2023.07.06
chatgptによる株式ヘッドラインのセンチメント予測を検証してみる
はじめに
こんにちは、グループ研究開発本部 AI研究開発室のS.Sです。
最近、ChatGPTによりニュースのヘッドラインのsentimentを予測して、株式の取引をした場合に高い収益率が出たという研究が話題になっております。
ニュース記事 https://www.artisana.ai/articles/chatgpt-trading-algorithm-delivers-500-returns-in-stock-market
元論文 https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4412788

もちろんそうした方法を使って実際に収益を上げられるのかというと、そこまでおいしい話はないのではないかと思います。
とはいえ応用事例としては話題性はあり、ChatGPTでどのようなことができるのか感覚をつかむためにはよいトピックなので、今回のブログ記事ではこのトピックを少し掘り下げてみたいと思います。
データの抽出
今回は過去のbloombergのヘッドラインを取得して、ニュース発表1週間後での株式リターンを予測することにします。
個別株の予測は難しいので、以下の情報だけを抽出して株式インデックスのリターンとの相関を分析します。
セクター・キーワードといった情報は、ChatGPTがヘッドラインをどの程度正しく解釈できているか確認するための参考情報として一緒に抽出しています。
- 資産クラス
- 株式もしくは他の資産
- 関連セクター
- IT・金融・製造業…etc
- キーワード
- センチメント
- ポジティブ・ネガティブ・不明
抽出する情報のフォーマットをchatgptに以下のような形で指示します。
必要な要素をはじめに説明し、選択肢などがある場合は補足します。
また出力フォーマットは後ほど分析しやすいように、行ごとのjsonフォーマットになるよう指定します。
From the following headlines, extract asset class (Equity or other assets), related sectors (or answer "All" if all sectors are affected), keywords and its sentiment. output format: - ["asset class1", ["sector1", "sector2", ...], ["keyword1", "keyword2", ...], "positive"] - ["asset class1", ["sector1", "sector2", ...], ["keyword1", "keyword2", ...], "negative"] input data: - 米ISM製造業景況指数~~~ - 日本株反落 - ~セクターは下げ
bloombergの過去の記事データは一括で取得することはできませんが、過去のヘッドラインをWayback Machineで取得することができます。
理想を言えばWayback MachineとChatGPTのAPIを操作し、過去の日次のヘッドラインのデータを取得して解析するところまで自動でやりたいところですが、今回は感覚をつかむのが目的なのでニュース記事のアーカイブがある期間の中からランダムに15日間をピックアップし、ChatGPTに解析させてみます。
データ解析例
それでは試しに2016/10/03のヘッドラインに対する処理結果をみてみましょう。
次のようなインプットをChatGPTのプロンプトに入力します。

すると次のような応答が返ってきます。

日本株が反発というヘッドラインに関してはsentimentを正しくプラスと予測し、輸出・金融のセクターもうまく抽出できていることがわかります。
ドイツ銀に関するニュースが3件登場しますが、株式に関するニュースだと判定してくれているのは株というワードが登場するヘッドラインのみでした。
センチメントに関してはそこそこの精度にみえますが、キーワードの抽出はうまくいきませんでした。
このような形で残りのヘッドラインからも情報を抽出し、次のセクションで分析します。
時代を遡っていくとWebページの幅が狭くなり、デザインもどこか懐かしさが漂うものへと変わっていきます。
ヘッドラインのセンチメントとリターンの相関
それでは集めたデータをもとに、ヘッドラインのセンチメントとリターンの相関をみてみます。
データ件数は15件しかないので、もちろんこの相関から何かの結論を導くことはできないですが、データを揃えて検証するとどのような結果になりそうか占うことはできるかもしれません。
まず必要なライブラリ・データなどを読み込みます。
S&P 500にリストされている銘柄の日次データをweb上から取得し、週次のリターンに変換します。
import pandas as pd
import numpy as np
import json
df_stock = pd.read_csv("./stock_sp500_20220623.csv")
df_stock["Date"] = df_stock["Date"].pipe(pd.to_datetime)
df_stock = df_stock.set_index(["Date"])
df_stock_1w = df_stock.resample("1W").last().pct_change()
さきほどのセクションでChatGPTを使って抽出した結果を参照できるようにいくつか変数を定義します。
15件しかないのでベタ書きしてcont_で始まる変数を一括で処理してしまいます。
cont_20100410 = """...""" cont_20110603 = """...""" ... cont_20161003 = """["Other Assets", ["Unknown"], ["ドイツ銀に新たな痛手、モンテ・パスキの取引めぐりイタリアで起訴"], "Negative"] ["Other Assets", ["Unknown"], ["ドイツ銀、国内1000人削減で従業員代表と合意の見通し-関係者"], "Positive"] ["Other Assets", ["Unknown"], ["世界の債券市場を席巻する中銀、黒田総裁の金利操作でますます強固に"], "Positive"] ["Equity", ["Financial Services"], ["日銀新枠組みは「リフレ派の敗北」、黒田氏再任難しく-中原伸之氏"], "Negative"] ["Other Assets", ["Financial Services"], ["アセットマネジメントOne、買収視野に収益倍増へ(訂正)"], "Positive"] ["Equity", ["Export", "Financial Services"], ["日本株は反発で始まる、ドイツ銀懸念後退や円の安定-輸出や金融高い"], "Positive"] ["Equity", ["Financial Services"], ["ドイツ銀株が急反発、54億ドルで米司法省と合意に近いと報道"], "Positive"] ["Other Assets", ["Unknown"], ["メイ英首相:EU離脱来年3月までに通告-EU法も英国法に転換"], "Positive"] ["Other Assets", ["Unknown"], ["難民受け入れめぐるハンガリー国民投票は不成立-投票率50%下回る"], "Negative"] ["Other Assets", ["Unknown"], ["トランプ氏は納税情報開示せず、税金逃れかとの報道でも-関係者"], "Negative"]""" ...
データはjsonとして読み込み、日次で資産クラスごとのセンチメントを出します。
df_hl_cat = []
for _, row in pd.Series(vars().keys()).loc[lambda x: x.str.contains("cont_")]\
.to_frame("var").assign(date=lambda x: x["var"].str.extract("cont_(\d+)").squeeze()).iterrows():
df_hl = pd.DataFrame(np.vstack(pd.Series(eval(row["var"]).split("\n")).apply(json.loads).apply(lambda x: [x[0], x[1][0], x[-1]]).values))
df_hl_cat.append(df_hl.assign(date=lambda x: row["date"]))
資産クラスとして全てを対象にしたケースと株式のみのケースでそれぞれ日次の平均センチメントを算出します。
df_all_sentiment = pd.concat(df_hl_cat).set_axis(["asset_class", "sector", "sentiment", "date"], axis=1)\
.assign(sentiment=lambda x: x["sentiment"].map({"Negative": -1, "Positive": 1}))\
.rename(columns={"date": "Date"})\
.assign(Date=lambda x: x["Date"].pipe(pd.to_datetime, format="%Y%m%d") + pd.offsets.BDay(1))\
.groupby(["Date"])["sentiment"].sum()
df_equity_sentiment = pd.concat(df_hl_cat).set_axis(["asset_class", "sector", "sentiment", "date"], axis=1)\
.assign(sentiment=lambda x: x["sentiment"].map({"Negative": -1, "Positive": 1}))\
.rename(columns={"date": "Date"})\
.assign(Date=lambda x: x["Date"].pipe(pd.to_datetime, format="%Y%m%d") + pd.offsets.BDay(1))\
.loc[lambda x: x["asset_class"] == "Equity"].groupby(["Date"])["sentiment"].sum()
さらにヘッドライン掲載日の前後1週間のリターンを以下のような形で計算します。
ここでは計算を簡単にするために、時価総額加重平均ではなくS&P500の銘柄のリターンの単純平均を使います。
df_stock_1w = pd.concat((df_stock.stack().rename("open_price"),
df_stock.shift(-5).stack().rename("close_price")), axis=1).pct_change(axis=1).iloc[:, -1].unstack(-1)
df_stock_1w_prev = pd.concat((df_stock.shift(5).stack().rename("open_price"),
df_stock.stack().rename("close_price")), axis=1).pct_change(axis=1).iloc[:, -1].unstack(-1)
それでは相関があるかどうかをみてみましょう。
ここでは計算を簡単にするために、時価総額加重平均ではなくS&P500の銘柄のリターンの単純平均を使います。
センチメントとリターンのデータを合わせてポジネガのそれぞれのケースで平均リターンを出すには次のような処理を実行します。
pd.concat((
pd.concat((df_all_sentiment.to_frame()\
.pipe(lambda df: pd.merge_asof(df, df_stock_1w_prev.mean(axis=1).to_frame("ret").reset_index(), on=["Date"]))\
.pipe(lambda df: df.groupby(df["sentiment"].pipe(np.sign))["ret"].agg(["mean", "std", "count"])),
df_equity_sentiment.to_frame()\
.pipe(lambda df: pd.merge_asof(df, df_stock_1w_prev.mean(axis=1).to_frame("ret").reset_index(), on=["Date"]))\
.pipe(lambda df: df.groupby(df["sentiment"].pipe(np.sign))["ret"].agg(["mean", "std", "count"]))), axis=1, keys=["all", "equity"]),
pd.concat((df_all_sentiment.to_frame()\
.pipe(lambda df: pd.merge_asof(df, df_stock_1w.mean(axis=1).to_frame("ret").reset_index(), on=["Date"]))\
.pipe(lambda df: df.groupby(df["sentiment"].pipe(np.sign))["ret"].agg(["mean", "std", "count"])),
df_equity_sentiment.to_frame()\
.pipe(lambda df: pd.merge_asof(df, df_stock_1w.mean(axis=1).to_frame("ret").reset_index(), on=["Date"]))\
.pipe(lambda df: df.groupby(df["sentiment"].pipe(np.sign))["ret"].agg(["mean", "std", "count"]))), axis=1, keys=["all", "equity"])),
keys=["before", "after"])
結果は次のようになりました。
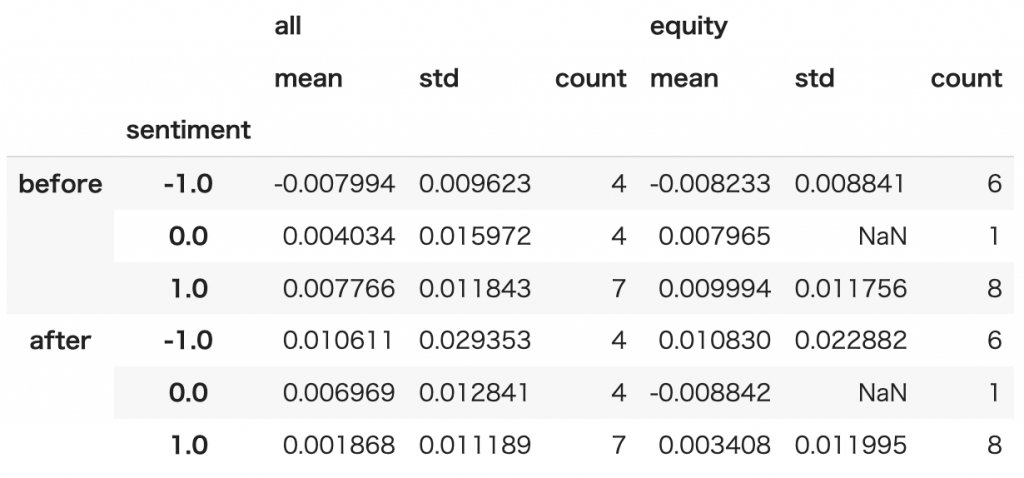
beforeはニュース発表日1週間前から発表当日までのリターン、afterは発表当日から1週間後までのリターンを示しています。
ニュースが発表される前には確かにネガティブのセンチメントのときに、株価が下落するというような動きになっています。
しかし発表の直後にはニュースを受けてある程度株価が調整された後の状態になっており、発表後に素朴にセンチメントの方向にプラスなら買うといった取引をしても、収益はとれないことを示唆する結果となっています。
1週間のようなタイムスケールではなく、ニュースが出てすぐに取引をすれば収益が出る可能性も残されていますが、ニュースの発表時刻を含む正確なメタデータや過去の分足のプライスデータを遡って取得するにはハードルが高いです。
それよりかはむしろ株価が下がりきったタイミングを見計らって、株式を購入する押し目買いの判断に使えるかどうかといったところでしょうか。
まとめ
ChatGPTを使ってヘッドラインから株式のリターンが予測をできるのか簡単な検証をしてみました。
検証では個別株やセクターのリターン予測はせず、株式指数のリターンを予測できるかにフォーカスしましたが、それでも簡単ではなさそうな雰囲気だけは伝わってくる結果となっています。
最後に
グループ研究開発本部 AI研究開発室では、データサイエンティスト/機械学習エンジニアを募集しています。ビッグデータの解析業務などAI研究開発室にご興味を持って頂ける方がいらっしゃいましたら、ぜひ 募集職種一覧 からご応募をお願いします。皆さんのご応募をお待ちしています。
グループ研究開発本部の最新情報をTwitterで配信中です。ぜひフォローください。
Follow @GMO_RD