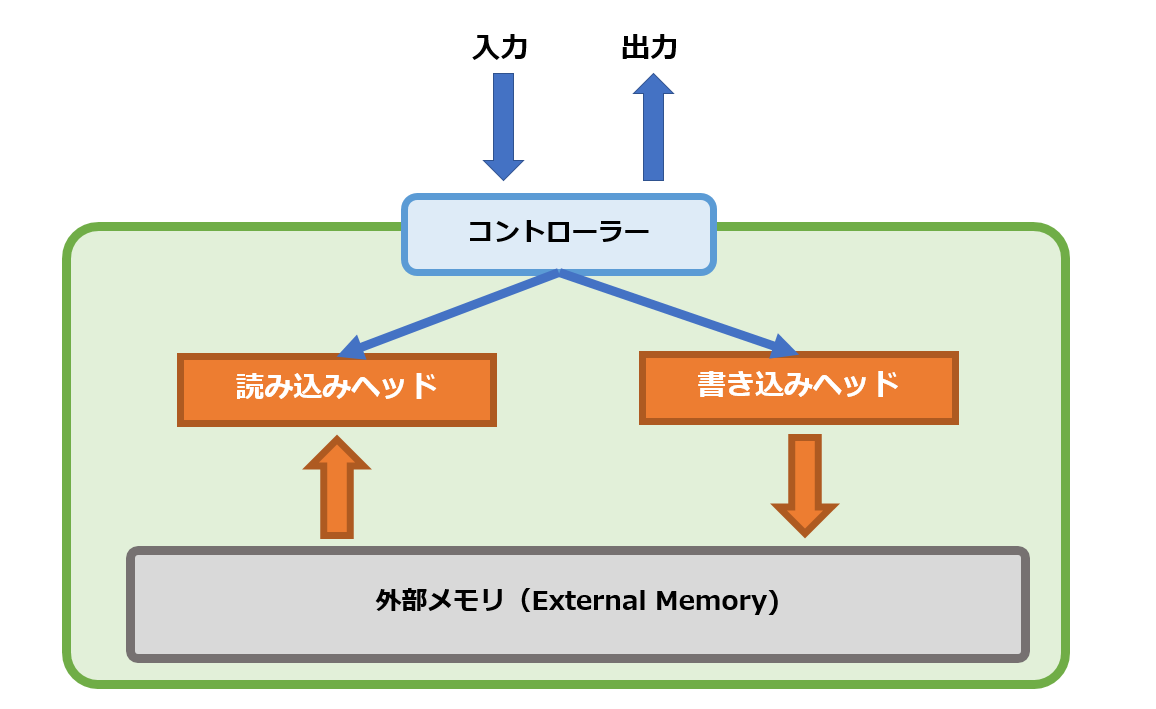
この構造は、人間の認知メカニズムの「短期記憶(ワーキングメモリ)」にヒントを得て設計されています。
外部メモリが短期記憶に相当しています。
ニューラルチューリングマシンは、コントローラーが外部から入力を受け取ると、書き込みヘッドを操作し、外部メモリに記憶を書き込みます。
コントローラーは続いて読み込みヘッドを操作し、外部メモリから内容を読み込み、出力として返します。
とてもシンプルで原始的ですが、まさにCPUとRAMからなるコンピュータです。
ニューラルネットワークで、CPUとRAMの機構を模倣しようというわけです。
それでは各コンポーネントの役割について見ていきましょう。
コントローラー
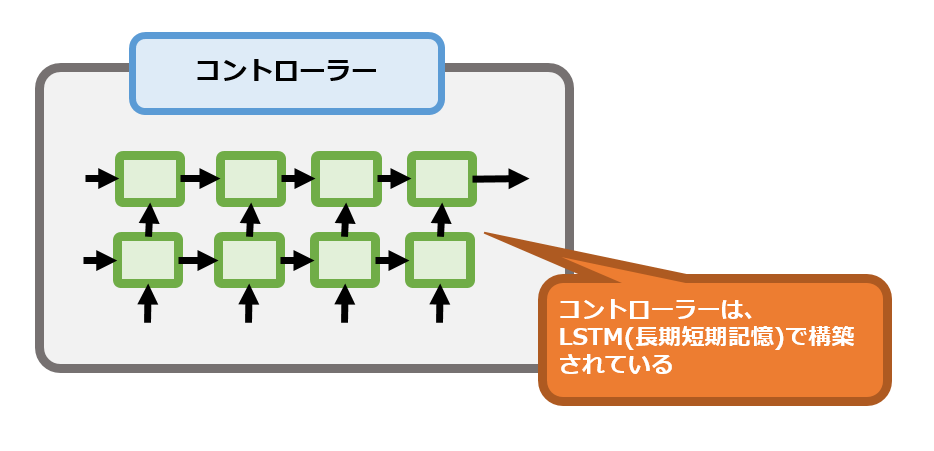
コントローラーは、LSTMを用いて構築されます。
入力を受け取ると、書き込みヘッドを介して外部メモリに記憶します。
そして、読み込みヘッドを経由して外部メモリを参照し、出力すべき値を取得します。
読み込みヘッド
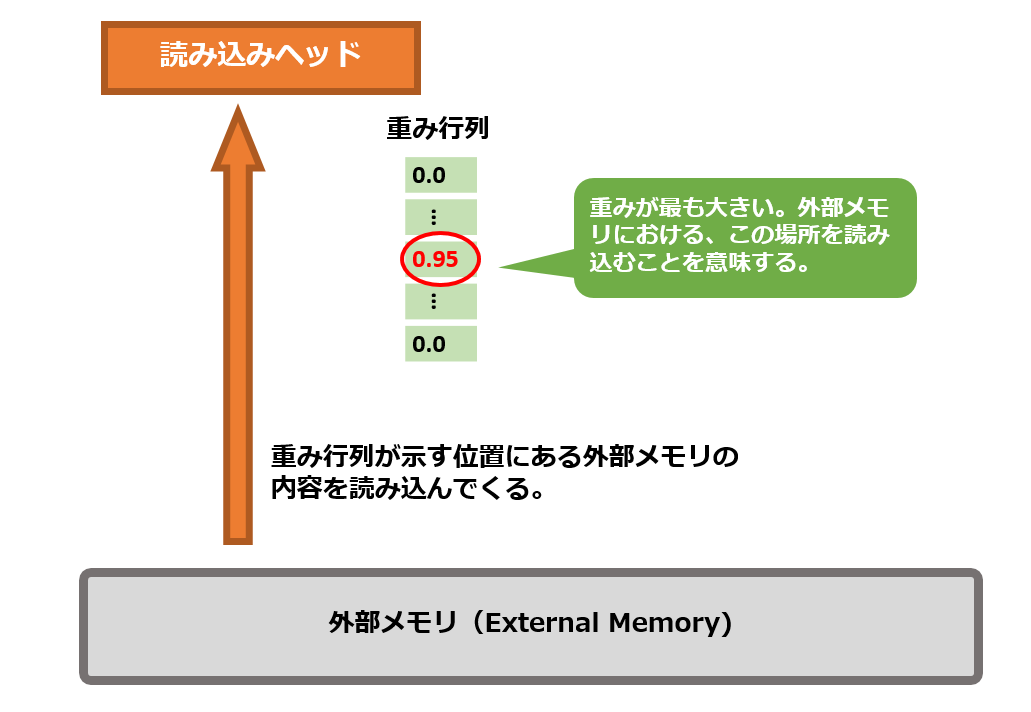
外部メモリを参照して、読み込んだ値を取得してコントローラーに返します。
読み込む位置は、重み行列という形で求めます。
重み行列を使い、狙った位置の外部メモリの内容を読み込みたい場合、該当位置の要素だけ1.0に近い数字となり、それ以外の要素は0になります。
他の使い方としては、3つの位置に 0.3ずつ重みを配置して、ぼやけた位置指定をすることも可能です。
アクセスする位置を表す重み行列の計算方法を、読み込みヘッドは学習します。
書き込みヘッド
コントローラーから入力の値を受け取り、外部メモリに値を記録します。
書き込み位置を決めるのは、読み込みヘッドと同じく重み行列です。
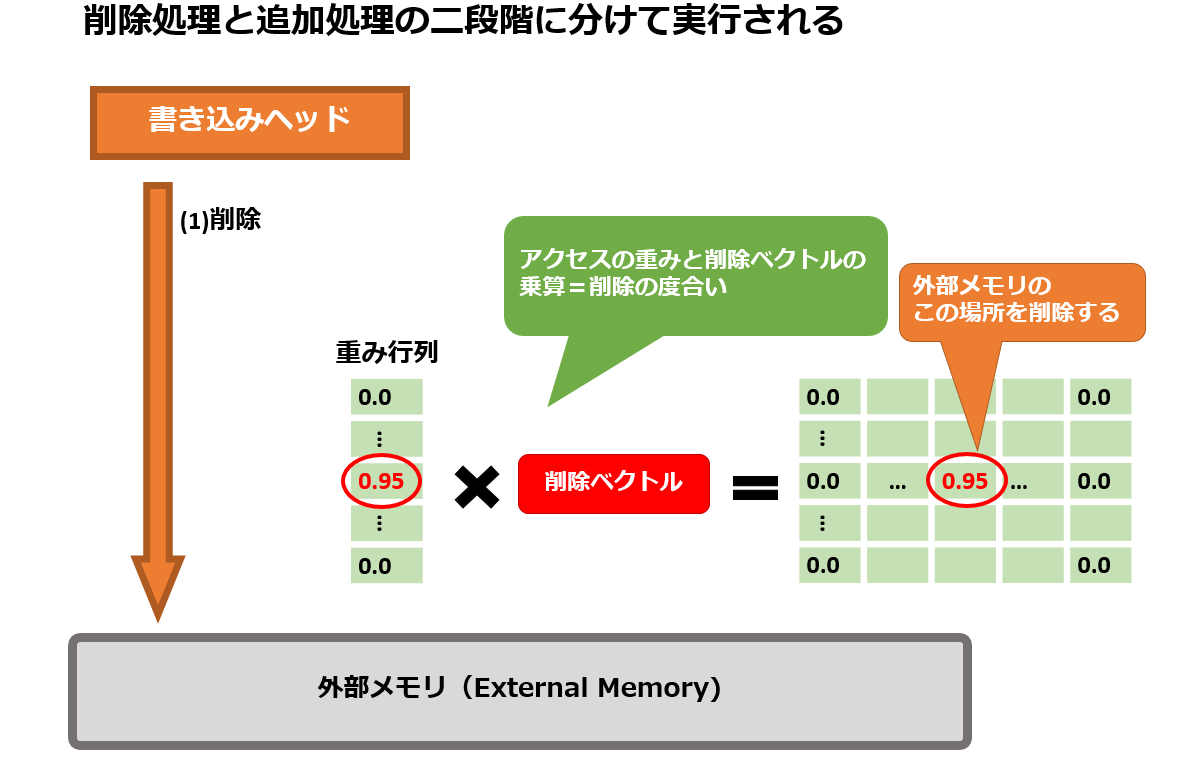
読み込み処理は、1回の外部メモリへのアクセスで完了していたのに対し、書き込み処理は、削除と追加の二回のアクセスに分けて実行されます。
重み行列に加え、削除ベクトルと追加ベクトルの二つのベクトルを計算して、外部メモリの更新処理に使います。
削除処理ですが、重み行列の要素の値と削除ベクトルの要素の値の乗算の結果が、削除の度合いとなります。
具体的に申しますと、重み行列の要素と削除ベクトルの要素が共に1.0に近い値の場合、外部メモリの該当セルが削除されます。
逆にいずれか一方が0の場合は、外部メモリの削除処理は行われません。
削除処理が終わってから、値の追加を行います。
重み行列と追加ベクトルの積を計算し、外部メモリのどの位置にどれだけ値を追加するのか求めます。
そして、外部メモリの該当位置のセルの値を追加します。
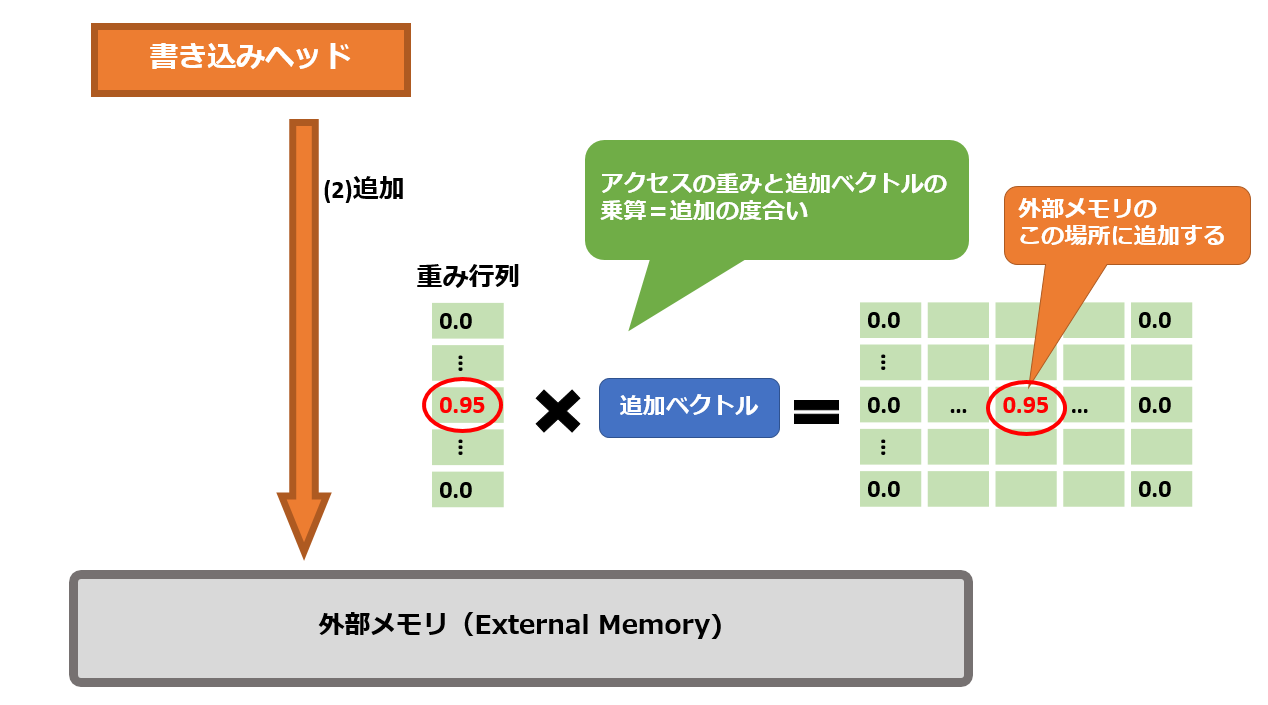
なぜこのような手間をかけるのかというと、外部メモリは行列の形で存在しているからです。
通常のRAMのように、狙ったセルに対してピンポイントなアクセスはできません。
行列計算を通して、外部メモリ全体を丸ごと更新する仕組みになっているのです。
そのため、削除したいセルの値を限りなく0に近づけるような行列操作をしてから、狙ったセルの値だけ加算する行列を作ってあげるわけです。
読み書き位置の決定メカニズム(Addressing Mechanism)
読み込みヘッドおよび書き込みヘッドは、直前の状態(外部メモリの内容、読み込み位置の重みベクトル、書き込み位置の重みベクトルなど)と
直前のコントローラーの出力を手がかりに、外部メモリのどの場所を参照すべきなのか学習します。
外部メモリの操作方法を学習していると言い換えることもできます。
では、ニューラルチューリングマシンは、どのようにして外部メモリの位置を決定しているのでしょうか。
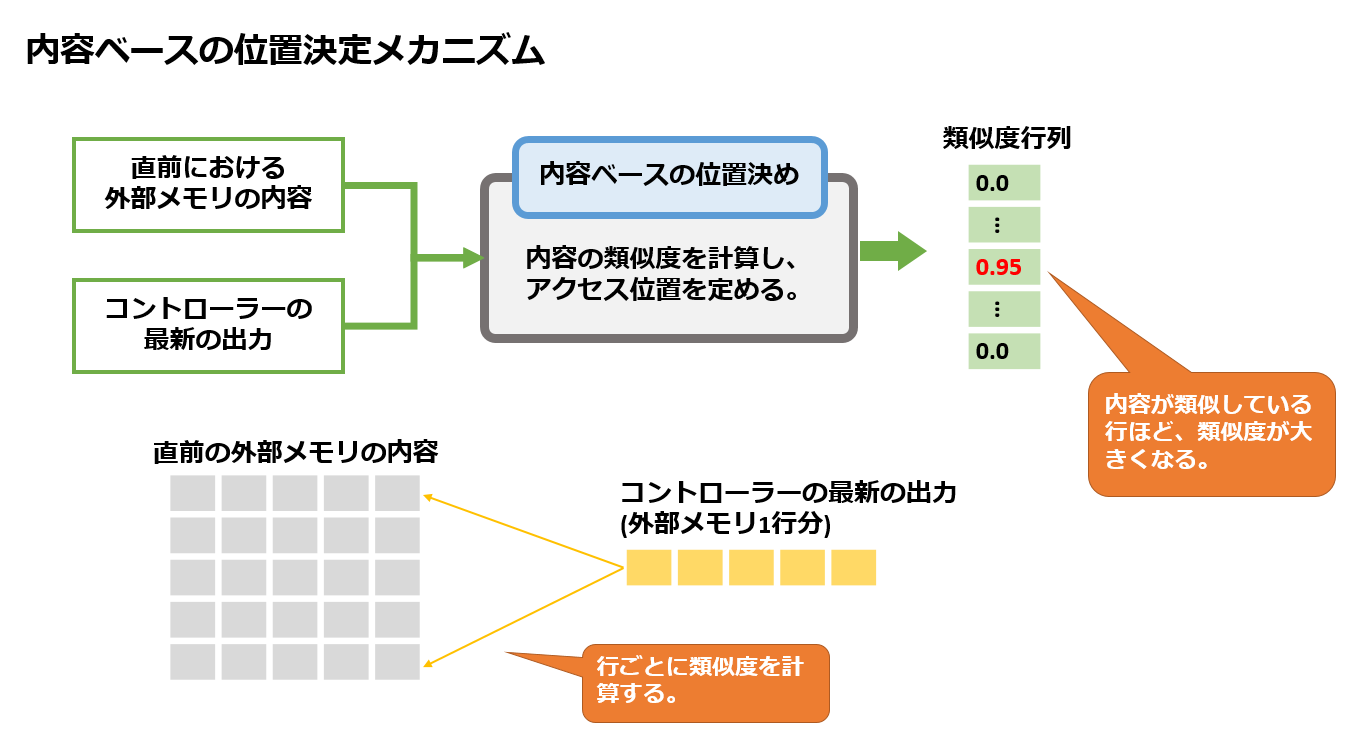
(1)内容ベースの位置決定
最初に、内容ベースの位置決定を行います。
直前の外部メモリの内容と、最新のコントローラーの出力を比較し、類似度を計算します。
内容が近いほど類似度は高くなる、つまりアクセスの重みが大きくなります。
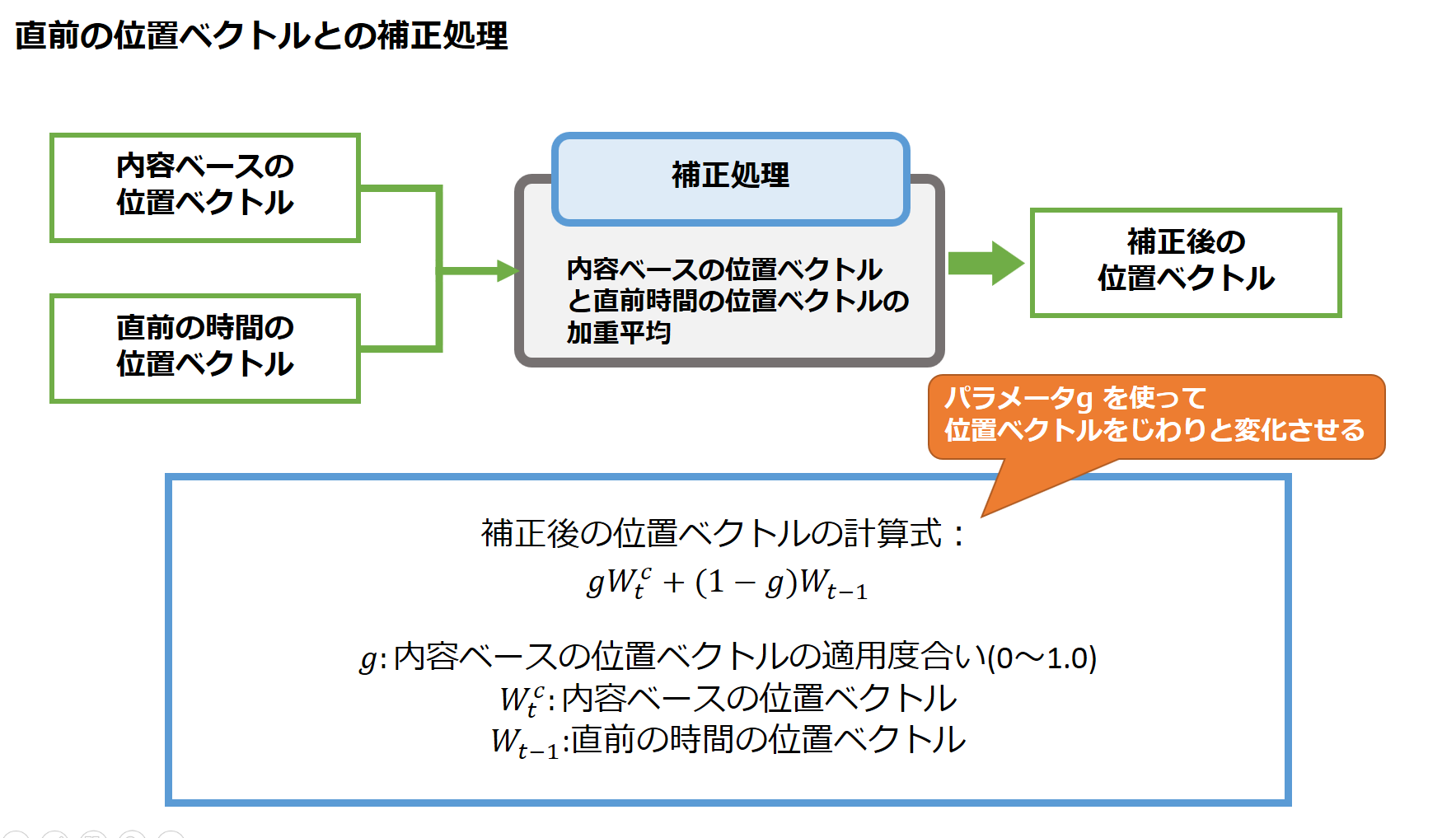
(2)直前の位置ベクトルとの補正処理
内容ベースの位置ベクトルを算出したら、直前の時間における位置ベクトルとの間で補正処理を行います。
内容ベースの位置ベクトルをどれくらいの割合適用するのかをパラメータで定め、直前の時間の位置ベクトルと加重平均を取ります。
この処理は、LSTMセルにおける入力ゲートの処理と似ています。
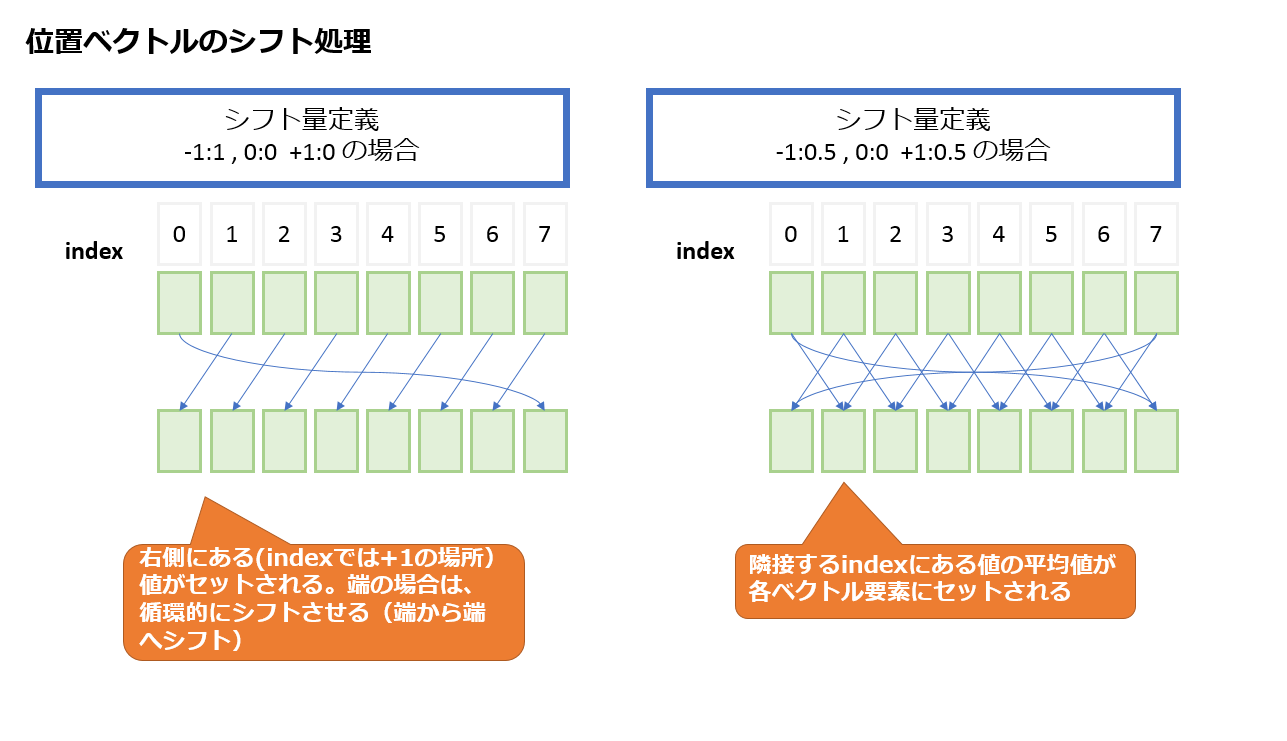
(3)位置ベクトルのシフト処理
補正処理した位置ベクトルに対して、シフト処理を施します。
シフト方向は-1,0,+1の3つです。シフト0は、文字通り位置を動かさないという意味です。
-1,+1は、位置ベクトルを左右に移動させる重みです。
シフト量は、0~1.0の実数で指定できます。最新の出力を踏まえて、どのようなシフトを施すべきなのかを学習します。
(4)位置ベクトルを磨く(sharpening)
ここまで計算してきた位置ベクトルですが、0 ~ 1.0の値をとります。
どれか一つの要素だけが1.0を取るというケースだけではなく、0.2と0.8や0.3と0.7といった値のとり方もありえます。
そうした値のとり方の場合、フォーカスがぼやけているので、磨いてやる必要があります。
具体的には、位置ベクトルに乗数を掛けて以下のように計算します。
すると、1.0以下の値であることが効いてきて、値の大きい要素以外は、簡単に小さくすることができます。
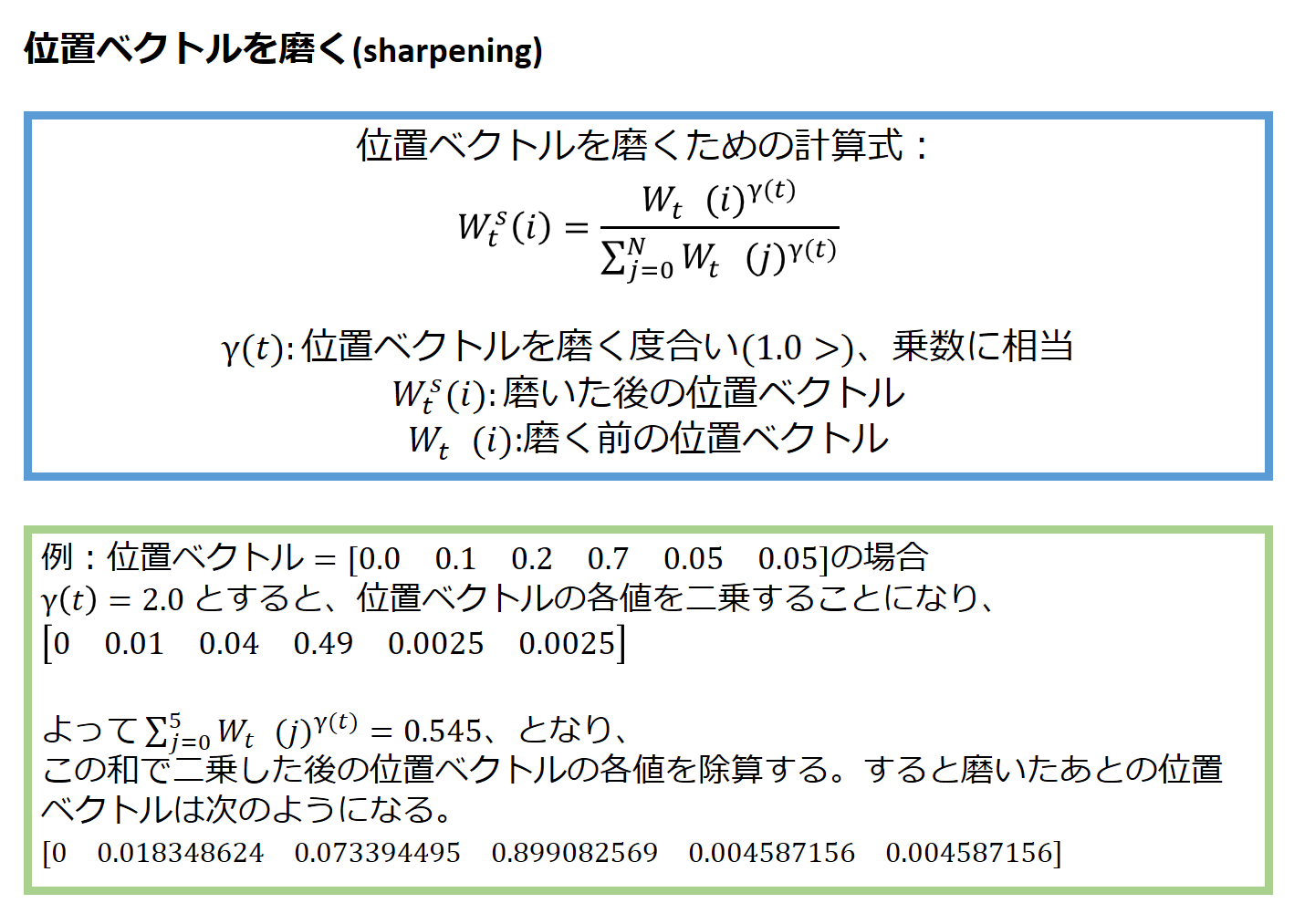
上記例では、最大値0.7だった位置ベクトルが、磨くとおよそ0.9になり、他の要素は相対的に小さくなっています。
サンプルコードを動かしてみよう
ニューラルチューリングマシンの理論の紹介が一段落したところで、そろそろ実際に動くサンプルコードの紹介へ移りたいと思います。
今回紹介するのは以下のサンプルコードです。
【Tensorflowによるニューラルチューリングマシンの実装例】
https://github.com/carpedm20/NTM-tensorflow/
動作環境と留意点
公式サイトでは、以下の条件を満たしている必要があるとされています。
- Python 2.7 or Python 3.3+
- Tensorflow 1.1.0
- NumPy
私が動作を確認した環境は、以下の通りです。
- Python3.5.2
- Tensorflow 1.4.0
- Numpy1.13.3
しかし、ループ処理の部分でxrange()が使われており、そのままでは動きませんでした。
xrange()はPython3.xでは使用できなくなっているためです。
そこで、xrange()の部分を修正して動作できるようにしました。
Python3.x環境で動かしたい場合は、xrange()の部分の修正が必要になるので、ご注意ください。
ソースコード構成
ニューラルチューリングマシンのサンプルコードの構成は以下のようになっています。
(source root)
|
+-- main.py メインプログラム。これを呼び出してサンプルコードを実行する。
|
+-- ntm.py ニューラルチューリングマシンのモデル構築や保存、読み込みなど。
|
+-- ntm_cell.py ニューラルチューリングマシンの実体はこちら。
|
+-- ops.py 計算処理関数を定義
|
+-- utils.py 各種補助処理関数を定義
|
+-- /tasks
| |
| +-- copy.py コピータスククラス。
| |
| +-- recall.py まだ作りかけである(in progress)
|
+-- /checkpoint
|
+-- /copy_10 学習済みモデルを保存してある。
実行方法と動作を確認できるタスク
基本的には、main.py を引数なしで実行すれば、コピータスクによるニューラルチューリングマシンの動作を確認することが出来ます。
$ python3.5 ./main.py
コピータスクとは、入力された内容をそのまま返すというシンプルなタスクです。
可変長の入力に対応したコピーなので、学習プロセスで経験したことがない未知の長さの入力パターンにも対応できるかどうかが見所となります。
これまでの機械学習は、学習プロセスで経験したことがあるパターンに対しては非常に高い精度で認識・判別可能ですが、未知のパターンに対しては急激にその性能が悪化するという課題があります。
一方ニューラルチューリングマシンは、入力パターンを覚えるのではなく、処理の手順を学習する(=自動プログラミングする)ので、未知の入力パターンに対しても頑健で汎用的な性能を発揮するものと期待されます。
果たしてどのような実験結果が得られるのか、それでは見ていきましょう。
実験概要
- 実験するタスク:ニューラルチューリングマシンを用いたコピー処理
- 学習プロセス:入力長10までのパターンを学習
- 入力データ制約:最大128
- 入力次元サイズ:10(入力1行における要素数)
- 実験対象:入力長5、10、20、30、80、120のパターン
- 評価関数:交差エントロピー
実験にあたり、main.py のタスク実行の部分(61~67行)を以下のように変更してから実行しました。
if FLAGS.task == 'copy':
task.run(ntm, int(5), sess)
print("…" * 50)
task.run(ntm, int(10), sess)
print("…" * 50)
task.run(ntm, int(20), sess)
print("…" * 50)
task.run(ntm, int(30), sess)
print("…" * 50)
task.run(ntm, int(FLAGS.test_max_length * 1 / 3), sess)
print("…" * 50)
task.run(ntm, int(FLAGS.test_max_length * 2 / 3), sess)
print("…" * 50)
task.run(ntm, int(FLAGS.test_max_length * 3 / 3), sess)
実験結果
(1) 入力長5
入力パターン長さ5は、学習した範囲なので、正確にコピーできています。
true output : □□■□■■■■□□ □□□■□■■■□□ □□■■□□□□□■ □□□□■□□□□□ □□■■□□■□■■
predicted output : □□■□■■■■□□ □□□■□■■■□□ □□■■□□□□□■ □□□□■□□□□□ □□■■□□■□■■
(2) 入力長10
入力パターン長さ10も、学習した範囲なので、正確にコピーできています。
true output : □□■■■□■■□□ □□□□□□■□□□ □□□□□■□□■□ □□□□□□■□□□ □□□□□■□□□■ □□□■■□■■□■ □□■■■■■■□■ □□□□□□■□■□ □□■■□■■□■■ □□■□■□□□■■
predicted output : □□■■■□■■□□ □□□□□□■□□□ □□□□□■□□■□ □□□□□□■□□□ □□□□□■□□□■ □□□■■□■■□■ □□■■■■■■□■ □□□□□□■□■□ □□■■□■■□■■ □□■□■□□□■■
(3) 入力長20
ここからが正念場です。学習プロセスで経験したサイズを超えた入力パターンがやってきます。
これまでの機械学習モデルでは、大きく性能が悪化してしまうでしょう。果たしてどこまで性能を発揮できるでしょうか?
true output : □□□■□■□■■□ □□■□□■□□■■ □□□■■■■■■■ □□□■■■■■□□ □□■□■□□□■□ □□□□□■□□□■ □□□■■■□□□□ □□■□□□□□■■ □□□□□□□□□□ □□□■□□■□□■ □□■□□■□■□□ □□□□■■□□□■ □□□■■□■■□□ □□□□■□■□□■ □□■□□■□■■■ □□□□□■■■■□ □□■■□□■□■□ □□■□■□■■■□ □□■□□■■□■□ □□■□□■■□■□
predicted output : □□□■□■□■■□ □□■□□■□□■■ □□□■■■■■■■ □□□■■■■■□□ □□■□■□□□■□ □□□□□■□□□■ □□□■■■□□□□ □□■□□□□□■■ □□□□□□□□□□ □□□■□□■□□■ □□■□□■□■□□ □□□□■■□□□■ □□□■■□■■□□ □□□□■□■□□■ □□■□□■□■■■ □□□□□■■■■□ □□■■□□■□■□ □□■□■□■■■□ □□■□□■■□■□ □□■□□■■□■□
なんときっちり正確にコピーすることができました。
未知の入力パターンに対してもしっかりと対処できることを確認しました。
(4) 入力長30
学習プロセスで経験したパターン長の2倍までは、大丈夫でした。
ですが3倍の長さには対応できるでしょうか?
界王拳のように基本能力のN倍の性能を発揮できるでしょうか?
true output : □□□□□■■□■□ □□■□■□□□■■ □□□□■■□□■■ □□□■□■□□□□ □□■□■■□□■■ □□□□□■■□■□ □□□□■■■□□□ □□■■□■■■□□ □□■□□□■□■□ □□■□□■■□■■ □□■■■□■■■□ □□■□□■□■■■ □□■□□□■■□□ □□■■□■□■□□ □□■■□■□■■□ □□□■■■□□■■ □□□□□□□□■□ □□□□■■□■■□ □□■■□■■■□■ □□□■■□□□□□ □□□■□■■□□■ □□■■■□□□□■ □□□□■■□■■■ □□■□□■■□■■ □□□□■□□■□■ □□□□□■□■■□ □□■■■■■□□■ □□■■□□■■■□ □□■■□■■■□■ □□■□□■□□□□
predicted output : □□□□□■■□■□ □□■□■□□□■■ □□□□■■□□■■ □□□■□■□□□□ □□■□■■□□■■ □□□□□■■□■□ □□□□■■■□□□ □□■■□■■■□□ □□■□□□■□■□ □□■□□■■□■■ □□■■■□■■■□ □□■□□■□■■■ □□■□□□■■□□ □□■■□■□■□□ □□■■□■□■■□ □□□■■■□□■■ □□□□□□□□■□ □□□□■■□■■□ □□■■□■■■□■ □□□■■□□□□□ □□□■□■■□□■ □□■■■□□□□■ □□□□■■□■■■ □□■□□■■□■■ □□□□■□□■□■ □□□□□■□■■□ □□■■■■■□□■ □□■■□□■■■□ □□■■□■■■□■ □□■□□■□□□□
できました! 見事正確にコピーしています。
学習した範囲の3倍まで対応できることが分かりました。
(5) 入力長80
ここで一気に学習した範囲の8倍の長さのパターンを試したいと思います。
エントリーが長すぎても問題があるので、途中の範囲を飛ばして実験したいと思います。
そろそろ、性能がガクっと落ちてきても不思議ではないと思うのですが、どんな結果になるでしょうか?
true output : □□■■□■□□□□ □□□■□■■□■■ □□■■■□■□■□ □□□■■□□■□■ □□■■■■□■□■ □□■□■□□■■■ □□■□□□■■□□ □□■□■□□□□□ □□■■□■□□□□ □□■■■■■□■□ □□■□■□□□■■ □□■■□■■■□■ □□□□■□□□□□ □□□■■■□■□■ □□□■□■■□□■ □□□■■□□□■□ □□■□□■□■□□ □□■■□□□□□□ □□□□■□□□□■ □□□■■■□■■□ □□□□□■□■□□ □□■□□■■■■□ □□■□■□■■■□ □□□□■□■■■□ □□□■■■□□■□ □□■■□■□■□■ □□■■■■■□□■ □□□■■■□□■■ □□■■□■□□■□ □□■□□□■□■■ □□■■■■□■□■ □□■■□□□□□□ □□■■□□□■■■ □□■□■■■□□□ □□□■□□□□□■ □□□■■■■■■□ □□□■■■□■■■ □□■■□□■□□■ □□■□□■□□□□ □□□□■□■■□□ □□■■■■■□■■ □□□□□□■□■□ □□■■■■■■■□ □□□■■■■□□□ □□■■■■□■□□ □□□□■■□□□■ □□□□□□■■■■ □□□■□□□■■■ □□■□■■□□■■ □□■■□■■■□■ □□□■■□■□□■ □□□■□□□□□□ □□■■■□□□□■ □□■■□■□□■□ □□□■□□■□■□ □□■■■□■■■■ □□□□□■■■□□ □□□□□■■□□■ □□■□□■■□□■ □□■■■■□□■■ □□□□■■□■■■ □□□■■■■■■□ □□■■■□■□■□ □□□■□□□□□□ □□□□□■■■■■ □□□□□□■■□■ □□□□■□■□■■ □□□■□□■■■□ □□□□□□□■□□ □□□■■■□■□■ □□□■■■■■□■ □□■□□■■■■■ □□■■■■■■□■ □□■■□■■■□□ □□□□■■□■□□ □□□□■□■□■■ □□■□□□□□■□ □□□□■□■□■□ □□■■□■□■■■ □□□□□□■□■■
predicted output : □□■■□■□□□□ □□□■□■■□■■ □□■■■□■□■□ □□□■■□□■□■ □□■■■■□■□■ □□■□■□□■■■ □□■□□□■■□□ □□■□■□□□□□ □□■■□■□□□□ □□■■■■■□■□ □□■□■□□□■■ □□■■□■■■□■ □□□□■□□□□□ □□□■■■□■□■ □□□■□■■□□■ □□□■■□□□■□ □□■□□■□■□□ □□■■□□□□□□ □□□□■□□□□■ □□□■■■□■■□ □□□□□■□■□□ □□■□□■■■■□ □□■□■□■■■□ □□□□■□■■■□ □□□■■■□□■□ □□■■□■□■□■ □□■■■■■□□■ □□□■■■□□■■ □□■■□■□□■□ □□■□□□■□■■ □□■■■■□■□■ □□■■□□□□□□ □□■■□□□■■■ □□■□■■■□□□ □□□■□□□□□■ □□□■■■■■■□ □□□■■■□■■■ □□■■□□■□□■ □□■□□■□□□□ □□□□■□■■□□ □□■■■■■□■■ □□□□□□■□■□ □□■■■■■■■□ □□□■■■■□□□ □□■■■■□■□□ □□□□■■□□□■ □□□□□□■■■■ □□□□□□□■■■ □□■□■■□□■■ □□■■□■■■□■ □□□■■□■□□■ □□□■□□□□□□ □□■■■□□□□■ □□■■□■□□■□ □□□■□□■□■□ □□■■■□■■■■ □□□□□■■■□□ □□□□□■■□□■ □□■□□■■□□■ □□■■■■□□■■ □□□□■■□■■■ □□□■■■■■■□ □□■■■□■□■□ □□□■□□□□□□ □□□□□■■■■■ □□□□□□■■□■ □□□□■□■□■■ □□□■□□■■■□ □□□□□□□■□□ □□□■■■□■□■ □□□■■■■■□■ □□■□□■■■■■ □□■■■■■■□■ □□■■□■■■□□ □□□□■■□■□□ □□□□■□■□■■ □□□□□□□□■□ □□□□■□■□■□ □□■■□■□■■■ □□□□□□■□■■
なんと、ほぼ正確にコピーしています。
一部のセルのコピー忘れがありますが、8倍のパターン長まで対応できているといってよいと思います。
少なくとも人間の目では、その違いを見分けるのが難しいレベルです。
(6) 入力長120
入力長80では、一部のコピーミスが見られました。そろそろ性能限界が近いかもしれません。
また、ニューラルチューリングマシンのメモリ長の限界が128でもあるので、直感的でありますが入力長120を試して締めくくりたいと思います。
そろそろ、性能がガクっと落ちてきても不思議ではないと思うのですが、どんな結果になるでしょうか?
true output : □□■□■□□■□■ □□■□■■■□■□ □□□■■□■□□■ □□□■■■□□□■ □□□■■■■□□□ □□■□■□■□□□ □□■■□□□□■■ □□■□■■■□■■ □□■■■□□□■□ □□□■□□□□■□ □□■□□□■■■□ □□□□□■■■■□ □□■■■□□■□■ □□□■□■□■■□ □□□□□■■■□□ □□■□■■□□■■ □□■□■□□■□□ □□■□□□■□■■ □□■■■■□□■□ □□■■□□□□■□ □□■■□■■□■■ □□□■■□■□□■ □□□□■□■■■□ □□□□■■□□■■ □□□□■□□■■□ □□□□□□□□□■ □□■■□□□■□□ □□■□□□■■■□ □□□■□□■■□■ □□■□■□■■□■ □□□■■■□■□■ □□□■■■■□■■ □□■■■□□□■■ □□■□■□□■□■ □□□□■□□□□■ □□■□□□□■□■ □□■■□□□□□■ □□■□□■■□■□ □□■■■■□■□□ □□□□■□■□□□ □□□□■□□■□■ □□■□□■■■□□ □□■□□■□■■■ □□■□■■■■□■ □□□■■■■■□■ □□■■■□□□■■ □□■■■■■■■■ □□□□□■□□□□ □□■□■□■■■□ □□□■□□■■■■ □□□■■■■□■■ □□■□■■■■□□ □□■□□□■□■■ □□■■□■□■■■ □□■□□□■■□■ □□■■□■□□□□ □□■■■■■□■□ □□□■■■□■□□ □□■■■■■□□□ □□■□■□■■■□ □□■□■□■■■□ □□□□■■■■□□ □□□□■■■□□■ □□□□■■□□■□ □□■■□□□□□□ □□■■□■■■□□ □□□■■■□■□■ □□■■■□□■□□ □□■■□■□■□□ □□□■■□■□□■ □□■■■■■□■□ □□■■□□□■■□ □□■■■□■□□□ □□■■■□□■□□ □□□□□□■□■■ □□□■■■■■■□ □□■■■■■□■■ □□□□■□□□■■ □□□□□■□■□□ □□■□□■■□■□ □□■□■■■□□■ □□■■■■■□■□ □□□■■□□■■□ □□■□■□■■■□ □□■□■■□■■□ □□■■■□■□□■ □□□□□■■□■□ □□■□□□□■□□ □□□□■■■□■■ □□■■□■■■□□ □□■□■■□□□■ □□■■□□□■■□ □□□□■■■□□■ □□□■□■■■□□ □□□□□■■□□■ □□■■□□■■□■ □□■■□□□□■■ □□■□■□□■□□ □□■■■■■■■□ □□□□■□■■□■ □□■■■■□□■■ □□■■■□■■■■ □□■□□■□□■■ □□□□□□□□□■ □□■■□□□■□■ □□□■□□□■■■ □□■□□■□■□■ □□■□■■□□□□ □□■□□□□□■■ □□□■■■■■□■ □□□□■□□□□■ □□■■□□■■□□ □□□□■■□■■■ □□■□■■□□□■ □□□□□■■■■■ □□■■■□□□□■ □□□■■■■□□□ □□■■□□□□□□ □□□□■■□■□□ □□□■□□□■□□
predicted output : □□■■□□□□■■ □□■□■■■□■■ □□■■■□□□■□ □□□■□□□□■□ □□■□□□■■■□ □□□□□■■■■□ □□■■■□□■□■ □□□■□■□■■□ □□□□□■■■□□ □□■□■■□□■■ □□■□■□□■□□ □□■□□□■□■■ □□■■■■□□■□ □□■■□□□□■□ □□■■□■■□■■ □□□■■□■□□■ □□□□■□■■■□ □□□□■■□□■■ □□□□■□□■■□ □□□□□□□□□■ □□■■□□□■□□ □□■□□□■■■□ □□□■□□■■□■ □□■□■□■■□■ □□□■■■□■□■ □□□■■■■□■■ □□■■■□□□■■ □□■□■□□■□■ □□□□■□□□□■ □□■□□□□■□■ □□■■□□□□□■ □□■□□■■□■□ □□■■■■□■□□ □□□□■□■□□□ □□□□■□□■□■ □□■□□■■■□□ □□■□□■□■■■ □□■□■■■■□■ □□□■■■■■□■ □□■■■□□□■■ □□■■■■■■■■ □□□□□■□□□□ □□■□■□■■■□ □□□■□□■■■■ □□□■■■■□■■ □□■□■■■■□□ □□■□□□■□■■ □□■■□■□■■■ □□■□□□■■□■ □□■■□■□□□□ □□■■■■■□■□ □□□■■■□■□□ □□■■■■■□□□ □□■□■□■■■□ □□■□■□■■■□ □□□□■■■■□□ □□□□■■■□□■ □□□□■■□□■□ □□■■□□□□□□ □□■■□■■■□□ □□□■■■□■□■ □□■■■□□■□□ □□■■□■□■□□ □□□■■□■□□■ □□■■■■■□■□ □□■■□□□■■□ □□■■■□■□□□ □□■■■□□■□□ □□□□□□■□■■ □□□■■■■■■□ □□■■■■■□■■ □□□□■□□□■■ □□□□□■□■□□ □□■□□■■□■□ □□■□■■■□□■ □□■■■■■□■□ □□□■■□□■■□ □□■□■□■■■□ □□■□■■□■■□ □□■■■□■□□■ □□□□□■■□■□ □□■□□□□■□□ □□□□■■■□■■ □□■■□■■■□□ □□■□■■□□□■ □□■□□□□■■□ □□□□■■■□□■ □□□■□■■■□□ □□□□□■■□□■ □□■■□□■■□■ □□■■□□□□■■ □□■□■□□■□□ □□■■■■■■■□ □□□□■□■■□■ □□■■■■□□■■ □□■■■□■■■■ □□■□□■□□■■ □□□□□□□□□■ □□■■□□□■□■ □□□■□□□■■■ □□■□□■□■□■ □□■□■■□□□□ □□■□□□□□■■ □□□■■■■■□■ □□□□■□□□□■ □□■□□□■■□□ □□□□■■□■■■ □□■□■■□□□■ □□□□□■■■■■ □□■■■□□□□■ □□□■■■■□□□ □□■■□□□□□□ □□□□■■□■□□ □□□■□□□■□□ □□□□□□□□■□ □□□□□□□□□□ □□□■■□□□□□ □□□□□□□□□■ □□□□□□□□■□ □□□□□□□□□□
残念! この辺が限界のようです。
しかし、かなり頑張ったのではないかと思います。
10倍近くまで基本性能を引き伸ばせるのであれば、実験としては十分成果が確認できたのではないかと思います。
まとめ
ニューラルチューリングマシンは、入力パターンではなく、入力データに対する対応方法を学習できることを実験を通して確認しました。
データのコピーというシンプルなタスクではありますが、まさに自動的にプログラミングを行い、処理を学ぶ様子を見ることができました。
現時点では、まだ原始的なニューラルコンピュータという段階ですが、今後発展が続けば、いずれは本当にプログラミングさえAIが自動化してくれる日が来るかもしれません。
【重要】最後に
次世代システム研究室では、機械学習や統計処理に関心を持つ開発者、アーキテクト、データサイエンティストを求めています。
自由闊達にのびのびと働きながら学べる環境が、コーヒー片手にアカデミックとビジネスの融合したディスカッションをしながら、知的好奇心を満たすことができる環境があなたを待っています。
次世代システム研究室にご興味を持たれたらすぐに 募集職種一覧 からご応募してください。
皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD