2024.04.03
退屈なことはマルチモーダルLLMにやらせよう(画像解析編)

はじめに
グループ研究開発本部・AI研究開発室のM.Mです。
マルチモーダルLLMsが実務で使用できるレベルに進化してきていますので、今までできなかったことや既存のAIではうまくできなかったことをいろいろ挑戦して日常業務に溢れる煩雑極まる作業を全て排除してしまいたいと思っている今日のこの頃です。
私の業務ではクラウドにあるデータから日々または毎週KPI等を報告するタスクがあります。今はページを開いて目視で状況を確認し、その画像を報告書にペタペタ貼りつつ考察と、何かあれば(だいたい何かある)追加分析を行う状況なのですが、例えばそういった作業をある程度全て自動化してしてしまいたいと思うのです。
今回のブログでは、特にマルチモーダルLLMの画像解析に焦点を当てて、ネット上の情報収集から画像解析のためのマルチモーダルLLMの活用の一連の流れを書いていきたいと思います。
データ取得に関して
業務上ネットの情報を解析する場合もありますが、どちらかというと解析する際は自社のデータを使用することが多いと思いますが、自社のデータを使用するにもクラウドでもオンプレでも何かしらのURLを持ったところに情報をストックしている場合が多いと思います。
今回はブログなのでネット上の何かしらのURLからブラウザツールを使用して自動でデータを取得するところから始めます。
例としてブラウザツールを利用する具体的な使用例は多岐にわたり、以下にいくつかの典型的なシナリオを挙げます。
- 最新ニュースやイベントの確認
- 現在のニュースの確認: 例えば、最新の政治ニュース、スポーツの試合結果、または特定の業界の動向など、リアルタイムのニュース情報を取得
- 重要なイベントのアップデート: 大規模なイベントや自然災害、政治的な出来事などの最新情報を確認する
- 研究や学習
- 特定のトピックに関する詳細情報: 科学的な研究、歴史的な出来事、特定の文化や国に関する情報など、様々なトピックの詳細な情報を検索し、提供
- 教育資料の検索: 学校の課題や研究プロジェクトに必要な情報や資料の検索が可能
- 製品やサービスの情報
- 製品レビューや比較: 特定の商品やサービスに関するレビュー、評価、価格比較情報を取得
- 購入先や取引条件の調査: 製品やサービスを購入する際の最良の取引先や条件を調べる
- 旅行計画
- 旅行先の情報: 観光スポット、ホテルの予約、地元の文化や規則についての情報など、旅行計画に役立つ情報を収集
- 交通機関のスケジュール: 飛行機のフライト情報、列車の時刻表、バスやタクシーの運行情報など、移動に関する詳細を調べる
- 個人的な質問や興味
- 健康やウェルネスなど
他にも自分が興味ある分野の日常的な情報収集、あるトピックに絞ったニュース、最近は猫も杓子もNISA NISAと言っていますが金融市場の情報など、さまざまに活用できるケースがあります。
画像解析のためのマルチモーダルLLM
現在マルチモーダルLLMは例えば下のような様々な画像解析タスクに活用されているそうです。
- ヘルスケア、医療: LLMは、病気の診断に役立つ医療記録や画像の分析に使用されている。例えば、LLMは、特定の病気を示す医療画像のパターンを特定するために使用することができる
- 小売業: ソーシャルメディアから得られる非構造化画像は、顧客の嗜好や傾向に関する貴重な洞察を小売業者に提供する。AIとLLMを利用することで、企業はこうした進化するパターンを捉え、市場の変化に先手を打つことができる
- 農業: 農家は、ドローンで撮影した非構造化データ画像を活用し、潜在的な作物のトラブルが大きな問題になる前に突き止めようとしている。AI分析により、作物の健康状態、土壌の状態、害虫の発生に関する洞察が得られ、タイムリーな介入が可能になる
- 取引: 市場データの分析に使用することができ、取引の意思決定を改善するのに役立つ
- 人事: 履歴書や応募書類などの大量のデータを分析・解釈し、より多くの情報に基づいた採用の意思決定に役立てるために、人事部門で使用することができる
他にもたくさんありそうです。
今回のブログですること
当部署ではBIツールを使用したデータ分析業務の日常的なレポート作業の負担が少なくないので
- グラフ(画像)から定型的な数値の抽出とフォーマットの成形
- そこから導かれるKPIの状況
- いつもと違う動きがあった場合は根拠とともにその旨を伝える
みたいなことを完全自動化してしまいたいと強く思っています。もちろん出てくる結果の状況が毎回違うので定型的にするというのは限界がありますが、それでも効率化できる部分は少ないと思っています。
しかしこのブログでは、上のような自動化処理をデータサイエンス業務以外にも適用するヒントになるように以上の作業を少し抽象化して、下の一連の流れを試してみたいと思います。
- Pythonで指定したURLへ飛ぶ
- そのURLから欲しい情報に該当する箇所のスクリーンショットを取得
- その画像をLLMないしAIが解析し欲しい情報を抽出
クローリング・スクレイピングを使用しなかったのは、すでにそのような技術の紹介がされている記事が多く存在していること、サイト上の任意の位置の情報を取得したいケースもあること、また情報を取得する先のサーバーに可能な限り負荷をかけないようにするため等です。
短く簡単な処理なので長いブログにはなりませんが、どうぞお付き合いいただければ幸いです。
その前に
スクレイピングやスクショなどのネットからの情報取得には法的な規則がありますので十分注意する必要があります。
以下に注意すべき点を整理して記載します。
著作権
コンテンツの著作権: ウェブサイト上のテキスト、画像、ビデオ、音楽などは著作権で保護されている可能性があります。これらを無断でコピー、共有、再配布することは違法です。
情報の使用法: 情報を利用する際には、著作権法の範囲内で行う必要があります。一般的に、短い引用や要約は許容されることが多いですが、全文のコピーは避けるべきです。
プライバシーとデータ保護
個人情報の保護: 個人を特定できる情報(個人情報)には特に注意が必要です。プライバシー保護法規に従い、個人情報の取り扱いには慎重になる必要があります。
データ収集の規制: 特にEUのGDPR(一般データ保護規則)のような、データ保護に関する法律を遵守することが重要です。
利用規約の遵守
ウェブサイトの利用規約: 多くのウェブサイトは利用規約を設けており、これにはサイトの内容をどのように利用して良いかについてのガイドラインが含まれています。例えば、サイト内コンテンツのスクレイピングを禁止している場合もあります。
法的責任
情報の正確性と信頼性: 公開された情報の正確性については、法的な責任が伴うことがあります。誤った情報に基づく決定が損害を引き起こした場合、その責任問題が生じる可能性があります。
地域や国による法的違い
地域による法律の違い: インターネットは国境を越えて利用されますが、各国・地域によって法律は異なります。特に、国際的に情報を扱う場合は、異なる法域の法律に注意する必要があります。
また、商用利用と個人利用でも状況は異なります。以下に要点をまとめます。
商用利用
商用利用とは、利益を得る目的でコンテンツや情報を使用することを指します。これには、商品やサービスの宣伝、ビジネスの宣伝、またはその他の金銭的利益を目的とした活動が含まれます。商用利用における法的規則には以下のような特徴があります。
- 厳格な著作権遵守: 商用目的でのコンテンツ使用は、特に著作権法の下で厳しく監視されます。無許可でのコピー、再配布、または改変は著作権侵害とみなされる可能性が高いです。
- 商標とブランドの保護: 他の企業の商標やブランドを無断で使用することは、商標権侵害に当たる可能性があります。
- 広告やマーケティングに関する規制: 誤解を招くような広告や不正確な情報を使用することは、消費者保護法に違反することがあります。
- 契約法の遵守: ビジネス間の取引においては、契約法が適用され、これに違反する行為は法的な責任を負う可能性があります。
個人利用
個人利用とは、個人的な楽しみや非営利目的でのコンテンツや情報の使用を指します。これには、自己教育、趣味、個人的な研究などが含まれます。個人利用に関する法的規則は以下のように異なります。
- 著作権の例外: 個人利用の場合、特定の状況で著作権の例外が適用されることがあります(例:フェアユース)。これにより、教育目的や批評、パロディなど特定の目的で限定的なコンテンツ使用が許されることがあります。
- プライバシー保護の重要性: 個人情報を扱う際には、他人のプライバシーを尊重し、無断で公開・共有しないことが重要です。
- データの利用制限: 個人的な目的であっても、特定の情報(例えば著作権で保護されたコンテンツ、個人情報など)の利用には制限があります。
商用利用と個人利用では、法的な規則の適用に重要な違いがあります。商用利用の場合は特に注意が必要で、著作権侵害、商標権侵害、契約違反などのリスクが高くなります。個人利用の場合でも、著作権法やプライバシーに関する規則を遵守する必要があります。常に最新の法的情報に基づいて行動し、不明点がある場合は法律専門家に相談することが望ましいです。
実際、今回のブログではあんなことやこんなことをしたかったのですが、商用利用となると非常にStrictで、使用できる情報を探しに探しまわった結果、気象庁のお天気情報を例に処理をしてみることにしました。
出典:気象庁ホームページ (https://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre24h0325.html#a44)
こちらは利用規約です(https://www.jma.go.jp/jma/kishou/info/coment.html)
Programming
まずは必要なライブラリと不要なライブラリをまとめてインポートします。
import pandas as pd import numpy as np import matplotlib.pyplot as plt from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options from PIL import Image import pytesseract import cv2 import io, time, tqdm, os, base64 from datetime import datetime
事前にChomeのバージョンを合わせたり、必要なファイルを必要なディレクトリにおいたりする作業が必要なので、注意が必要です。
Chomeのバージョンが変わって動かなくなった時は、こちらのサイトからChomeバージョンにあったDriverをダウンロードして、セキュリティ的に大丈夫であれば設定のセキュリティで許可して使用します。
https://googlechromelabs.github.io/chrome-for-testing/#stable
ChomeのDriverを適当なディレクトリにおいてください。私はMacを使用していて下のディレクトリに入れました。
/opt/homebrew/bin/chromedriver
では気象庁のサイトから東京都のお天気のデータを取得してみましょう。
chrome_driver_path = '/opt/homebrew/bin/chromedriver'
service = Service(chrome_driver_path)
options = Options()
options.headless = False
image_path = './screenshot.png'
driver = webdriver.Chrome(service=service, options=options)
url = "https://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre24h0325.html#a44"
driver.get(url)
y = 14500
driver.execute_script("window.scrollTo(0, {});".format(y))
time.sleep(1)
png = driver.get_screenshot_as_png()
im = Image.open(io.BytesIO(png))
current_time = datetime.now()
driver.quit()
im
取得した画像は下の通りです。
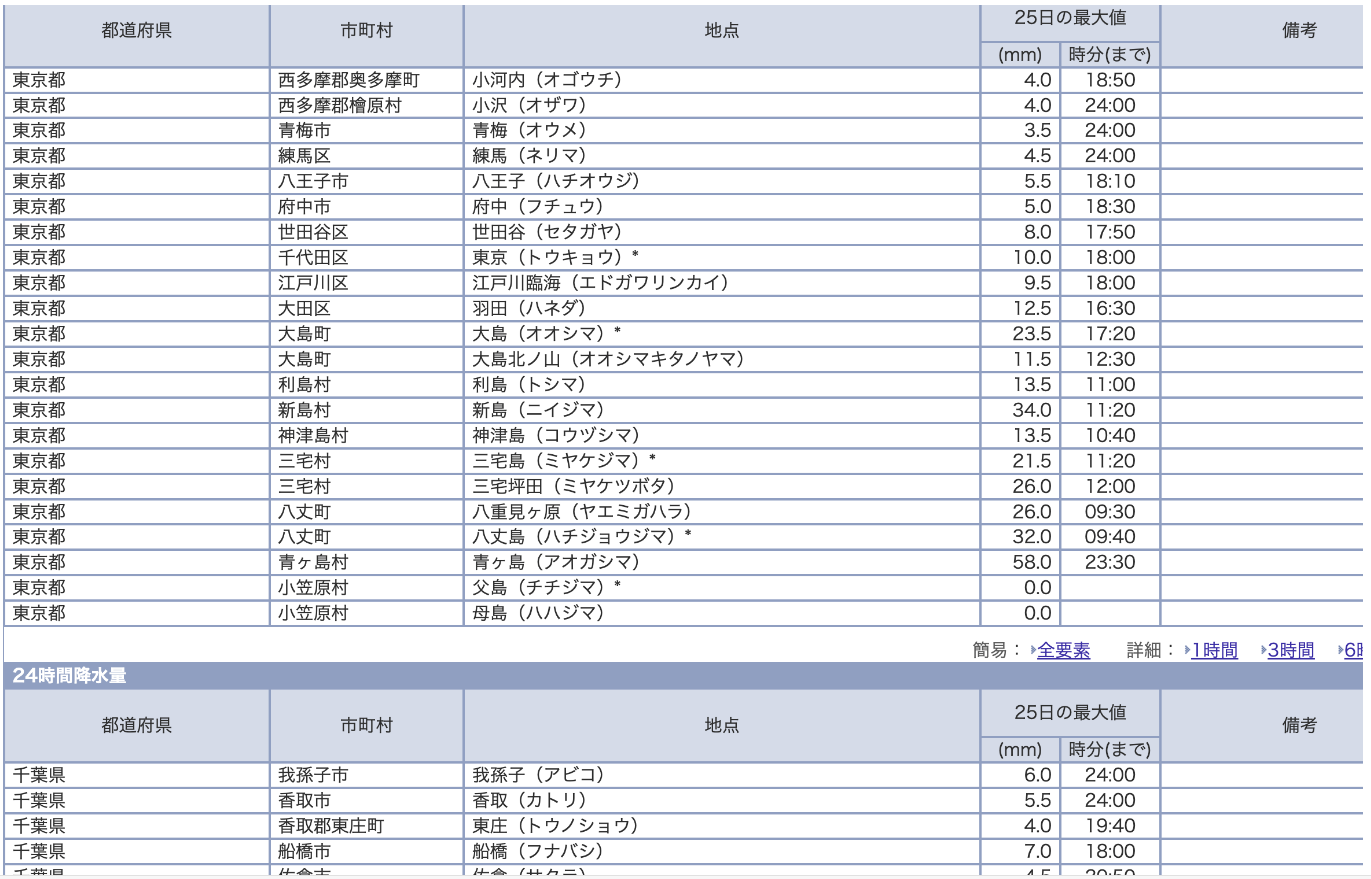
「東京都と千葉県の降雨情報」(気象庁ホームページより)
悪くないです。あとはちゃんとGPT4-Visionが解析してくれるか。
大田区の情報を抽出してくれるようにお願いしてみます。
import base64
from openai import OpenAI
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
chrome_driver_path = '/opt/homebrew/bin/chromedriver'
service = Service(chrome_driver_path)
options = Options()
options.headless = False
image_path = './screenshot.png'
driver = webdriver.Chrome(service=service, options=options)
url = "https://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre24h0325.html#a44"
driver.get(url)
y = 14500
driver.execute_script("window.scrollTo(0, {});".format(y))
time.sleep(1)
png = driver.get_screenshot_as_png()
im = Image.open(io.BytesIO(png))
current_time = datetime.now()
driver.quit()
try:
with io.BytesIO() as buffer:
im.save(buffer, format='PNG')
image_bytes = buffer.getvalue()
base64_image = base64.b64encode(image_bytes).decode('utf-8')
client = OpenAI(
api_key=api_key,
)
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": f"""
画像はある地点における降水量のデータを表したものです。東京都大田区に該当する情報を教えていただけますか?
"""},
{"type": "image_url", "image_url": f"data:image/jpeg;base64,{base64_image}"},
],
}
],
max_tokens=2000,
)
data_str = response.choices[0].message.content
except Exception as e:
print(f"Error: {e}")
print(data_str)
結果は、、
「この画像には、日本のさまざまな地点における降水量のデータが表になって記載されています。表は「都道府県」「都市」「地点」の三段階に分けられており、降水量(mm)と時間(時分)がそれぞれ示されています。 さて、「東京都大田区」についての情報ですが、この表には具体的な「大田区」という名称は見当たりません。しかし、もし表に「大田区」が含まれているとしたら、それは「東京都」の下の「地点」の欄に記載されるでしょう。これは表に記載されている情報から特定の地点を見つけるための一般的な指針です。 画像が不鮮明であったり、データが膨大であるために一部しか表示されていない等の理由で、特定の地点を見つけることができない場合もあります。もしそのような場合であれば、実際には表に含まれているかどうかを確認できません。もし実際のデータにアクセスができる場合は、そちらを直接参照することをお勧めします。」
どうやら大田区を見つけられなかったらしい。
これくらいのBusyさの画像だと特定の文字を拾ってくれないのでしょうか。
もちろん、この画像に対して一般的なOCRライブラリであるpytesseractも試してみましたが、出力は下の通りです。

気象庁「東京都と千葉県の降雨情報のOCR出力結果」 (https://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre24h0325.html#a44)を加工して作成
今回のケースのように、画像がBusyでGPT4-Visionがうまく認識してくれないケースも多々あると思いますので、そのような場合はピンポイントでスクショを撮ってくるのが良いと思います。下はxpathを使用して特定の地域の情報(スクリーンショット)を取得し、OCRしてみます。
chrome_driver_path = '/opt/homebrew/bin/chromedriver'
service = Service(chrome_driver_path)
options = Options()
options.headless = False
image_path = './screenshot.png'
res = {
"timestamp": [],
"region": [],
"precipitation": [],
}
for _ in tqdm.tqdm(range(0, 30)):
driver = webdriver.Chrome(service=service, options=options)
url = "https://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre24h0325.html#a44"
driver.get(url)
try:
for i in range(609, 614):
element = driver.find_element("xpath", f"/html/body/div[2]/div/div/table[2]/tbody/tr[{i}]")
element.screenshot(image_path)
image = Image.open(image_path)
_res_ocr = pytesseract.image_to_string(image, lang='chi_tra')
res_ocr = _res_ocr.replace("|", "").split("\n\n")
region = res_ocr[1]
precipitation = res_ocr[-3]
res["region"].append(region)
res["precipitation"].append(precipitation)
current_time = datetime.now()
res["timestamp"].append(current_time)
except Exception as e:
print(f"Error: {e}")
res["region"].append(None)
res["precipitation"].append(None)
res["timestamp"].append(None)
continue
driver.quit()
# 10分ごとの降水量の更新を待機
time.sleep(10 * 60)
df = pd.DataFrame(res)
display(df)
降水量のデータは10分おきに更新されるらしいので、10分の待機時間を設けています。
またこの処理は5時間ちょっとかかるのでloopの数は適宜変更していただければと思います。
「driver.find_element」のxpathはサイトを開いてfunctionキーのF12で「elements」の中で
該当箇所を右クリック→Copy→Copy full Xpath
で取得できます。
ある地点でのスクショの結果は下の通りです。

「複数地点での降雨情報」(気象庁ホームページより)
できたりできなかったりですね。
でも流石にこのくらいキャプチャして文字がはっきりしていたらGPT4-Visionはいけるかと思います。やってみます。
chrome_driver_path = '/opt/homebrew/bin/chromedriver'
service = Service(chrome_driver_path)
options = Options()
options.headless = False
image_path = './screenshot_test.png'
driver = webdriver.Chrome(service=service, options=options)
url = "https://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre24h0325.html#a44"
driver.get(url)
element = driver.find_element("xpath", f"/html/body/div[2]/div/div/table[2]/tbody/tr[612]")
element.screenshot(image_path)
if image.mode == 'RGBA':
image = image.convert('RGB')
image.save(image_path, "JPEG")
image = Image.open(image_path)
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
base64_image = encode_image(image_path)
current_time = datetime.now()
driver.quit()
try:
client = OpenAI(
api_key=api_key,
)
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": f"""
画像から、「地名」「数値」「日時」の情報を出力していただけますか?
"""},
{"type": "image_url", "image_url": f"data:image/jpeg;base64,{base64_image}"},
],
}
],
max_tokens=2000,
)
data_str = response.choices[0].message.content
except Exception as e:
print(f"Error: {e}")
print(data_str)
image
結果

「兵庫県の降雨情報」(気象庁ホームページより)
私には文字がはっきり見えます。どうしたのでしょうか。
残念ながらこのあとプロンプトをさまざま変えてみてもうまくいかなかったので省略しますが、他のサイトの市場データなどでは結構うまく抽出し構造化できたので、何か相性みたいなのがあるのか、とりあえずやってみてどうかで見てみるのが良いと思います。
以降の作業としては、上記のコードの「df = pd.DataFrame(res)」などでDataFrameを作り可視化やさまざまな分析タスクに繋げれば良いかと思います。
まとめ
今回はブラウザツールとGPT4-Vision, pytesseractを使用してデータ取得→情報抽出→構造化の一連の処理を紹介しました。
今回のケースでは画像から情報をうまく抽出できませんでしたが、(載せられませんが)他のケースだとうまくいったので、試してみる価値は大いにあると思います。
またLLMの進化も日進月歩なので、今後日々の分析タスクで使用してみようと思っています。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD